Machine Learning by professor Andrew Ng in Coursera
1) Error Metrics for Skewed Classes
Cancer classification example
logistic regression모델을 훈련시켰더니 에러율이 1%밖에 되지 않았다.
즉 99%의 정확도를 가진다는 것이다.
하지만 이때 0.5%만이 암환자 였다면?
애초에 암환자의 비율이 상대적으로 적었기 때문에 에러율은 낮을 수 밖에 없었던 것이다.
이런 경우를 skewed classes라고 한다.
'정확도는 매우 높고 에러율은 작을 수 밖에 없다.'
적절한 성능 측정 지표가 필요하다.
Precision/Recall
이때 우리가 감지하려는 rare class를 y=1로 설정한다.
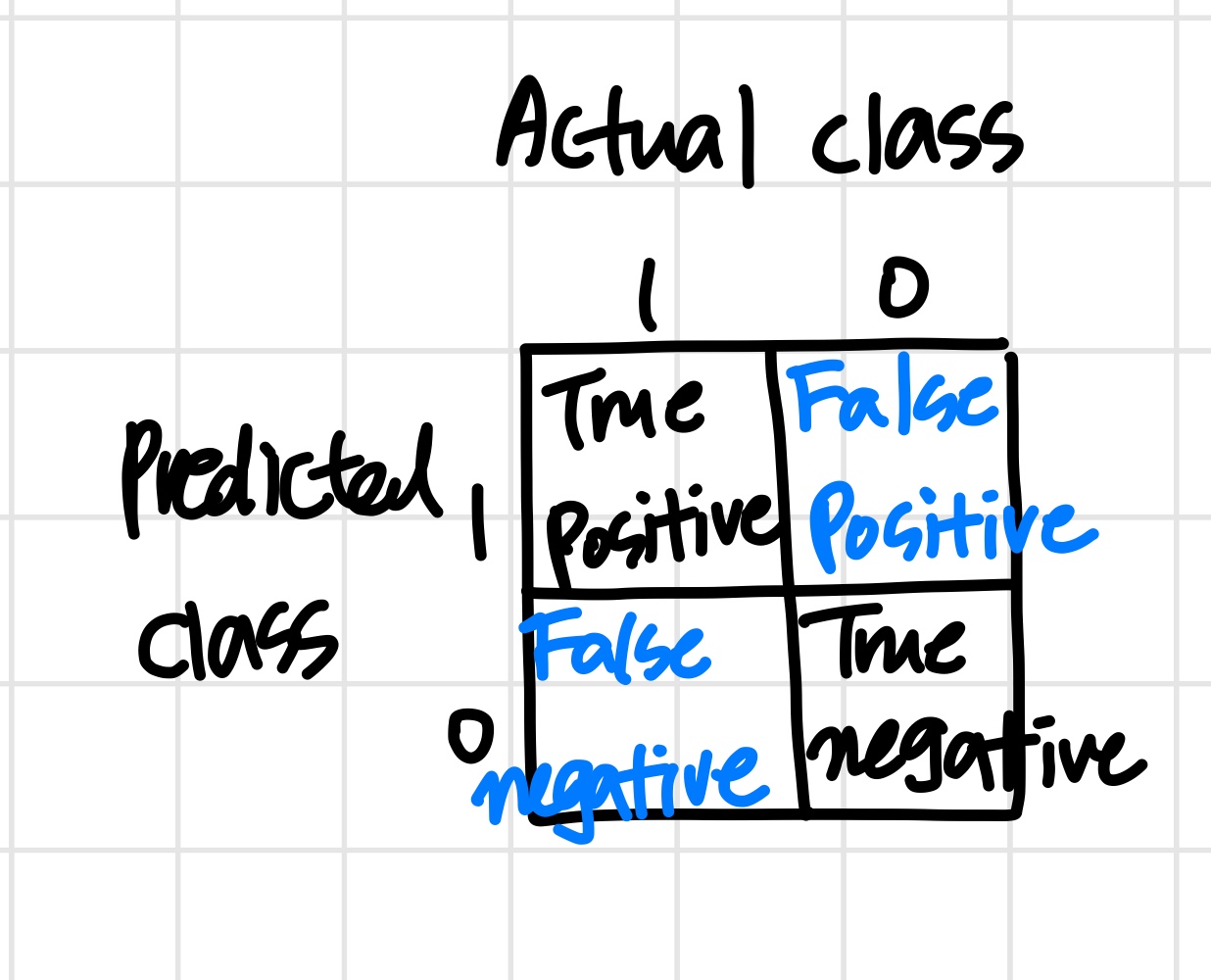

- Precision : y=1로 예측된 것 중 진짜 True인 것
- Recall : 실제 True인 것 중 y=1로 예측까지 된 것
Precision과 Recall이 모두 높다면 알고리즘이 잘 동작하고 있는 것을 의미한다.

