Smilegate Devcamp내에서 프로젝트를 하면서 겪었던 트러블 슈팅과 이에 대해 고민했던 글입니다.
빠른 코드 통합 및 자동 검증을 위해, GitHub Actions 내에서 pnpm과 Turborepo를 활용하여 Lint, build, type-check 등의 프로세스를 그룹화하여 CI 파이프라인을 구축했습니다. 하지만 초기 파이프라인 설계에서는 몇 가지 성능 병목이 발생했고, 이를 해결하기 위해 여러 단계의 최적화를 거쳤습니다. 이번 글에서는 CI/CD 환경을 최적화하는 과정과 성능 개선 결과를 정리해보겠습니다.
초기 CI/CD의 문제점
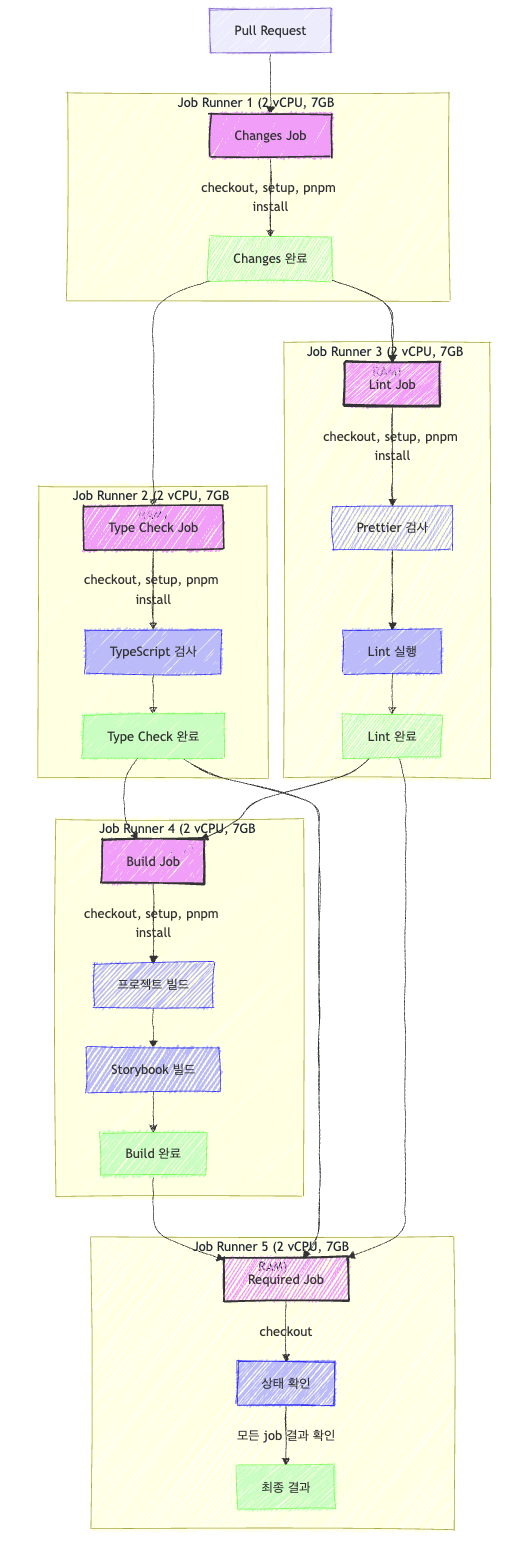
- Job Runner 리소스 할당:
- 각 job(
changes,type-check,lint,build,required)은 별도의 ubuntu-latest 러너에서 실행됩니다. - GitHub Actions의
ubuntu-latest러너는 기본적으로 2-core CPU, 7GB RAM, 14GB SSD를 제공합니다.
- 비효율적인 리소스 활용:
- 각 job마다 새로운 환경을 설정하고 있습니다(
actions/checkout,pnpm/action-setup, 의존성 설치 등). - 모든 job에서 pnpm install을 반복 실행하고 있습니다.
- 작업 간에 캐시를 공유하려고 시도하지만, 매번 새 환경을 설정하는 오버헤드가 있습니다.
