[논문리뷰] A Survey of Large Language Models
https://arxiv.org/abs/2303.18223
Introduction
PLM
- ELMO는 고정된 단어 representation 대신 양방향 LSTM (biLSTM)을 사전학습해서 문맥을 잘 아는 단어 표현을 포착하도록 고안되었다.
- Self attention 메커니즘은 병렬처리가 가능한 Transformer 아키텍쳐 기반으로 BERT는 대량의 unlabeled copora로 양방향의 언어모델을 사전학습한다. 사전학습 된 context-aware word representation은 문맥적인 feature로 매우 효과적이다.
LLM
- GPT-3는 incontext learning을 통해 few shot task를 해결한다.
- PLM과 LLM의 차이
1. LLM은 이너제 작은 PLM에서 관측되지 않은 emergent 능력이 발견된다.- LLM은 인간이 ai 알고리즘을 발전시키고 사용하는 방법에 대한 혁명이다.
- LLM의 발전은 더이상 리서티와 엔지니어를 구별하지 않는다.
- LLM과 human value 혹은 선호를 align 시키는 것에 대해 발전이 필요하며, 여전히 아래와 같은 영역에서 연구가 필요하다.
1. pretraining : capable LLM을 사전학습 시키는 방법- adaptation tuning : effectiveness와 safety 측면에서 효과적으로 사전학습된 LLM을 조율하는 방법
- utilization
- capability evalutaion
Overview
background of LLM
Scaling Law of LLMs
-
KM scaling law
- power law 관계 모델링
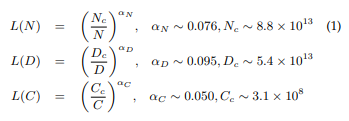
-
Chincilla scaling law (DeepMind)
- 하지만 ICL은 scaling law를 따르지 않는다.
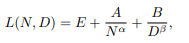
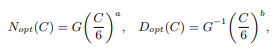
Emergent abilities
- In-Context Learning(ICL)
- 언어모델에 instruction과 task demonstartion (optional)이 제공된다면, 추가적인 학습이나 gradient update없이 input text의 word sequence를 완성함으로써 text instance에 대한 expected output을 생성할 수 있다.- GPT-3는 ICL 능력이 강해, 수학과 같은 추론 태스크에 강하다.
- Instruction following
- (unseen task) instruction tuning을 하기 위해 description로 포맷된 여러 태스크의 데이터셋의 혼합으로 파인튜닝함으로써 LLM은 instrunction 형식으로 기술된, 이전에 보지 않은 태스크에 대해 문제 해결이 가능하다.- (generality) Instruction tuning으로 예제 없이도 새로운 태스크에 대한 task instrunction을 따를 수 있다.
- LamDA-PT 68B
- (generality) Instruction tuning으로 예제 없이도 새로운 태스크에 대한 task instrunction을 따를 수 있다.
- step-by-step reasoning
- Chain-Of-Thought(CoT) promping 전략으로 intermediate 추론 단계를 포함한 프롬프팅 메커니즘을 활용하여 수학과 같은 추론 문제도 풀 수 있다.- 이러한 능력은 code를 학습함으로써 잠재적으로 얻게 되었다고 추론한다.
- CoT 프롬프팅은 60B PaLM과 LaMDA에 적용되었을 때 성능이점이 있었고, 모델 사이즈가 크면 클수록 그 이점이 더 크다고 밝혀져 있다.
Key technologies for LLMs
- scaling
- training
- DeepSpeed와 Megatron-LM과 같은 다양한 병렬처리 전략- 최적화 trick으로 훈련 안정성과 모델성능 향상 : 훈련 로스가 뛰는것을 막기 위한 restart, mixed precision training, GPT-4는 훨씬 더 작은 모델로 거대 모델의 성능을 예측하는 특별한 infrastructure나 최적화 기법을 제안
- emergent ability
- 적절한 task instruction이나 특정 ICL 전략- CoT 프롬프팅은 intermediate 추론 단계를 포함시켜 복잡한 추론 태스크를 해결하는데 유용
- 자연어로 표현된 task description으로 Instruction tuning을 수행하여 보지 않은 태스크에 generalizability 향상
- alignment tuning
- LLM 사전학습 copora의 데이터 특성을 포착하도록 훈련되었기 때문에 toxic, biased, harmful한 contents 생성 가능성이 높다.
