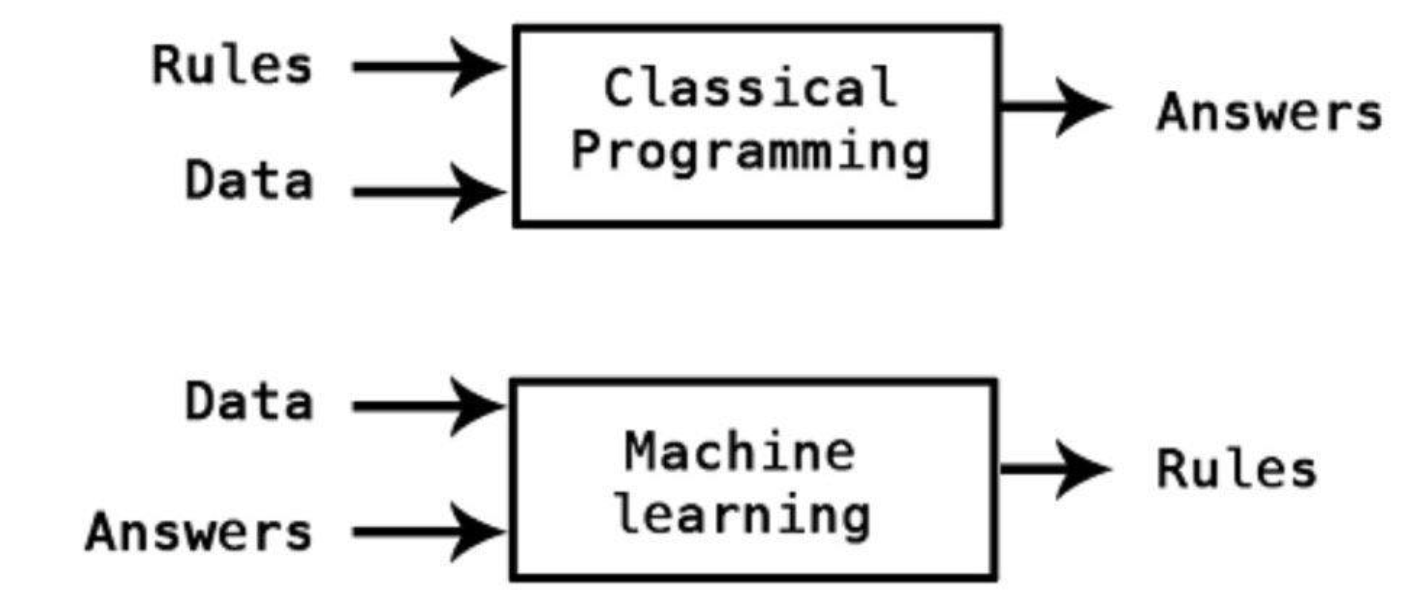
지도 학습은 두 가지 유형으로 나뉘는데, 바로 분류(classification)와 회귀(regression)이다. 이 두 가지 기법의 가장 큰 차이는 분류는 예측값이 카테고리와 같은 이산형 클래스 값이고, 회귀는 연속형 숫자 값이라는 것이다.
선형모델 (Linear Models)
- 선형회귀 직선은 독립변수(independent variable, x)와 종속변수(dependent variable, y) 간의 관계를 요약해 줍니다.
- fit() 메소드를 사용하여 모델을 학습합니다.
- predict() 메소드를 사용하여 새로운 데이터를 예측합니다.
- 기준 모델을 평균으로 사용
선형회귀모델의 계수(Coefficients)
# 계수(coefficient)
model.coef_# 절편(intercept)
model.intercept_다중선형회귀(Multiple Linear Regression)
- 단순선형회귀에서는 모델이 직선의 방정식으로 표현이 되었다면, 이번에는 특성이 두 개이므로 평면의 방정식으로 표현이 됩니다.
# 회귀식 만들기
b0 = model.intercept_
b1, b2 = model.coef_
print(f'y = {b0:.0f} + {b1:.0f}x\u2081 + {b2:.0f}x\u2082')Ridge Regression
정규화(regularization)을 위한 Ridge 회귀모델을 이해하고 사용할 수 있습니다.
Ridge 회귀는 기존 다중회귀선을 훈련데이터에 덜 적합이 되도록 만든다는 것입니다. 그 결과로 더 좋은 모델이 만들어 집니다.
