개요
잡담 겸 배경지식
-
현재 딥러닝 모델을 학습시킬 때 사용할 수 있는 가장 좋은 GPU 중 하나는 NVIDIA의 Tesla A100 80GB이다. 하도 싯가로 거래되기 때문에 제대로 된 정가는 잘 모르겠으나 현재 시중에서 약 2,500~3,000만원 사이에 거래되며, 클라우드로 이용한다고 해도 AWS EC2 기준 8 x A100 인스턴스는 하루 기준 약 150만원 정도를 지불해야 한다.
-
그렇다면 LLM을 훈련시키려면 어느 정도의 GPU 리소스가 필요할까? 데이터셋과 학습 설정에 따라 다르겠지만, GPT-3의 경우 추론에만 A100 8대가 사용되며 사전 학습에는 3,000~5,000대를 약 30일 넘는 기간 동안 사용한 것으로 추정된다. 경량화 모델로 유명한 LLaMA도 가장 큰 65B 모델은 2,048대의 A100을 21일 동안 사용했다고 하니 LLM이 얼마나 비싼 기술인지 감이 올 것이다.
-
그런 와중 ChatGPT의 주인, OpenAI는 ChatGPT가 가장 뜨거웠던 올 한해 약 7,000억의 적자를 입었다고 발표했다. AI에 대한 사람들의 기준이 전례없이 높아진 이제부터는 경량화 없이 수익성을 갖기란 힘든 일이다.
-
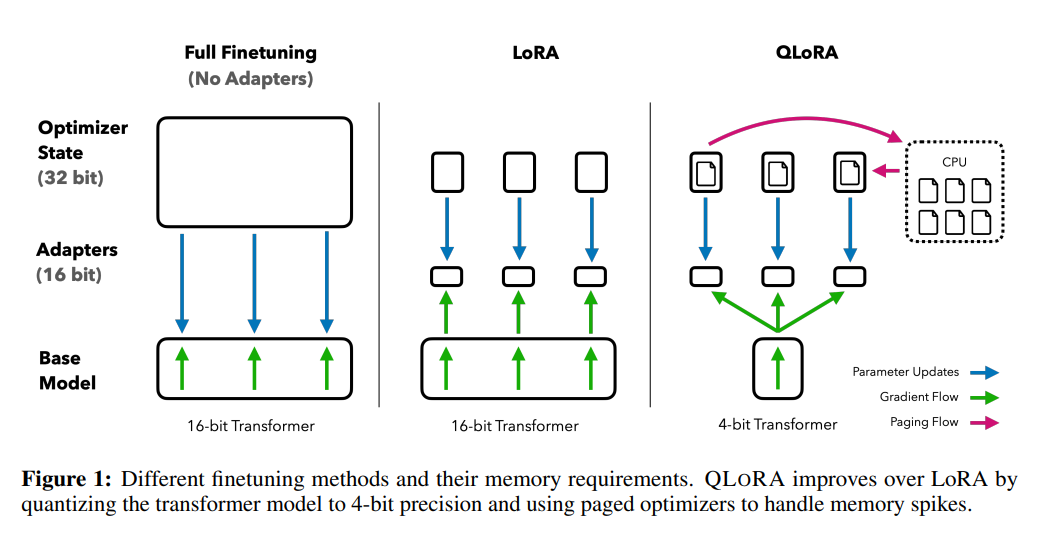
그래서인지 최근 2년여 간 모델 경량화 연구에 대한 관심도 높아지고 있다. Quantization, pruning, distillation 등의 방법을 거쳐 최근에는 LoRA(low-rank adaptation)나 IA3를 필두로 한 adapter 방식까지 주목을 받고 있다. 그리고 2023년 5월 NeurIPS에 양자화와 LoRA를 합쳐 단일 48GB GPU로 65B 모델을 튜닝할 수 있는 Quantized-LoRA, QLoRA가 발표된다.
양자화(Quantization)
-
우선 양자화의 사전적 정의부터 살펴보자면, '모델 가중치와 활성화 함수 출력을 더 작은 비트 단위로 표현하도록 변환'하는 것이다. 쉽게 말해 데이터의 정보를 약간 줄이고 정밀도를 낮추되, 저장 및 연산하는데 필요한 용량을 감소시켜 효율성을 확보하는 경량화 방법론이다. 양자화에는 크게 세 가지 방식이 있다: (1) 동적(dynamic) 양자화, (2) 정적(static) 양자화, (3) 양자화-인지 훈련(quantization-aware training, QAT).
-
동적 양자화는 가중치만 미리 양자화해 활성화 함수는 추론 시에 동적으로 양자화하는 방식이고, 정적 양자화는 가중치와 활성화 함수를 모두 미리 양자화하는 방식이다. 두 방식 모두 이미 학습이 완료된 모델을 양자화 하는거라 quantization loss와 inference latency 간의 trade-off를 피하기가 어렵다. 이를 보완하기 위해 개발된 방법이 QAT이다. 학습 당시부터 quantization-dequantization을 반복하는 fake-quantization으로 학습 이후 수행할 양자화를 미리 학습 당시부터 인지할 수 있도록 시뮬레이션하는데, 이는 기존 모델을 그대로 사용하지 못하고 처음부터 재학습을 해야한다는 단점이 있다(QLoRA도 마찬가지이나 용량 압축률과 학습 속도 측면에서 압도적인 차이가 있음).
-
QLoRA의 저자인 Tim Dettmers는 2021년 강건성과 정밀도를 가지면서 LLM의 입력 분포 불균형 문제를 완화할 수 있는 동적 양자화 방법인 k-bit block-wise quantization을 제안한다. 입력 텐서의 개 값을 하나의 블록으로 간주하고, 각 블록의 absmax를 양자화 상수 로 취급하여 병렬 처리가 가능하도록 만든 것이다.
이후 최종적으로 개의 가능한 양자 후보 집합 중 (원래 값 ) ÷ (양자화 상수 )와 가장 가까운 후보가 양자화된 수가 된다.
LoRA (Low-Rank Adaptation)
- 언어 모델 크기가 GPU 값 무서운 줄 모르고 커져가던 2021년, ChatGPT의 주인의 주인 마이크로소프트는 거거익선 사태에 책임감이라도 느끼는 듯 혁신적 경량화 방법론 LoRA를 발표하게 된다. 당시 quantization이나 distillation에 약간 밀려있던 기술인 adapter를 아주 간단하지만 혁신적으로 바꿔 내놓으면서, 꺼져가던 개인 PC LLM 튜닝의 불씨를 살렸다.
