구조 요약
BLIP-2는 Vision-language pre-training(VLP)에서 기존의 방법과 같이 on-the-shelf 방식이 아닌 이미 pretrain 되어 있는 image encoder 모델과 LLM 모델, 즉 unimodal 모델을 compute-efficient하게 이용할 수 있는 방법을 제시한 논문이다.
이를 위해 unimodal 모델을 cross-modal alignment를 해야 하는데, 기존의 방법들은 image encoder를 freeze하고 LLM을 튜닝한다거나(LiT), LLM을 freeze하고 image encoder를 학습하는(MAPL, Pali 등) 방식으로 했는데, 결국 요점은 두 모달리티의 space를 align해야한다는 것이다. 예를 들어 Frozen은 이를 위해 image encoder를 finetune하여 결과값이 LLM의 soft prompt로 바로 이용되도록 했고, Flamingo는 LLM에 새로운 cross attention layer를 넣어 visual feature를 이용하도록 했다.
BLIP-2는 이와 다르게 image encoder와 llm을 모두 freeze하고 Q-former를 학습하는 식으로 작동하게 된다.
Q-former는 두 transformer를 가지고 있는데,
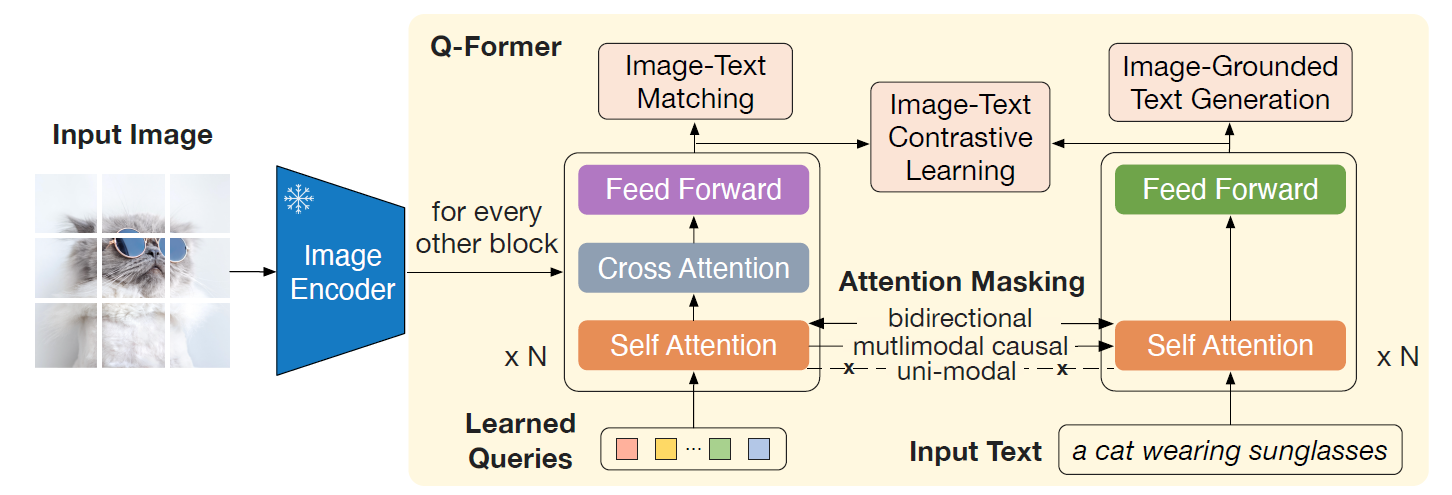
image transformer는 Learned Queries를 Query로 넣고 Input Image를 cross attention으로 넣어주게 된다.
text transformer는 Input text를 넣어 embedding을 만들게 된다. 재미있는건 두 transformer의 Self-Attention layer는 공유되기 때문에 두 모달리티가 서로를 참조하는 방식이 그냥 같은 Self-attention layer에 넣는 방법이라는 것이다. Transformer로는 pretrained 를 이용한다.
Loss
모델은 3가지의 objective를 가지고 학습을 진행하는데
Image-Text Contrastive Learning(ITC)
ITC는 CLIP에서와 같이 image-text similarity를 positive pair와 negative pair에 서로 contrastive하게 학습하는 방식이다.
