[2024.06.06] AGENTGYM: Evolving Large Language Model-based Agents across Diverse Environments
[2025.09.10] AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn RL
[GitHub] WooooDyy/AgentGym-RL
제안 배경
-
보통 expert demo나 정교한 프롬프트에 기반한 SFT에 크게 의존하는데, 이들은 보통
- 상호작용의 깊이가 제한되며
- Exploration-Exploitation 간의 균형이 불안정하고
- 학습 안정성을 유지하면서 다양한 환경을 처리할 수 있는 포괄적이고 모듈화된 프레임워크가 없음
-
AgentGym-RL 프레임워크로 위 문제들을 해결
- AgentGym-RL은 24년 6월에 발표됐던 AgentGym이라는 바이트댄스의 에이전트 학습 프레임워크에 VERL 기반 RL 학습 프레임워크를 달아준 형태
- 그래서 레포를 확인해보면 AgentGym 이외의 레포는 생각보다 굉장히 단순하게 생겼음
방법론
모듈 구성
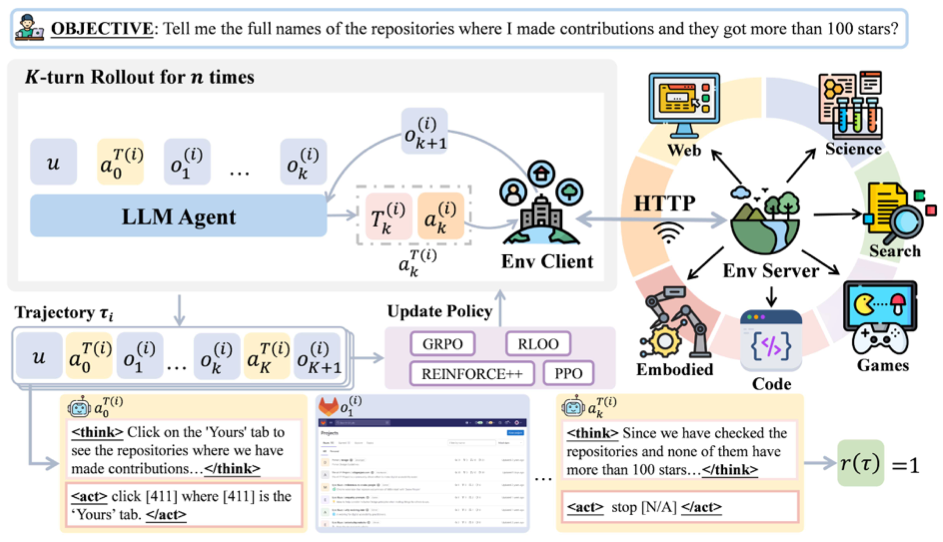
