지도 학습
지도학습(Supervised Learning)은 머신러닝의 한 분야로, 입력 데이터와 그에 상응하는 정답(라벨 또는 타깃) 데이터를 이용하여 모델을 학습시키는 방법
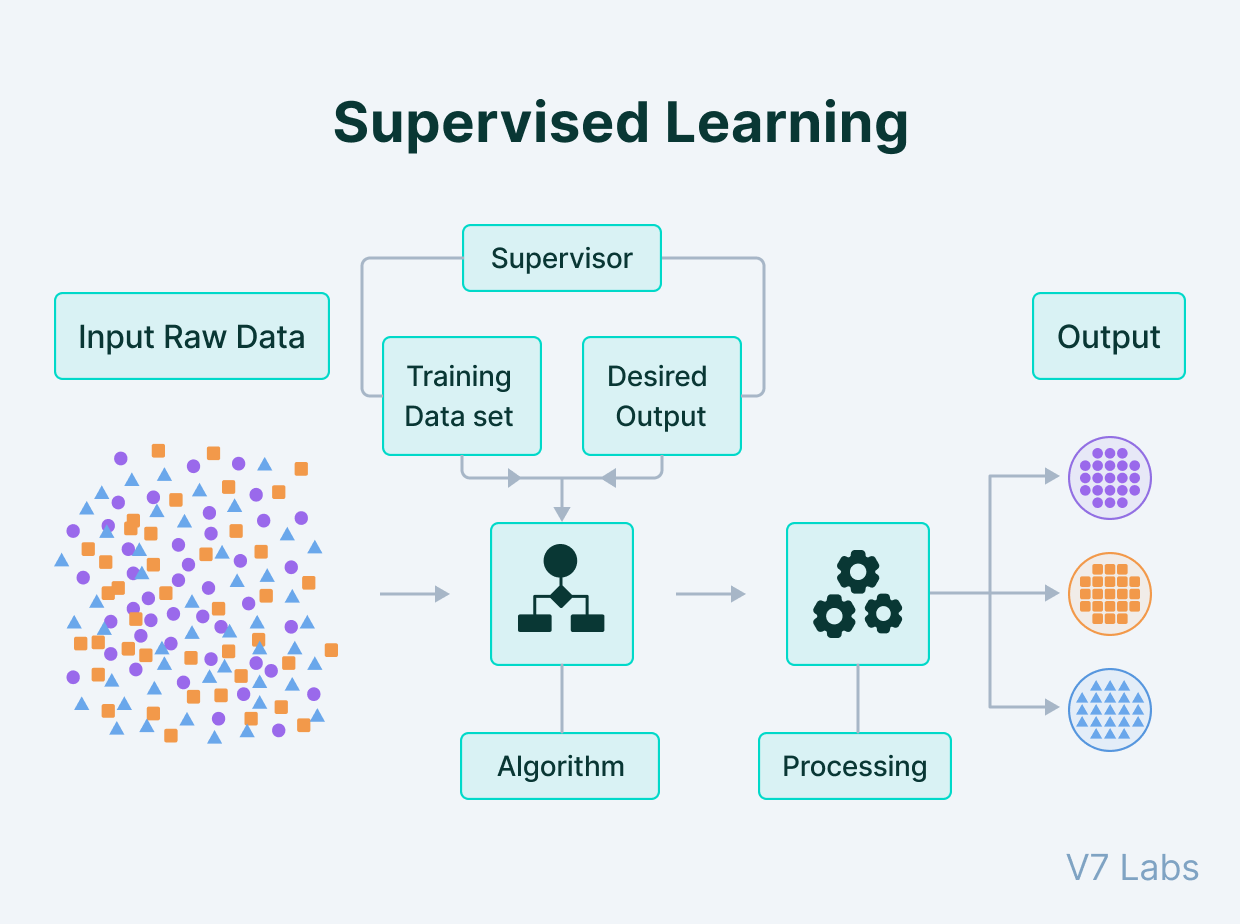
Image : Supervised and Unsupervised Learning
from sklearn.datasets import load_iris
from sklearn.tree import plot_tree
iris = load_iris()
plt.figure(figsize=(12,8))