Trading Off Precision and Recall
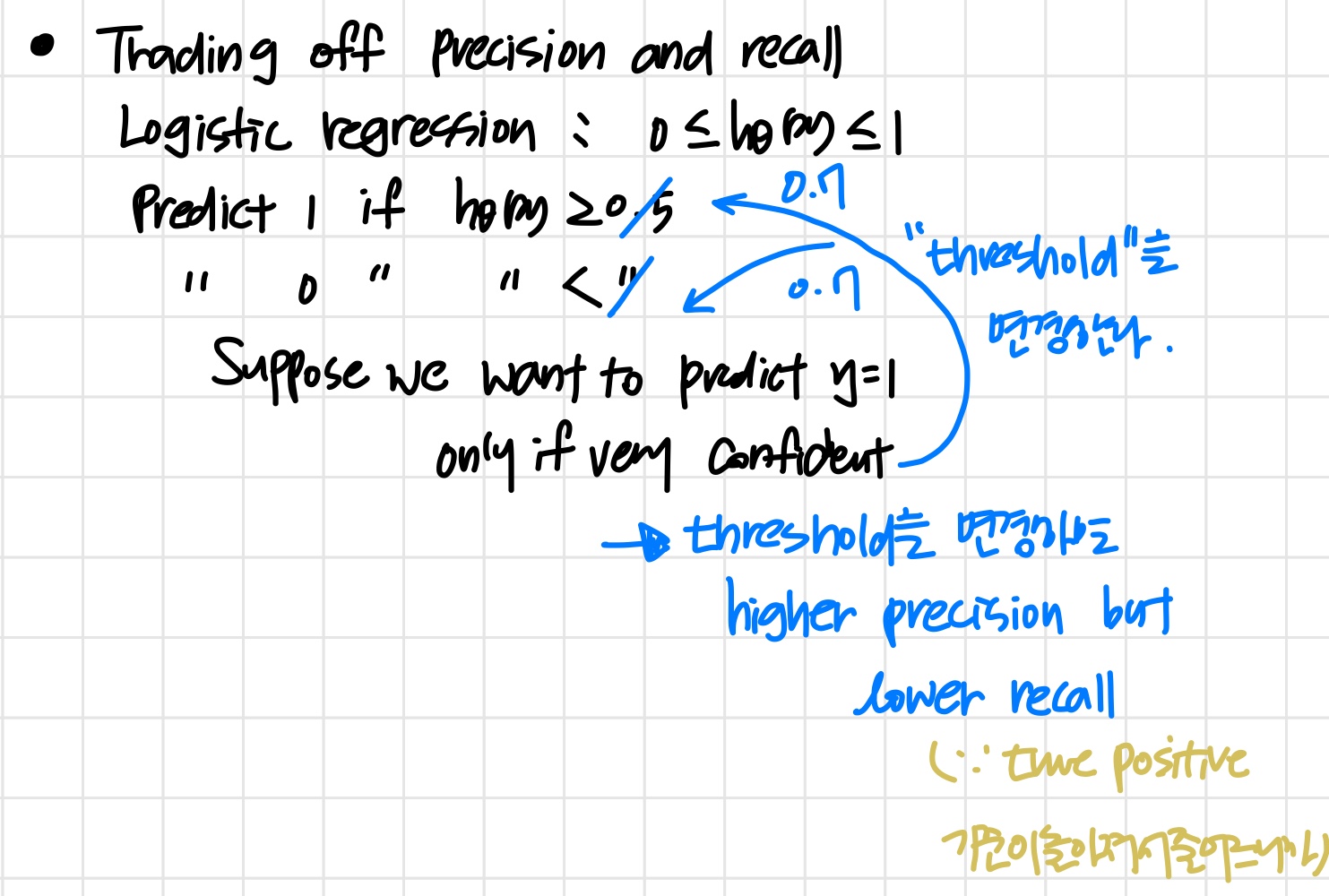
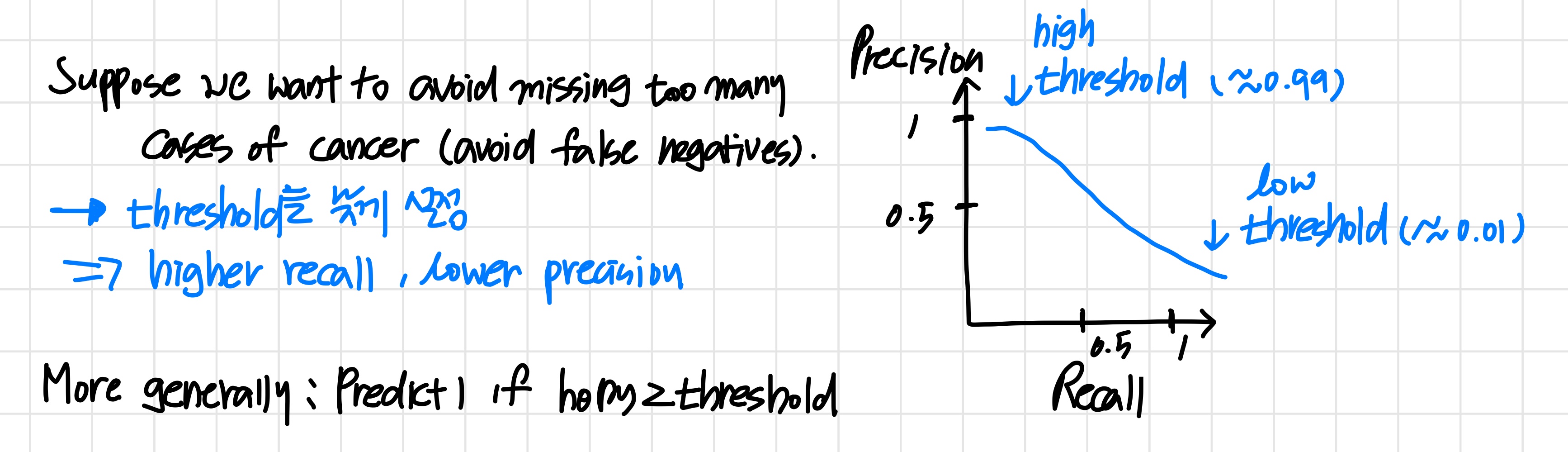
'threshold를 더 높은 값으로 변경하면 true positive의 기준이 높아진다.'