AgentGym-RL은 extensible한 에이전트 학습 프레임워크로, 3개의 독립 모듈로 구성됨
환경 모듈
에이전트의 다양한 측면을 테스트하는 5개 시나리오를 제공
- WebArena: HTML 구조 및 사용자 인터페이스 이해가 필요한 웹 탐색
- DeepSearch: 정보 수집 및 합성 관련 검색 증강 생성
- TextCraft: 명확한 규칙과 목표가 있는 디지털 게임
- BabyAI: 공간 추론 및 계획이 필요한 grid-world 구현
- SciWorld: 복잡한 추론 및 도구 사용이 필요한 과학 실험 작업
- 위 5개 환경이 HTTP API 형태로 독립적 서비스로 작동하며 병렬 실행 및 확장을 가능하게 함
에이전트 모듈
- 에이전트 내 orchestrator 모듈
- 일반 ReAct와 다른건 planning과 reflection 메커니즘을 따로 지원한다는 것인듯
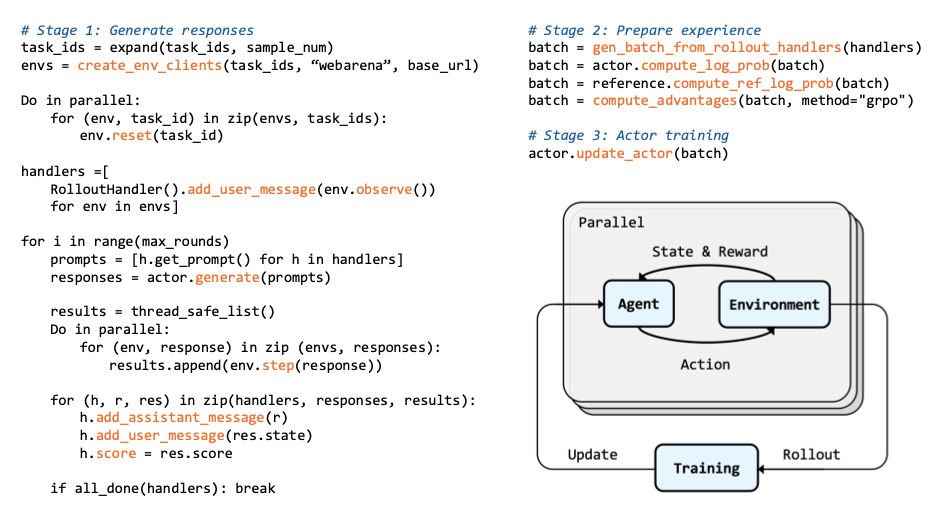
학습 모듈
- PPO, GRPO, RLOO, REINFORCE++ (PPO의 여러 기법을 포함한 REINFORCE) 등의 여러 알고리즘들을 포괄 지원하는 파이프라인
