Supervised Learning

Supervised Learning
📖 지도 학습(Supervised Learning)은 기계 학습 방법 중 하나로, 데이터의 레이블을 기반으로 패턴을 학습하고 예측하는 방법이다. 마치 학생에게 문제지(데이터)와 답안지(레이블)을 모두 주며 학습하도록 하는 방법라고 할 수 있다.
지도 학습 방법에는 대표적으로 분류(Classification), 회귀(Regression)이 있다.
Classification
🎏 분류(Classification)는 주어진 데이터들을 클래스 별로 구별하는 것을 말한다.
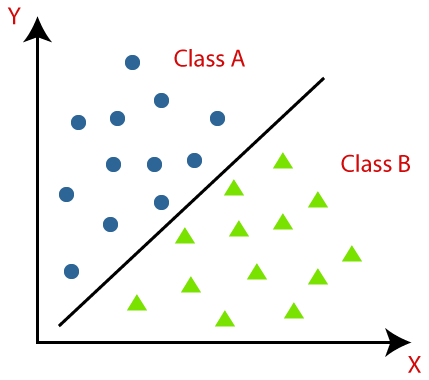
위와 같이 클래스가 여러 개 있을 때 두 클래스를 가장 잘 구분할 수 있는 선을 그려낼 수 있는데, 이것이 분류 문제가 풀고자 하는 것이다.
주로 예측 결과가 숫자가 아닌 경우에 많이 사용하며, Logictic Regression, Naive Bayes, SVM 등이 분류 문제에 사용된다.
Regression
📊 회귀(Regression)는 독립 변수와 종속 변수 간의 관계를 파악하는 것을 말한다.
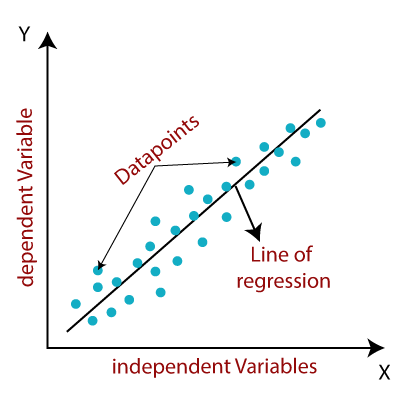
위와 같이 데이터들이 나타내는 관계를 가장 잘 나타내는 선을 그려낼 수 있고, 이것이 회귀 문제가 풀고자 하는 것이다.
주로 예측 결과가 숫자인 경우 많이 사용하며, Linear Regression, Ridge Regression 등이 회귀 문제에 사용된다.
Linear Regression
👆 선형 회귀(Linear Regression)는 독립 변수들과 종속 변수 간의 관계를 예측할 때, 그 관계를 선형의 관계로 가정하는 방법이다.
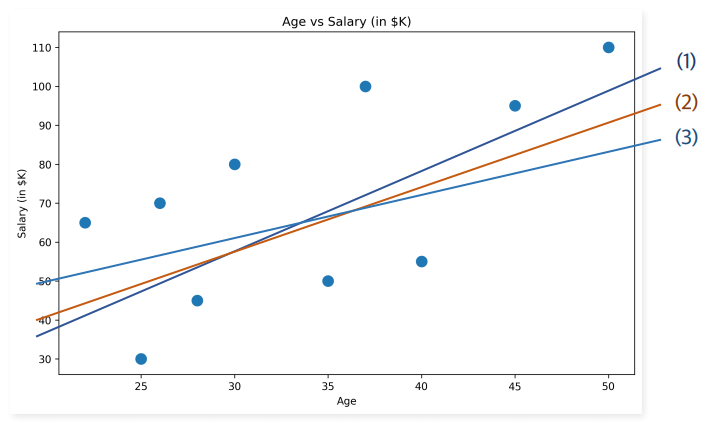
위 그림과 같은 상황에서 데이터를 가장 잘 설명해주는 직선은 어떤 직선일까?
이를 구하기 위해 잔차(Residual)의 제곱 합을 구해야 한다.