- 따라서, InstructGPT에서는 LLM과 human value 혹은 preference가 일치되도록 (LLM이 expected instruction을 따르도록) RLHF를 도입하여 인간이 훈련 과정에 정교한 레이블링 전략을 취하는 접근을 취했다. - tools manipulation
- 계산기, 검색엔진, 외부 plugin을 사용하여 과거 수학과 코딩과 같은 비언어적인 표현이나 사전학습시 보지못한 데이터, 최신 정보에 대해 응답할 수 있도록 하였다.
technical evolution of GPT-series modules
early
- GPT-1
- decoder only- unsupervised pretraining & supervised finetuning
- GPT-2
- unsupervised multitask learner, ICL- multitask를 위해 텍스트 생성문제를 단어 예측문제로 바꿈
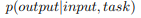
- multitask를 위해 텍스트 생성문제를 단어 예측문제로 바꿈
capacity leap
- GPT-3(175B)
- scaling parameters- ICL
- LLM을 fewshot, zeroshot으로 이용
- ICL은 LLM이 텍스트 형식으로 태스크를 이해하도록 학습시키거나 가르치는 것을 가능하게 한다.
- 사전학습은 context에 대한 조건부확률로 다음 텍스트 시퀀스를 예측하게 하는 반면, ICL은 태스크 description과 demonstration이 주어지면, 텍스트 시퀀스 형식으로 포매팅되어 올바는 태스크 솔루션을 예측할 수 있다.
- 추론이나 도메인 적용에도 가능하다.
- LLM을 fewshot, zeroshot으로 이용
- ICL
capacity enhancement
- 코드 데이터를 학습함으로써 추론능력과 CoT 프롬프트 능력이 향상되었다. text와 code 임베딩 학습을 위해 contrasitve 접근하였는데, 이로써 linear-probe 분류, text search, code search와 같은 태스크 성능 향상되었다.
- 강화학습으로 사람의 선호에 근접하게 학습되었다.
milestones of LLM
- ChatGPT
- 인간 같은 AI 시스템- InstructGPT와 비슷한 방식이지만 대화 데이터에 최적화 되었다.
- 유저와 AI가 만든 human-generated 대화가 InstructionGPT 데이터셋과 대화형식으로 합겨짐
- Knowledge, reasoning, multitun 대화에어 context 유지, safety 사용해서 human alignment
- GPT-4
- text input multimodal- more safety : RLHF 훈련에서 추가적인 safety reward signal로 반복하여 alignment
- read teaming 메커니즘을 사용해 보다 안전한 데이터를 생성함으로써 할루시네이션, 개인정보, 전반적인 이슈 완화
- 개선된 최적화 메서드 (predictable scaling) : 모델 학습동안 작은 양의 계산으로 final 성능 정확하게 예측
Resources of LLM
mainstream architecture
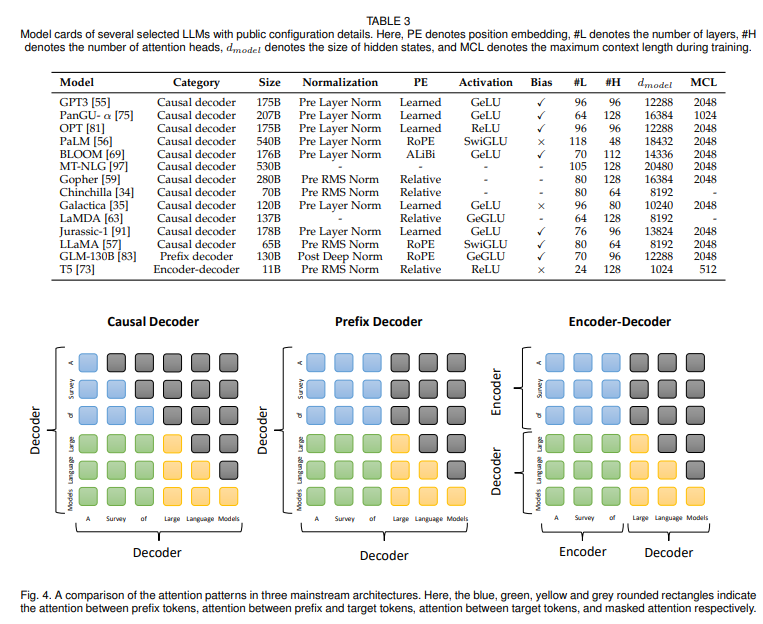
encoder-decoder architecture
- encoder : latent representation을 생성하기 위해 input sequence를 인코딩 하는 multihead self attention layuers 적재
- decoder : laent representation에 cross attention 수행, target sequence를 autoregressive하게 생성
- Flan-T5
causal decoder architecture
- 단방향 attention mask를 통합하여 각각의 input token은 오직 자신과 과거 토큰만 attend
- GPT-1, 2와 달리 scaling law에 따라 GPT-3에서는 ICL기능을 통해 효과를 증명하여 현재 널리 사용되고 있다.
- OPT, BLOOM, GoPher
prefix decoder architecture
- causal decoder의 masking 메커니즘 고안 : prefix token과 생성된 토큰에만 단방향 attention 수행
- 이러한 방식으로 enc-dec 구조처럼 prefix sequence에 양방향 인코딩 가능하여 autoregressive하게 아웃풋 예측 가능, 같은 파라미터는 인코딩 디코딩동안 공유됨.