- Parallel environment 인스턴스에서, (1) trajectory batch 수집, (2) advantage 계산, (3) policy 업데이트를 수행
- 메모리 효율성을 보장하고 각 환경의 고유 task를 처리하는 엔지니어링 최적화 모듈? 기능?도 있다고 함
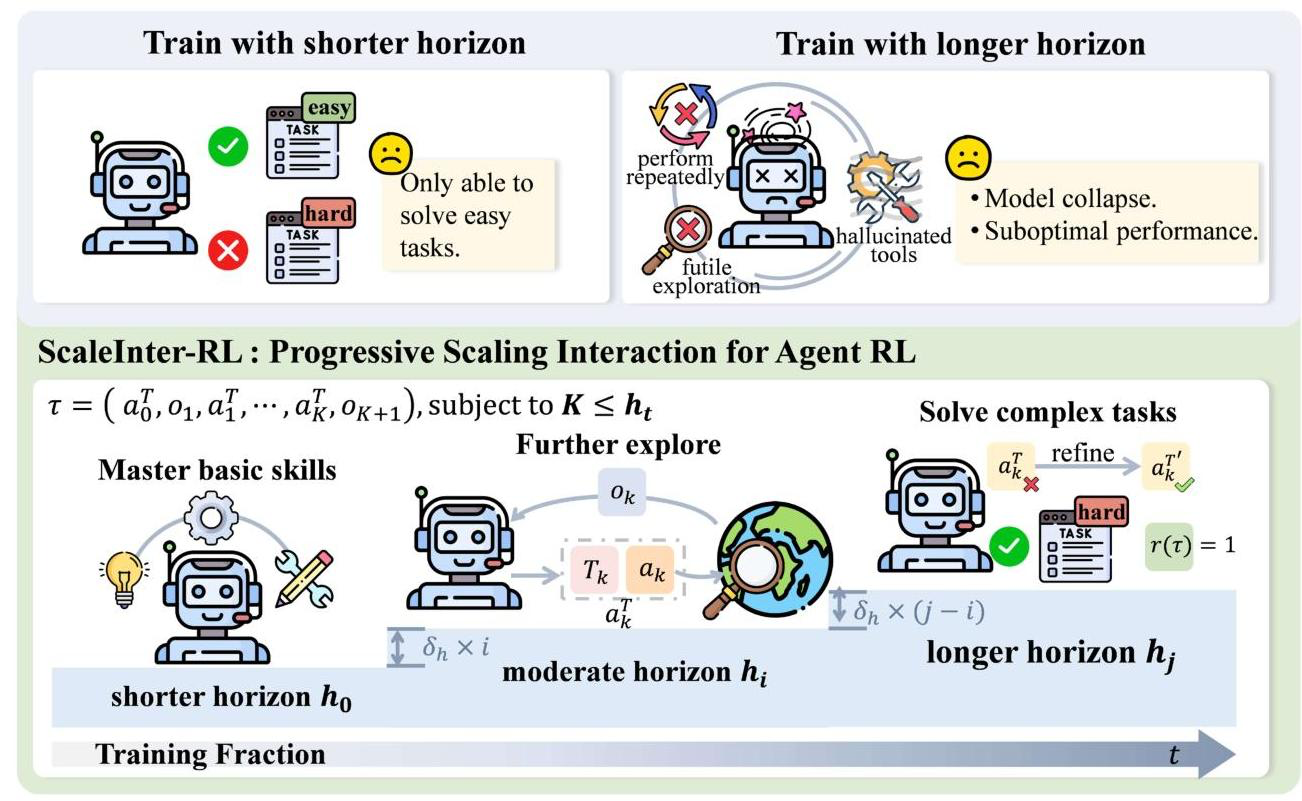
ScalingInter-RL: 점진적 탐색 범위 확장
이론적 배경
이름은 꽤 거창하지만 그냥 agent RL 버전의 curriculum learning임
- 이 학습 방법론은 학습 도중 interaction 최대 턴수를 점진적으로 증가시키며, long-term RL에서 exploration-exploitation 간 밸런스를 조정할 수 있게 만듬
- 에이전트가 학습 도중 능력이 진화함에 따라, interaction의 깊이도 같이 증가시켜 학습 깊이를 동기화한다는 것이 핵심
- 처음부터 넓게 학습하면 학습이 꽤나 불안정하게 진행된다고 함
- 흔히 말하는 horizontal extension이 이런 느낌이며, planning, reflection, correction 등의 행동이 여기서 확장 학습될 수 있다고
학습 단계
- 초기: 2-5턴 정도의 간단한 작업에서 시작해 기본적인 도구 활용 능력을 빠르게 숙달