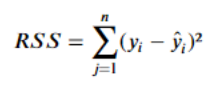
잔차는 모델의 예측값과 실체 관측값 사이의 차이로, 잔차의 값은 음수가 될 수 있기에 합이 0이 되지 않도록 제곱하여 합하게 된다. 데이터의 관계를 가장 잘 나타내는 직선은 잔차의 절댓값이 작을 것이므로, 해당 직선은 잔차 제곱의 합이 최소가 되는 직선일 것이다.
Classification & Regression
분류 문제와 회귀 문제에 모두 사용되는 방법들이 존재한다.
K-NN, Decision Tree, Random Forests,,, 등이 분류와 회귀에 사용된다.
K-NN
🤝 K-NN(K-Nearest Neighbor)는 새로운 데이터를 주변의 K개의 이웃 데이터 중 가장 많은 데이터 세트에 할당하는 방법이다.
K-NN의 과정은 아래와 같다.
- 새로운 데이터와 다른 데이터 포인트 간의 거리를 모두 계산한다
- 그중 가까운 이웃 데이터 포인트 K개를 선택한다
- 이웃 데이터 포인트의 레이블을 기준으로 가장 많은 데이터 레이블에 새로운 데이터를 할당한다
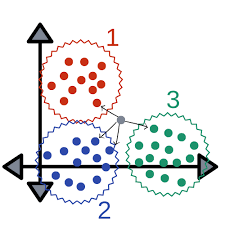
위와 같은 상황이라면 K가 4일 때 회색 데이터는 2번 레이블로 할당해야 한다.
🙆♂️ 장점
- 직관적으로 이해할 수 있다
- 훈련 과정이 필요하지 않다
- 다중 클래스에도 효과적이다
🙅♂️ 단점
- 데이터 규모에 민감하다
- 특성 스케일링에 민감하다
- 하이퍼 파라미터를 결정해야 한다
Decision Tree
🌳 의사결정나무(Decision Tree)는 의사결정 규칙과 그 결과물들을 트리구조로 도식화 한 것을 말한다.
의사결정 나무의 과정은 다음과 같다.
- 데이터 집합의 불순도(Impurity)가 가장 낮아지도록 하는 분기점을 선택한다
🎊 불순도(Impurity)
📌 엔트로피(Entropy)
: 데이터 집합의 불확실성이나 무질서도를 측정하는 값
정보량은 로그를 활용하여 아래와 같이 정의한다.
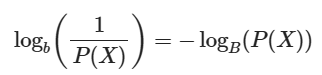
확률값에 반비례 해야 하고, 두 사건의 정보량 합이 각 사건의 정보량 합과 같아야 하기 때문에 로그를 사용한다.
엔트로피는 이러한 정보량의 평균이므로 아래와 같이 정의할 수 있다.
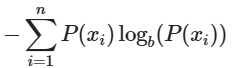
위 식에 따라 확률 분포가 균일할수록 엔트로피가 높아진다.
📌 정보 이득(Information Gain)
: 특정 분할에 의해 얻어지는 순도의 증가/불순도의 감소
정보 이득은 이전(상위 노드) 엔트로피의 값을 현재(하위 노드) 엔트로피의 값으로 뺀 것이다.
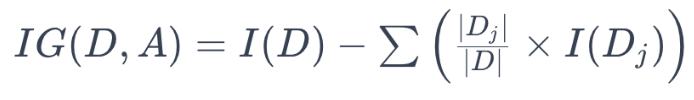
따라서 불순도가 가장 낮아지는 분기점은 순도가 가장 높은, 즉 정보의 이득이 가장 많은 분기점으로 해석할 수 있다. 또한 상위 노드에서의 엔트로피와 하위 노드에서의 엔트로피의 차가 가장 커져야 하므로, 분기점을 통해 데이터를 분할할 때 엔트로피가 낮아져야 함을 의미한다.