- 병렬성과 의존성 문제:
type-check와lint는changes완료 후 병렬로 실행될 수 있지만, 각각 별도의 러너에서 실행됩니다.build는changes,lint,type-check모두 완료될 때까지 기다려야 합니다.required는 모든 작업이 완료될 때까지 기다린 후 상태를 확인합니다.
- 메모리 관리 문제:
- 각 job에서
NODE_OPTIONS: --max-old-space-size=4096설정은 메모리 제한을 4GB로 설정하지만, 이는 7GB RAM 환경에서 여전히 제한적입니다.
- 불필요한 중복 작업:
- 모든 job에서 코드 체크아웃과 환경 설정을 반복합니다.
- 각 단계마다
pnpm install을 실행하므로, 의존성 설치 시간이 중복됩니다.
- 파이프라인 구조의 비효율성:
needs구문을 통해 작업 간 의존성을 설정하지만, 이로 인해 병렬 처리의 이점이 감소합니다.requiredjob이 모든 작업 상태를 확인하기 위해 별도의 러너를 사용하는 것은 리소스 낭비입니다.
1차 최적화
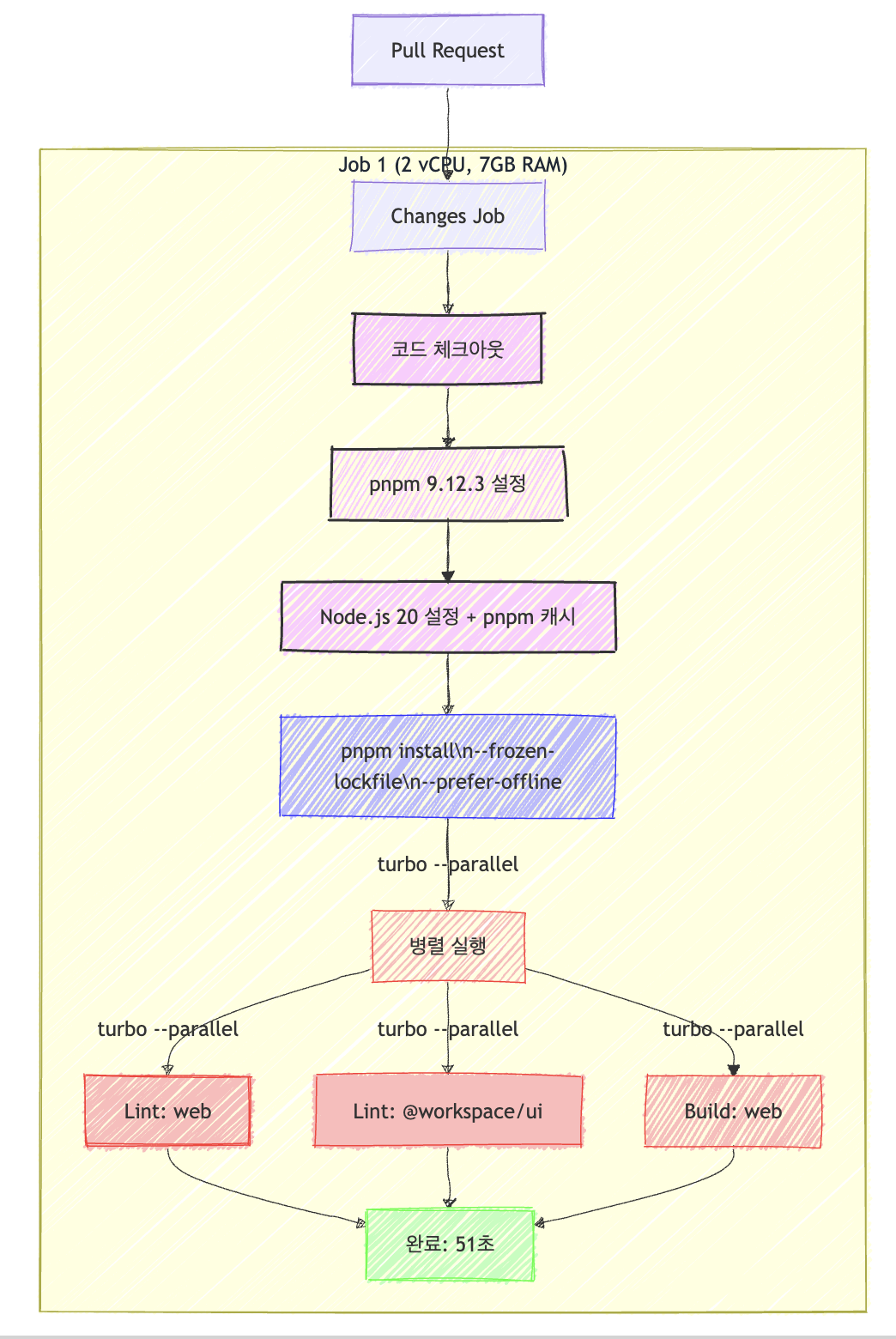
- 단일 Job Runner로 통합:
- 모든 작업이 하나의 ubuntu-latest 러너에서 실행되어 환경 설정 중복을 제거하였습니다.
