[2025.08.26] MUA-RL: Multi-Turn User-Interacting Agent RL for Agentic Tool Use
제안 배경
기존 방법들
- 프롬프팅: 추가 학습 없지만 동작이 불안정하고 작업 복잡도 올라가면 성능 급락
- SFT: 훈련 데이터의 coverage에 의해 근본적으로 제약이 심하며, 새로운 시나리오(OOD)에 일반화되는 데 어려움
- RL: STEM 영역에서 가능성이 있으나, 일반적으로 static한 환경에서 미리 스크립팅된 쿼리로만 학습 -> 실제 상호작용에 내재된 동적 불확실성을 포착하지 못함
에이전트의 동적 상호작용
- 실제 에이전트 시스템의 유저는 질문을 조정하고, 요구사항을 변경하며, 에이전트에게 지속적인 양방향의, adaptive한 요청을 하는 피드백을 보냄
- 이러한 self-evolutionary dynamics를 현재 RL 프레임워크는 다루지 못하고 있음
방법론
SFT와 simulated user 기반의 RL 프레임워크를 결합한 2단계 접근 방식을 사용
에이전트 체인 수식화
- 전체 체인은 의 튜플로 표현 (각각 tool, message, observation의 공간)
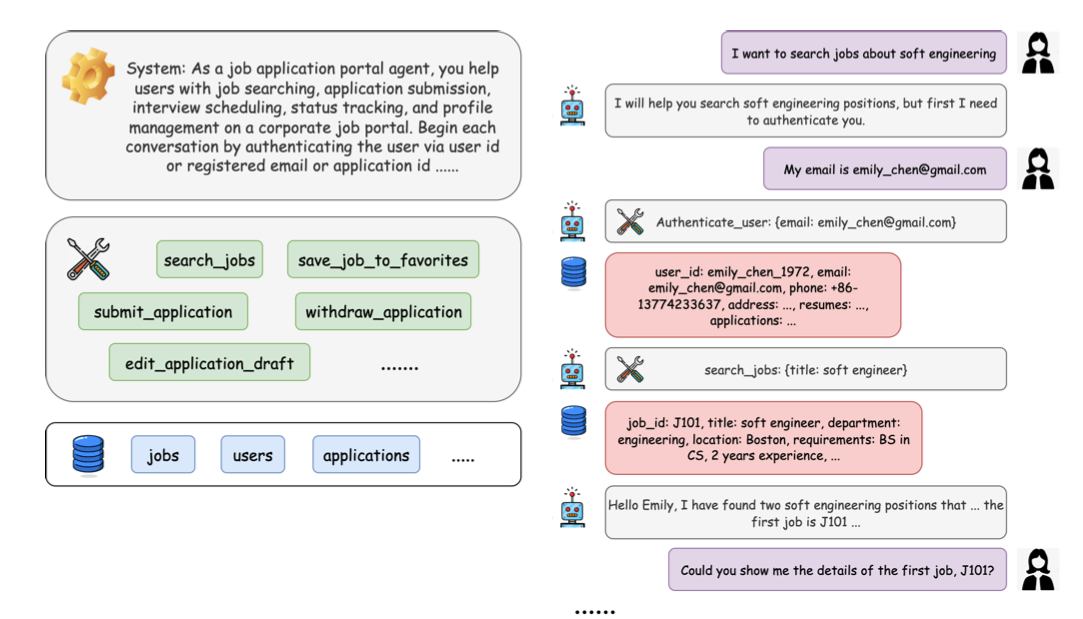
SFT Data Synthesis & Cold Start
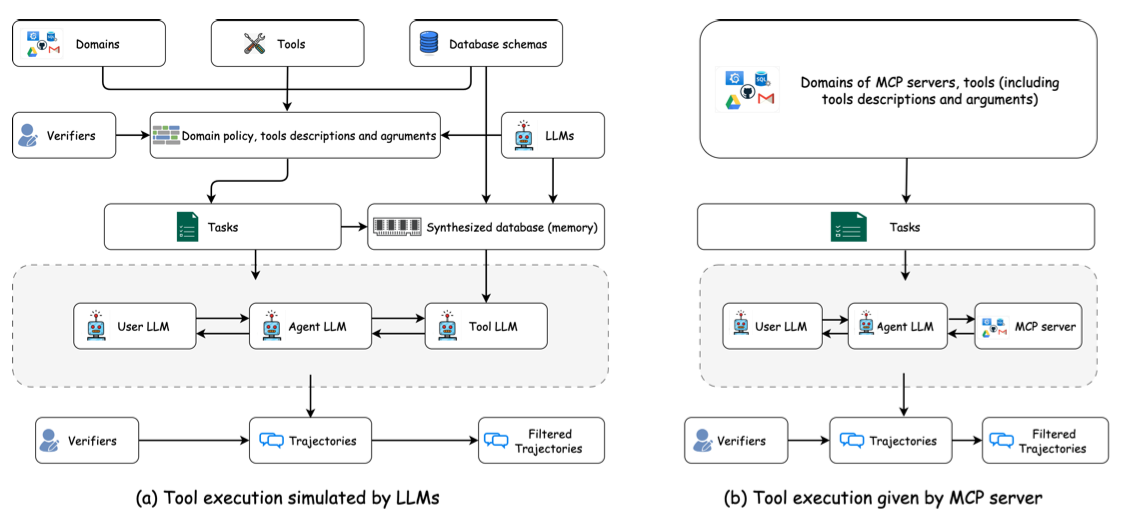
- Tool response는 두 가지 방식으로 생성: (1) LLM simulated, (2) 실제 MCP 서버 응답
- 모든 데이터셋은 품질 보장을 위해 인간 전문가의 annotation과 자동화된 LLM 평가를 모두 거침 (double validation)
- 기본적으로 non-thinking instruct 데이터로 만들어짐
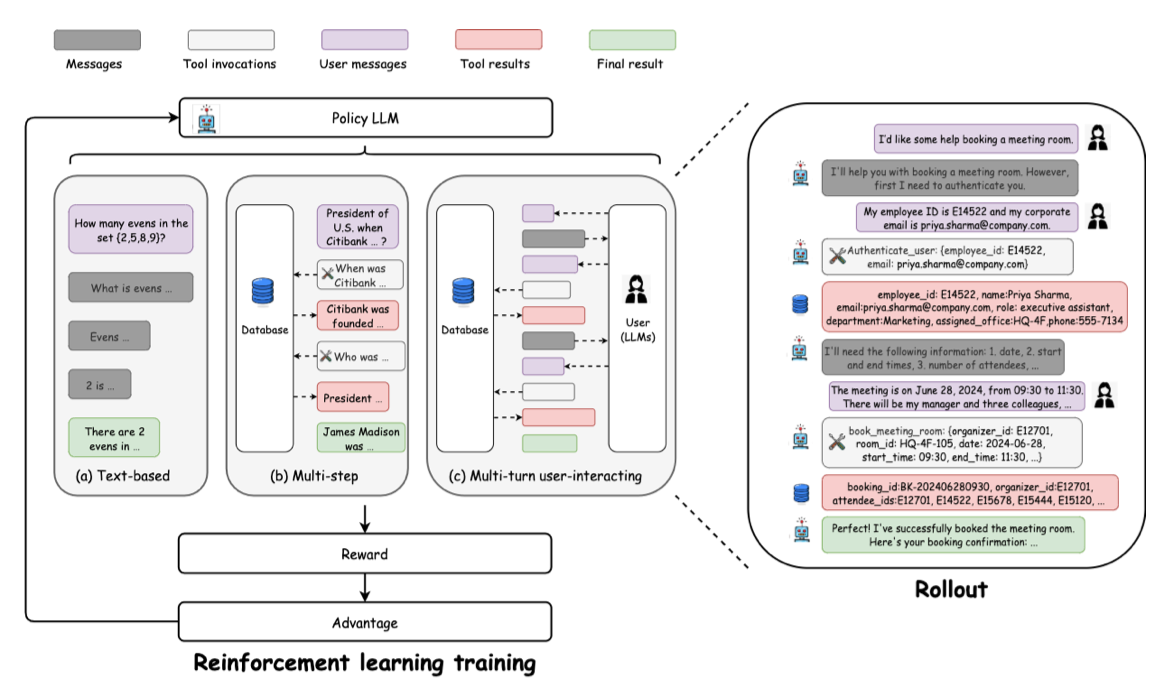
MUA-RL 학습 프레임워크
중요 포인트: 사용자와의 동적 상호작용 (User-LLM simulator)
- MUA-RL 에이전트는 다음을 동시에 수행하며, 멀티턴으로 유저 상호작용 롤아웃을 수행
- 사용자에게 적절한 응답을 생성
- DB와의 실시간 상호작용을 위한 tool calling
- 시뮬레이션된 사용자의 동적 메시지에 적응
- 높은 수준의 역동성, 확률성, 불확실성을 도입할 수 있으며, 사용자 의도 파악 및 의사소통 기술을 동시에 요구하는 정교한 행동 패턴 강제
