들어가며
-
현대 NLP의 기초를 닦은 단어 벡터 임베딩에 관한 초기 논문이라 방법론은 짧고 그리 어렵지 않은데 반해 실험 결과에 대한 내용이 길다. 이 논문을 이해하기 위해서는 방법론만 훑어도 크게 상관 없다.
-
중간중간 생략된 부분이나 목차에서 조금 벗어나게 정리한 부분들도 있다.
개요
등장 배경
Word2Vec은 현대 NLP 분야의 근간이 되는 기술이다. 해당 논문을 기점으로 기계학습 자연어처리분야의 main stream이 LSA(latent semantic analysis)나 co-occurrence matrix 등의 one-hot encoding 기반 통계 시스템에서 신경망 기반의 임베딩 벡터 기반으로 넘어오게 되었다.
이 논문의 발표 이전에는 N-gram 모델과 같은 NLP 시스템이 주류였으나, 이러한 시스템들은 in-domain에 데이터가 제한되어 있는 등 한계가 너무 극명한 기술이었다. 이런 이유로 기존 시스템의 scaling up보다 아예 더 고도화된 기술의 등장이 필요했다고 한다. 이 와중에 ML 기술의 발전으로 단어의 분산 표현(distributed representation)을 사용하는 NNLM 모델(Mikolov 2007; Mikolov et al. 2009)이 등장하게 되고, N-gram 모델보다 좋은 성능을 보이게 된다. 본 Word2Vec 연구에서 제안하는 두 가지 모델은 상술한 NNLM의 원리를 차용한다:
- 단일 은닉층으로 단어 벡터를 만들고
- NNLM이 1에서 만들어진 단어 벡터를 가지고 훈련
연구의 목표
그간의 NLP 모델 중 수 억개 이상의 단어를 학습하면서, 단어 벡터의 차원을 50~100 수준으로 유지할 수 있는 모델은 없었다고 한다. 그러나 Word2Vec의 저자들은 유사한 단어는 단순히 서로 가까운 위치에 있는 것 뿐 아니라, 다중 척도의 유사성(multiple degree of similarity)을 갖고 있다고 보았다. 예를 들어, 아래 수식처럼 덧셈 뺄셈 등의 단순한 벡터 연산으로 "King", "Man", "Queen", "Woman" 단어들 간의 관계 파악이 가능하다고 본 셈이다.