Text Transformer의 [CLS]토큰의 embedding과, image transformer에서는 query의 수 만큼의 embedding이 나오므로 text embedding과의 similarity가 가장 큰 것만을 이용하게 된다. Encoder를 freeze하여 더 많은 sample을 이용할 수 있게 되었으므로 in-batch negative를 이용하게 된다.
Image-Grounded Text Generation(ITG)

이건 텍스트 생성을 이용하는 loss인데, 일단 [CLS] 토큰을 [DEC] 토큰으로 바꾸게 되고, self-attention을 통해 Query와 text 정보를 공유하면서 text 생성을 했을 때, 실제 text와의 차이를 이용한 loss이다. 이를 위해 위처럼 마치 PrefixLM과 비슷하게 Query는 full attention을 하고, text는 causal attention을 하는 방식으로 attention을 하게 된다.
Image-Text Matching(ITM)
ITM은 query와 text간에 full attention을 하며 진행되는데, image와 text의 pair가 positive한지 negative한 지 output query embedding에 linear layer를 합쳐 2개의 logits를 결과로 내게 되고, 모든 query에 대해 이를 평균값을 내어 최종 logits을 만들어 평가하게 된다. BLIP에서의 hard negative mining 전략도 이용했다고 한다. 즉 원래 positive pair에 해당하는 text를 제외하고 나머지 중 가장 similarity가 높은 sample을 hard negative sample로 이용하게 된다.
LLM
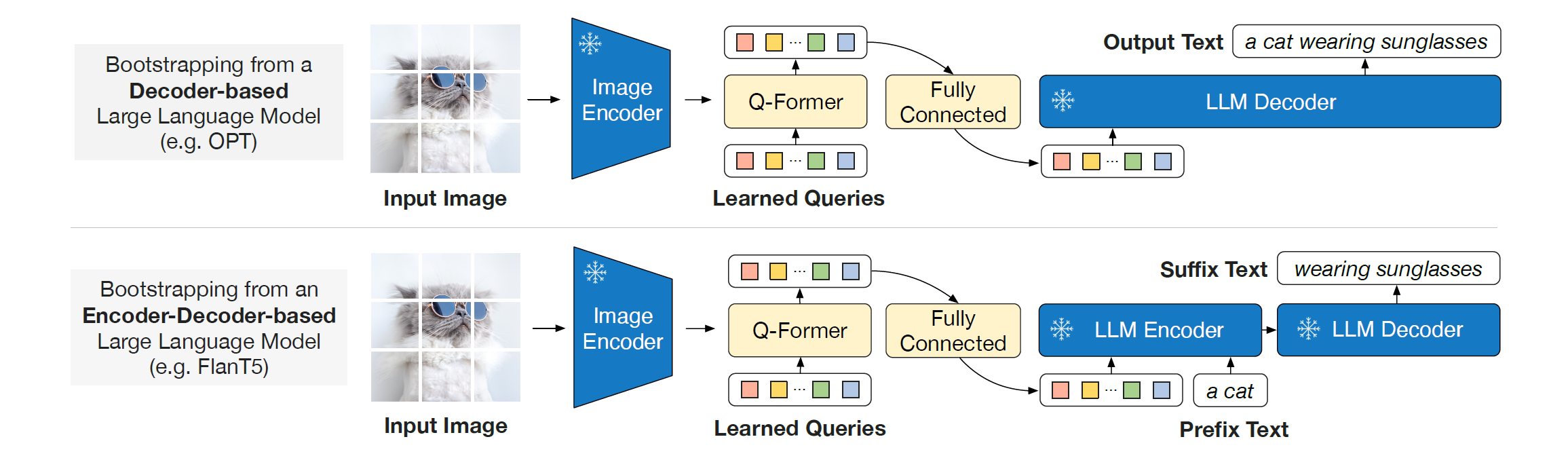
앞의 학습이 1Stage이고 여기서 나온 정렬된 Embedding을 다시 LLM에 넣어서 LLM에 사용할 수 있도록 재정렬 하게 된다. Q-Former의 결과값을 Linear layer에 넣어 LLM의 dimension과 맞춰주고 이를 LLM의 soft visual prompt로 넣어주게 된다.
앞에서 language-informative visual representation을 추출하도록 pretrain되었기 때문에, irrelevant visual information을 제거하면서 representation이 생성되고, 이를 통해 LLM에 align하는 데 부담이 줄어든다고 한다.