리워드 설계
- 이진 보상 사용: 시스템 프롬프트에 맞게 작업이 성공했다면 1, 그렇지 않으면 0 -> Trajectory-level의 outcome reward only
- 복잡한 reward shaping 대신 일부러 단순하게 사용하였으며, robustness를 강화하고 hacking을 완화하면서도 작업 해결에 초점을 맞춤
결과
학습 지표
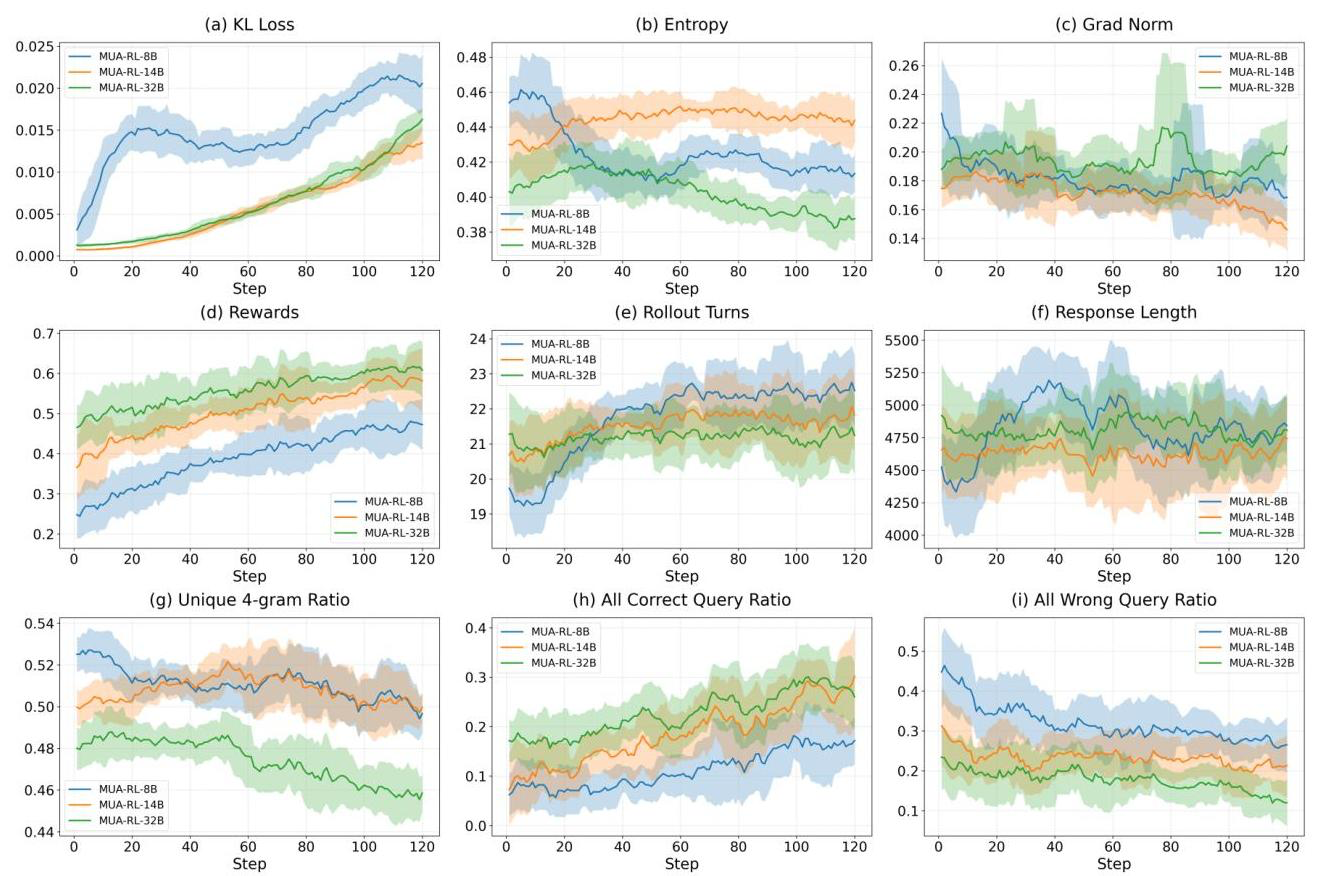
- KL loss: CS 체크포인트부터 점진적으로 증가하며, 작은 모델은 더 많은 변동
- Entropy: 작은 모델은 더 빠른 엔트로피 감소 -> 더 빠르게 감을 잡음 (broad exploration -> deterministic exploitation)
- Rollout: 턴이 점차 증가하며 21-23턴 정도에서 안정화되기는 하였으나, 응답 길이는 대체로 비슷함 -> 장황한 출력이 아니라 상호작용의 효과적인 구조화에서 비롯된다는 사실
- Correctness: "All correct query ratio"는 증가, "All wrong query ratio"는 감소