plot_tree(iris_tree, filled=True);
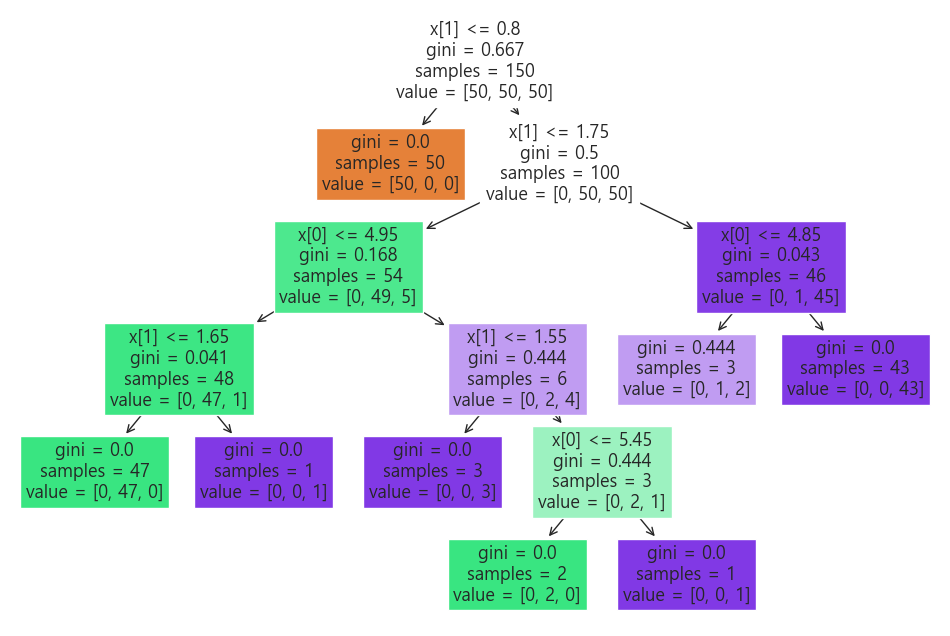
Accuracy 가 높을 수 있었던 이유 : 경계면이 복잡하다
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_tree,legend=2)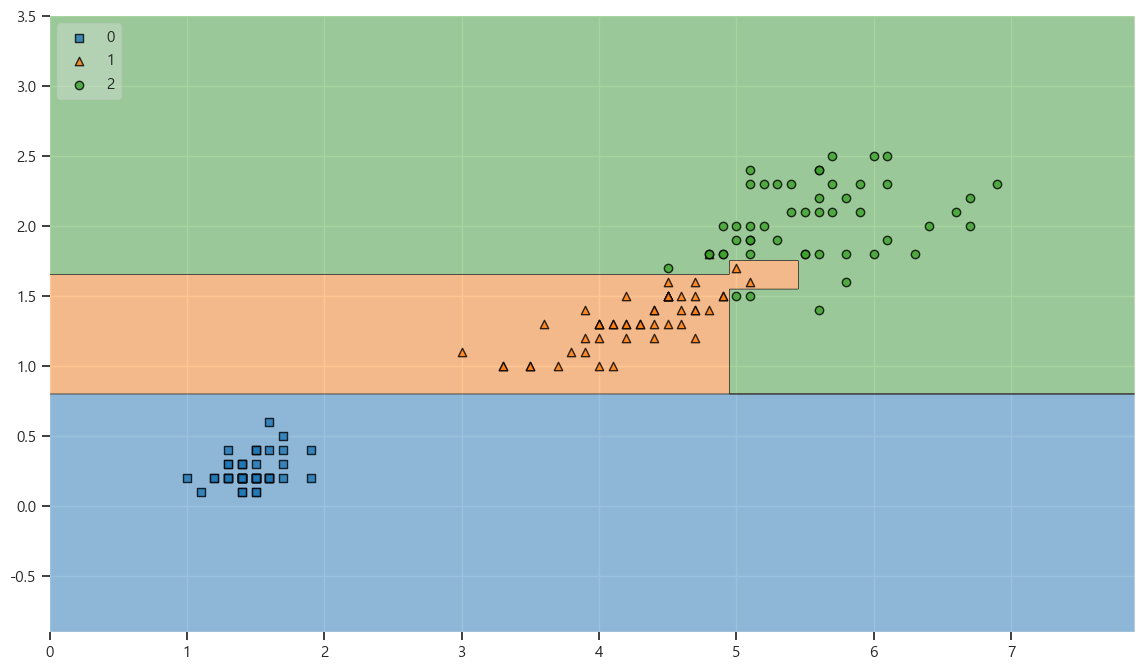
생각해 볼 점
- Accuracy를 믿을 수 있을까?
- 저 경계면은 올바른 걸까?
- 저결과는 내가 가진 데이터를 벗어나서 일반화할 수 있는 걸까?