학습
BLIP에서와 같이 CapFilt 방법을 사용하는데, 즉 human labeled된 데이터로 학습된 captioning model, filtering model을 이용해 web에서 나온 noise가 섞인 데이터를 걸러주고, 모델로 captioning한 데이터도 학습에 이용하는 방법이다.
이를 위해 모델로 captioning한 10개의 text data를 기존의 web caption과 함께 CLIP VIT-L/14 모델로 similarity를 구해준 후에, top-2 caption을 저장하고, 훈련 과정에 이 중 1step에 1개를 샘플해서 사용한다고 한다.
학습 결과
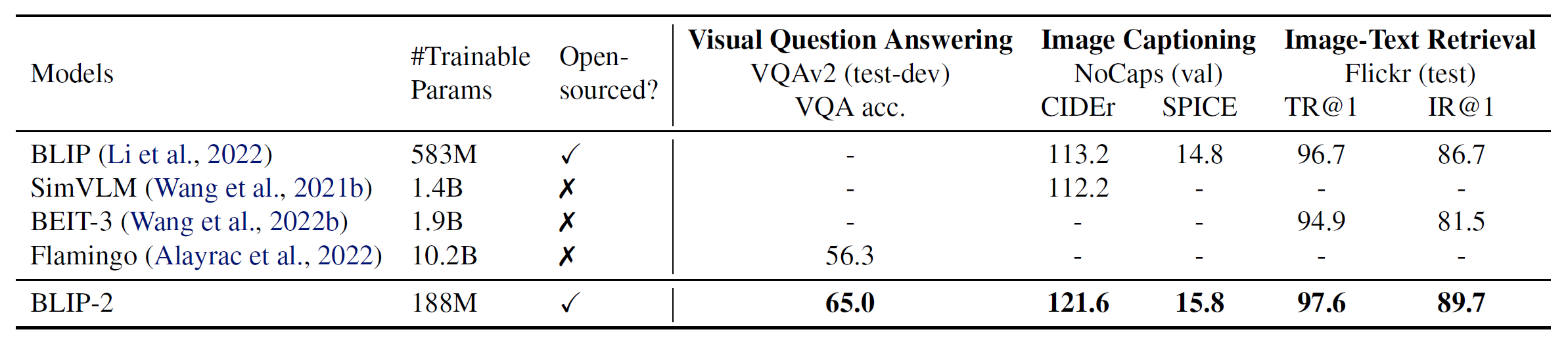
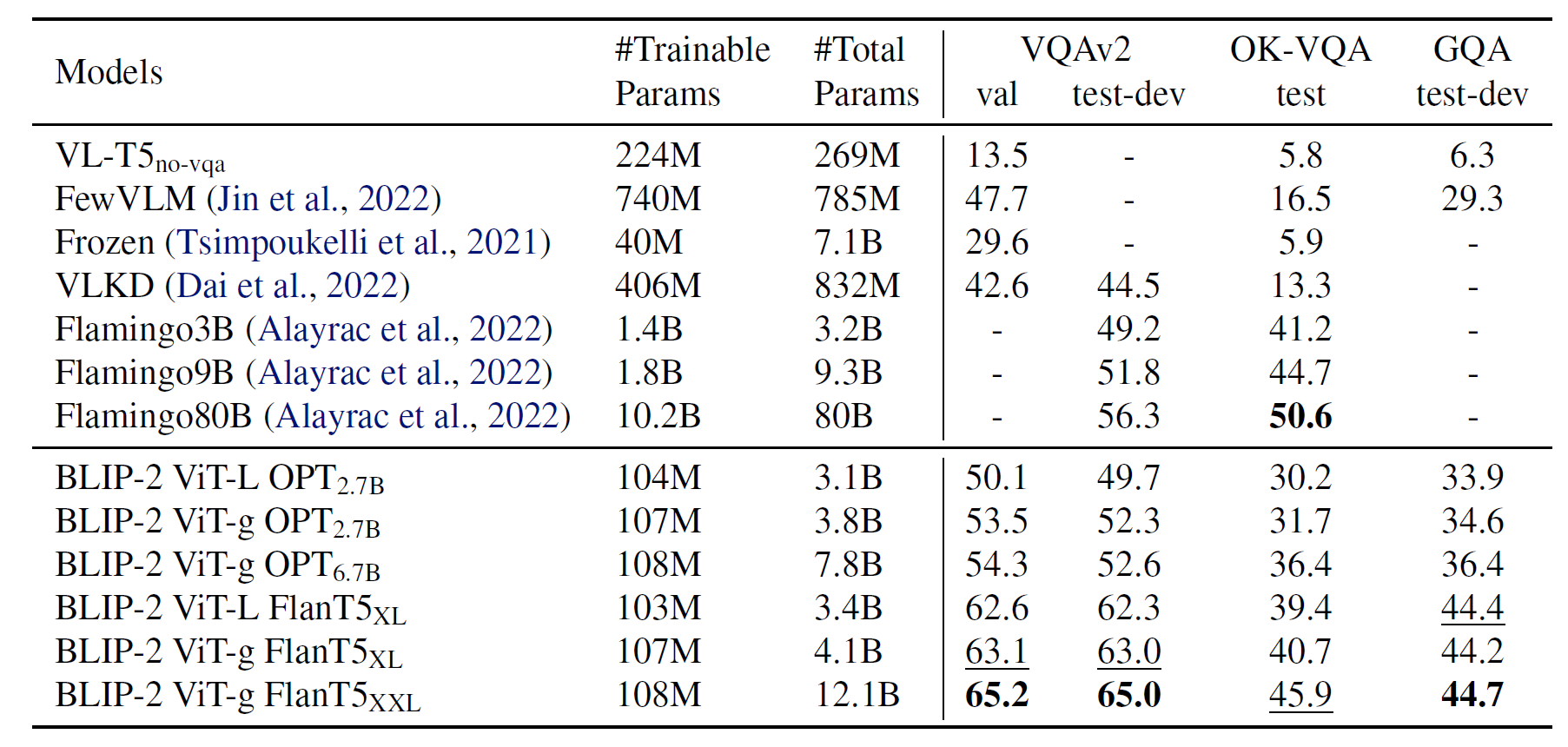
기존 모델보다 더 좋은 성능을 보여줌을 확인 가능하며, Image encoder와 LLM을 크고, 성능 좋은 것을 쓸수록 성능이 증가한다고 한다. 두번 째 그래프에서 OK-VQA에 대해 Flamingo80B보다 성능이 안나온 이유에 대해 OK-VQA는 visual understanding봐다 open-world knowledge가 더 중요하기 때문에 모델의 크기가 큰 Flamingo80B가 성능이 더 잘나왔다고 생각한다고 한다.