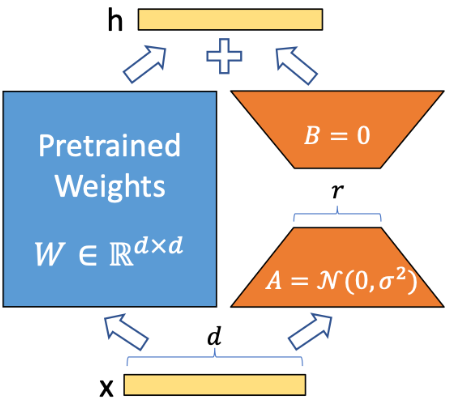
- 기본적인 아이디어는 아주 간단하다. 트랜스포머 기반의 LLM은 어쨌든 임베딩을 받아 선형 변환을 하고 임베딩을 뱉는다는 점에 착안해, 이미 사전 학습이 완료된 LLM의 파라미터는 업데이트하지 않고 downstream task에 필요한 파라미터 업데이트, 즉 변화량만 낮은 차원의 bottle-neck으로 계산해 순전파 시 더해주기만 하자는 것이다.즉, 위 식에서 는 frozen, 와 는 trainable한 상태이다. 기존의 LoRA는 트랜스포머 모듈의 query와 value 행렬에 adapt해 붙어있었고, 기존 LLM의 1%도 안되는 trainable 파라미터로 full-finetuning과 거의 동일한 수준의 성능을 보여주었다.
-
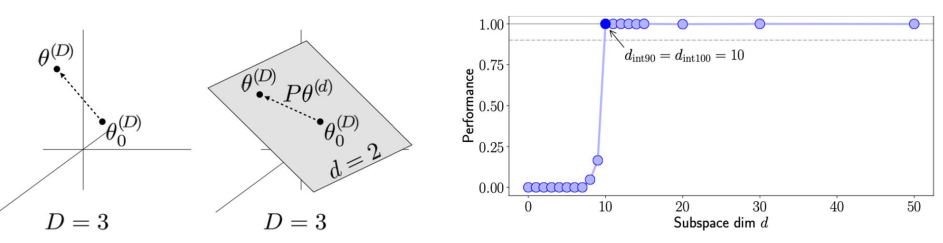
이것이 가능한 이유는, 기존 LLM들의 어마어마하게 크고 복잡한 언어 표현 공간이 그다지 효율적이지 않을 수도 있다는 사실 때문이다. Farkhoor et al. (2018)은 모델의 전체 파라미터 공간에서 탐색의 첫 포인트부터 최종 탐색 목표인 최적 포인트까지를 잇는, 상대적으로 낮은 차원의 subspace인 low intrinsic dimension을 이용할 수 있는 가능성을 제시했다. 여기에 기반해 Aghajanyan et al. (2020)은 RoBERTa-large의 3억 5,500만 파라미터 중 200개 만을 finetuning해 MRPC 데이터셋 기준 full-finetuning 대비 90%의 성능을 달성하기도 했다.
-
다시 말해, 선행 연구들에서 모델이 크다고 finetuning까지 꼭 무겁게 할 필요는 없을 수도 있다는 가능성을 제시했고, LoRA에서는 만큼 의 intrinsic dimension이 낮을 것이라는 가정 하에 가중치 업데이트까지 low-rank decomposition으로 대체한 셈이다.
QLoRA?
- QLoRA는 결국 기존의 LoRA에 새로운 quantization을 더한 형태이다. 베이스 모델인 PLM의 가중치를 얼리고(frozen), LoRA 어댑터의 가중치만 학습 가능하게(trainable)하는 것은 LoRA와 동일하며, frozen PLM의 가중치가 '4비트로 양자화'되었다는 정도가 다른 점이다. 때문에, QLoRA에서 주요히 새로 소개되는 기술은 양자화 방법론이 주가 된다는 사실을 알아두면 편하다.
방법론
4-bit NormalFloat (NF4)
-
QLoRA의 가장 핵심적인 방법론이다. QLoRA 모델은 PLM 가중치가 4비트로 양자화된 채 저장되며, 그 데이터 타입이 바로 NormalFloat 되시겠다. 보통 컴퓨터에서 실수를 표현할 때 사용하는 데이터 타입은 32-bit floating point, 줄여서 FP32이다. 32개의 비트 중 첫 번째 1개는 부호, 8개는 지수부(exponent), 나머지 23개를 가수부(mantissa)로 사용하여 실수를 표현한다.
-
모델 경량화를 위해서 가장 쉽게 사용할 수 있는 데이터 타입은 FP16인데, 비트수를 반으로 줄여 지수부를 8개에서 5개로, 가수부를 23개에서 10개로 줄여 정밀도를 약간 감소시킨 실수 데이터 타입이다. 8비트로 내려가면 이제부터 선택의 갈림길이 생긴다. 8비트로 표현 가능한 수의 개수는 2^8=256개로 확 줄어들기 때문에, FP8로 몇 안되는 실수를 표현하느냐, int8로 정수로 표현해버리느냐를 선택할 수 있다.
-
QLoRA는 과감하게 4비트를 선택한다. 단순히 FP4나 int4 타입을 선택하는 것은 아니고, 본인들이 새로 개발하여 제안한 4-bit NormalFloat를 사용한다. 그런데 아무리 심혈을 기울여 개발했다고 한들, 2^4=16개의 숫자로 신경망 가중치를 표현하는 것으로 어떻게 모델 정확도를 확보할 수 있을까?
Quantile Quantization
-
NF4는 quantile quantization(분위 양자화, 정확한 한국어 번역이 없어 직역함)라는 개념에 기반한다. 분위 양자화는 양자화 대상이 되는 데이터 집합의 누적 분포를 통해 해당 분포의 분위를 구하고 이를 양자화 구간으로 간주한다. 이후 데이터를 양자화했을 때, 각 양자화 구간에 할당되는 데이터의 개수가 동일하도록 보장하는 양자화 방식이 바로 분위 양자화이다. 즉, 해당 데이터의 분포에 따라 비선형적인 구간을 가질 확률이 높고, 데이터의 분포가 달라질 때마다 이를 새로 계산해줘야하는 비용이 높은 양자화 방식이다. SRAM-quantiles 등 계산을 간소화하여 비용을 줄이고 속도를 높인 알고리즘 등이 있으나, 해당 방식을 사용하는 경우 이상치에 상당히 취약해진다고 한다.