Ridge 회귀를 사용하는 이유는 과적합을 줄이기 위해서 사용하는 것입니다. 과적합을 줄이는 간단한 방법 중 한 가지는 모델의 복잡도를 줄이는 방법입니다. 특성의 갯수를 줄이거나 모델을 단순한 모양으로 적합하는 것입니다.
모델학습에 있어서 편향(bias)과 분산(variance)의 영향에 대해 이해가 필요합니다. Ridge 회귀는 이 편향을 조금 더하고, 분산을 줄이는 방법으로 정규화(Regularization)를 수행합니다. 여기서 말하는 정규화는 모델을 변형하여 과적합을 완화해 일반화 성능을 높여주기 위한 기법을 말합니다.
정규화의 강도를 조절해주는 패널티값인 람다는 기울기를 조절할 수 있습니다.
람다(alpha)값이 0인 경우에는 OLS 와 같은 그래프 형태로 같은 모델 임을 확인 할 수 있고, 람다(alpha) 값이 커질 수록 직선의 기울기가 0에 가까워 지면서 평균 기준모델(baseline) 과 비슷해지는 모습을 볼 수 있습니다.
이 패널티값을 보다 효율적으로 구할 수 있는 방법에는 어떤 특별한 공식이 있는 것은 아니며, 여러 패널티 값을 가지고 검증실험을 해 보는 방법을 사용합니다. 교차검증(Cross-validation)을 사용해 훈련/검증 데이터를 나누어 검증실험을 진행하면 됩니다.
sklearn에서 내장된 교차검증 알고리즘을 적용하는 RidgeCV를 제공합니다.
# RidgeCV를 통한 최적 패널티(alpha, lambda) 검증
from sklearn.linear_model import RidgeCV
alphas = [0.01, 0.05, 0.1, 0.2, 1.0, 10.0, 100.0]
ridge = RidgeCV(alphas=alphas, normalize=True, cv=5)
ridge.fit(X_train, y_train)
print("alpha: ", ridge.alpha_)
print("best score: ", ridge.best_score_)원핫인코딩(One-hot encoding)
범주형(카테고리컬) 데이터를 행열로 나열해 숫자로 표현해 주는 기법.
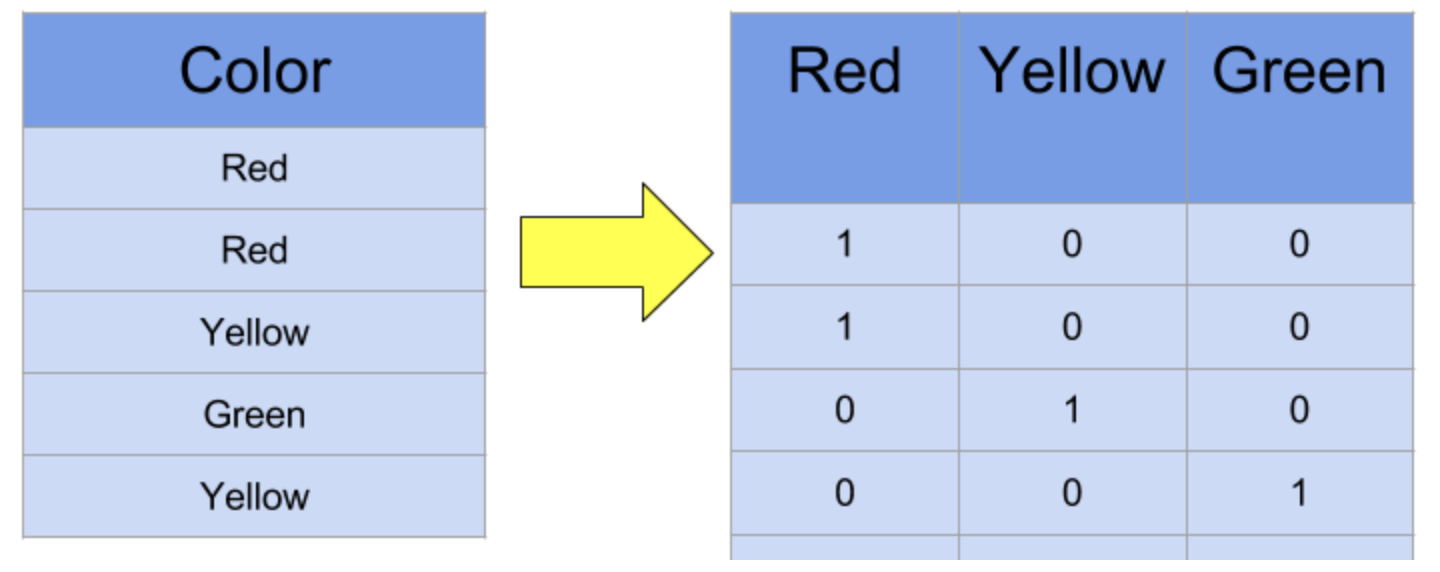
!pip install category_encoders
from category_encoders import OneHotEncoder
encoder = OneHotEncoder(use_cat_names = True)
X_train = encoder.fit_transform(X_train)
X_test = encoder.transform(X_test)
일변량 통계 기반 특성선택(Feature Selection) 과정을 이해합니다.