- 어차피 얻은 데이터는 유한하고 내가 얻은 데이터를 이용해서 일반화를 추구하게 된다. (과적합 발생 사능성)
- 이때 복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다
Split Data
데이터의 분리 ( 훈련 / 검증 / 평가)
#데이터를 나눠주는 함수
from sklearn.model_selection import train_test_split
#fetal length, width 만 사용
feature = iris.data[:, 2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(feature, labels,
test_size=0.2, # 8:2로 데이터 분리
random_state=13) # 호출할 때마다 동일한 학습/테스트용 데이터 세트를 생성하기 위해 주어지는 난수 값.X_train.shape, X_test.shape((120, 2), (30, 2))print(X_train[:10]) #fetal length, width
print(y_train[:10]) # 0 : setosa, 1 : versicolor, 2 : virginica [[5.5 1.8]
[1.5 0.1]```
코드를 입력하세요 [1.5 0.4][5.1 2.3]
[5. 1.9][4.3 1.3]
[1.7 0.5][4.5 1.5]
[4.5 1.5][1.4 0.1]]
[2 0 0 2 2 1 0 1 1 0]
```python
#train, test data의 iris 분포 확인
import numpy as np
np.unique(y_test, return_counts=True) # setosa : 9, versicolor : 8 , virginica : 13 분포 )(array([0, 1, 2]), array([ 9, 8, 13], dtype=int64))
startify
# 비율을 맞춰주는 옵션 : startify
X_train, X_test, y_train, y_test = train_test_split(feature, labels,
