Decision Trees
Random Forests
- bootstrap 샘플링을 통해 여러개의 데이터 세트를 복원 추출한다.
- Bagging: Bootstrap Aggregating
- 추출된 여러개의 샘플 세트을 가지고 각각의 '결정트리' 모델을 구현한다.
- [앙상블] 구현된 여러개의 '결정트리'들의 모델들의 예측결과를 다수결이나 평균을 내서 하나의 모델을 만듭니다.
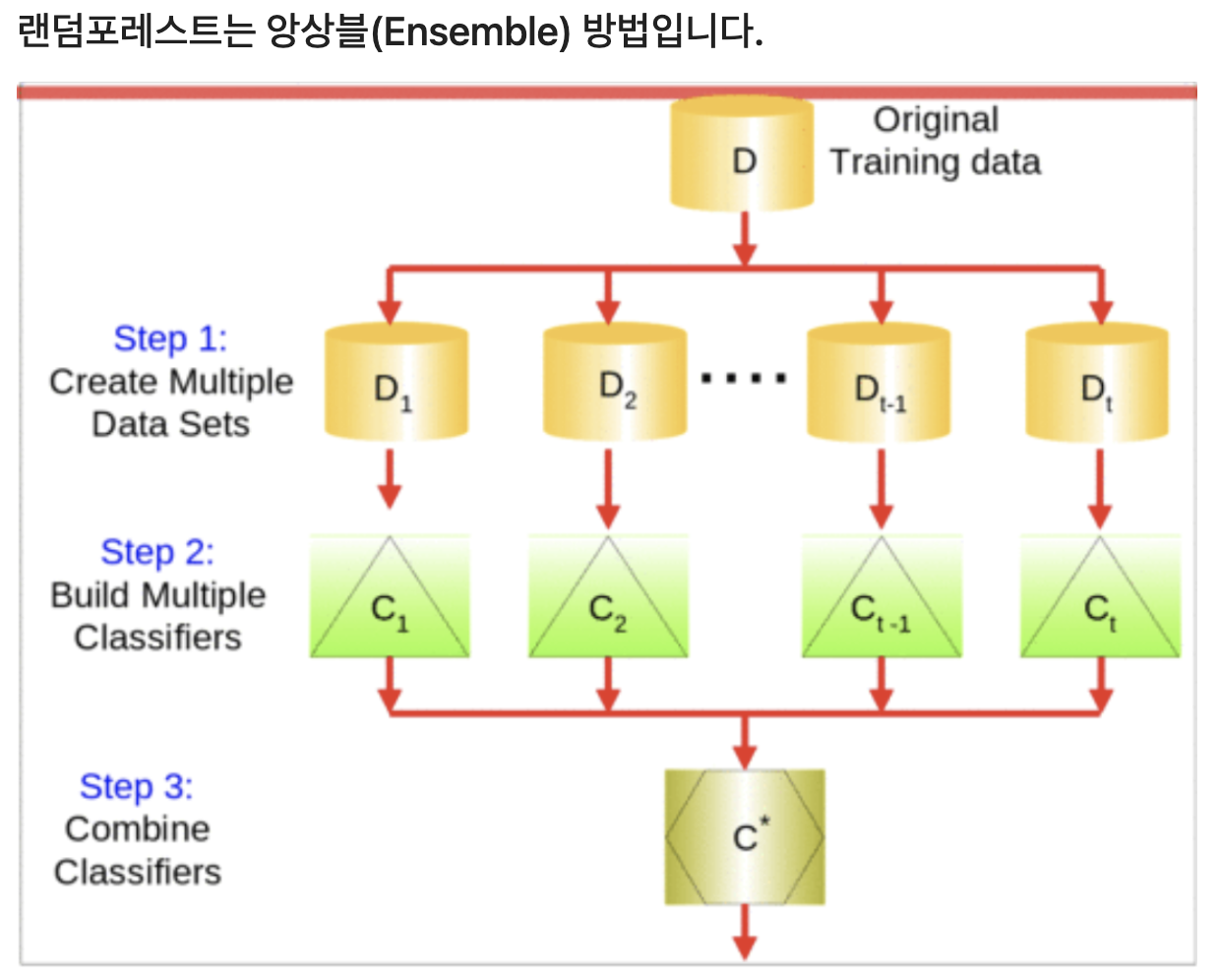
- 추출되지 않은 샘플을 Out-Of-Bag 샘플이라 부르며 이것들을 사용해 모델을 검증할 수 있다.
pipe.named_steps['randomforestclassifier'].oob_score_Ordinal Encoder
- 원 핫 인코더와 다르게 cardinality가 높은 특성을 각각의 특성으로 바꾸지 않고 그대로 유지 하는 것이다. 다만 숫자형으로 변환한다.
- 이때 장점은 가치가 높은 특성을 살릴 수 있어서 복잡하지 않게 구현할 수 있다는 것이고 단점은 숫자형으로 변하기 때문에 크고 작음을 인지하는 특성이 된다.
- 결정트리 및 랜덤 포레스트에서 순서형(ordinaly) 특성을 사용 할 수 있는 이유는 숫자의 크기 여부가 관계가 없기 때문이다.
- 즉, 특성의 중요도가 높을 수록 그리고 cardinality가 높을 수록 one-hot encoder를 사용하는 것을 지양해야 하며 ordinal encoder를 사용하여 특성의 효율을 올려 모델을 만드는 것이 좋다.
Decision Tree VS Random Forest
트리 앙상블 모델이 결정트리보다 상대적으로 과적합을 피할 수 있는 이유가 무엇일까요?
1. 랜덤 포레스트에서 학습되는 트리들은 배깅을 통해 만ㄷ르어진다. 각 기본트리에 사용되는 데이터가 랜덤으로 선택된다.
2. 각각 트리는 무작위로 선택된 특성들을 가지고 분기를 수행한다.
즉 랜덤성에서 과적합을 피할 수 있는 이유를 보여준다.Random Forest 알고리즘

Evaluation Metrics for Classification
Model Selection

Studying for Data Analysis, Data Engineering & Data Science