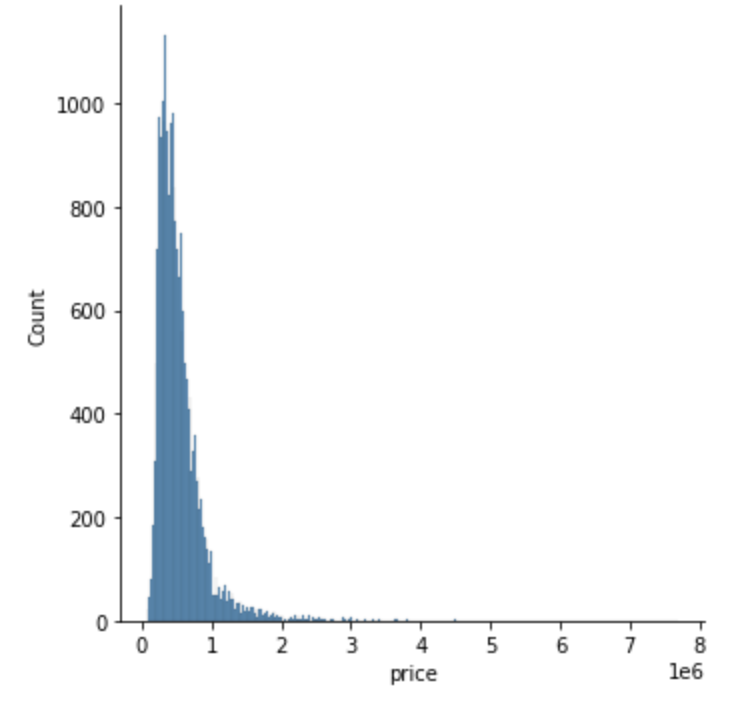
#np.percentile 사용해 이상치 제거
df = df[(df['price'] >= np.percentile(df['price'], 5)) &
(df['price'] <= np.percentile(df['price'], 95))]

Logistic Regression
- 로지스틱 회귀의 목적은 일반적인 회귀 분석의 목표와 동일하게 종속 변수와 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다.
- 독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀 분석과 유사하다. 하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류 (classification) 기법으로도 볼 수 있다.
분류문제는 회귀문제와 다른 기준으로 기준모델을 설정합니다.
- 다수 클래스를 기준모델로 정하는 방법(Majority class baseline) 에 대해 알아 봅시다.
- 회귀문제에서는 보통 타겟 변수의 평균값을 기준모델로 사용합니다.
- 분류문제에서는 보통 타겟 변수에서 가장 빈번하게 나타나는 범주를 기준모델로 설정합니다.
- 시계열(time-series) 데이터는 보통 어떤 시점을 기준으로 이전 시간의 데이터가 기준모델이 됩니다.
# mode(): Return the highest frequency value in a Series.
major = y_train.mode()[0]
# 타겟 샘플 수 만큼 0이 담긴 리스트를 만듭니다. 기준모델로 예측
y_pred = [major] * len(y_train)
# 최다 클래스의 빈도가 정확도가 됩니다.
from sklearn.metrics import accuracy_score
print("training accuracy: ", accuracy_score(y_train, y_pred))로지스틱회귀 모델을 만들기
from sklearn.linear_model import LogisticRegression
logistic = LogisticRegression()
logistic.fit(X_train_imputed, y_train)
print('검증세트 정확도', logistic.score(X_val_imputed, y_val))