- 수렴을 빨리 하기 위해서는 from the scratch로 사전학습 하는것 보다, causal decoder로 훈련하고, 훈련된 causal decoder를 prefix decoder로 바꾸는게 실용적이다.
-U-PalM, GLM 130B
mixture-of-expert(MoE)
- 위 세 종류의 아키텍쳐를 mixture-of-expert(MoE) scaling을 통해 각각의 input에 대한 가중치의 subset은 sparse하게 activated되어 있는 곳에 확장 시키는 것
- Switch Transformer, GLaM
Detailed configuration
normalization
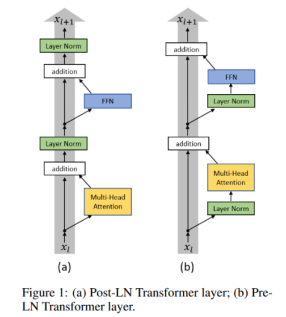
- Layer Normalization의 위치가 LLM의 성능에 강력한 영향을 미친다.
- 초기 트랜스포머에서는 post-LM을 사용했지만 LLM에서는 pre-LN을 사용하다.
- Sandwich-LN은 value explosion을 막기 위해 residual connection 전에 extra LN을 더하는 것인데, 학습 안정화에 실패하여 몇가지 advanced normalization 기술이 고안되었다.
- Gopher와 Chincilla에서는 학습 속도와 성능을 위해 RMSNorm(Root Mean Square Layer Normalization, 루트 평균 제곱 정규화)을 사용
- GLM-130B에서 post normalization으로 사용된 DeepNorm은 학습의 안정성에 있어서 좋은 성능을 보인다.
- 임베딩 레이어에 추가적인 LN을 다는것 또한 초거대언어모델을 안전하게 학습시킬 수 있지만, 떄때로 엄청난 성능 하락을 야기해 최근 LLM에서는 제거되었다.
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weightactivation functions
- 좋은 성능을 얻기 위해 활성화함수는 feed-forward 네트워크에서 적절하게 세팅되어야 한다.
- 기존 LLM에서는 GeLU 활성화함수가 널리 사용되었지만, 최근에는(PaLM, LaMDA) SwiGLU와 GeGLU같은 GLU의 변이 활성화함수들이 사용되고 있다.
- 그러나 GeLU와 비교했을 때, GLU 변이 활성화 함수들은 feed forward network에서 대량 50% 의 추가적인 파라미터를 요구한다.
class SwiGLU(tf.keras.layers.Layer):
def __init__(self, bias=True, dim=-1, **kwargs):
"""
SwiGLU Activation Layer
"""
super(SwiGLU, self).__init__(**kwargs)
self.bias = bias
self.dim = dim
self.dense = tf.keras.layers.Dense(2, use_bias=bias)
def call(self, x):
out, gate = tf.split(x, num_split=2, axis=self.dim)
gate = tf.keras.activations.swish(gate)
x = tf.multiply(out, gate)
return x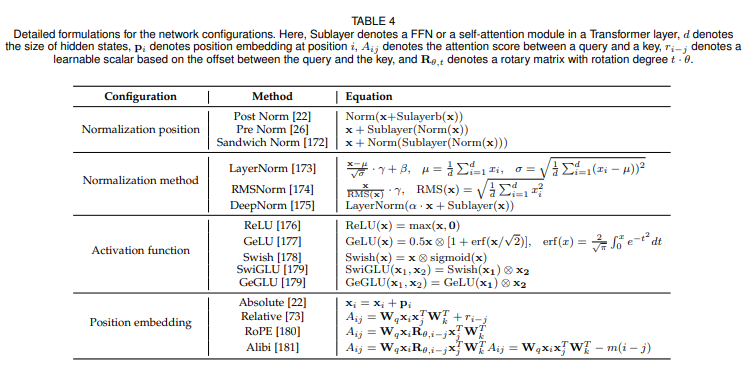
position embeddings
- absolute 포지션 임베딩에는 sinusoid와 학습된 position embedding이 있는데 후자가 초거대 언어모델에서 대게 사용된다.
- 현재까지 공개된 position infomation을 주입하는 방법들이 아직 efficient extrapolation을 얻지 못했다.
- extrapolation은 validation에서 모델이 학습한 토큰수를 증가시켜서 테스트를 할때 모델이 얼마나 잘 동작하는지에 대한 능력으로 정의
- 다른 포지션 임베딩보다 extrapolation이 강할 수록 zero shot이 더 좋은 것으로 연구결과가 있다.
- ALiBi(Attention with Linear Biases)는 word embedding에 positional embedding 값을 추가하지 않고, query-key 어텐션 스코어에서 각 거리에 따라 페널티를 주도록 어텐션 스코어를 수정한다.