또한 instruction finetuning된 FlanT5모델이 unsupervised-trained OPT모델보다 성능이 잘나옴으로써 BLIP-2를 일반적으로 vision-language pretraining을 하는데 이용 가능하다고 한다. 즉 finetuning된 LLM모델에 사용해도 문제가 없다는 것.
1 stage의 효과
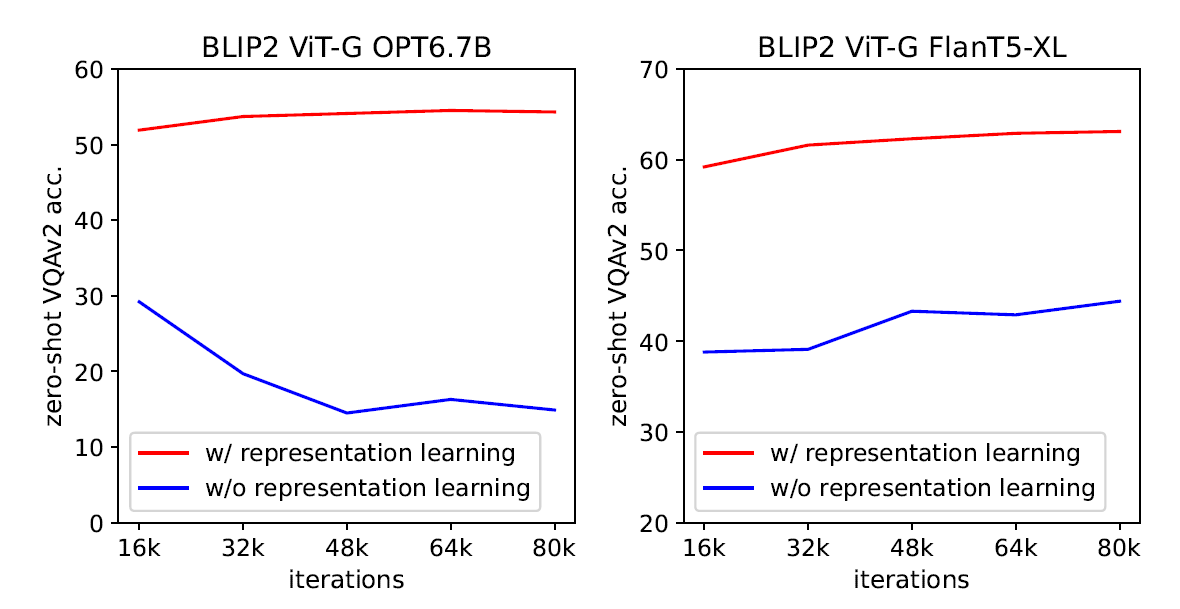
1 stage에서 이미 Q-Former가 visual feature와 text와 align하는 방법을 배우기 때문에 LLM과 학습할 때 부담이 줄어든다고 했는데, 실제로 1 stage를 하지 않았을 때에 비교해 훨 좋은 성능을 보여주는 것을 확인 가능하다. 또한 앞의 그래프를 보면 representation learning을 하지 않았을 때, 학습을 할수록 성능이 떨어지는 것을 보아 catastrophic forgetting을 방지하기 위해 1st stage는 필수라고 볼수 있다.