- 효율적인 캐싱:
actions/setup-node의 캐시 기능 활용하였습니다. (cache: 'pnpm')- 명확한 캐시 의존성 경로 지정하였습니다. (
cache-dependency-path) - 오프라인 모드 선호 (
--prefer-offline)로 네트워크 요청 최소화하였습니다.
- Turborepo를 활용한 병렬 실행:
--parallel플래그로 가능한 작업을 동시에 실행하였습니다.--filter옵션으로 필요한 패키지만 선택적으로 처리하였습니다.
- 간소화된 프로세스:
type-check는 제외하고 중요 작업인lint와build에만 집중하였습니다.- 불필요한 반복 작업과 중간 확인 단계 제거하였습니다.
- 타임아웃 설정 최적화:
- 타임아웃을 15분에서 10분으로 줄여 불필요한 러너 사용 시간 방지하였습니다.
🧐 1차 개선 후 여전히 발생했던 문제점 및 고민들
CI 시간내에서 51s가 그렇게 빠르다고 매력적으로 다가오지 못했었고 여전한 하나의 job runner가 3개의 task가 전부 돌아간다라고 파악을 했기 때문에 오히려 메모리 경합(memory contention)과 리소스 사용 비효율성이 발생한다고 생각했습니다.
🔍 세부 분석
- 하나의 Job Runner에서 3개의 Task가 동시에 실행됨 → 리소스 경합 발생
- CI/CD 환경에서 논리 CPU 2개, 7GB RAM을 가진 GitHub Actions Runner는 기본적으로 멀티태스킹이 제한적입니다.
- Lint, Build, Type-Check를 동시에 실행하면 CPU 및 메모리를 경쟁적으로 사용하게 되
며, 컨텍스트 스위칭이 과도하게 발생합니다.
- 과도한 컨텍스트 스위칭으로 인한 성능 저하
- OS 스케줄러는 각 태스크를 번갈아 실행하며 컨텍스트 스위칭(Context Switching)을 수행합니다.
- 이 과정에서 CPU가 태스크 상태를 저장/복구하는 오버헤드가 발생하여 실행 시간이 늘어납니다.
메모리 누수(Memory Leak) vs 메모리 경합(Memory Contention)이란?
- 메모리 누수(Memory Leak): 프로그램이 사용한 메모리를 해제하지 않아 점점 늘어나는 현상
- 메모리 경합(Memory Contention): 여러 프로세스가 한정된 메모리를 공유하면서 경쟁하는 현상
➡️ 결과적으로 CI 속도가 드라마틱하게 개선이 되지 않았습니다.
2차 최적화
이후 테스트 코드를 점진적으로 작성을 하게 되면서 CI 시간은 다시 1분 14초대로 늘어나게 되어버렸습니다. 그래서 추가적인 개선이 필요했고 두 번째 개선을 진행하였습니다.