- ALiBi는 네거티브한 바이어스를 어텐션 스코어에 추가하는 방법으로 쉽고 간편하게 적용할수 있다.- query와 key 사이의 거리에 따라 비율로 선형으로 페널티를 주는 방법을 사용
- 모델은 1.3B 모델에서 1024 학습 되고 2048 length 까지 extrapolate 한다.
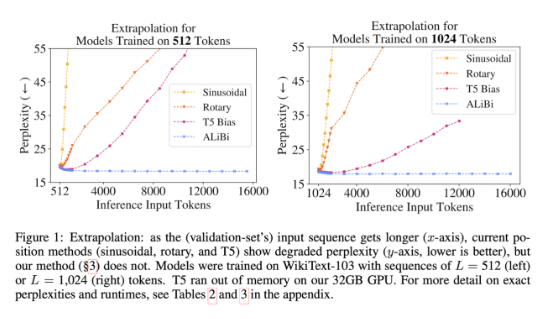
- query와 key 사이의 거리에 따라 비율로 선형으로 페널티를 주는 방법을 사용
- absolute position에 기반한 rotatory matrice외에도 RoPE는 GPT-J에서 공개되어 유명해진 position embedding으로 rotary method로 키와 쿼리간의 스코어를 계산하여 매 레이어마다 포지션 값을 주입해 긴 시퀀스를 모델링하는데 유용한 상대적인 포지션 정보로 계산될 수 있다.LLM에서 최근 많이 사용되고 있다.
attention and bias
- (Factorized attention) GPT-3는 full attention보다 더 낮은 계산 복잡도를 가진 sparse attention을 사용한다.
- 긴 시퀀스를 효과적으로 모델링하기 위해 special attention pattern 도입, flash attention같은 gpu memory 접과 같은 여러 시도가 이루어지고 있다.
- original transformer에 따라 대부분 초거대언어모델은 각각의 dense kernel에 biase와 layer normalization을 유지하지만 PaLM과 Galactia는 biase를 제거시켜 bias가 없는 것이 llm의 학습 안정성을 높여준다는 것을 보여주었다.
pre RMS Norm for layer normalization
- SwiGLU, GeGLU 활성화 함수
- Layer normalization은 성능저하를 야기시킬 수 있기 때문에 임베딩 레이어 바로 뒤에는 사용되지 않는다
- position embedding은 (RoPE, ALiBi) 긴 시퀀스에 효과적이다.
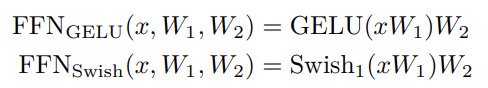
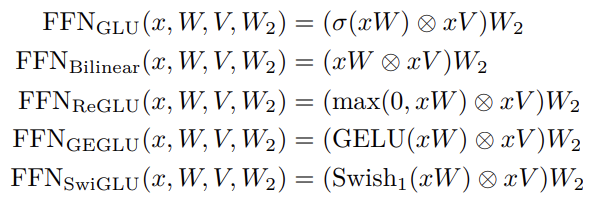
pretraining tasks
language modeling
- 대게 decoder only llm을 사전학습 목적식으로 다음 토큰은 autoregressive하게 예측함으로써 특정 태스크를 파인튜닝 없이 수행할 수 있다.
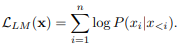
- prefix LM 태스크: prefix decoder 구조로 모델 사전학습을 위해 고안된 것으로
사전학습동안 봤던 랜덤으로 선택된 prefix 내에 있는 토큰들은 prefix LM의 로스 계산에 사요되지 않는다.
- prefix LM은 사전학습에 사용된 니퀀스보다 더 적은 수의 토큰들이기 때문에 lm보다 다소 성능이 떨어진다.
denoising autoencoding
- 사전학습에 활용되는 DAE
- T5 : autoregressive 방법으로 대체된 span을 예측하도록 하는 방법 - DAE task의 input은 랜덤으로 대체된 span으로 텍스트를 corrupt 시킨다. 다음, LM 은 corrupted text를 대체된 토큰 x로 회복시키도록 훈련된다.
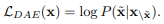
Summary & discussion
- 아키텍쳐와 사전학습 태스크의 선택이 초거대언어모델에 inductive bias를 유래할 수 있다.
- 언어모델 목적식으로 사전학습함으로써 causal decoder 아키텍쳐는 multitask finetuning 없이 월등한 제로샷 (퓨샷) 일반화 능력을 가진다.
- GPT-3는 큰 causal decoder 모델이 좋은 퓨샷 러너일수 있다는 것을 증명했다.
- Instruction tuning과 alignment tuning은 거대 디코더 모델의 능력을 향상시킬 수 있다는 것을 증명했다.
- 모델, 데이터셋, 계산의 scaling law는 causal decoder의 성능을 향상시켰다.