Finetuning
Image Captioning
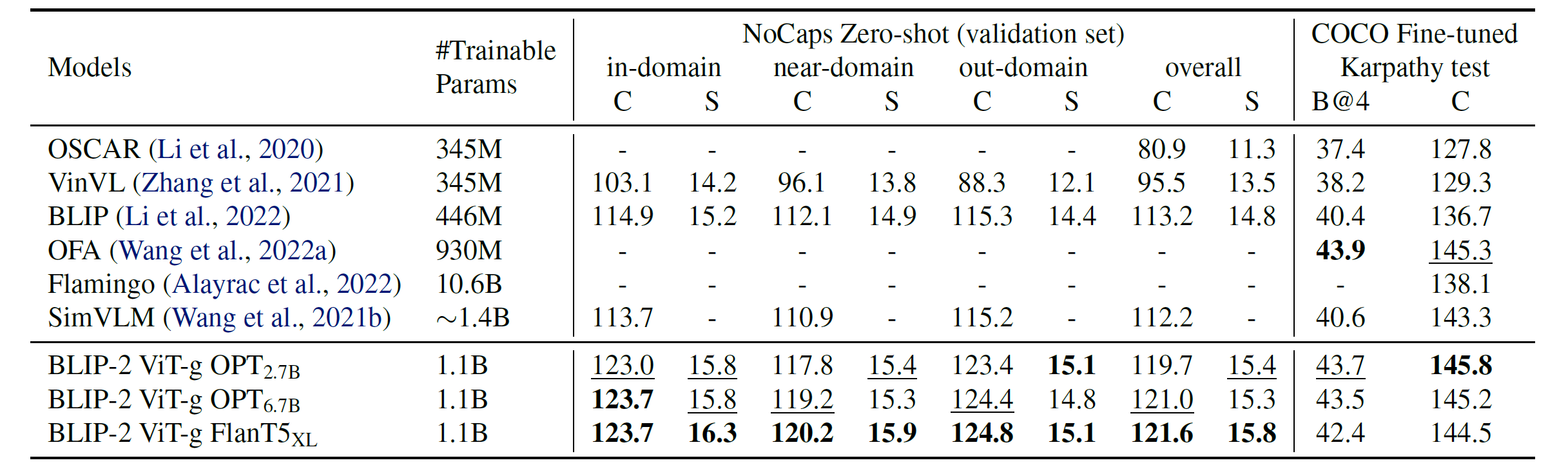
Pretrain된 BLIP-2 모델을 Image Captioning을 위해 "a photo of"이라는 prompt를 붙여 language modeling loss로 학습을 했다고 한다. 이 때 LLM은 freeze하고 Image encoder와 Q-Former를 업데이트 했다고 한다. 기존의 모델들을 outperform 함을 확인 가능하다.