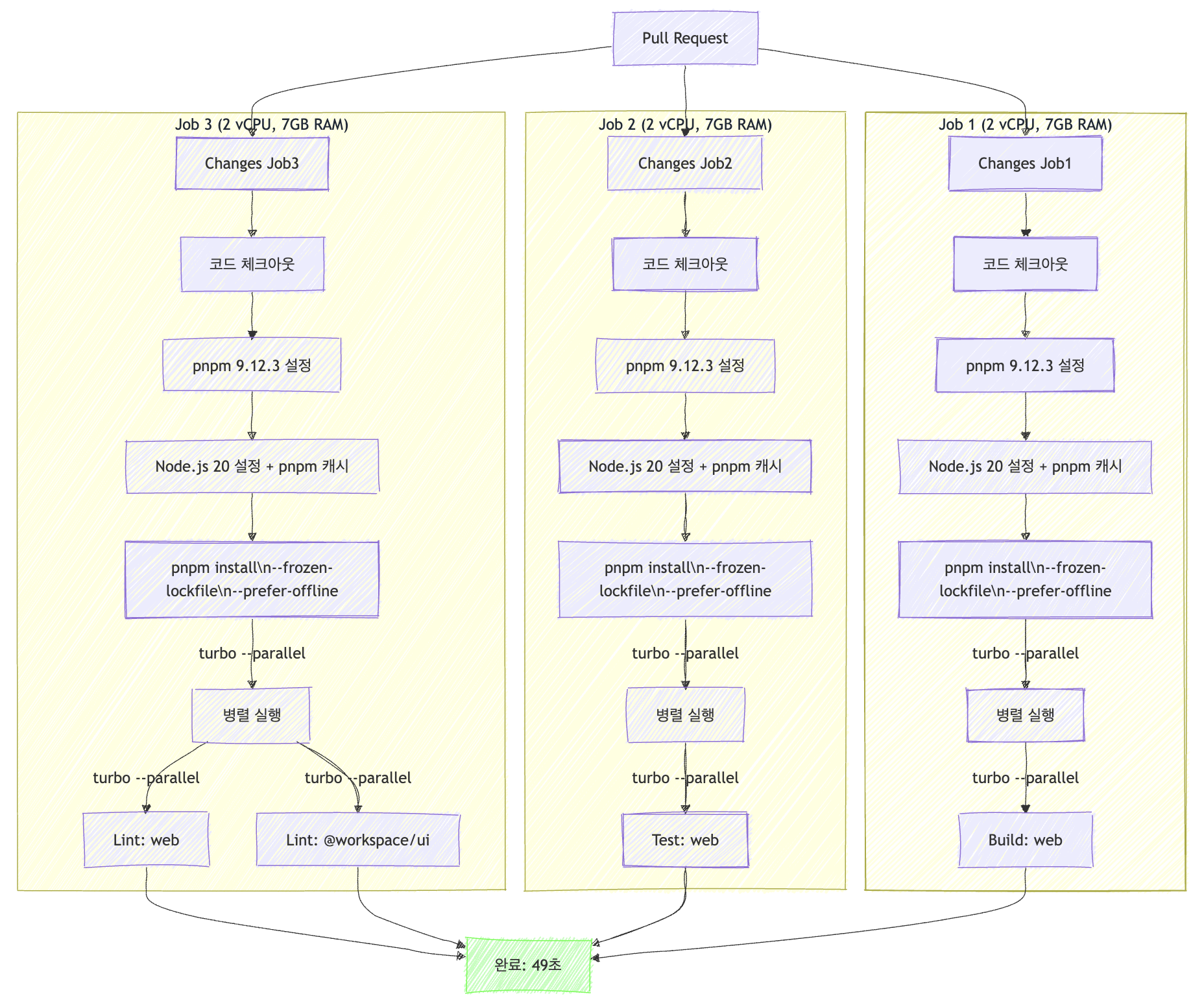
- 3개의 Job Runner로 분리:
- 모든 작업을 각각의 job runner로 분리하여 ubuntu-latest 러너에서 실행되어 메모리 경합과 CPU Bound의 작업 처리 내에서 오버헤드가 발생하지 않도록 하였습니다.