-
이러한 trade-off를 한 번에 완화할 수 있는 방법이 있다. 분위 추정의 계산 비용이 높은 이유는 수행할 때마다 여러 데이터 집합의 서로 다른 누적 확률 분포를 매번 추정하고 분위를 나눠야하기 때문인데, 만약 모든 데이터 집합의 분포가 동일하게 고정된다면? 앞서 말한 확률 분포 추정, 분위 분할 등의 과정을 모두 생략하고 이미 정해진 양자화 구간에 데이터 포인트들을 맵핑만하면 된다. 이것이 NF4 데이터 타입이 경량화의 핵심인 이유인데, (1) 분위 양자화를 통해 데이터가 이산화되면서도 정보의 분포를 최대한 이상적으로 유지하며, (2) 그 와중에도 계산 비용을 줄인 것이기 때문이다. (저자는 'information theoretically optimal data type' 이라고 칭했다)
-
사전학습 된 언어 모델의 가중치는 초기화, 업데이트, 정규화 등의 과정을 거쳐 평균이 0이고 표준편차가 인 zero-centered 정규 분포를 가진다. 이때 이 분포를 통일하여 표준화하면 분위 양자화에 적합한 '단일 고정 분포'로 변환할 수 있고, 이렇게 표준화된 양자화 구간을 가지는 데이터 타입이 바로 NF4이다.
NF4 Mapping
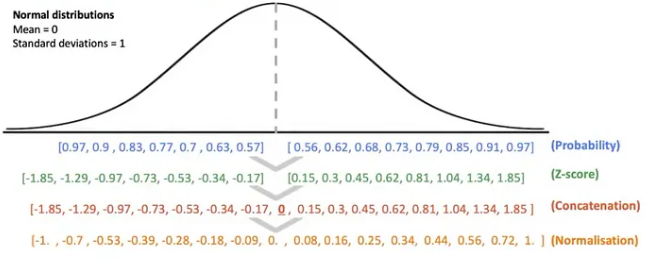
-
8비트 이상의 실수를 NF4 타입의 양자로 맵핑하는 과정을 크게 보면 다음과 같다.
- 분포의 분위수를 추정한다.
(4비트 양자화라면 16개의 양자 후보가 필요하다. 사분위수가 3개이듯, 16개의 양자가 필요한 경우 17분위수를 구해야한다.) - 위 1번의 데이터 타입을 [-1, 1]로 정규화한다.
- 입력 텐서의 를 양자화 상수로 삼아 양자화를 수행한다.
- 분포의 분위수를 추정한다.
-
그러나 위 과정을 그대로 이행하기에는 한 가지 문제가 있다. 16개의 양자 후보가 구간 내 대칭으로 분포하는 경우 중심, 즉 0에 대한 명확한 표현을 가질 수 없다는 것이다(e.g., [-1.0, -0.6, -0.2, 0.2, 0.6, 1.0]). 정확한 0의 부재가 양자화를 불가능하게 만드는 것은 아니나, 0값의 텐서를 입력받았을 때 quantization loss를 유의미하게 증가시킬 수 있다. Task를 막론하고 입력 텐서에는 zero-padding 등 처리해야하는 0이 꽤 많이 존재하기 때문에, 정확한 0의 표현은 무시할 수 없는 부분이다.
-
이 때문에 구간을 대칭으로 16등분하는 것이 아닌, 음수부를 7등분, 양수부를 8등분한 후 0을 중심으로 구간을 concatenate하게 된다. 이렇게 만들어진 16개 분위수를 [-1, 1] 구간으로 정규화하면 이것이 바로 NF4의 양자화 구간이 되며, 입력된 텐서의 값에 해당하는 양자로 맵핑시킬 수 있게 된다.
-
QLoRA 모델들은 NF4 PLM에 후술될 BF16(16-bit BrainFloat) LoRA 어댑터가 붙어있는 형태로 구성되어 있다. 따라서 순전파, 역전파 등 연산 시 PLM과 LoRA의 출력을 합산해야하는 경우 PLM의 NF4는 BF16으로 dequantize된다(PLM은 frozen이라 BF16이 NF4로 변환되는 경우는 없음).
Double Quantization
- Double quantization은 말 그대로 한 번 양자화된 값을 한 번 더 양자화해 추가적인 메모리 이득을 보기 위한 기법이다. 대신 NF4로 양자화된 가중치 자체를 한 번 더 양자화한다는 것은 아니고, 가중치를 양자화할 때 추가적으로 발생하는 값인 '양자화 상수(quantization constant)'를 양자화하는 것이다. 위 두 문장에만 '양자화'라는 단어가 7번 들어가고, 앞으로의 설명에도 많이 나오지만 차근히 이해하면 별로 어렵지 않다.
k-bit Block-wise Quantization
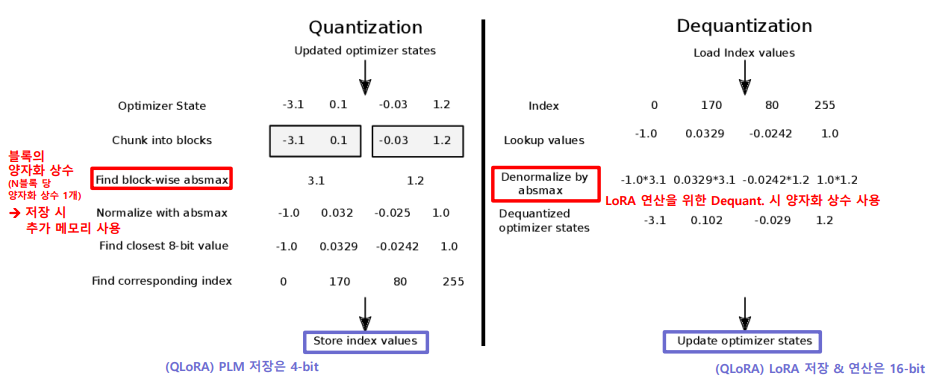
-
위의 NF4 양자화는 [-1, 1] 내로 구간을 정규화하는 과정이 포함된다. 그렇다는 말은, 입력 텐서의 absmax 값으로 나머지 값들을 나누는 과정이 필요하다는 뜻이다. 이때 사용되는 absmax가 바로 양자화 상수이다. QLoRA에서 PLM은 얼어있지만 LoRA는 업데이트가 필요하고, 이때의 LoRA 어댑터는 4비트가 아닌 16비트 실수형으로 존재한다. 때문에 4비트 모델과 16비트 어댑터 간 연산을 위해 quantization-dequantization을 반복해야 하므로, 이 양자화 상수는 모델 밖에 따로 저장되어야 한다.