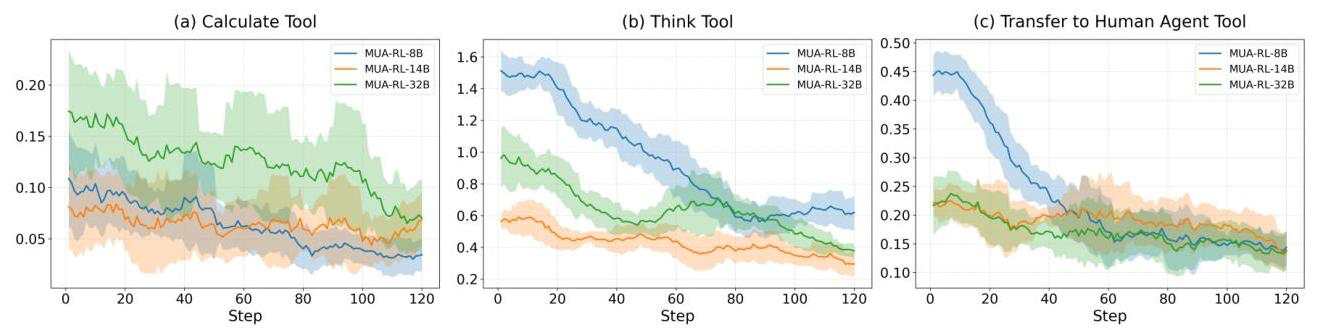
- 특히 tool calling 패턴을 보면 calculate, think, transfer to human agent와 같은 범용 도구(찬스 카드)의 사용은 감소
- 점점 더 필요한 도구들만 똑똑하게 부를 줄 알게되었다는 뜻임
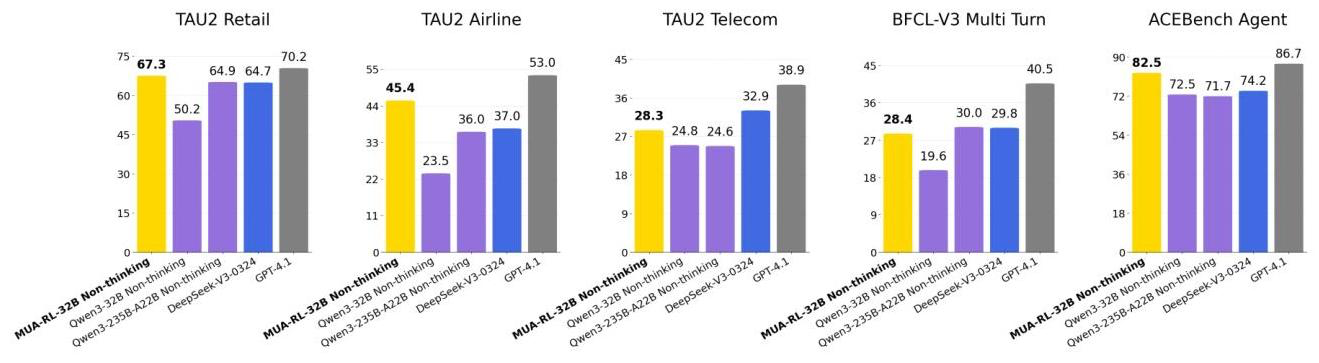
성능 지표
- Tau1 & Tau2
- BFCL
- ACE
Frontier 급 성능
- Qwen3 패밀리의 8~32B 모델을 대상으로 학습됐고, 베이스 -> SFT-CS -> MUA-RL 순으로 성능이 순차 증가했다고 함
- 32B는 최종 학습 시 Tau1 & Tau2 벤치마크에서 Qwen3-235B나 DeepSeek-V3-0324를 넘어 GPT-4.1에 대적할 성능을 보임
- BFCL 및 ACE에서는 frontier에 가까운 성능을 기록했다고 함
시사점
-
위 논문들은 모두 turn-level로 리워드를 계산해 합산을 하든, 개별 업데이트를 하든 했음
- 근데 이 논문은 꽤 최신(8월) 논문임에도 task의 해결에 대한 binary outcome reward만 사용