즉, 연구진은 단어 간의 선형 규칙성을 보존하면서도 표현의 정확도를 높일 수 있는 모델을 개발하는 것을 목표였으며, 성능의 정량적 측정을 위해 구문적(syntactic) 규칙과 의미론적(semantic) 규칙을 가진 종합 테스트셋을 제작하였다.
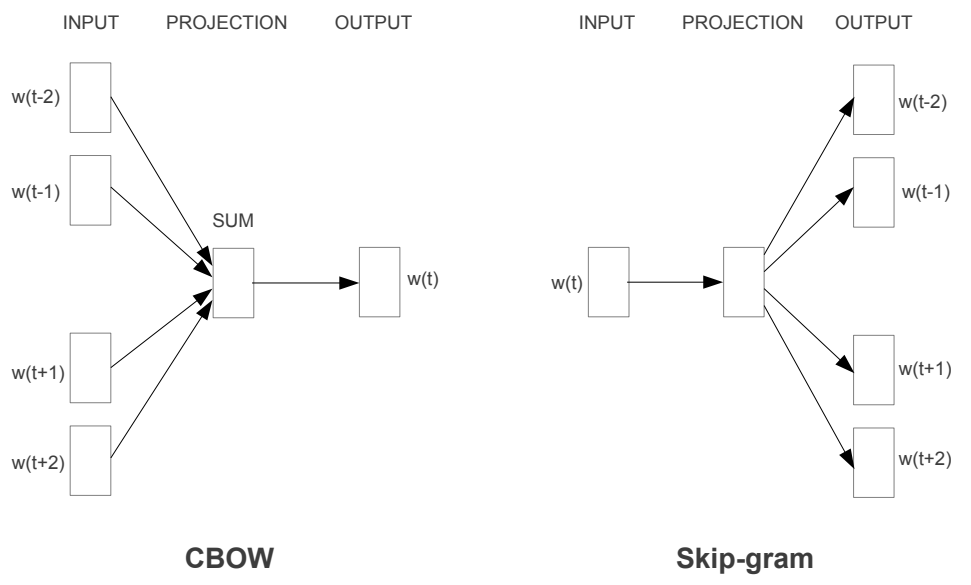
모델 구조: CBOW & Skip-Gram
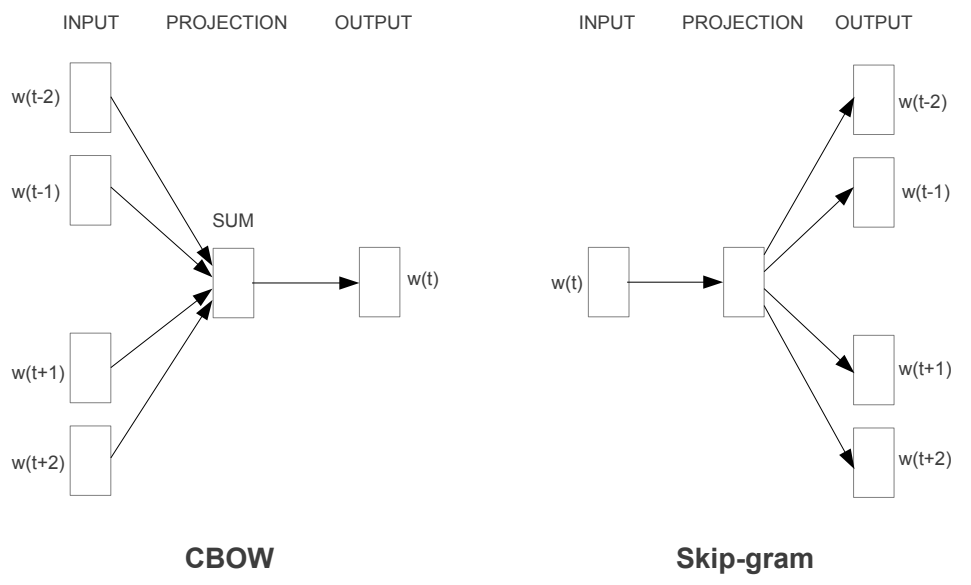
텍스트의 연속적 표현을 추정하는 가장 유명했던 모델들로는 위에 언급한 LSA와 LDA(latent Dirichlet allocation)였는데, 본 Word2Vec 모델은 LSA보다 선형 규칙성 보존도가 높고 LDA보다 계산 비용이 낮다. 보통 계산 복잡도의 경우 아래와 같이 모델 파라미터 수로 계산되는데, 학습 조건(: 에포크)이나 데이터(: 데이터셋 내 단어 개수)에 의존하는 앞의 두 term을 제외하고 보통 가 모델 구조로 인한 복잡도를 좌우한다.
앞서 제안된 NNLM이나 Recurrent-NNLM의 경우 는 보통 비선형 은닉층 파라미터 수인 가 dominating term이 된다. 이것이 신경망의 매력 포인트이긴 하나, Word2Vec에서는 이러한 비선형 은닉층을 제거하고 projection layer만을 사용해 데이터를 더 효율적으로 학습할 수 있는 단순한 모델에 집중한다.
Continuous Bag-of-Words (CBOW)
Word2Vec 방식의 첫 번째 모델은 CBOW로, 앞 뒤 N개의 단어를 보고 현재의 단어가 무엇인지 예측하는 모델 이다. 모든 단어에 대해 projection layer가 공유되며, 계산 복잡도는 이다. 원래 bag-of-words(BOW)라는 통계 기반 표현 방법이 존재했으나, CBOW는 말그대로 '연속적인' 문맥 표현 분포("continuous" distributed representation of the context)를 만들어내기 때문에 이름이 그렇게 지어졌다.