-
꽤 간단하지만 조금 더 세부적으로 들어가보자면, 그렇다면 이때의 absmax는 전체 가중치의 absmax인가? 하는 의문이 들 수 있다. LLM의 크기가 billion을 넘어 trillion으로 가고 있는 상황에서, 전체 가중치의 absmax를 상수로 고른다면 아무리 zero-centered 정규 분포라 한들 매우 큰 상수가 선정될테고, 대부분의 가중치를 0에 수렴시키는 사태를 발생시킬 것이다. 이를 방지하면서 어느정도의 계산 효율을 보장하기 위해 QLoRA는 k-bit block-wise quantization 방식을 채택한다. 일정 개수의 가중치를 묶어 하나의 블록으로 간주하고, 해당 블록의 absmax를 양자화 상수로써 채택하는 방식이다.
Quantize Quantization Constant
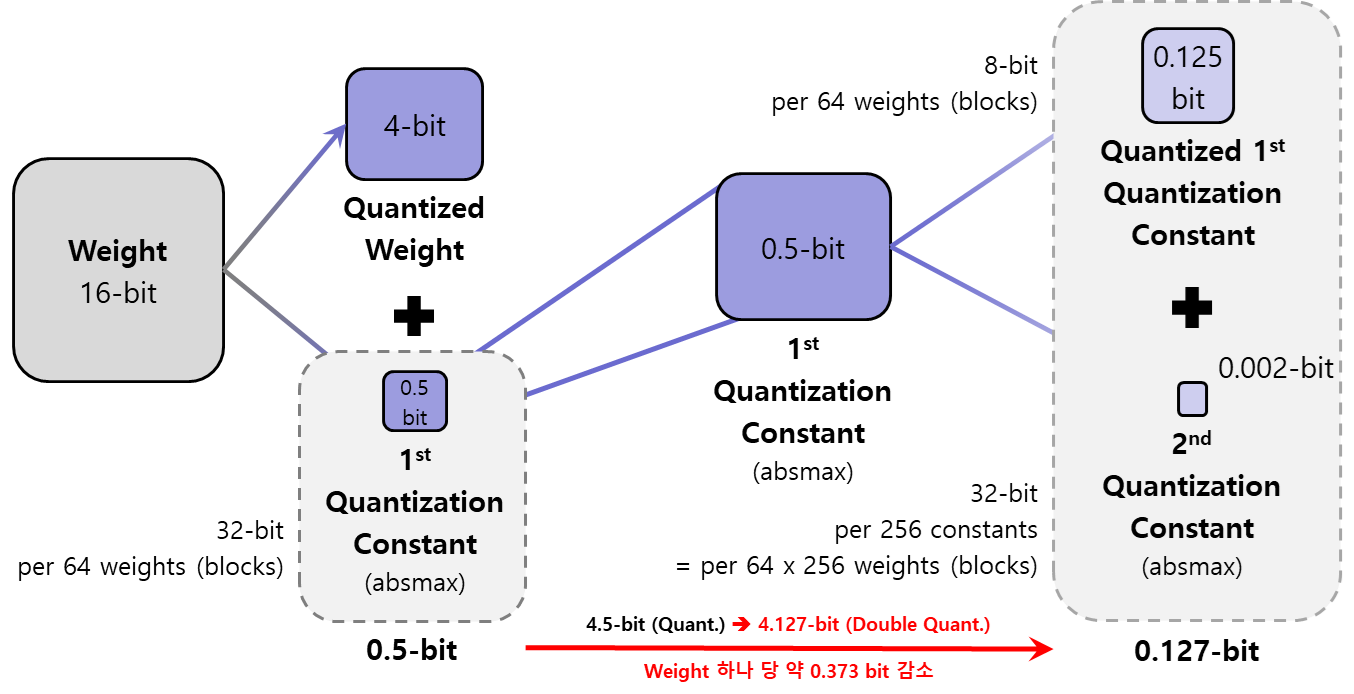
-
Double quantization은 바로 이 양자화 상수를 양자화하는 것이다. 상술했듯이 양자화 상수는 모델 밖에 따로 저장되는 형태이고, 단순히 4비트 모델의 메모리 외에도 이 양자화 상수를 저장하기 위한 약간의 추가적인 메모리 오버헤드가 발생한다. 비율로 보자면 크지 않을 수 있지만 모델이 커질수록 양자화 상수의 절대적 메모리 용량도 커지기 때문에, 여기에도 추가적인 양자화를 가하면서 최대한의 효율을 가져가는 것이다.
-
k-bit block-wise quantization은 블록의 크기가 클 수록 양자화 상수의 개수는 줄지만 정밀도가 낮아지는 trade-off가 존재한다. 이를 적정 선에서 맞추기 위해 QLoRA는 64의 블록 크기를 채택했다. 64개의 가중치가 1개의 양자화 상수(64개 가중치의 absmax)를 가지고 양자화된다는 뜻이다. 양자화 상수는 dequantization을 위해 필요한 것이니 FP32로 저장되고, 이를 가중치 1개 당 추가 메모리로 계산하면 32-bit / 64-block = 0.5비트이다. 다시 말해, NF4는 모델 크기의 측면에서 엄밀하게 말하자면 4비트가 아니라 4.5비트인 셈이다.
-
이때 추가되는 비트를 0.5비트보다 작게 만들기 위해 양자화 상수에 quantization을 가한다. 마찬가지로 block-wise quantization을 사용하며, BF16을 NF4로 만들었던 가중치 양자화와 다르게 양자화 상수 양자화는 FP32를 FP8로 만든다. 이때 가중치 양자화를 위해 생성되었던 양자화 상수를 1차 양자화 상수(first quantization constant), 이 1차 양자화 상수를 한 번 더 양자화할 때 생성되는 양자화 상수를 2차 양자화 상수(second quantization constant)라고 한다.
