충남대학교 컴퓨터융합학부의 김동일 교수님의 기계학습을 수강한 후 정리한 글입니다.
그래서 머신러닝이 뭔데? 😐
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Tom Mitchell이 정의한 머신러닝이다. 해석해보면 성능측정 P로부터 측정된 어떤 종류의 작업(T)가 경험(E)에 의해 향상된다면 어떤 종류의 작업(T)는 경험(E)를 통해 학습을 진행한다는 의미이다.
Based on data, Algorithm that find rules, relations, and functions, To solve a real-world problem.
이건 우리 교수님이 정의하신 머신러닝이다. 훨씬 이해하기 쉽다. 데이터에 기반으로 규칙과 관계를 찾는 알고리즘으로 실제 문제를 해결한다는 의미이다.
지도학습 VS 비지도학습
지도학습, Supervised Learning 의 경우 Input 과 Output 이 있다. 다시 말해 target variable 이 있다는 말이다. 이와 반대로 비지도학습, Unsupervised Laerning 의 경우 Input 만 존재한다.
Supervised Learning
- Classification
- Regression
지도학습의 경우 위에서 말했듯이, Output 이 있기 때문에 어떤 입력 값을 줬을 때 어떤 출력 값이 나온다를 학습시키는 것이다. 이 때 Output 에 따라 Classification 이냐 Regression 이냐를 나눈다. 가령, Output 이 True or False, Male or Female, binary, Multi-category 처럼 클래스 간의 분류가 명확한 경우 Classification 으로 정의한다. 이와 다르게 Amount of Rain, Amount of sale, total sale of visiting 처럼 클래스 간의 분류가 명확하지 않고 반복된 값을 가지는 경우 Regression 이라고 한다.
Classification
클래스의 분류가 명확한 경우 Classification
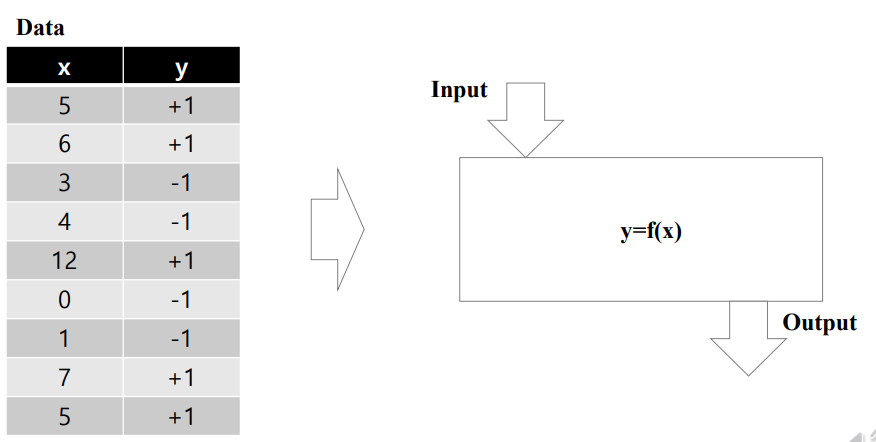
input 에 따라 서로 다른 두 개의 output 을 보여준다. 두 개의 클래스로 나타낼 수 있으므로 classification 에 해당한다.
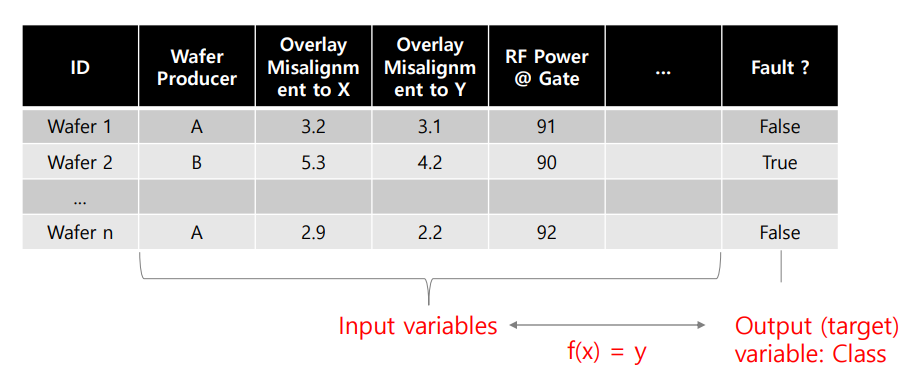
input 에 따라 서로 다른 두 개의 output 을 보여준다. 두 개의 클래스로 나타낼 수 있으므로 classification 에 해당한다.