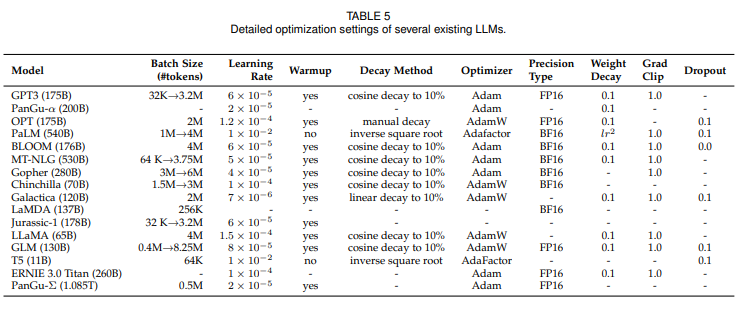
Model training
optimization setting
- batch training
- 기존에는 무조건 큰 수로 setting 했으나 GPT-3, PaLM이 학습하는 동안 dynamically 증가시켜 궁극적으로 million scale에 도달하도록 하는 dynamic schedule of batch size를 도입하였다. 이는 초거대언어모델의 학습과정을 효과적으로 안정화시킨다. - learning rate
- 기존에는 사전학습 동안 warm up과 decay 전략으로 lr을 스케쥴링했다.
- 학습 step 초기 0.1-0.5%에서는 linear warmup scheduling을 사용하여 lr을 증가시키고, 그리고 나서 cosine decay 전략을 취해 학습 로스가 수렴할때까지 maximum value의 대략 10%까지 lr을 점차 줄인다. - optimizer
- Adam, AdamW : first-order gradient 기반 최적화 기법으로 lower-order moment의 adaptive estimate
- Adafactor : PaLM, T5에서 사용되었으며 학습동안 Gpu 메모리를 보전하도록 고안되었다. - training stability
- 일반적으로 weight decay=0.1, gradient clipping=1.0
- 하지만 초거대언어모델에서는 학습 로스가 스파크 튀는 현상이 종종 발생한다 (불안정한 학습)
- 따라서 PaLM과 OPT는 로스 스파크가 발생하기 바로 직전의 체크포인트에서 학습 프로세스를 다시 시작하도록 하는 전략을 사용하여 문제를 일으킨 데이터를 건너 뛴다.
- GLM은 임베딩 레이어의 abnormal 그래디언트가 대게 스카프를 일으킨다는 것을 발견하고 이를 완화시키기 위해 임베딩 레이어의 그래디언트를 줄이도록 제안하였다.
scaliable training techniques
- 3D parallelsm
- Data parallelism : multiple gpu에 모델 파라미터, optimizer state 복제하여 분배한 corpus 학습 후 다시 aggregation- Pipeline parallelism : GPU마다 LLM의 다른 layer 분배하는 것으로 이전 layer가 다 학습되어야 그 다음 레이어 학습이 가능하기 때문에 bubbles overhead 가 발생한다. GPipe, pipedream은 파이프라인 효율화를 위해 multiple batch padding과 asynchronous gradient update에 대한 기술을 제안한다.
- Tensor parallelism : 텐서를 분해하는 것으로 A라는 텐서를 컬럼에 따라 A1, A2로 분해한다. Y=MA는 Y=[XA1, XA2]가 되어 A1, A2 분해된 텐서를 다른 GPU로 보낸다. matrix multiplication은 parallel하게 2개의 gpu에서 실행하고 final result는 gpu같의 cross communication을 통해 결합한다.
- ZeRO, FSDP(Fully Sharded Data Parallelism) (Deepspeed) : data parallelism의 memory redundancy 이슈를 해결하기 위해 각각의 gpu에 데이터의 부분만 보유하고 다른 데이터는 필요시 다른 gpu에서 retrieve 되게 수정하여 학습 데이터의 pararrel offloading을 가능하게 했다. 특히, ZeRO는 데이터가 어떻게 저장되는지에 따라 3가지 솔루션을 제안했는데 1) optimizer state partitioning 2) gradient partitioning 3) parameter partitioning, 1)2)는 copmmunication overhead가 증가하지 않고 3)은 50%가 증가하지만 gpu 수에 비례하여 메모리를 절약할 수 있다.
- Mixed Precision Training
- BERT는 FP32로, LLM은 FP16로 사전학습하여 메모리 사용량을 줄이고 communication overhead를 줄였다. 하지만 fp16은 정확성에서 로스가 발생할 수 있기 때문에 Brain Floating poing (BF16)을 학습할 때 사용했다. - Overall tarining suggestion
- GPT-4는 더 작은 모델로 큰 모델의 성능예측이 가능하도록
- 양자화로 추론 속도 향상 (INT8 quantization)
Adaptation tuning of LLM
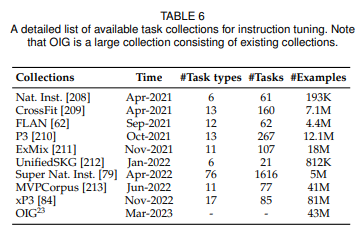
Instruction tuning
- Instruction tuning은 사전학습된 초거대언어보델을 자연어 형식으로 포맷된 인스턴스에 파인튜닝하는 접근법이다
- supervised 파인튜닝과 multi task promped training과 관련이 있다.