-
FP8로의 양자화이므로 정밀도를 조금 더 보전할 수 있는 덕에 블록의 크기를 조금 더 늘릴 수 있으며, 256개의 1차 양자화 상수를 하나의 블록으로 보고 1개의 2차 양자화 상수를 생성한다. 결과적으로, 256개의 1차 양자화 상수는 64 * 256개의 가중치에서 도출되므로, 2차 양자화 상수는 가중치 1개 당 32-bit / (64 * 256-block) = 약 0.002비트의 메모리를 추가한다. 이 결과 생성된 '양자화된 1차 양자화 상수'는 기존의 '1차 양자화 상수'와 여전히 동일한 개수로 존재하지만, FP32에서 FP8이 되었으니 가중치 1개 당 비트는 0.5비트에서 8-bit / 64-block = 0.125비트로 감소하게 된다. 즉, 전체적으로 추가되는 비트는 0.5비트에서 (0.125 + 0.002) = 0.127비트가 되어, 가중치 한 개당 0.373비트를 감소(기존 NF4 대비)시켜 저장할 수 있다는 것이다.
Paged Optimization
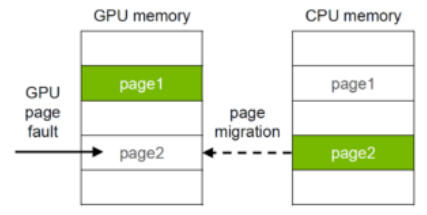
-
마지막으로 소개되는 paged optimization의 경우 직접적인 모델 경량화 기술이라기보다는, 제한된 리소스에서 학습 및 추론을 시도하는데 간접적으로 도움을 주는 유틸리티에 가깝다. 컴퓨터에서 프로세스를 메모리에 올릴 때 작은 단위인 페이지(page)로 분할하여 불연속적으로 저장하는 기술을 페이징(paging)이라고 하는데, GPU의 VRAM도 페이징을 사용하는 물리 메모리의 일종이다.
-
딥러닝 모델을 다룰 때 가장 중요한 하드웨어 중 하나도 이 VRAM이다. 위의 양자화 및 경량화 기술의 궁극적인 목적이 결국 이 VRAM을 얼마나 효율적으로 사용할 수 있는지의 문제이고, 결국 효율성이 떨어져 모델이 사용하는 메모리가 VRAM 용량을 초과하는 경우 OOM(Out-of-Memory) 에러가 발생하기 때문이다.
-
Paged optimization은 바로 이러한 문제를 해결하기 위해 GPU가 사용하는 VRAM 페이지를 CPU의 RAM에도 일부 저장할 수 있게 할당해주는 기술이다. 디스크를 RAM의 일부로 사용하는 가상 메모리와도 비슷한 결이라 볼 수 있다. 사실 이 내용은 본문에서도 크게 중요히 다루지 않고 인터넷에도 정보가 많지는 않아서, 그냥 'OOM을 이런식으로 일시적 해결해줄 수 있는 방법도 있구나' 하고 넘어가면 될 것 같다.
QLoRA!
-
상술했듯이 QLoRA는 LoRA에 새로운 양자화 기법을 추가한 느낌이 강한 기술이라, 기존 LoRA와의 차이점으로 QLoRA를 요약 설명해보겠다.
- FP32 PLM + FP32 LoRA 조합에서 NF4 PLM + BF16 LoRA 조합으로
- 양자화가 없는 타입에서 블록 양자화 상수를 한 번 더 양자화 한 이중 양자화로
- VRAM 초과시 OOM 에러 발생에서 paged optimization을 통한 CPU RAM 활용으로
-
바로 다음 섹션에서 설명되는 내용이지만, 번외로 바뀐 점 중 기존의 LoRA가 트랜스포머의 와 에만 adapted 되었던 것이 '모든 트랜스포머 내 선형 변환'에 붙는다는 점도 있다.
실험 결과
vs Standard Finetuning
기존 LoRA와 Alpaca의 Undertuning 이슈
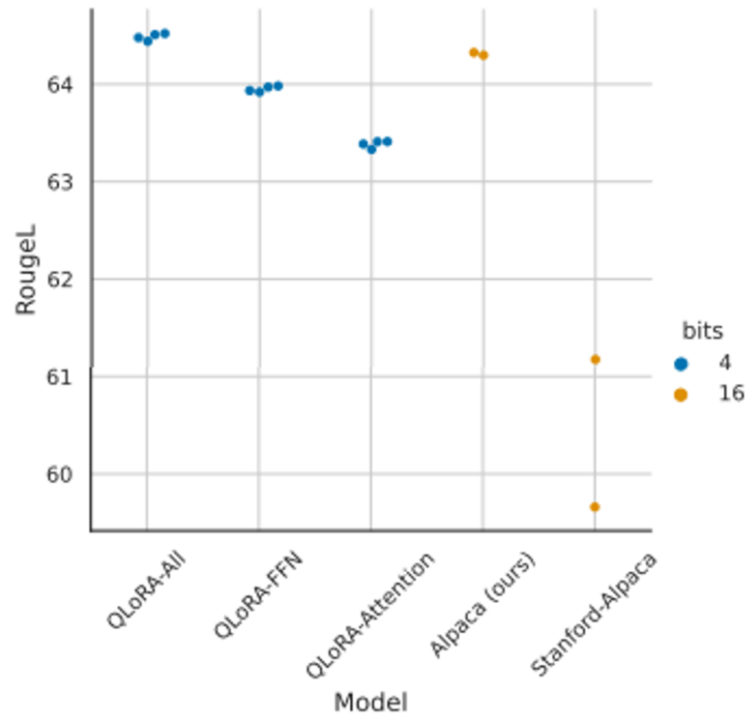
- 바로 위에서 이야기 했듯이, QLoRA의 연구진들은 기존 LoRA가 더 좋은 성능을 낼 수 있었다고 주장했다. 기존 LoRA는 트랜스포머 모듈의 query와 value 벡터를 처리하는 와 에만 붙어 adaptation을 수행했다. 그러나 위 그래프(LLaMA 7B의 Alpaca 데이터셋 finetuning 결과)에서 볼 수 있듯이 attention 레이어 뿐만 아니라 feed-forward network(FFN)까지 LoRA를 adapt했을 때 더 좋은 성능을 낸 결과를 보였다. 게다가 Alpaca 또한 다소 undertuned된 부분이 있음을 확인했는데, finetuning 시 학습률과 배치 사이즈에서 재탐색을 수행한 결과 더 높은 RougeL 점수를 도출하는 모습을 보였다.