아래는 Classification 에 해당하는 알고리즘 모델들이다.
- Bayesian classifier
- Neural networks
- Support vector machines
- Decision tree
- k-Nearest neighbors
Regression
클래스의 분류가 불명확하고 선형적인 형태를 띄고 있는 경우 Regression
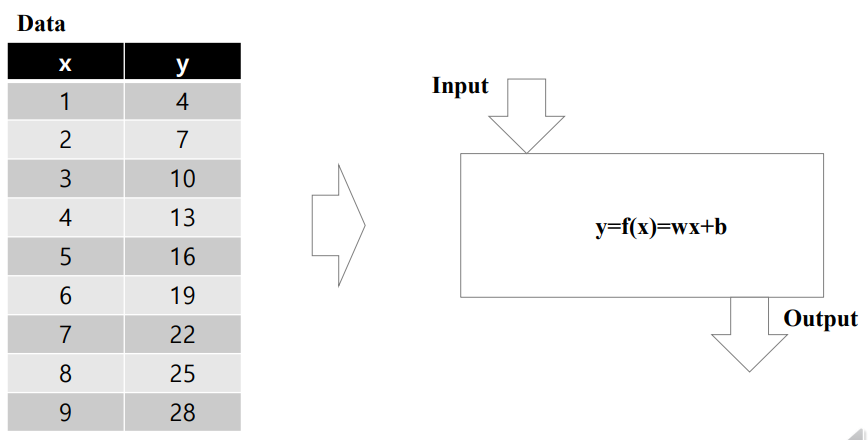
위에서 본 사진과 다르게 Output 이 선형적인(Regression) 형태를 띄고 있다. 클래스로 분류하기 매우 어렵다. Input 과 Output 을 통해 가장 적합한 방정식을 찾는다.
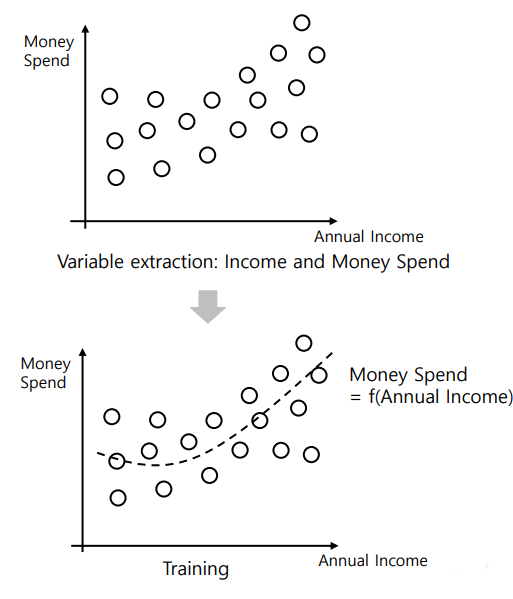
위 사진은 소득에 따른 소비 금액을 나타낸 것이다. 각 point를 가지고 가장 적합한 방정식 모델을 찾는다고 생각하면 된다.
아래는 Regression 에 해당하는 알고리즘 모델들이다.
- Linear regression
- Multivariate linear regression
- Lasso and Ridge linear regression
- Neural network regression
- Support vector regression
- Decision tree regression
Unsupervised Learning
- Clustering
비지도학습 의 경우, target 이 존재하지 않는다. "말 그대로 지도하지 않는다." 라고 생각하면 이해가 쉽다. 지도학습 에서는 "이건 A야." 이렇게 Input 과 Output 을 모두 제공하고 이들 사이의 관계를 찾아내는 것이였다면, 비지도학습 에서는 Input 만 존재한다.
Clustring
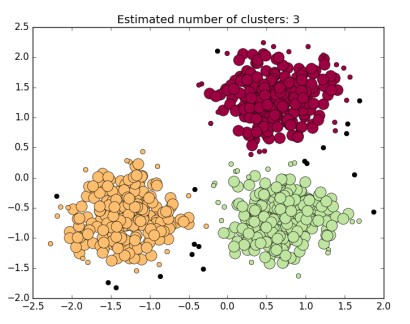
Clustring 은 Input 을 군집화를 하는 것이다. Input 개체들을 일정한 그룹으로 군집화하는 과정을 통해 군집 내부의 개체들은 서로 가깝거나 비슷하고, 서로 다른 클러스터 간의 개체들은 서로 멀거나 비슷하지 않게 하는 것이 군집화의 목표이다.
