Machine Learning by professor Andrew Ng in Coursera
1) Data For Machine Learning
몇몇 알고리즘들은 training set 크기가 커질수록 정확도가 높아진다.
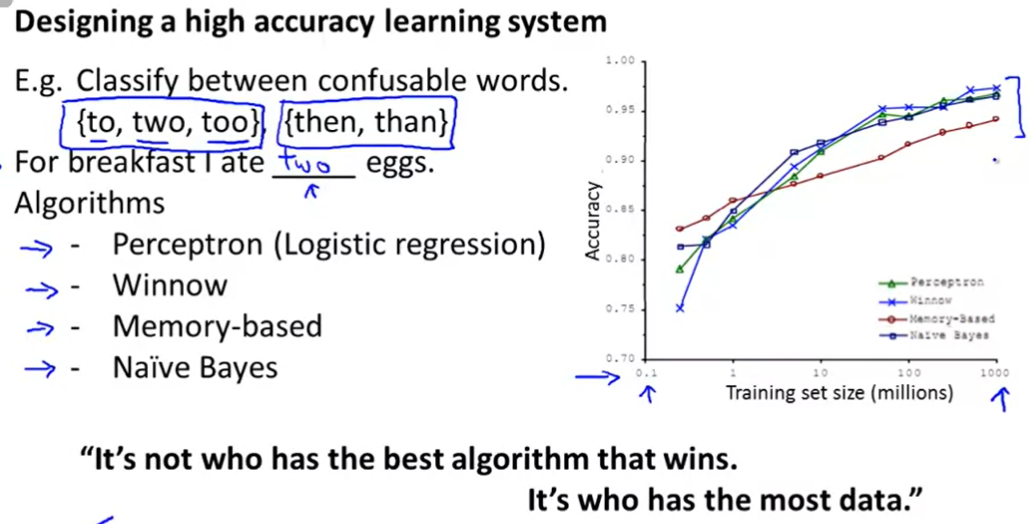
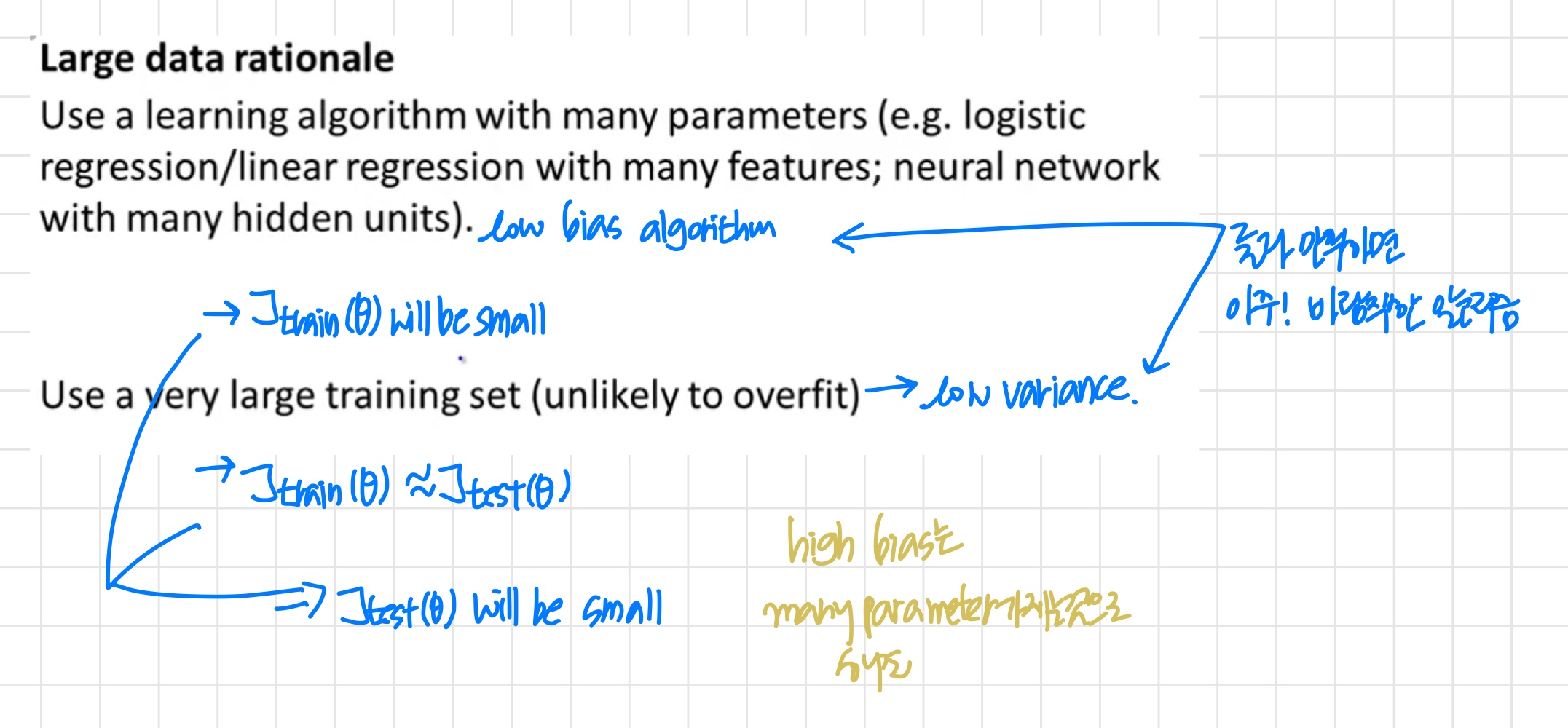
'training set가 매우 크기 때문에 parameter가 많더라도 overfit되지 않는다.'
it's a key ingredients of assuming that the features have enough information and we have a rich class of functions that's why it guarantees low bias,
and then it having a massive training set that that's what guarantees more variance.

개똥이