NF4 vs FP4 / int4
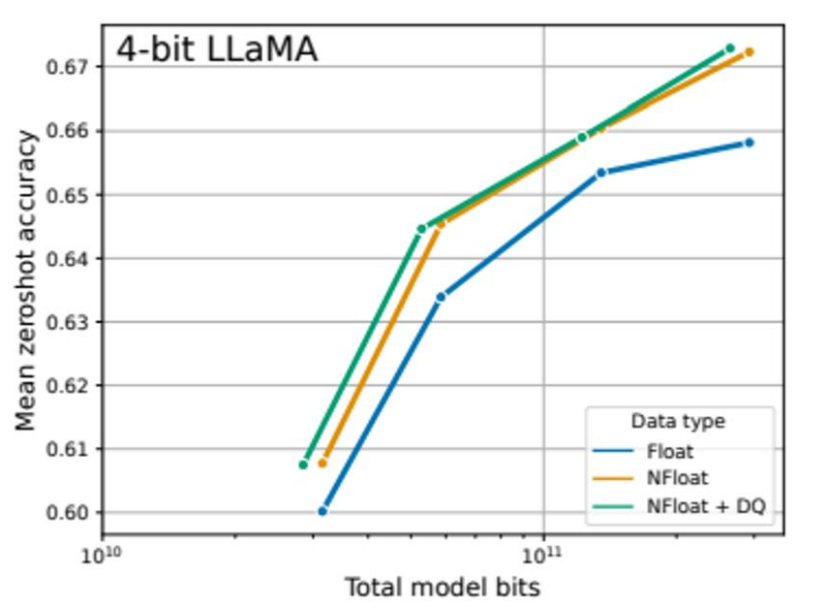
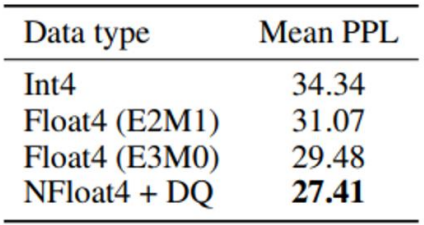
- 위 그래프는 여러 4비트 데이터 타입의 LLaMA가 수행한 Winogrande, HelloSwag, PiQA, Arc-Easy, Arc-Challenge의 zero-shot 벤치마크 결과이며, 아래 표는 125M~65B의 OPT, BLOOM, Pythia, LLaMA 4비트 모델들의 Pile-CC 데이터셋에 대한 perplexity이다. NF4의 성능이 FP4나 int4 데이터 타입들에 비해 유의미하게 높은 성능을 보이며, double quantization까지 추가되는 경우 성능 저하 없이 메모리 사용량의 감소를 구현할 수 있음을 확인할 수 있다.
k-bit QLoRA vs 16-bit Full-Finetuning / 16-bit LoRA
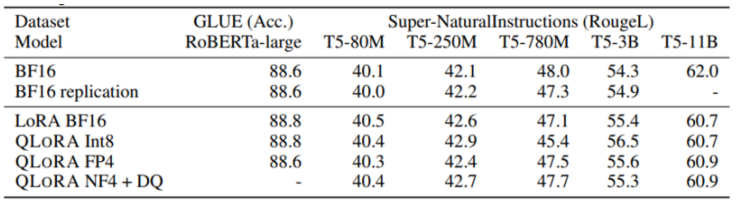
- 위 표는 125M~3B 크기 RoBERTa, T5 모델의 데이터 타입 별 GLUE와 Super-NaturalInstructions 벤치마크 점수이다. 두 벤치마크 모두에서 16, 8, 4비트의 어댑터가 16비트 full-finetuning 베이스라인 성능을 거의 재현 가능함을 확인할 수 있다. 저자들은 이 결과를 두고 adapter finetuning after quantization이 quantization loss를 거의 복구할 수 있음을 시사한다고 설명했다.

- 위 표는 LoRA-adapted 된 7B~65B 크기 LLaMA의 데이터 타입 별 5-shot MMLU 정확도이다. LLaMA의 경우 33B부터는 리소스 한계로 full-finetuning을 할 수 없어 애초에 LoRA로 비교했다고 한다. 두 instruction following 데이터셋을 각각 학습한 모델들을 5-shot MMLU task로 검증했는데, NF4 + DQ 조합의 LLaMA + QLoRA가 BF16 LLaMA + LoRA의 성능을 거의 완벽히 따라잡을 수 있다는 결과가 도출되었다. 반면 FP4 버전은 BF16 버전보다 평균적으로 1% 정도 성능 하락이 있음을 확인하였다.
SOTA Chatbot by QLoRA: Guanaco
- QLoRA가 어느정도 유의미한 결과를 보인다는 점을 근거로, 저자들은 QLoRA를 통해 단일 소비자용 GPU에서도 학습시킬 수 있는 SOTA 챗봇 Guanaco를 제작했다.
Setup
-
목적
NF4 + DQ 기반의 QLoRA가 어디까지 적용될 수 있는지 파악하기 위해, 제한된 리소스 내에서 가장 큰 가용 모델에 instruction tuning을 시도했다고 한다. -
학습 디테일
OASST1, HH-RLHF, Alpaca, self-instruct, unnatural-instructions, FLAN v2, Chip2, Longform 까지 총 8개의 데이터셋을 따로 학습하여 실험하였다. 모든 실험에서 동일하게 NF4 + DQ의 QLoRA를 적용했고, 학습 목표가 서로 다른 다양한 데이터셋을 사용했기 때문에 설정 통일을 위해 교차 엔트로피 기반 지도학습만 사용했다.