- process: instruction formatted instance 수집 -> 지도학습 방식으로 파인튜닝 -> instruction tuning후 심지어 multilingual 환경에서 보지않은 태스크에 높은 성능을 보임
formatted instance construction
- instance formatted instance는 instruction이라고 불리는 task description, input-output pair, 작은 수의 demonstrations(optional)로 구성되어 있따.
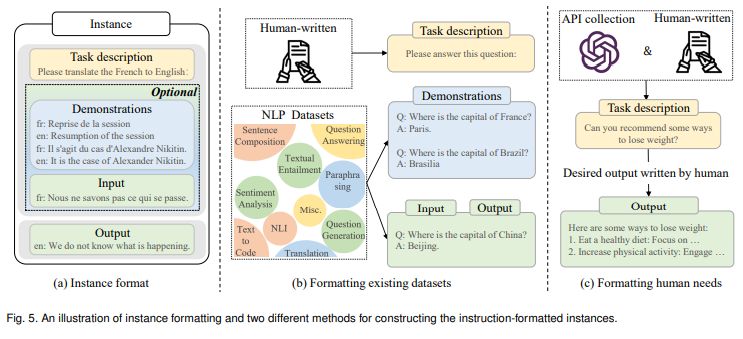
- 초거대언어모델이 task를 이해하도록 가르친다.
- 보지 않은 태스크에도 잘 작동하며 instuct가 초거대언어모델의 태스크 생성능력에 중요항 요인이며, instruction 수보다 다양성이 중요하다.
- demonstration는 CoT예제는 수리추론같은 문제에서 초거대언어모델이 단계별로 추론 능력을 이끌어낸다. LLM 파인튜닝을 cot 예제로 하느냐 안하느냐는 추론 task 뿐만 아니라 일반 상식 QA와 수리추론 같은 다양한 multi hop추론 task에 높은 성능을 보인다.
instruction tuning 전략 및 효과
- 사전학습과 달리 적당한 수의 인스턴스가 학습에 사용될 떄 더 효율적이다.
- instruction 튜닝은 지도학습으로 고려되기 때문에, 학습 목적식(seq-to-seq loss)나 최적화 configuration(작은 배치사이즈와 lr) 측면에서 사전학습과 다르다.
- 이것 외에도 데이터 분포의 균형과 instruction tuning과 사전학습의 결합은 중요하다.
- instruction tuning은 파라미터 수를 증가시키고 파인튜닝 없이 더 좋은 성능을 낼 수 있으며, 잠재적으로 emergent 능력을 획득하여 task generalization이 가능하게 한다.
Alignment tuning
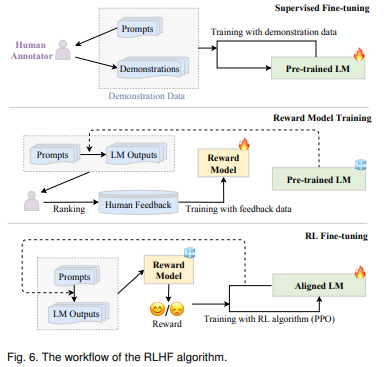
RLHF
1) 사전학습된 언어모델 (optional)
인간 레이블러에 의해 쓰여진 input prompts(instruction)과 언어모델을 파인튜닝하면 생성될 아웃풋 데이터로 지도학습
2) 인간 피드백으로 리워드 모델 학습
인간 피드백 데이터로 보상모델 훈련하는 것으로 특히, 언어모델과 sampled 프롬프트를 인풋으로 사용하여 특성 수의 아웃풋을 생성한다.
ai가 생성한 텍스트에 사람이 선호를 반영하는 가이드로 대게 align된 언어모델과 다른 스케일의 파라미터를 사용한다. (6B GPT-3)
인간은 모델이 생성한 아웃풋에 랭킹을 매기고 보상모델을 그 랭킹을 예측하도록 학습된다.
3) 언어모델을 훈련시킬 강화학습 알고리즘
보상모델로 부터 나온 시그널을 사용하여 사전학습된 언어모델 최적화
이 단계에서, 언어모델을 파인튜닝하는 것은 강화학습 문제로 푼다. 사전학습된 언어모델은 input으로 프롬프트를 받고 output을 return하는 policy로 행동하고 action space는 단어, state는 현대 생성된 토큰의 sequence, 보상은 보상모델에 의해 제공된다. 페널티 텀은 보상 함수로 통합된다. 예를들어 InstructGPT는 PPO 알고리즘을 사용하여 언어모델을 ㅁ보상모델에 최적화시킨다. InstructGPT는 각각의 인풋 프롬프트에서 현재 언어모델에서 생성된 결과와 초기 언어모델에서 생성된 결과를 페널티로 둘 간의 KL divergence를 계산한다.