Skip-Gram
두 번째 모델은 skip-gram인데, CBOW와는 반대로 현재의 단어 하나를 보고 앞뒤로 N개 씩의 단어를 예측 하는 모델이다. 때문에 한 문장 내에서 어떤 특정 단어 하나와 다른 단어들을 분류하도록 학습된다. 계산 복잡도는 이며, 이때 는 예측하려는 단어의 최대 앞뒤 거리이다.
실험 결과
위에 말했듯이 이 연구진들은 단어는 굉장히 다층적인 면에서 유사도를 가질 수 있다고 보았다. 예를 들어, "big"이라는 단어가 "bigger"와 유사하듯이, "small"은 "smaller"와 유사하다. 연속적 단어 임베딩을 사용하는 경우 대수 연산을 사용하여 이러한 단어의 관계에 부합하는 어떤 단어를 찾아낼 수 있다. 즉, "'biggest'가 'big'과 유사하듯이, 'small'과 유사한 단어는 뭐지?"라는 질문을 다음과 같은 수식으로 풀어낼 수 있다.
연구진들은 이러한 방식으로 구문적/의미론적 유사도를 모델이 얼마나 정확하게 예측할 수 있는지 검증하기 위해 아래와 같은 word-pair 데이터셋을 만들게 된다(위 5개: 의미론적 단어 쌍, 아래 9개: 구문적 단어 쌍).
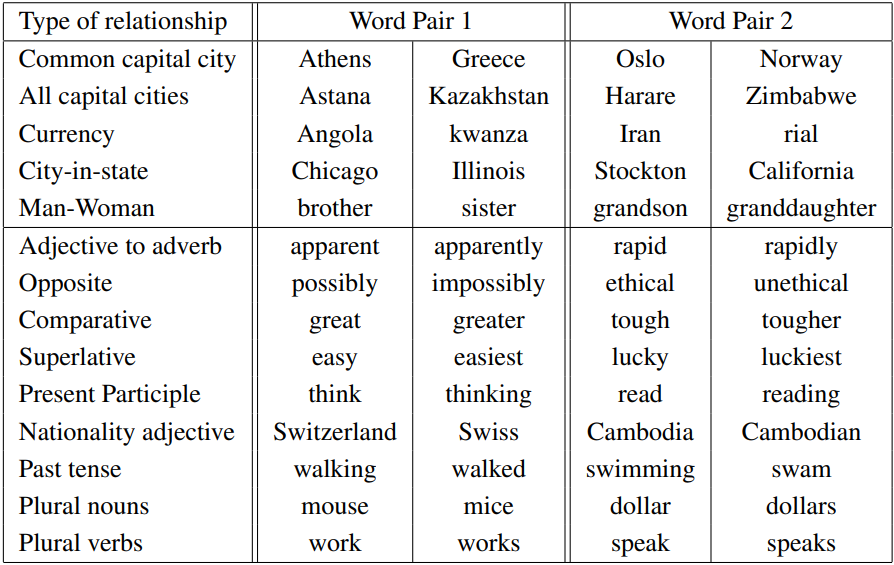
질문은 단어 쌍 리스트를 수동으로 먼저 고르고, 선택된 단어 쌍들로 여러 질문을 만드는 방식으로 생성된다. 가장 윗 줄의 <Athens/Greece + Oslo/Norway> 단어 쌍을 예로 들자면, Greece → Athens 관계를 예시로 Norway → ? 를 물어볼 수도 있고, Athens → Greece 관계를 예시로 Oslo → ?를 물어볼 수도 있다. 두 판단 기준을 합친 모든 질문들에 대한 정확도와 각 판단 기준 별 질문의 정확도를 모두 검증한다.