데이터셋 중 instruction과 response가 명확히 구분된 데이터셋은 response로만 finetuning을 했고, 여러 응답이 가능한 OASST1이나 HH-RLHF의 경우 대화 트리의 최상위 response를 기준으로 instruction을 함께 포함해 finetuning 했다고 한다. -
베이스라인
Vicuna 13B: ShareGPT의 user-shared conversation을 통해 GPT-distillation으로 학습
Open Assistant 33B: OASST1 데이터셋으로 RLHF를 통해 학습된 LLaMA 33B
그리고 그 외 GPT-3.5-turbo(ChatGPT), GPT-4, Bard 등 상용 챗봇 시스템들
Evaluation
-
벤치마크 및 평가 방식
각 80개와 953개인 Vicuna와 OASST1의 validation 셋을 사용하였으며, 평가 방식으로는 human evaluation과 함께 GPT-4 기반의 automated evaluation을 사용했다고 한다.
Human eval의 경우 Amazon Mechanical Turk를 통해 평가자를 고용해 ChatGPT와의 비교 평가 그룹, 그리고 Elo 점수 계산을 위한 모델 간의 pairwise 비교 평가 그룹으로 나눴다.
Automated eval의 경우 GPT-4가 채점자로서 타겟 모델과 ChatGPT가 도출한 두 출력을 비교해 10점 만점의 점수를 부여하는 방식으로 수행했는데, 먼저 제시된 답변에 더 높은 점수를 주는 order effect가 있어 순서를 한 번씩 바꿔 총 2번 채점한 후 평균을 냈다고 한다. -
Elo Rating
원래 체스 선수의 실력 표현을 위해 개발된 측정 방식으로, 나의 승리 확률을 , 상대와 나의 Elo를 각각 , 라고 할 때 다음과 같이 표현한다.Elo rating은 매 경기가 종료될 때 가중치 와 경기 결과 (승리 시 1, 무승부 시 0.5, 패배 시 0)에 따라 다음과 같이 업데이트 된다.
이러한 방식으로 객관적인 각 모델의 챗봇 성능을 나타내고자 주어진 공통의 프롬프트에 대해 더 좋은 응답을 생성하는 모델이 승리하는 토너먼트 대회를 구성하였고, 32의 가중치 와 random seed로 10,000회 반복하였다.
Results
-
Automated Evaluation 결과와 타당성
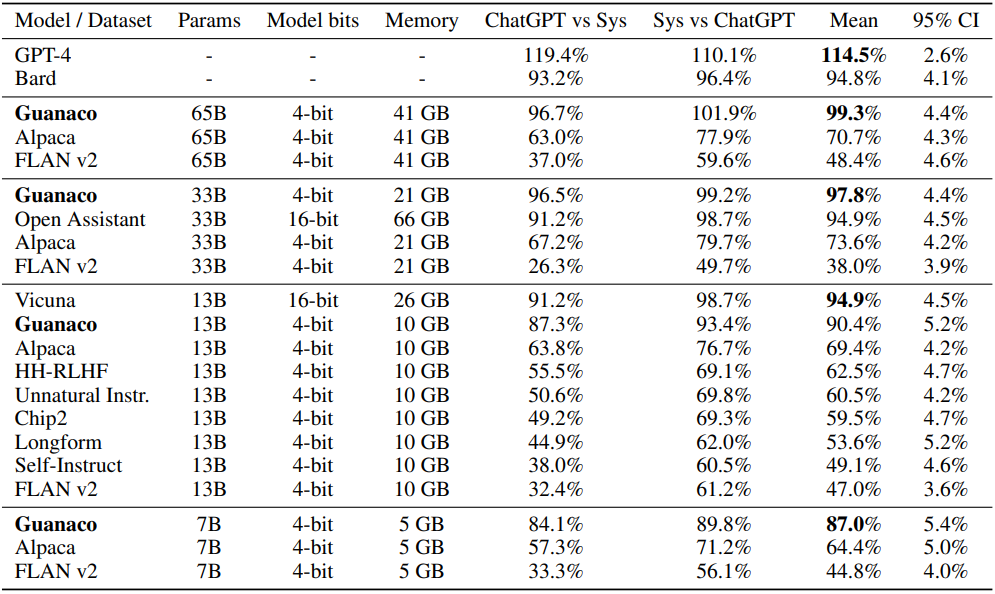
우선 GPT-4의 채점 결과부터 확인해볼 때, Guanaco 65B의 경우 ChatGPT에 비교해 99.3%의 점수를 얻어 경쟁이 가능한 수준으로 확인되었다. 33B 버전은 16비트 Vicuna 13B보다 성능이 더 좋고, 무엇보다 20B의 크기 차이에도 불구하고 실제 메모리 용량은 5GB 더 작은 것으로 나타났다. 16비트 Open Assistant 33B와 비교했을 때는 더 좋은 성능은 물론이거니와 무려 45GB의 압도적인 메모리 용량 차이를 보였다. 7B 버전의 경우 사이즈가 작다보니 엄청난 성능을 보이지는 못했으나, 동일 크기 Alpaca, FLAN v2 학습 버전과 비교했을 때는 압도적인 성능차를 나타냈다. 이론상 ChatGPT 성능 87%의 언어 모델을 5GB의 용량으로 스마트폰에 탑재할 수도 있게된 것이다.
