아침에 일어났을 때,
몸이 생각보다 개운하고 밖이 쨍쨍해서
큰일났다 하고 생각했지만
다행히도 8시 50분에 눈이 떠졌다.
알람 안 듣고 일어난 건 처음인 것 같은데,
역시 인간은 적응의 동물이랬던가.
아침에 일어나는 것이 점점 익숙해지고 있다.
오늘 배워간 것
CNN
CNN의 경우, layer 사이의 파라미터 개수는 필터 사이즈와 상관이 있다.
이로 인해 필터 사이즈를 정하는 데에도 trade-off가 존재하는데,
필터 사이즈가 크면 한 번에 볼 수 있는 영역이 늘어나지만
그만큼 파라미터의 개수가 늘어나기 때문에 cost가 늘어난다.
ReLU
많이들 사용하는건 봤는데 왜 사용하는지는 몰랐다.
일단 활성 함수의 가장 큰 특징인 비선형이라는 특징을 가지고 있고,
값이 아무리 커지더라도 gradient vanishing이 일어나지 않는다는 특징을 가지고 있기 때문이다.
VGGNet
3x3 필터로 여러 번의 컨볼루션을 진행한 네트워크이다.
왜 3x3 필터를 여러개를 썼냐 하면,
3x3 필터를 두번 썼을 때와, 5x5 필터를 한 번 썼을 때,
input channel에서의 receptive field가 동일하지만
input, output channel의 개수가 같다고 가정하면
파라미터의 개수는 전자가 더 적다.
depth는 늘지만 파라미터는 더 적다는 것 ,,!
1x1 필터
1x1 필터는 왜 쓰지? 하고 종종 생각을 했었다.
중간에 채널을 줄이는 데에 쓰인다고 한다.
파라미터 개수를 줄이는 기법 중에 하나로 생각하면 될 것 같다.
ResNet
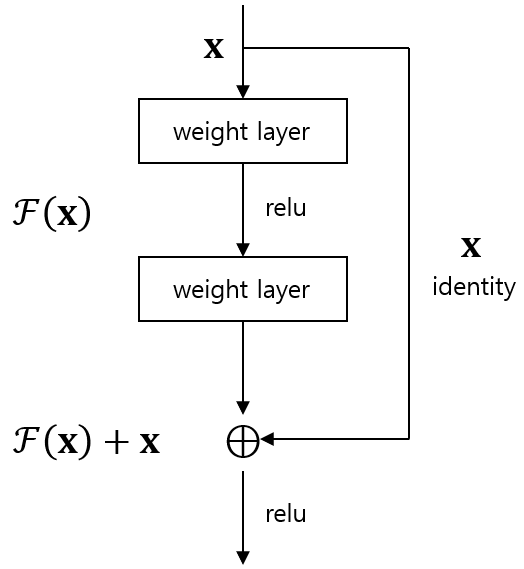
활성함수에 값이 들어가기 전에, 를 더해주어서
꼴을 만들어준다.
이 경우, 네트워크는 와 의 차이만큼만 학습하게 된다.
근데 사실,, 차이만큼만 학습하는게 test 케이스에 더 강건한 이유를 모르겠다.
Fully Convolutional Network
마지막에 Dense layer가 없기 때문에 input image의 사이즈에 상관 없이
네트워크가 돌아간다.
Deconvolution
컨볼루션의 역연산이 있는지 처음 알았다 ,,!
(엄밀히 말하면 역은 아니긴 함)
spatial demension을 늘릴 수 있다.
SPPNet
R-CNN의 경우 모든 바운딩 박스에 대해서 각각 컨볼루션을 했지만, 이 네트워크의 경우 미리 컨볼루션을 하여 feature map을 만들어두고, 바운딩 박스에 해당하는 텐서만 가져오는 식으로 구성하여 더 효율적이다.
Transformers
진짜 이해하기 힘들다 ,,
Attention is All You Need를 읽어봐야겠다.
서두르지 말고,
한 발짝씩 나아가기

열정넘치는 모습이 보기 좋아요😁