- 효율적인 캐싱:
actions/setup-node의 캐시 기능 활용하였습니다. (cache: 'pnpm')- 명확한 캐시 의존성 경로 지정하였습니다. (
cache-dependency-path) - 오프라인 모드 선호 (
--prefer-offline)로 네트워크 요청 최소화하였습니다.
- Turborepo를 활용한 병렬 실행:
--parallel플래그로 가능한 작업을 동시에 실행하였습니다.--filter옵션으로 필요한 패키지만 선택적으로 처리하였습니다.
- 간소화된 프로세스:
type-check는 제외하고 중요 작업인lint와build에만 집중하였습니다.- 불필요한 반복 작업과 중간 확인 단계 제거하였습니다.
- 타임아웃 설정 최적화:
- 타임아웃을 15분에서 10분으로 줄여 불필요한 러너 사용 시간 방지하였습니다.
3차 최적화
2차 최적화 이후 49s까지 최적화하였으나 결국 build랑 test같은 경우 각 job runner 하나씩 job하나를 처리하고 있으므로 idle 상태가 생긴다고 판단했었습니다. 그래서 태스크 작업의 각 특성을 파악하여 새롭게 추가적으로 최적화를 진행하였습니다.
- 2개의 Job Runner로 분리:
- test와 lint같은 경우 I/O Bound에 해당한다고 생각했고 build 같은 경우 CPU Bound라고 생각했기 때문에 test와 lint는 하나의 job runner로 같이 묶었고 matrix를 활용하여 git action내에서 병렬 실행할 수 있도록 하였습니다. Build는 온전히 하나의 job runner에 분배하여 vCPU 2개를 온전히 할당하도록 하였습니다.
- 효율적인 캐싱:
.turb캐시를 추가하였습니다.
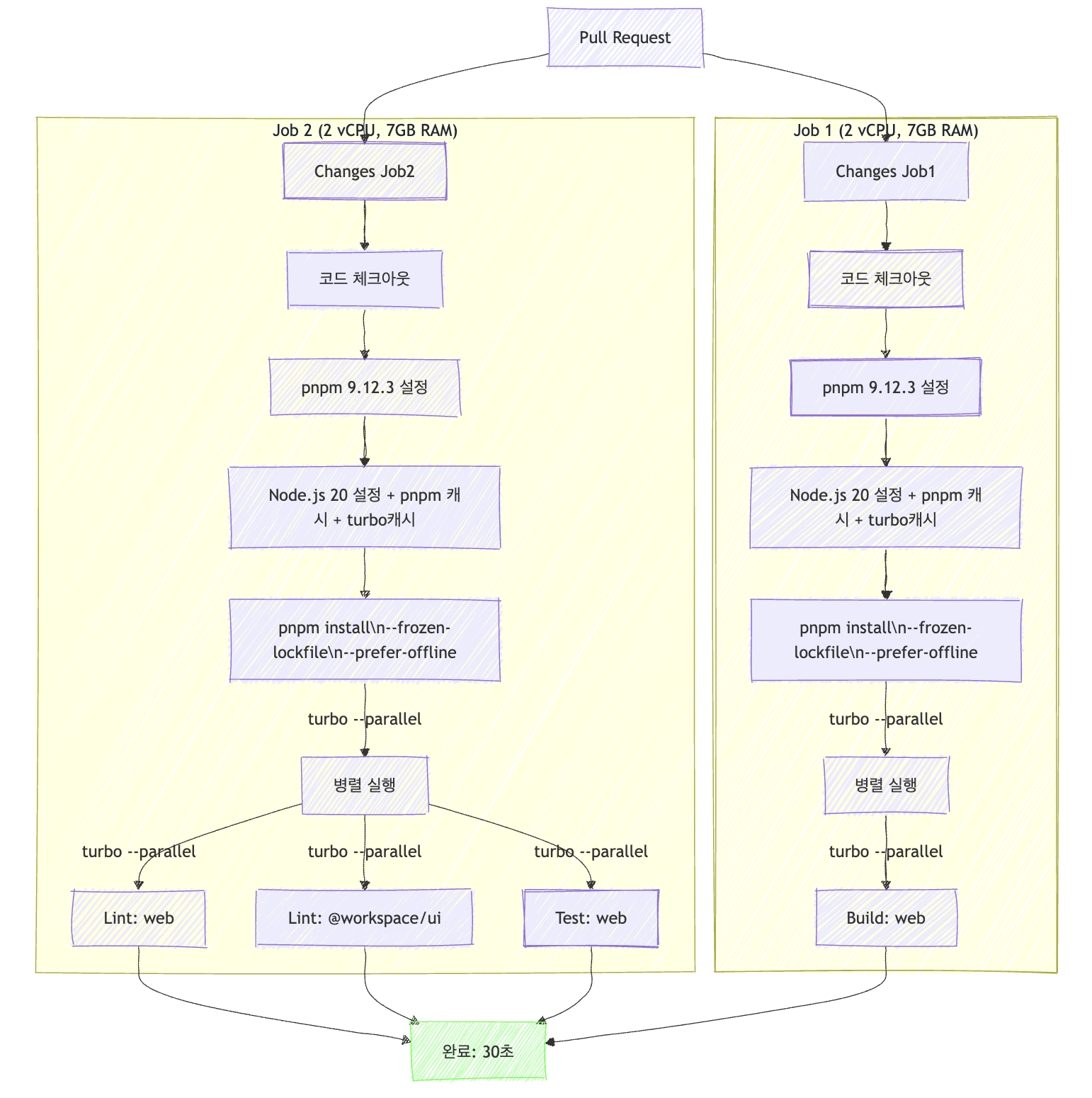
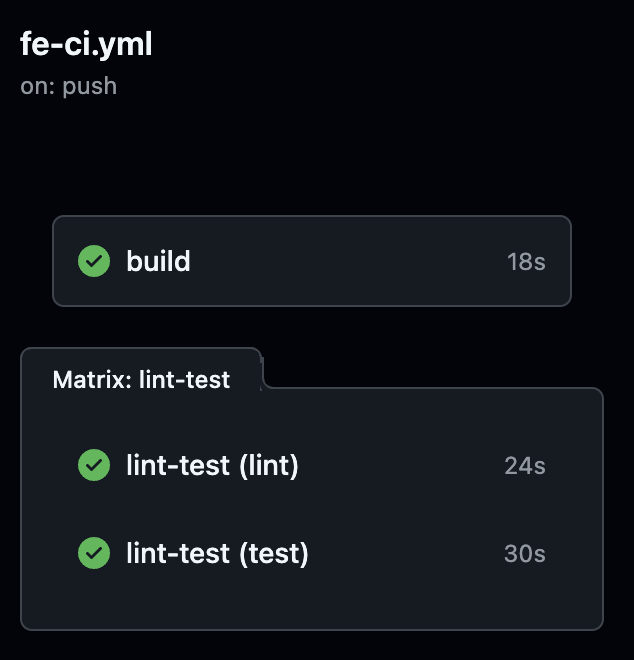
🚀 결과적으로 30s까지 최대 29s까지 개선할 수 있었습니다!!!
🔍 3차 개선에서 찾아보고 고민했던 내용들
1. CPU Bound와 IO Bound가 뭔가요?
CPU Bound와 IO Bound는 컴퓨터 프로그램이나 작업의 성능 병목 현상이 어디에서 발생하는지 설명하는 용어입니다.
CPU Bound (CPU 바운드)
- CPU의 처리 능력에 제한을 받는 작업입니다.
- 주로 복잡한 계산, 알고리즘 실행, 데이터 처리와 같은 연산 집약적 작업입니다.
- 특징: CPU 사용률이 높고(종종 100%에 가까움), CPU가 더 빠르면 작업 속도가 향상됩니다.
IO Bound (입출력 바운드)
- 입출력 작업(디스크, 네트워크, 데이터베이스 등)에 제한을 받는 작업입니다.
- 주로 데이터를 읽고 쓰는 작업으로, 이 과정에서 CPU는 대부분 대기 상태입니다.