그러나 오른쪽 95% 신뢰구간(confidence interval, CI)을 확인해보면, LLM 기반 채점이다보니 척도가 객관적이지 않아 CI가 다소 넓은 모습도 보인다. 표에 직접적으로 나오지는 않았으나 human eval 순위와 부분적으로 불일치하는 부분도 있기 때문에, 인간과 GPT-4의 채점 결과를 바탕으로 한 Elo rating도 확인할 필요가 있다. -
Elo Rating 해석과 MMLU 벤치마크의 적합성
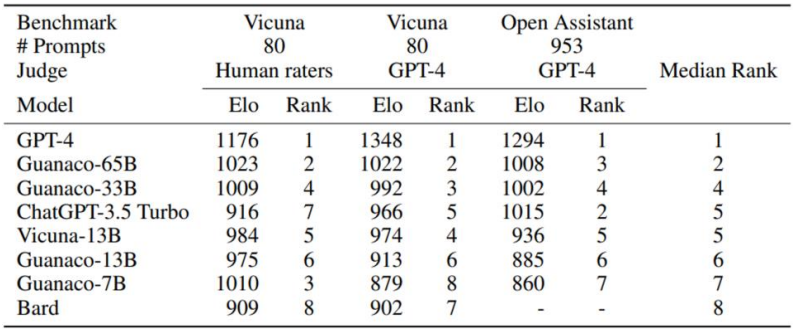
Vicuna 벤치마크에서는 human eval과 automated eval에서 Guanaco 33B와 65B 모두 ChatGPT보다 높거나 유사하게 도출되었다. 그러나 Vicuna가 전반적으로 오픈 소스 모델에 유리하게 점수를 주는 듯한 모습이 있고, 그보다 더 큰 OA 벤치마크에서는 크지 않은 점수차로 ChatGPT가 승리하는 모습도 볼 수 있었다. Elo rating이 얼마나 객관적이고 공정한 점수인지를 떠나서, 벤치마크에 따라 순위가 바뀌는 모습은 짚고 넘어갈만한 포인트이다.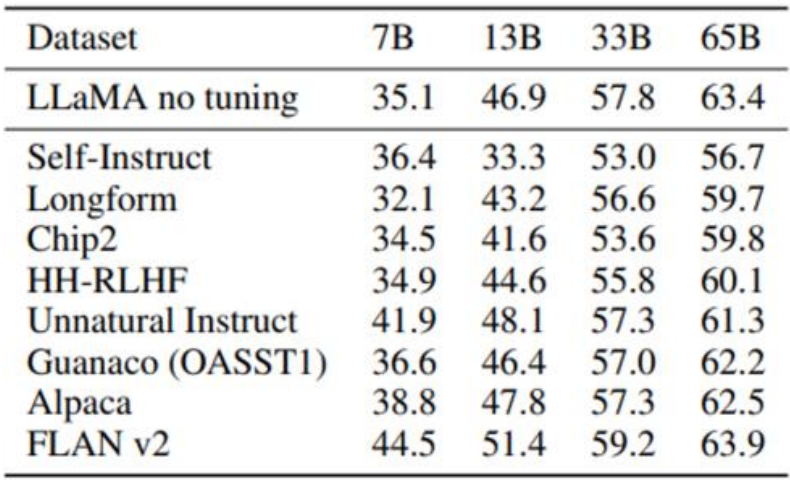
위의 표는 QLoRA로 학습된 LLaMA의 학습 데이터셋 별 5-shot MMLU 벤치마크 점수이다. FLAN v2로 학습한 경우 Vicuna 벤치마크에서는 거의 최저 성능을 기록했으나, MMLU는 데이터셋 후보들 중 가장 높은 점수를 기록했다. 학습 데이터셋과 벤치마크의 orthogonality가 점수에 결정적인 영향을 미친다고 볼 수 있다.| 사실 이 부분은 살짝 거르고 읽어도 상관 없다. 애초에 Vicuna는 본인들이 제안한 Elo rating으로, MMLU는 원래 벤치마크의 점수로 평가되어 지표가 통일되지 않았다. 또 QLoRA 논문에서 왜 갑자기 LLM 벤치마크에 대한 타당성 이야기가 나오는지 솔직히 잘 모르겠다. 저자들은 인간이 채점한 Vicuna 벤치마크의 ChatGPT 상대 점수를 공개하지 않았는데(appendix에도 없음), 아마 인간 채점 결과 Guanaco의 점수가 좋지 않았던 것은 아닌지, 그래서 벤치마크 테스트의 흠을 얘기한 것은 아닐지 생각이 든다.
-
SOTA 챗봇 Guanaco의 탄생
어찌됐든 Guanaco는 현재 open-source-only 모델들 중 유일하게 벤치마크 상위권에 위치한 모델이며, 그럼에도 33B 모델 기준 24GB GPU에서 12시간 내 훈련이 가능하다. 현존 최고의 상용 모델들과 경쟁이 가능한 근미래의 가능성을 제시했다고 볼 수 있다.
Qualitative Analysis
- 다른 LM들과 크게 다를 것 없는 분석이라 넘어간다.
한계점과 결론
Limitations
- 리소스 이슈로 인해 33B, 65B 크기의 full-finetuning 성능을 따라잡는지 확인하지 못했다고 한다.
- BigBench, RAFT 등 다른 LLM 벤치마크에 대한 평가를 제공하지는 못했으나, 대신 MMLU를 조금 더 광범위하게 연구하며 새로운 챗봇 평가 방법론을 연구하고 있다고 한다.
- Guanaco가 다른 LLM들에 비해 사회적으로 편향된 텍스트 생성을 필터링하지 못한다고 한다. PLM인 LLaMA와 비교했을 때에도 크게 상승한 수준이라 아마 학습 데이터셋인 OASST1 자체에 이슈가 있다고 판단하고 있다.
- 더욱 다양한 bit precision이나 adapter를 실험하지 않고 NF4 + DQ + LoRA로 fix한 방법론이라 다소 제한적이라고 볼 수는 있다. 다만 LoRA 외에도 강력하다고 알려진 PEFT들이 대부분 소형 모델로 검증되어 대형 모델에서도 LoRA의 강건성을 따라올 수 있을지는 의문이며, 또한 저자들은 양자화 이후 finetuning이 대부분의 quantization loss를 거의 완벽히 복구할 수 있다고 믿기 때문에 향후 더욱 공격적인 양자화 방법을 찾을 수 있으리라 보고 있다.
Conclusion
- QLoRA는 LoRA에 4-bit NormalFloat, double quantization, paged optimization을 추가한 경량화 기법으로, RTX 3090 24GB에서 33B 모델을, A6000 48GB에서 65B 모델을 finetuning할 수 있는 최초의 기법으로 소개되었다.
- 리소스가 부족한 연구자들이 모델 학습을 광범위하고 보편적으로 사용하여, 최신 NLP 기술에 대한 접근성 향상에 기여할 수 있을 것으로 생각하고 있다.
- 개인 스마트폰 단말에 on-premise로 보급할 수 있는 AI, 그리고 프라이버시 및 리소스 이슈로 구현할 수 없던 새로운 애플리케이션 구현 및 빠른 배포에 대한 가능성을 열어주었다.
- LLM의 보급이 쉬워지는 것에는 필연적으로 범죄 악용 등 부작용이 따라오지만, 대기업들에게 LLM의 권한을 넘기는 것보다는 기술 접근에 대한 평등함이 향후 더 나은 분석과 발전을 가져다 줄 것으로 기대하고 있다고 한다.




벨로그 로그인하게 하는 글이였습니다. 잘읽고가요