Visual Question Answering
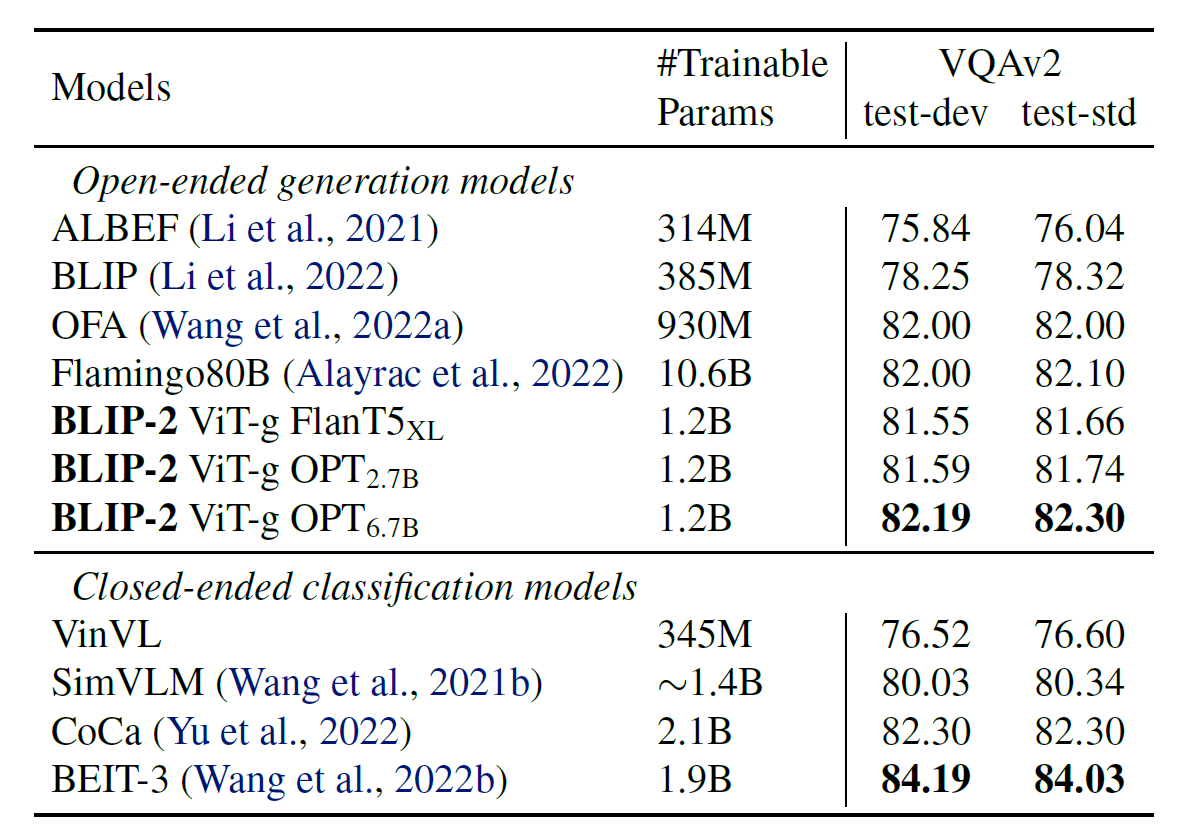
마찬가지로 Q-Former와 Image Encoder를 finetuning했다. 이 때, Q-Former에 question token을 입력으로 주어 Q-Former의 cross-attention layer에서 image의 더 informative한 영역에 집중할 수 있도록 했다고 한다. 이를 통해 BLIP-2는 open-ended generation model 중에서는 SOTA를 이뤘다고 한다.