- 아마도 task의 복잡도가 관건인듯 (기존 지식으로는 아예 해결할 수가 없는, 동적 상호작용이 해결에 필수인 요청) -> 메신저 전송, 페이지 작성 등 생각하면 될듯
- MT-GRPO에서는 ReAct 없이 2-turn TriviaQA (지식 테스트) -> OR만 주면 대충 툴 안쓰고 지식을 늘림
- RAGEN에서는 WebShop을 제외하고는 대부분 게임 환경 -> Static environment로 상호작용 없이도 학습 가능
-
그러나 agentic RAG처럼 지식 기반의 답변을 요하는 task의 경우 OR-only 방식은 위험할 것 같음 (환각 유도)
- RAG는 어쨌든 검색 결과에 기반한 답변을 하는 것이 정답을 전하는 것 만큼이나 중요함
-
그리고 정확히 학습 데이터에 어떤 종류의 task가 들어갔는지는 모르겠지만, 시킨 일을 완수하는데 23턴이 걸리는 에이전트는 뺨이 마렵다
- 이런 식의 trajectory-level을 고려할 때는 전체 응답 턴 수도 reward 설계에 포함하면 좋을 듯
- 혹은 뭐 시키는 task가 체크리스트로 sub-task화 되어있었을 수도

J의 틀에 몸을 녹여 맞추는 P