Prompt engineering
Reasoning with Language Model Prompting: A Survey
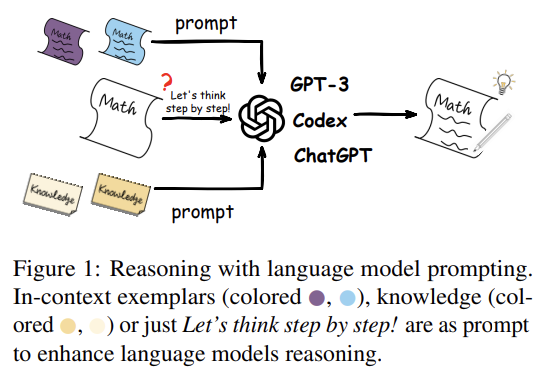
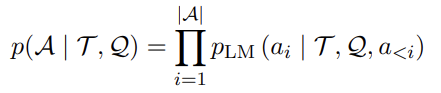
standard prompting은 reasoning question Q, prompt T, parameterized 확률모델 Plm이 주어지면 answer A의 likelihood를 최대화시키는 것이 목적이다. 여기서 |A|는 final answer의 길이, a는 i번째 토큰을 의미한다.
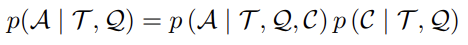
few-shot prompti에서 prompt T는 K개의 (Q, A)쌍으로 이루어져있고, CoT prompting은 프롬프트에 add reasoning step C가 추가된다.
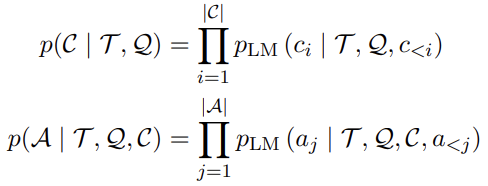
여기서 ci는 모든 |C| 추론 스텝 중 한 스텝을 의미한다.
언어모델 프롬프팅 추론 능력을 향상시키기 위해 두가지 연구가 있다.
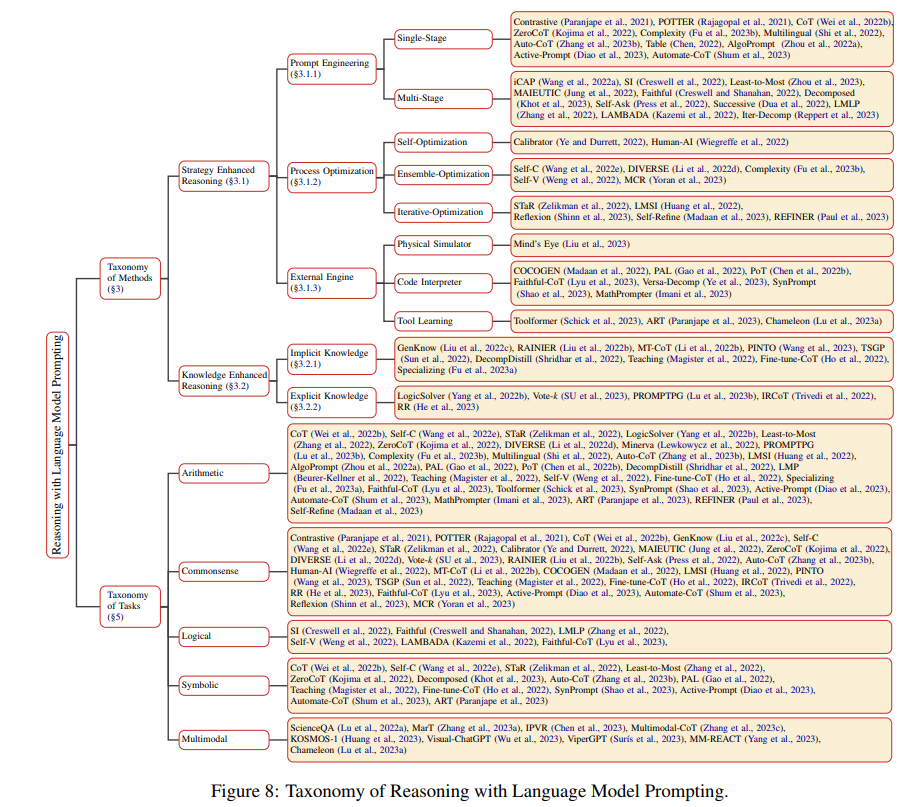
1. Strategy Enhanced Reasoning
1.1.prompt engineering
1) single-stage methods
LLM의 in-context learning 능력에 관련하여 few-shot prompt의 예제로 중간 추론단계를 더하는 CoT 프롬프팅이 제안되었다. CoT 프롬프팅은 큰 발전을 가져왔지만, in-context learning은 선택된 예제에 매우 민감하여 작은 변화가 모델 성능에 큰 drop을 가져오기도 하기 때문에 예제의 퀄리티가 중요하다.
prompt의 다양성과 퀄리티를 높이는 것이 중요하며, 클러스터링을 통해 프롬프트로 question을 얻는다. 더 명확한 설명과 자연어 instruction을 프롬프트로 함으로써 ood 문제에 직면했을 때 언어 모델의 애매함으을 완화할 수 있다. 언어 모델은 zero-shot reasoner이고 "let's think step b step" 혹은 Yann Lecun이라고 자아를 설정해주면 문제를 더 잘 푸는 현상이 있다.