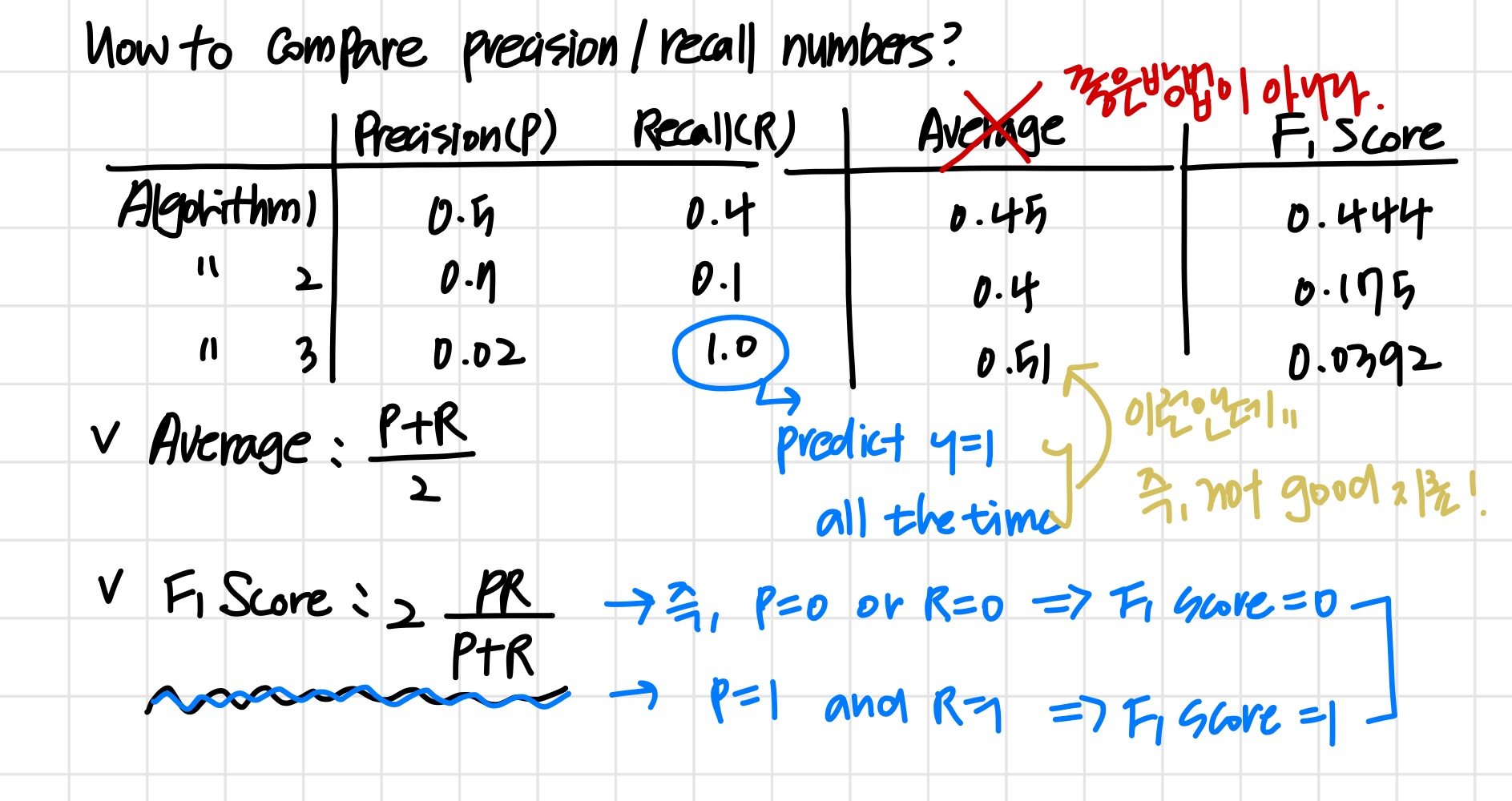
F1 Score (F Score)

개똥이