최대 정확도 측정
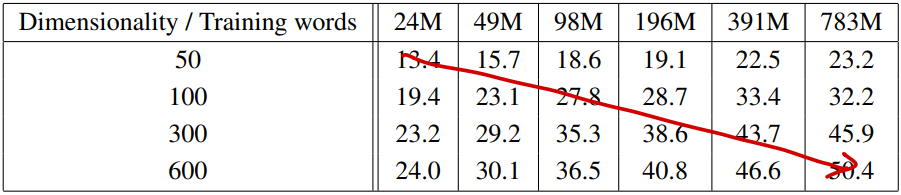
단어 벡터를 학습하기 위해서는 Google News 말뭉치(6B 토큰)를 사용하게 되는데, 이중 일부 고빈도 출현 단어 위주로 개수를 제한(최대 783M개)하여 학습하였고 evaluation을 위해서는 3만 개 단어를 사용하였다. 결과적으로 아래 표에서 확인할 수 있듯이 단어 벡터 차원과 학습 데이터 양에 동시에 비례하여 성능이 높아지는 것을 확인할 수 있는데, 특정 수준 이상의 차원과 학습 데이터에서는 증가폭이 감소하는 것 또한 확인할 수 있다.
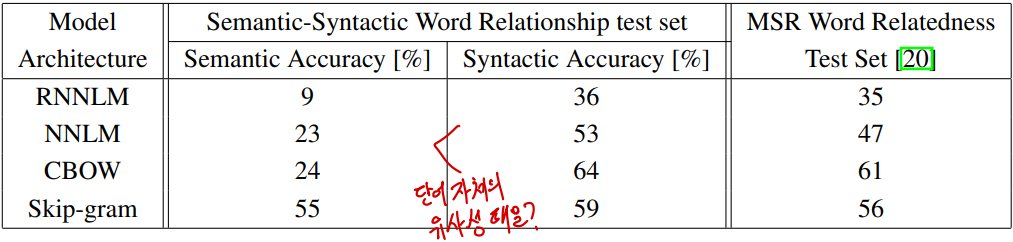
이후로 차원을 640으로 고정하여 기존의 NNLM, RNNLM과 비교한 성능은 아래와 같다. Semantic 테스트에서는 skip-gram이 압도적으로 높은 성능을 보이고, syntactic 테스트에서는 CBOW가 가장 높은 성능을 보이나 skip-gram 또한 NNLM이나 RNNLM 모델들보다는 높은 정확도를 보이는 것을 확인할 수 있다.
아키텍처 간 비교
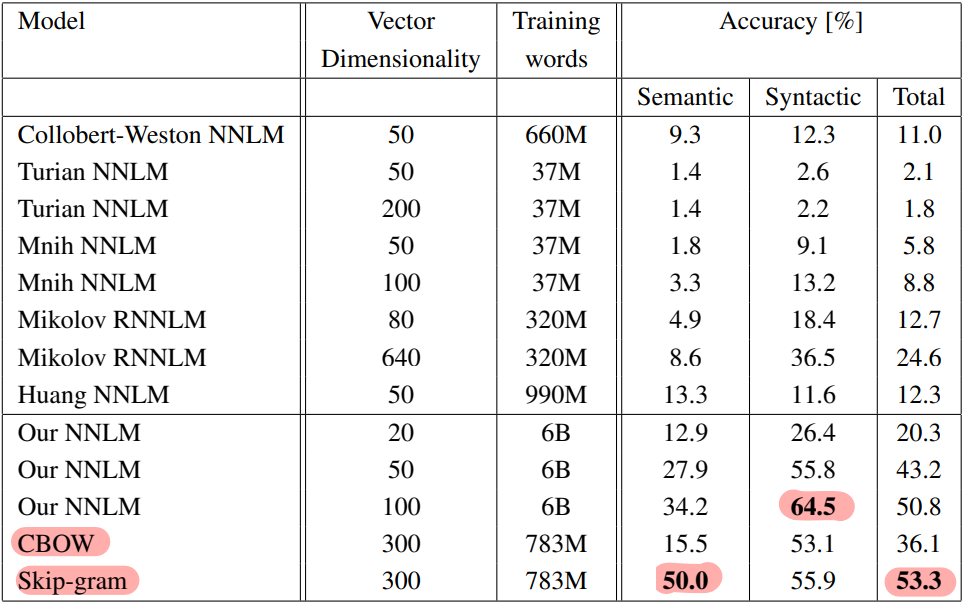
Legacy 모델들과 더 자세하게 비교한 결과도 있는데, 여기서는 이전 여러 저자들의 NNLM 및 RNNLM과 본 연구팀의 NNLM, 그리고 CBOW와 skip-gram을 비교한다. 학습한 데이터의 양이 크긴 해도 벡터 차원은 이전 모델들과 유사한데, 성능의 차이가 압도적으로 많이 나는 것을 확인할 수 있다. Syntactic 테스트에서는 6B 말뭉치를 전부 학습한 100차원의 NNLM이 가장 높은 정확도를 기록했으나, 전체 점수는 semantic 테스트에서 압도적인 차이로 50.0%의 정확도를 달성한 skip-gram에 밀리게 된다.