Image-Text Retrieval
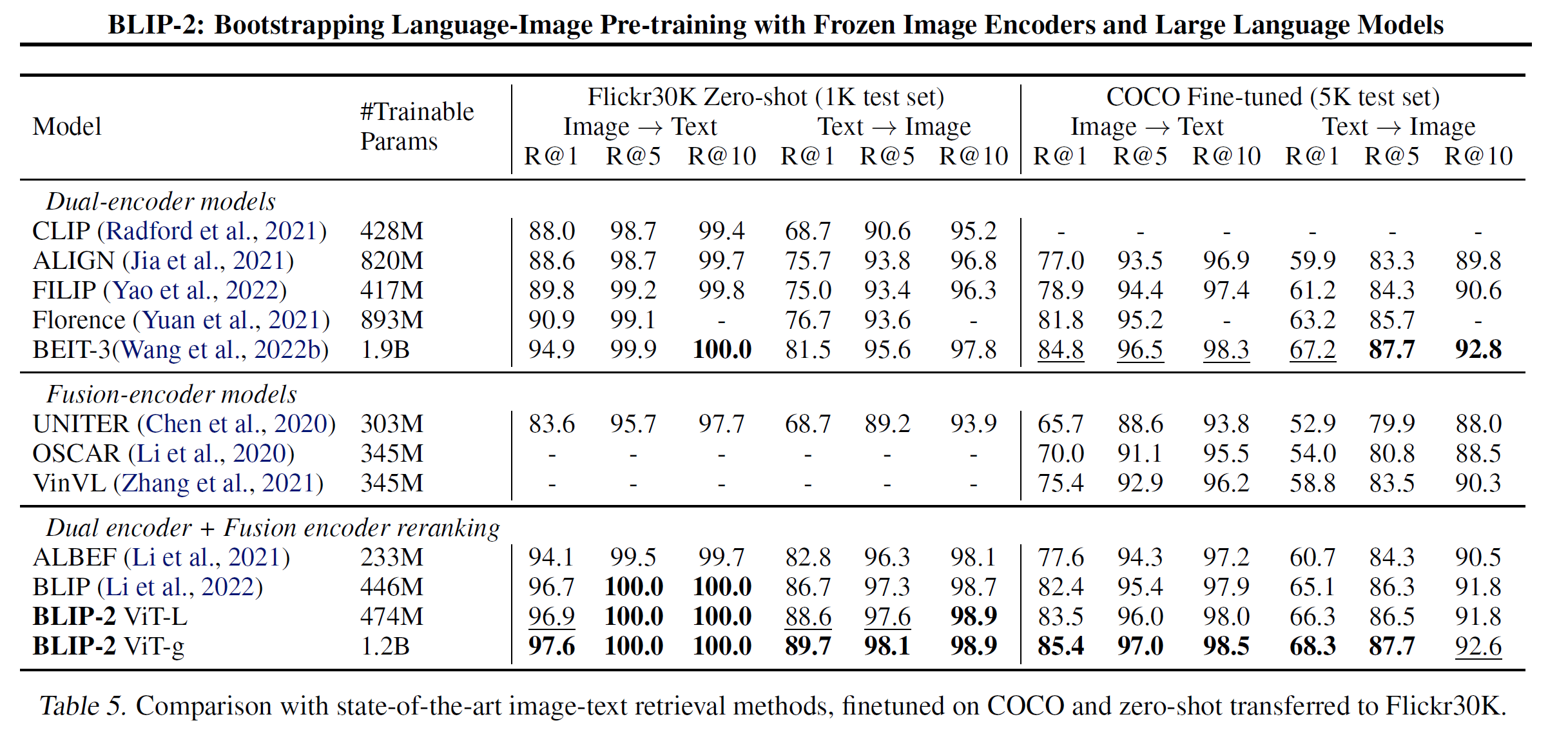
Image-Text Retrieval은 language generation을 하지 않으므로 LLM을 빼고 바로 finetuning 했다고 한다. COCO로 했다고 하고, image-text, text-image retrieval에 대해 COCO와 Flickr30K로 evaluate했다고 한다.(COCO로 finetune하고 COCO로 evaluate하는게 맞나..)
BLIP에서와 같이 similarity로 k=128개의 candidate를 뽑게 되고, ITM score로 re-ranking을 하게 된다. ITC와 ITM은 당연하게도 image-texgt retrieval에 중요한 역할을 하지만, ITG loss 또한 도움이 된다고 한다. ITG loss는 query가 visual feature을 text와 가장 가깝게 뽑아낼 수 있도록 강제하는 역할을 하기 떄문이다. 따라서 vision language alignment 향상에 도움을 준다.
한계
최근의 LLM은 in-context learning을 few-shot learning으로 할 수 있는데, BLIP-2에서 in-context VQA example을 줬을 때, 성능 향상을 확인할 수 없었다고 한다. 당연히 in-context dataset을 이용해 학습하지 않았기 때문이고, 저자들은 single sequence에 multiple image-text pair를 가진 데이터셋을 생성하는 것을 목표로 두고있다고 한다.
또한 BLIP-2의 image-to-text generation은 LLM의 부정확한 knowledge와 최근 정보를 가지고 있지 않아 불만족스러운 결과를 자주 도출했다고 한다. 또한 기존 LLM이 가지고 있는 문제도 그대로 계승했다고 한다.(hate word, social bias, private data leak 등)
