타이타닉 데이터 DESC
타이타닉 데이터는 1912년 4월 15일에 침몰한 타이타닉호의 승객 정보를 담고 있는 데이터셋입니다.
타이타닉 데이터셋에는 승객들의 성별, 나이, 티켓 등급, 승선 항구, 가족 구성원 수, 요금 등 다양한 정보가 포함되어 있습니다. 또한, 승객들이 생존했는지 혹은 사망했는지를 나타내는 정보도 함께 제공됩니다.
타이타닉 데이터셋에는 다음과 같은 변수들이 포함되어 있습니다:
PassengerId: 승객의 고유 식별번호
Survived: 생존 여부 (0: 사망, 1: 생존)
Pclass: 티켓 등급 (1: 1st class, 2: 2nd class, 3: 3rd class)
Name: 승객의 이름
Sex: 성별 (male: 남성, female: 여성)
Age: 나이
SibSp: 함께 탑승한 형제자매 또는 배우자의 수
Parch: 함께 탑승한 부모나 자녀의 수
Ticket: 티켓 번호
Fare: 운임 요금
Cabin: 객실 번호
Embarked: 승선 항구 (C: Cherbourg, Q: Queenstown, S: Southampton)
EDA 분석
import pandas as pd
titanic = pd.read_excel('titanic.xls')
titanic.head()
pd.crosstab(titanic['title'], titanic['sex'])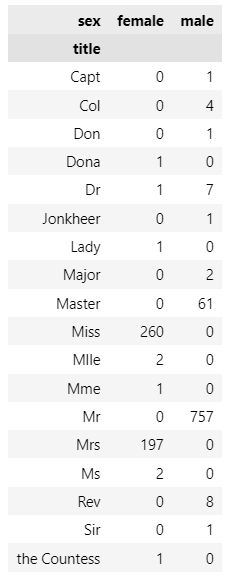
titanic['title'].unique()array(['Miss', 'Master', 'Mr', 'Mrs', 'Col', 'Mme', 'Dr', 'Major', 'Capt',
'Lady', 'Sir', 'Mlle', 'Dona', 'Jonkheer', 'the Countess', 'Don',
'Rev', 'Ms'], dtype=object)신분에 따라 승객 분류
titanic['title'] = titanic['title'].replace('Mlle','Miss')
titanic['title'] = titanic['title'].replace('Ms','Miss')
titanic['title'] = titanic['title'].replace('Mme','Mrs')
rare_f = ['Dona', 'Lady', 'the Countess']
rare_m = ['Capt', 'Col', 'Don', 'Major', 'Rev', 'Sir', 'Dr', 'Master', 'Jonkheer']
for each in rare_f:
titanic['title'] = titanic['title'].replace(each,'Rare_f')
for each in rare_m:
titanic['title'] = titanic['title'].replace(each,'Rare_m')
titanic['title'].unique()array(['Miss', 'Rare_m', 'Mr', 'Mrs', 'Rare_f'], dtype=object)titanic[['title','survived']].groupby(['title'],as_index=False).mean()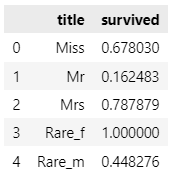
머신러닝을 이용한 생존자 예측
titanic.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 name 1309 non-null object
3 sex 1309 non-null object
4 age 1046 non-null float64
5 sibsp 1309 non-null int64
6 parch 1309 non-null int64
7 ticket 1309 non-null object
8 fare 1308 non-null float64
9 cabin 295 non-null object
10 embarked 1307 non-null object
11 boat 486 non-null object
12 body 121 non-null float64
13 home.dest 745 non-null object
14 age_cut 1046 non-null category
15 title 1309 non-null object
dtypes: category(1), float64(3), int64(4), object(8)
memory usage: 155.0+ KB머신러닝을 위해 컬럼을 숫자로 변경
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit((titanic['sex'])) #문자를 숫자로 바꿔줌
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()
결측치 제외
# 결측치 확인
print(titanic.isnull().sum())
# 결측치는 제외해줌
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]
pclass 0
survived 0
name 0
sex 0
age 0
sibsp 0
parch 0
ticket 0
fare 0
cabin 773
embarked 2
boat 628
body 926
home.dest 360
age_cut 0
title 0
gender 0
dtype: int64상관관계
correlarion_matrix = titanic.corr().round(1)
sns.heatmap(data = correlarion_matrix ,annot=True, cmap='bwr');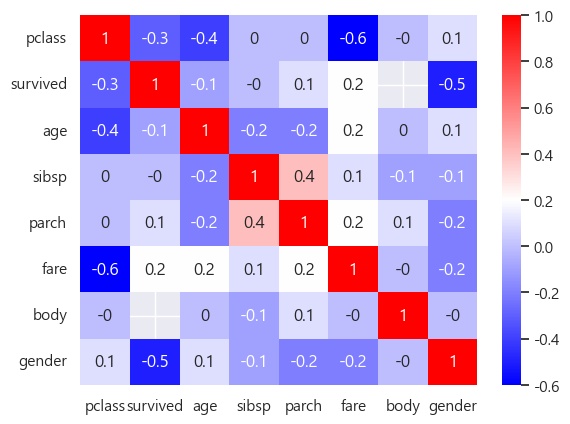
train_test_split
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=13)DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train,y_train)pred = dt.predict(X_test)
print(accuracy_score(y_test,pred))0.7896174863387978디카프리오는 생존할 수 있었을까?
import numpy as np
# titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
dicarprio = np.array([[3, 18, 0, 0, 5, 1 ]])
print( 'Dicarprio survived(%): ', dt.predict_proba(dicarprio)[0,1])
winslet = np.array([[1, 16, 1, 1, 100, 0 ]])
print( 'Winslet survived(%): ', dt.predict_proba(winslet)[0,1])Dicarprio survived(%): 0.2236842105263158
Winslet survived(%): 1.0
개발하고싶은사람