사족으로, 이 당시 보통의 NLP 모델은 semantic 테스트의 결과가 syntactic 테스트의 결과보다 압도적으로 낮은데, 모든 문장에서 조금씩 학습할 수 있는 텍스트의 구조적인 면보다 특정 문장들에서만 간혹 학습할 수 있는 의미론적인 면이 훨씬 적었을 것으로 예상한다. 혹은 그냥 단순히 단어 벡터 차원이 부족했을 수도 있다.
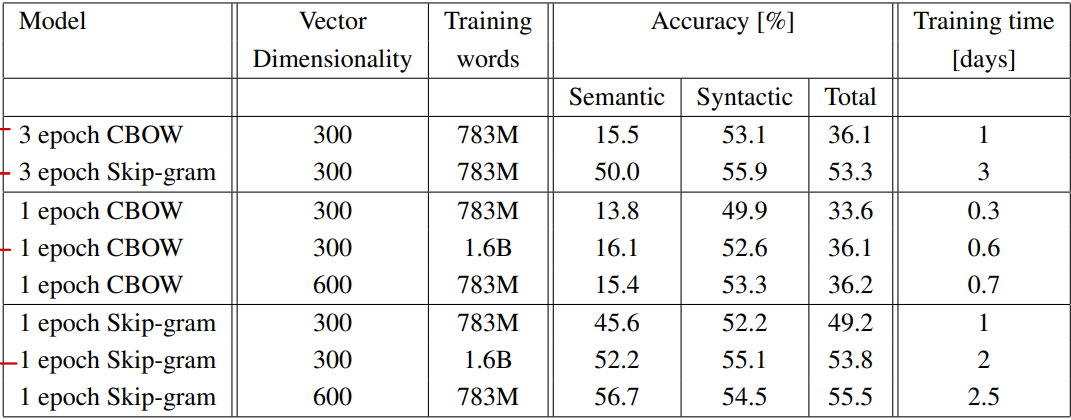
다음으로 제안된 CBOW와 skip-gram의 학습 조건에 따른 성능 차이를 비교하였다. 여기서는 최대 벡터 차원을 600까지, 학습 단어 수를 1.6B까지 증가시켰으며, 에포크는 3을 기준으로 1로 낮춘 실험 결과와 비교한다. 실험한 조건 상에서는 에포크, 벡터 차원, 학습 단어 수에 모두 비례하여 성능이 증가한다. 다만 주목해서 보아야할 점은 CBOW가 semantic 테스트에서 낮은 점수를 보이긴 하나 skip-gram보다 학습이 3배 가량 빨랐다는 점과, 데이터를 약 2배 증가(783M → 1.6B)시키는 것이 에포크를 3배 증가(1 → 3)시키는 것과 유사한 성능을 도출했다는 점이다.