test_size=0.2, # 8:2로 데이터 분리
random_state=13,
stratify=labels) # label 비율을 균일하게 설정 , 필수는 아니고 각자 필요에 따라 설정해줌 np.unique(y_test, return_counts=True) # setosa : 10, versicolor : 10 , virginica : 10 분포 )(array([0, 1, 2]), array([10, 10, 10], dtype=int64))결정나무 모델 만들기 - train data 대상
- mat_depth 를 설정하여 과적합되지 않도록 모델 성능 제한
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize=(12,8))
plot_tree(iris_tree);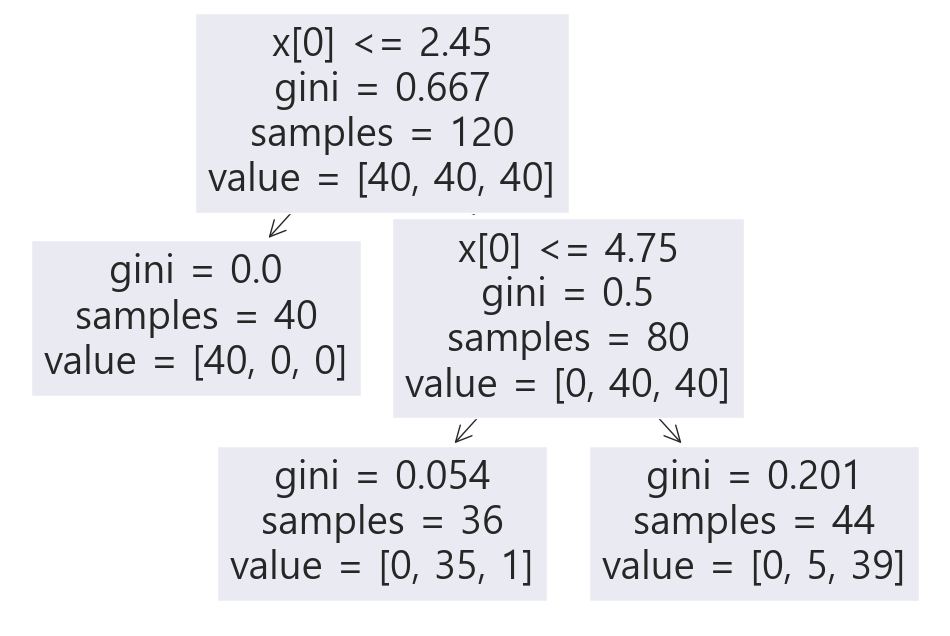
성능 측정
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:,2:])
accuracy_score(iris.target, y_pred_tr)0.9533333333333334훈련용 데이터에 대한 결정경계 확인
# 결정경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree,legend=2)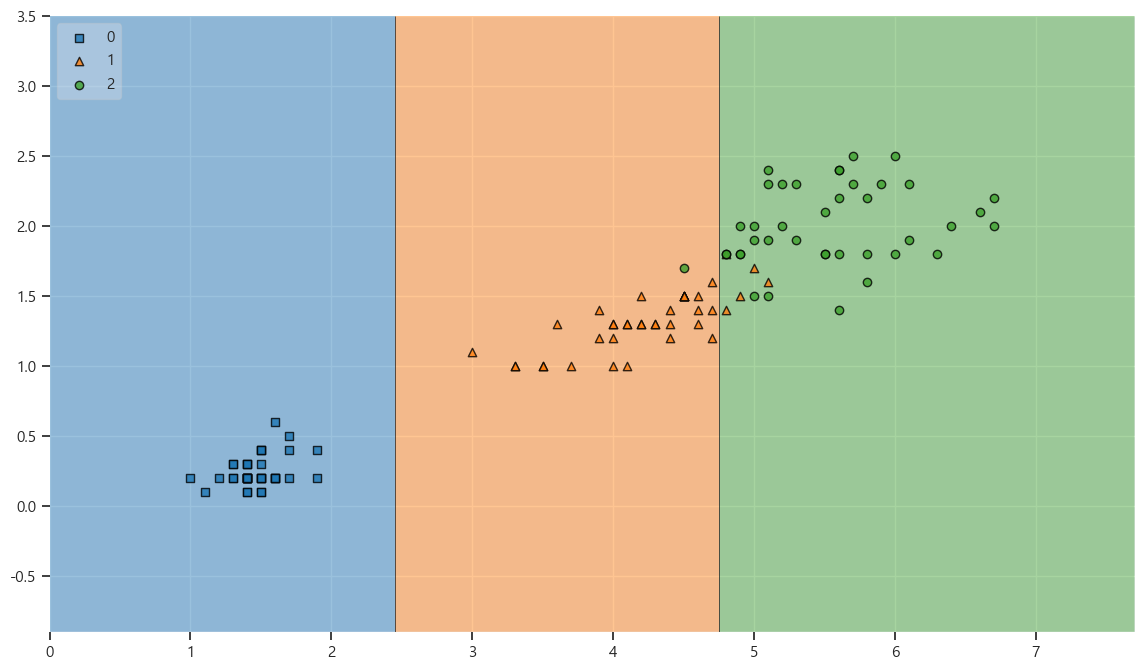
테스트 데이터 확인
과적합은 아닌걸로 확인
- train - 95%
- test - 96%
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)0.9666666666666667
# 결정경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_test, y=y_test, clf=iris_tree,legend=2)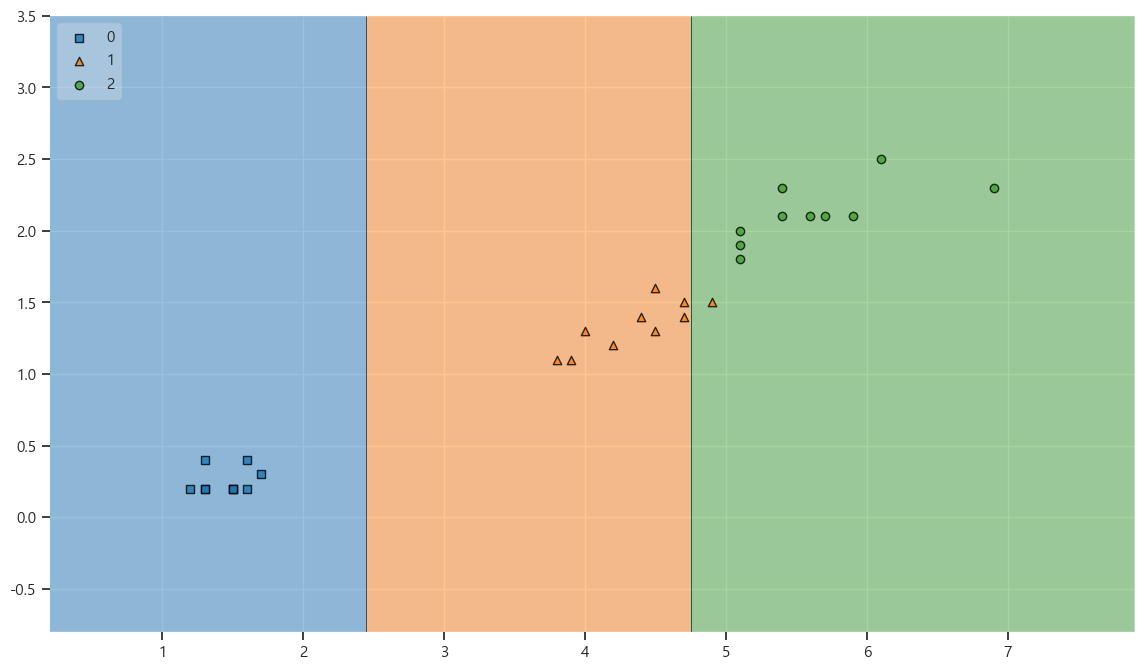
결정경계 하이라이트 주기
변수 설명
X=feature: 입력 데이터의 특성 행렬입니다.