2)과 3) 과정을 반복하여 더 낳은 초거대 언어모델을 만든다.
efficient tuning
- Parameter-Efficient fine-tuning methods
- Adapter tuning
- 작은 신경망 모듈(adapter)을 트랜스포머 모델에 통합시키는 것으로 어댑터 모듈을 실행시키기 위해 original 벡터를 더 작은 차원으로 압축시키고 다시 원래 차원으로 회복하는 보틀넥 아키텍처가 고안되어야 한다.
- 어댑터 모듈은 어탠션 레이어와 피드포워드 레이어 다음 serial insertion을 사용해서 각각의 트랜스포머 레이어로 통합된다.
- parallel adapter 또한 트랜스포머 레이어에서 사용될 수 있는데, 두개의 어댑터 모듈이 어텐션 레이어와 피드포워드 레이어와 병렬적으로 위치한다. 파인튜닝동안 원래 언어모델의 파라미터는 frozen시키고 어댑터 모듈만 최적화 시킨다. 이러한 방식으로 파인튜닝동안 훈련가능한 파라미터수를 효과적으로 줄일 수 있다.
- Prefix tuning
- Prompt tuning
- 인풋 레이어에 학습가능한 프롬프트 벡터를 통합한다.
discrete 프롬프팅 방법에 기반하여
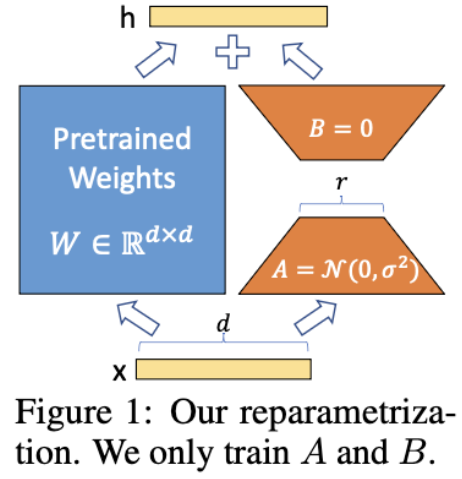
- Low-Rank Adaptation (LoRA)
- 각각의 dense layer에 업데이트 행렬을 근사하는데 low-rank 제한을 두어 학습가능한 파라미터 수를 줄인다.
- task adaptation을 위해 원래의 가중치 행렬은 frozen 시키고 low-rank 분해 행렬로 파라미터 업데이트를 근사시킨다.
- memory와 storate usage 절약
- 중요도 점수에 기반하여 rank를 정하던가 search-free optimal rank선택 방법이 있다.
Utilization
- 사전학습 또는 adaptation tuning 후에 다양한 문제를 풀기 위해 프롬프팅 전략을 디자인해야한다.
- 전형적인 프롬프팅 방법인 incontext learning은 task descriiption이나 demonstation을 구성한다.
- 이 외에도 chain of thought promping은 프롬프트에 중간중간 추론 단계를 넣어줌으로써 icl의 성능을 향상시켜준다.
In-Context Learning
- 특정 프롬프팅 형식인 icl은 gpt-3에 처음으로 고안되었다.
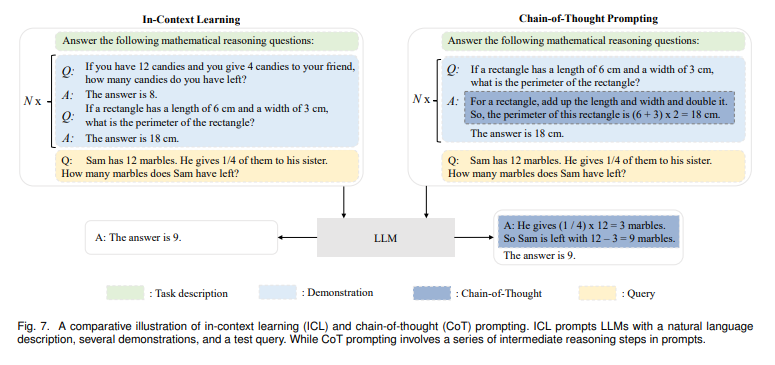
prompting formulation
- task description를 시작으로 데이터셋에서 몇가지 예제를 선택해 demonstartion으로 사용한다.
- 템플릿에 따라 프롬프트를 만들기 위해 description과 demonstration을 결합한다.
- 테스트 예제가 초거대 언어모델의 인풋으로 demonstartion에 추가되어 아웃풋을 생성한다.
task demonstation을 통해 초거대언어모델은 추가적인 그레디언트 업데이트 없이 새로운 태스크를 인지하고 수행할 수 있다.