병렬 학습 (DistBelief)
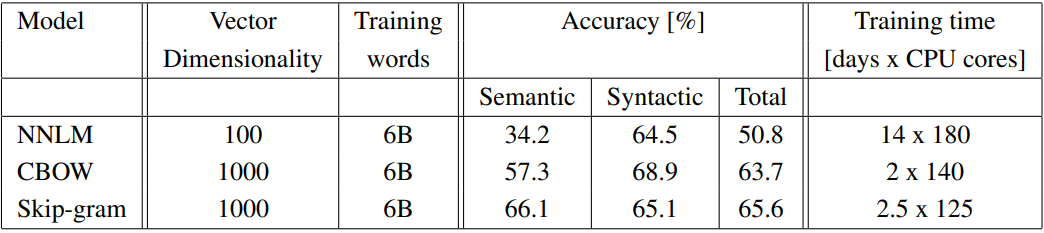
다음은 300차원, 783M 단어 학습으로 제한했던 기존 CBOW와 skip-gram의 성능을 최대화하기 위해 DistBelief 프레임워크를 사용해 병렬 학습을 진행한 결과이다. 벡터 차원은 1,000까지, 학습 단어는 제한없이 6B개를 모두 사용해 병렬 학습을 진행하였을 때, semantic 테스트와 syntactic 테스트 모두에서 비약적인 상승이 있었다. 1/10 수준의 차원을 가진 NNLM과 비교해 1/7 ~ 1/5 수준의 학습 시간이 소요되는 것은 물론 중요한 포인트이긴 하나 이 때는 학습이 CPU로 수행된 점을 감안해야 한다.
추론 예시 및 결론
마지막으로, 기준 모델인 300차원 + 783M 학습 단어 모델이 추론한 단어 관계의 예시를 보여준다. 실제로 전반적인 정확도가 60% 언저리이니 정답과는 먼 관계의 추론 결과도 포함되어 있다(e.g., copper/Cu - uranium/plutonium 등). 저자들은 더 큰 데이터셋을 활용하여, 관계 예시를 한 쌍보다 더 많이 제공하는 것을 성능 향상 방안으로 제시했다.
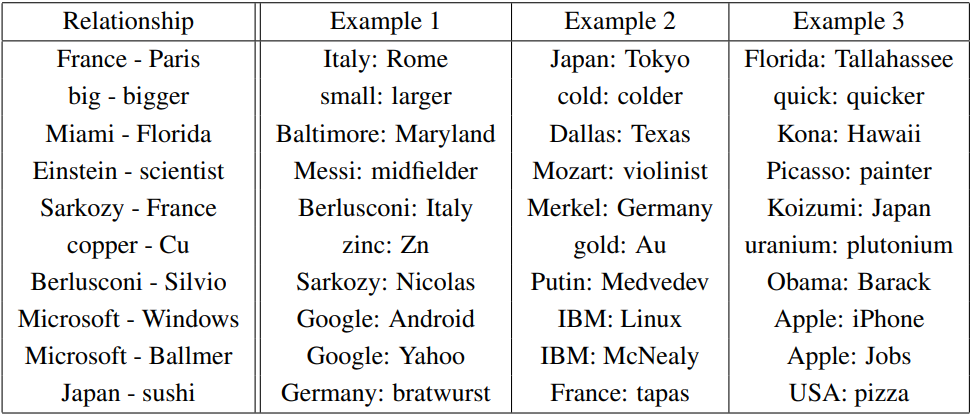
결론적으로 CBOW와 skip-gram의 Word2Vec 연구는 간단한 아키텍처로 고품질의 단어 벡터 학습을 가능하게 했으며, 병렬 컴퓨팅을 통해 이전 최고 규모보다 몇 배 큰 말뭉치에서도 학습이 가능해졌다(심지어 훨씬 빠른 속도로). 이 연구를 시초로 단어 임베딩은 negative sampling, GloVe, Seq2Seq 등의 방법론을 거쳐 transformer까지 발전하게 되었으며, 현대의 BERT, GPT까지 이르게 된다.