- 데이터를 분할하고 결정 노드를 생성하여 정지 기준을 충족할 때까지 의사결정나무를 계속 구축한다
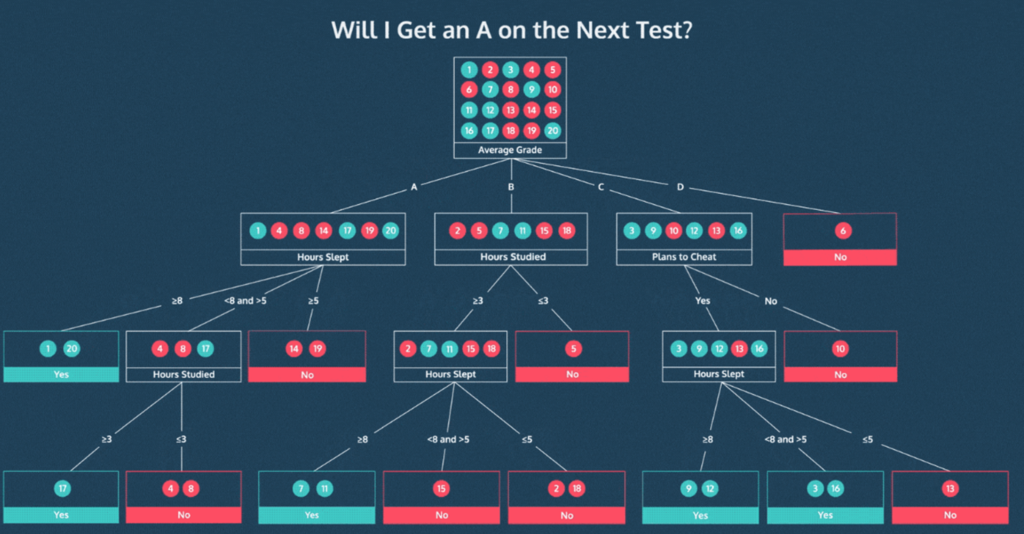
위 그림에서 볼 수 있듯 트리가 점점 깊어지면서 데이터가 잘 분류되고 있는 것을 볼 수 있다. 하지만 트리의 깊이가 너무 깊어지게 되면 오히려 과적합(overfitting)되어 새로운 데이터에 안좋은 성능을 낼 가능성이 매우 높다.
🙆♂️ 장점
- 해석/설명이 가능하다
- 데이터 전처리가 간단하다
- 비선형 관계도 포착할 수 있다
🙅♂️ 단점
- 과적합 경향이 있다
- 작은 데이터 변화에 민감하다
- 최적화가 어렵다
Confusion Matrix
🔢 혼동 행렬(Confusion Matrix)는 분류 문제에서 실제 값과 예측 값을 행렬 형태로 표현한 것이다.
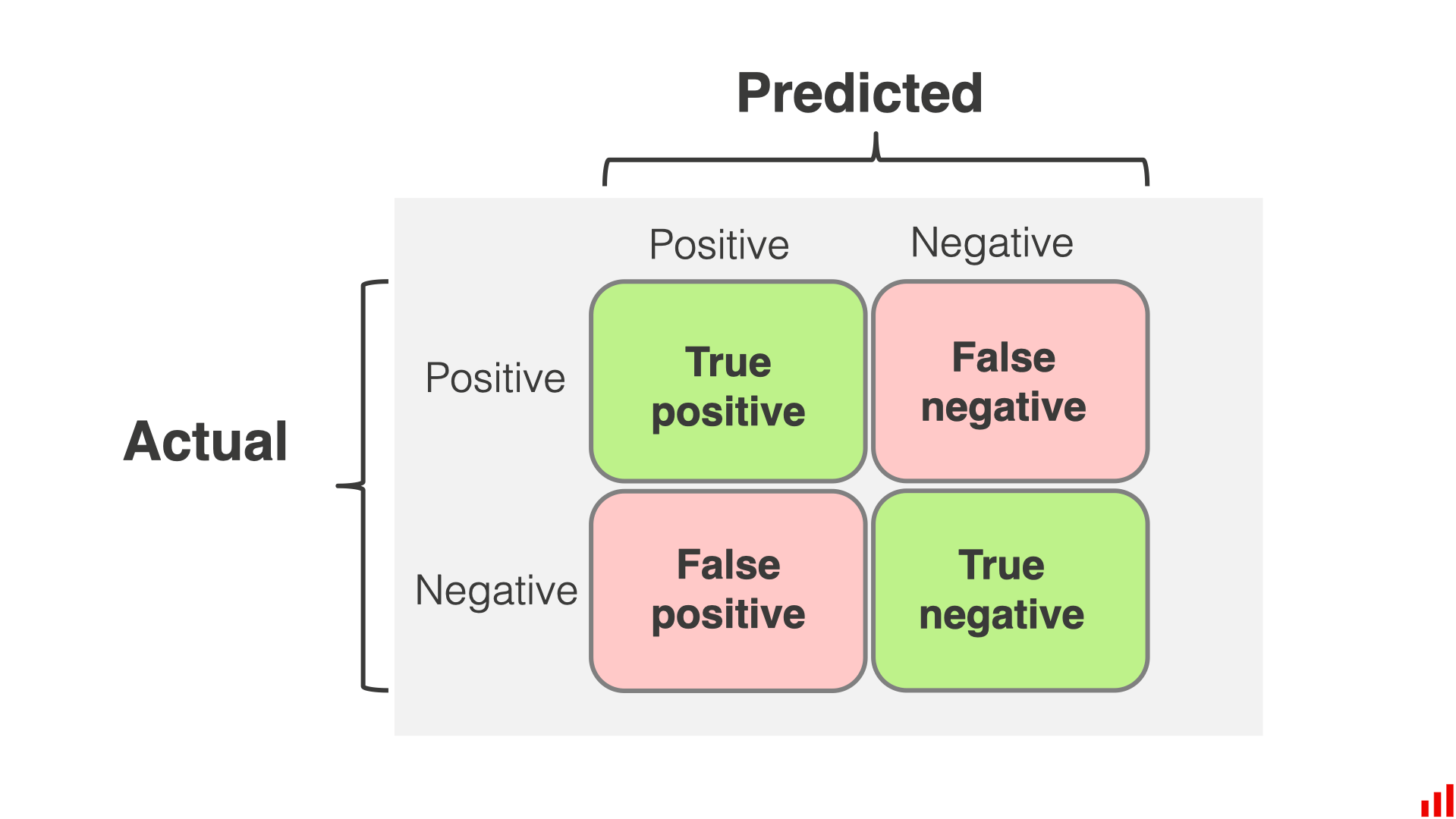
위의 그림과 같이 복잡하게 생겼다. Positive로 예측했는데 실제로 Positive면 True Positive(TP), Positive로 예측했는데 사실 Negative면 False Positive(FP)인 것이다.
이를 바탕으로 한 평가 지표로써 정밀도와 재현율이 존재한다.
😎 정밀도(Precision)는 양성으로 판단한 것 중 실제로 양성인 것의 비율이다.
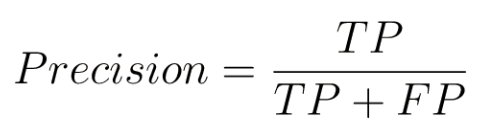
🤩 재현율(Recall)은 실제 양성인 것 중 양성으로 판단한 비율이다.
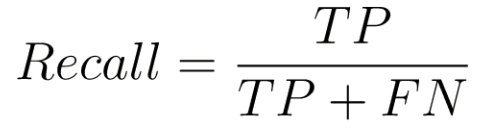
재현율을 다른 관점으로 보면, 양성에 대해 얼마나 '민감'하게 반응하는가로 해석할 수도 있다.
만일 정밀도와 재현율 모두 중요하다면, 정밀도와 민감도의 조화평균인 🚗 F1-Score를 사용할 수도 있다.