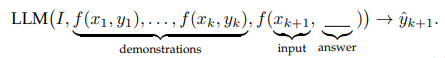
여기서 demonstartion을 구성한 예제를 선택하는 방법, 각각의 예제를 f함수로 프롬프트화 시키는 것, reasonable한 순서로 demonstation을 정렬하는 것이 중요하다.
- Instruction tuning은 adaptation을 위해 초거대 언어모델을 파인튜닝하여 특히 제로샷 환경에서 특정 태스크를 수행하기 위한 ICL능력을 향상시키는 반면 반면 ICL은 초거대 언어모델을 활용하기 위해 프롬프팅한다.
- [demonstation 선택] ICL의 효과는 demonstration에 크게 영향받는다. demonstation 선택은 heuristic과 llm 기반 접근이 있는데 llm 기반 접은은 example을 추가한 후 성능 gain 에 따라 각각의 example의 정보성을 직접적으로 측정하는 방식을 사용한다.
- EPR는 2단계의 retrieval 접근법을 제안한다. 1. BM25같은 비지도 메서드로 유사한 example들을 recall하고 dense한 retriever(llm으로 positive와 negative 예제라고 레이블된 데이터셋으로 훈현된)를 사용해서 랭킹을 매긴다.
- 이에 대안적인 방법으로 demonstration 선택의 태스크를 강화학습 문제로 풀어 llm을 policy 모델을 훈련시키기 위한 피드백을 제공하는 보상 함수로 사용한다.
- [demonstation 순서] 임베딩 공간에서 query에 유사한 정도에 따라 순서를 매긴다. global과 local entropy metrice는 다른 demonstaration 순서를 스코어링하는데 사용된다. llm에서 나온 validation data 그 자체를 sampling해서 ㅅㅁ나 ㅣㅁ디dmf wjsthdgksmsep vlfdygks zhem rlfdlfmf chlthghkgofk.
어떻게 사전학습이 ICL에 영향을 미쳤을까?
- ICL은 모델 사이트보다 사전학습된 copora의 근원에 더 강하게 의존한다는 연구 결과가 있다.
- 훈련 데이터 분포가 uniformly 분포 대신 다수의 infrequent 클래스에 클러스터링 되어 있을 떄 나타난다
어떻게 llm이 ICL을 수행할까?
- 추론단계에서 ICL의 능력이 주어진 demonstration에 근거한다는 것을 분석해본다.
- forward 계산의 평균으로 초거대언어모델은 demonstration에 관해 meta-gradient를 생성하고 어탠션 메커니즘을 통해 암묵적으로 gradient descent을 수행한다.- llm의 특정 어탠션 헤드는 태스크에 인지하는 오퍼레이션(복사와 prefix 매칭)을 수행하고, 이것이 icl과 밀접하게 관계가 있다.
- icl은 프로세스를 학습하는 알고리즘이다.
llm은 본질적으로 사전학습동안 파라미터를 통해 implicit model을 인코딩한다. icl에 제공된 example로 llm은 gradient descent와 같은 학습 알고리즘을 실행하ㄴ거나 forward 연산을 하면서 모델을 업데이트 시킨다. 이러한 프레임워크가 llm이 간단한 선형함수와 심지어 decision tree같은 복잡한 함수를 ICL로 학습할 수 있다고 본다.
Chain-of-Thoug prompting
- CoT는 충분히 큰 모델에서 긍정적인 효과를 가져온다.
Few-shot CoT
- ICL의 특별한 케이스로 cot 추론 단계를 통합하여 <input, output> 형식의 demonstration을 <input, cot, output>으로 증강시킨다.
- 여기서 CoT 프롬프트 디자인을 하는 법과 final answer를 유도하기 위해 생성된 CoT를 활용하는 법을 살펴보자.
- CoT 프롬프트 디자인
- Auto-CoT는 Zero-shot-CoT를 사용해 특별하게 llm을 프롬프팅 함으로써 cot 추론 과정을 생성하도록하여 매뉴얼 작업을 덜어준다.
- Auto-CoT는 더 나아가 훈련 셋에 있는 질문을 다른 클러스터로 나누고 각각의클러스터의 중심부에 가까운 질문을 선택한다.
- few-shot CoT는 ICL의 특별한 프롬프트 케이스로 고려될 수 있지만, demonstration의 순서는 ICL의 표준 프롬프트와 비교했을 때 훨씬 작은 영향을 미치고 있다.
- Enchanced CoT 전략
- self consistency : CoT와 final answer를 생성할 때 사용하는 새로운 디코딩 전략으로 우선 몇몇 추론 path를 생성하고 모든 대답을 앙상블한다.
- 다양한 추론 path
zero-shot CoT
- 퓨샷과 달리 사람이 어노테이션한 task demonstration을 포함하지 않는다.
- 그 대신 직접 추론 단계를 생성하고 대답을 이끌어내기 위해 생성된 cot를 사용한다.