- 병렬 작업을 할수록 성능이 향상됩니다.
- 특징: CPU 사용률이 낮고, 더 빠른 스토리지, 네트워크, 또는 IO 시스템으로 성능이 향상됩니다.
🧐 CI/CD 파이프라인에서 판단한 기준은요?
lint와test는 주로 많은 파일을 읽고 간단한 검증을 수행하므로 IO Bound에 가깝다라고 판단했습니다.- Code
build, Bundling, Optimization은 복잡한 변환을 수행하므로 CPU Bound에 가깝습니다.
2. 🧐 Lint, Test를 하나의 job runner에 분배하면 메모리 경합과 리소스 경합이 일어나는것 아닌가요?
IO Bound의 핵심 특성
- IO Bound 작업은 CPU를 100% 활용하지 않습니다. 대부분의 시간은 파일을 읽거나 쓰는 것을 기다리는 대기 시간입니다.
- CPU가 한 작업에서 IO를 기다리는 동안, 다른 작업을 처리할 수 있습니다.
- 예를 들어 lint:web이 파일을 디스크에서 읽는 동안, CPU는 test:web 작업을 진행할 수 있습니다.
리소스 활용의 상보성
- IO Bound 작업은 다른 시스템 리소스(디스크 IO, 네트워크)를 주로 사용합니다.
- 이런 작업들이 동시에 실행되면 CPU, 메모리, IO를 골고루 활용하게 됩니다.
- 작업들이 서로 다른 리소스를 주로 사용하므로 경합이 적습니다.
Turborepo의 최적화
- Turborepo는 태스크 간의 의존성을 스마트하게 관리하고 병렬 실행을 최적화합니다.
- 내부적으로 작업 스케줄링을 효율적으로 처리하여 리소스 활용도를 높입니다.
--parallel플래그를 사용하면 가능한 한 많은 태스크를 동시에 실행하면서도 리소스 제약을 고려합니다.
캐싱의 영향
- Turborepo 캐시는 이전에 실행한 작업의 결과를 저장하여 변경되지 않은 파일에 대한 작업을 건너뜁니다.
- 이로 인해 파일 시스템 IO가 크게 줄어들고, 실제로 필요한 작업만 수행됩니다.
🔍 모던 운영체제의 스케줄링
현대 운영체제는 IO 작업과 CPU 작업을 효율적으로 스케줄링하도록 설계되어 있습니다.
IO 대기 시간 동안 다른 프로세스에 CPU를 할당하는 것을 잘 처리합니다.
2개의 vCPU 환경에서도 여러 IO Bound 작업을 효율적으로 멀티태스킹할 수 있습니다.
🎊 결론
- 따라서
lint:web,lint:@workspace/ui,test:web과 같은 IO Bound 작업들은 하나의 Job Runner에서 동시에 실행되어도 서로 크게 방해하지 않고, 오히려 시스템 리소스를 더 효율적으로 활용할 수 있습니다. - 반면 CPU Bound 작업인
build는 별도의 Job Runner에서 실행하는 것이 더 효율적입니다.
참고했던 자료
- Git Action 워크플로우 및 청구 : https://docs.github.com/ko/enterprise-cloud@latest/actions/administering-github-actions/usage-limits-billing-and-administration
- CPU Bound & IO Bound : https://velog.io/@carrykim/%EB%B6%84%EC%82%B0-%EC%8B%9C%EC%8A%A4%ED%85%9C-2-3.-CPU-Bound-IO-Bound
최적화를 통한 본인 회고
2차 개선 이후 3차 개선을 진행하면서 운영체제의 특성을 고려한 최적화를 적용했습니다. 이 과정에서 제가 설정한 한계를 깨고 더 나은 방향으로 개선함으로써 큰 성취감을 느꼈습니다. 동시에 이전에 제한된 지식으로 쉽게 만족하려 했던 점을 반성하게 되었습니다. 시스템 최적화에는 CS 기초 지식이 얼마나 중요한지 실감했고, 이를 계기로 CS 공부를 더욱 깊이 있게 진행할 예정입니다.