각 행은 하나의 관측치를 나타내며, 각 열은 하나의 특성을 나타냅니다.
y=labels: 입력 데이터의 라벨(정답)을 담고 있는 벡터입니다.
각 원소는 해당 관측치의 라벨을 나타냅니다.
X_highlight=X_test: 선택적으로 입력 데이터 중 강조하고자 하는 부분집합의 특성 행렬입니다.
코드에서는 X_test를 강조하며, scatter_highlight_kwargs 인자를 사용하여 강조된 점들의 마커 특성을 지정합니다.
clf=iris_tree: 시각화할 분류 모델입니다.
코드에서는 iris_tree라는 결정 트리 분류기가 사용되었습니다.
legend=2: 시각화된 그래프에서 범례 위치를 정하는 인자입니다.
scatter_highlight_kwargs=scatter_highlight_kwargs: 강조된 점들의 마커 특성을 지정하는 딕셔너리입니다.
예시 코드에서는 점의 크기(s), 라벨(label), 투명도(alpha)를 지정하였습니다.
scatter_kwargs=scatter_kwargs: 일반적인 점의 마커 특성을 지정하는 딕셔너리입니다.
예시 코드에서는 점의 크기(s), 외곽선 색상(edgecolor), 투명도(alpha)를 지정하였습니다.
contourf_kwargs={'alpha': 0.2}: contourf() 함수에 대한 인자를 지정하는 딕셔너리입니다.
위 코드에서는 alpha 값만 0.2로 설정하였습니다.scatter_highlight_kwargs = {'s' : 150, 'label' : 'Test data','alpha' : 0.9} #마커 특성
scatter_kwargs = {'s' : 120, 'edgecolor' : None, 'alpha' : 0.9}
plt.figure(figsize=(12,4))
plot_decision_regions(X=feature, y=labels,
X_highlight=X_test, clf=iris_tree, legend=1, # clf - 시각화할 분류 모델
scatter_highlight_kwargs=scatter_highlight_kwargs,
scatter_kwargs=scatter_kwargs,
contourf_kwargs={'alpha': 0.2})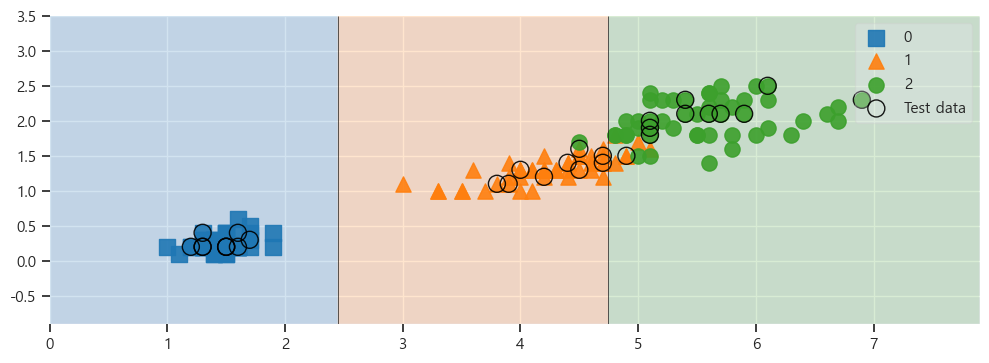
sepal 변수도 추가해서 결정나무모델 생성
# 전체 특성을 가지고 결정나무모델 생성
features=iris.data
labels=iris.target
X_train,X_test,y_train,y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13)
iris_tree=DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize=(12,4))
plot_tree(iris_tree);
주요 특성 조사하기
iris_tree=DecisionTreeClassifier(max_depth=5, random_state=13)
iris_tree.fit(X_train,y_train)
iris_tree.feature_importances_array([0. , 0.03389831, 0.39580123, 0.57030046])
iris_clf_model = dict(zip(iris.feature_names, iris_tree.feature_importances_)) # 각 특성의 중요도 확인
iris_clf_model{'sepal length (cm)': 0.0,
'sepal width (cm)': 0.033898305084745756,
'petal length (cm)': 0.3958012326656394,
'petal width (cm)': 0.5703004622496148}
개발하고싶은사람