- 후기: 턴 제한이 점차 증가하며 더 복잡한 작업들을 해결해나감
결과
종합 성능
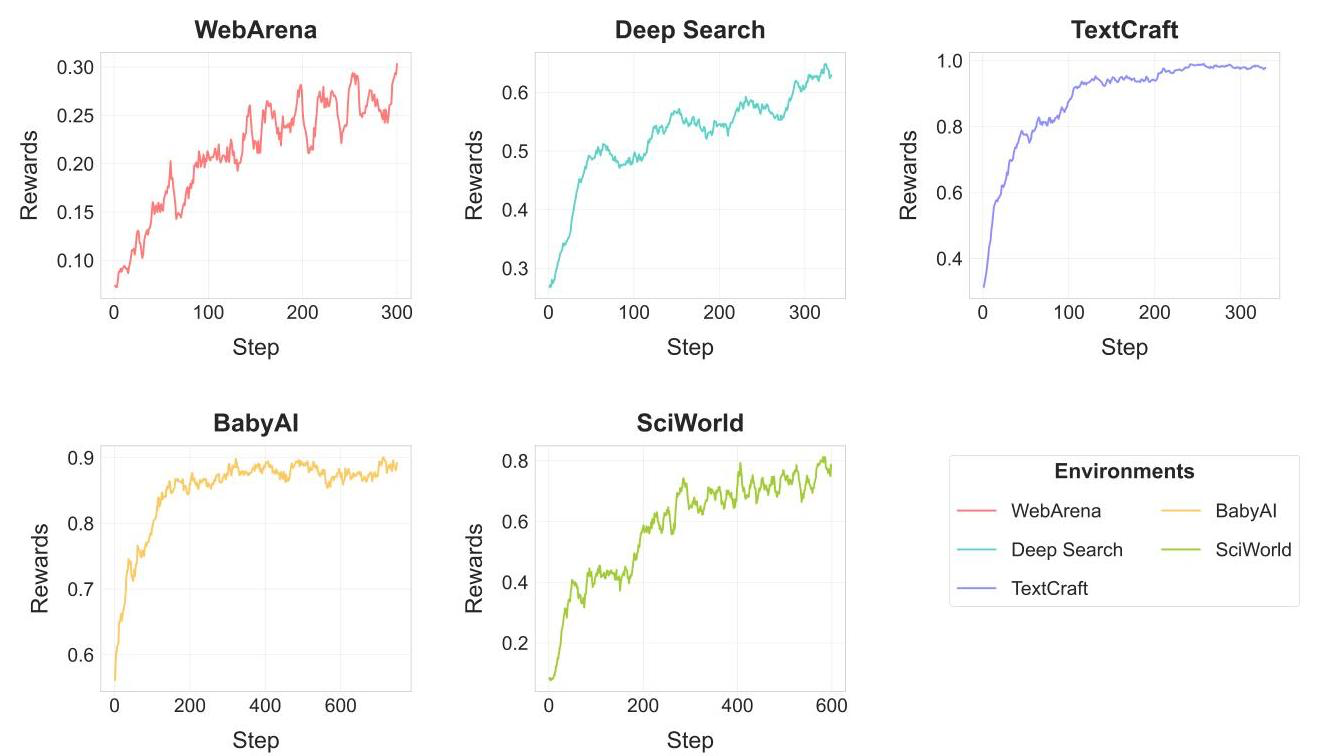
- 모든 측면의 task에서 큰 성능 향상이 있었음
- 알고리즘은 GRPO가 가장 효과적
Horizontal Length
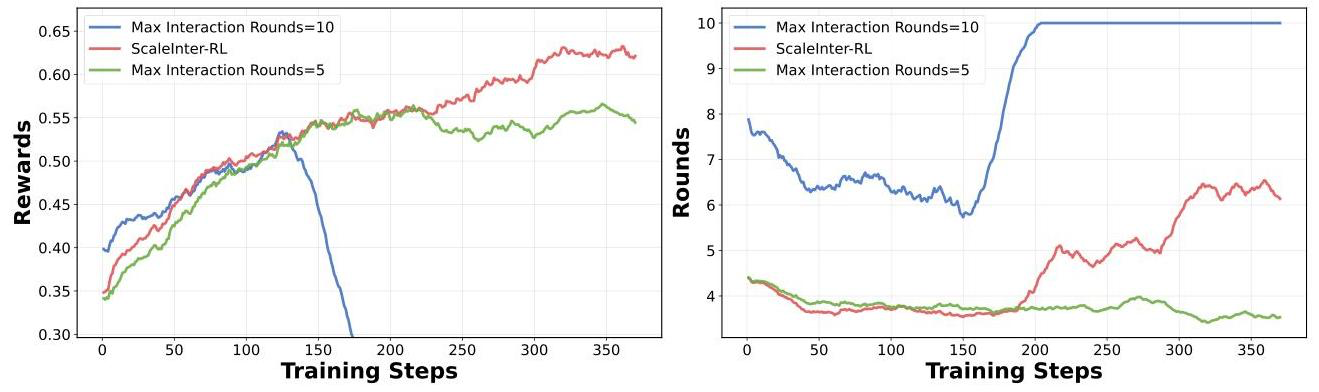
- ScalingInter-RL 없이 턴 제한을 5, 10턴으로 주는 경우
- 5턴으로 주면 잘 학습하다가 exploration이 필요한 때 부족한 성능으로 reward 상승폭이 급감함
- 10턴으로 주면 중반부에 너무 높은 분산(entropy)으로 인해 붕괴해버림
시사점
-
생각보다 논문에 자세한 내용이 공개되어 있지는 않음
- 데이터 확보나 리워드 설계 등
- 일단 프레임워크에 대한 테크 리포트라 보는게 더 적합하고, 자세한 동작은 공개된 레포를 뜯어봐야 할듯
-
요즘 에이전트 RL에 자주 등장하는 "horizon"의 개념을 명확하게 알 수 있었음
- 어떤 개념이며, 왜 중요한지
- 특히 학습이 무너지는 주요 원인 중 하나가 될 수 있음이 중요한 포인트

J의 틀에 몸을 녹여 맞추는 P