2) multi-stage methods
복잡한 문제를 단계별로 쪼개는 것으로 질문과 중간 중간의 대답들을 프롬프트에 명확히 정의한다. 매 추론 단계에 (T, Q)의 context에 ci를 추가하거나 매 ci에 구체적인 Tci 디자인한다.
- 한 단계는 input-output 과정
1.2.process optimization
추론 절차의 일관성과 추론 단계간의 연속성은 final answer의 정확도에 영향을 준다.
1) self-optimization methods
seq-to-seq 모델을 필터로 하용하거나 점수 기반 예측 확률을 조정하는 calibrator를 사용하는 등 추가적인 모듈을 사용
2) ensemble-optimization methods
- 다양한 절차간의 calibration을 앙상블하는 것으로 sampling 전략을 도입하여 다양한 추론 과정을 얻고 majority vote에 의거하여 가장 일관성있는 대답을 생성하는 방법이 있다.
- step-aware voting을 통해 각 추론 path를 점수화하는 방법
final answer 집합을 얻기 위해 여러 과정을 거침
3) iterative-optimization methods
- 언어모델을 반복적으로 파인튜닝함으로써 추론 절차를 calibrate하는 방법으로, 일반적으로 LM이 추론 프로세스를 생성하고 생성된 추론 프로세스가 있는 인스턴스를 사용하여 스스로 파인튜닝하도록 프롬프팅 과정을 반복한다.
- plm을 생성된 (Q, C, A)에 파인튜닝하며 반복적으로 통합
- Question과 reasoning단계에서 파인튜닝을 위해 정답여부를 label로 태크를 달아 데이터에 추가
- 추후 self-teaching 단계에서 gold label이 필요 없다는 것이 밝혀짐.
- 여러 추론 ㄱ절차를 생성하며 스스로 생성한 답변 중 가장 일관성있는 답변에 파인튜닝하며 self-reflection을 반복한다.
1.3.external engine
프롬프팅으로 추론할 떄 모델은 질문에 대한 의미론적 이해와 추론 절차를 생성하는 것과 같은 복잡한 추론 능력을 가지고 있어야 한다.
1) Physical simulator
prompt T를 생성하기 위해, 직접 C를 실행시기키 위해, 혹은 추론을 위해 C에 API call을 심어둠으로써
2) Code Interpreter
- 퓨샷 프롬프트와 언어모델 아웃풋에서 구조화된 그래프로 표현하기 위해 자연어를 파이썬 코드로 대체함으로써 commonsense reasoning task를 conde generation task로 리프레임
- 언어모델에서 programmatic runtime으로 solution 스텝을 쪼개고 언어모델에 대한 학습 태스크만 남긴다. 퓨샷 프롬프트와 언어모델 아웃풋에서 추론 절차는 코드의 생성을 돕기 위해 자연어가 어노테이션으로 들어간다.
- Program of Thoughts(PoT) 프롬프팅은 언어모델을(주로 Codex) 사용해서 텍스트와 프로그래밍 언어를 생성하고 마지막 답변까지 생성

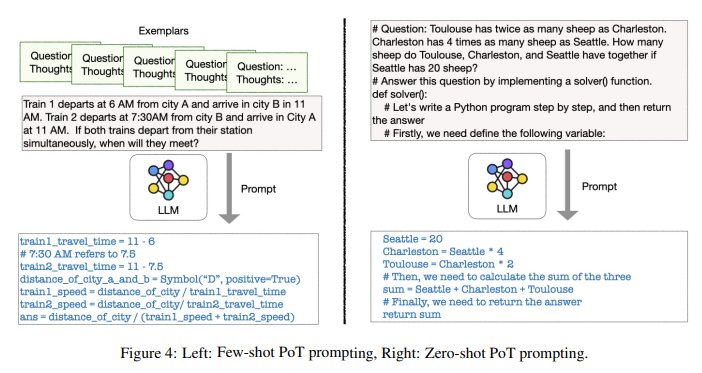
3) Tool learning
LLM이 외부 툴 사용할 수 있도록 결합
2. Knowledge Enhanced Reasoning
LLM은 상당한 양의 implicit 지식을 보유하고 있다고 여겨진다.
2.1.implicit knowledge
- 지식을 생성하도로 퓨샷 프롬프팅을 하거나 RL을 사용
- 추가적으로 대답 생성 프롬프트를 포함하는 두 단계 생성 프롬프팅 제안
- 큰 lm을 프롬프팅하여 작은 lm을 가르쳐 추론 샘플을 생성하는 지식 경량화
2.2.explicit knowledge
- 할루시네이션가 일관되지 않은 지식을 생성하는 경향을 줄이기 위해, 최근 in-context learning에 retrieving prompt
- 구조화된 정보의 유샤성을 측정하는데에 일반적인 retrieval 접근 방식의 불안정하기 때문에 brute-force searching 없이 policy gradient 전략에 기반한 dynamic prompt retrieval method 제안
- 더 신뢰성 있는 대답을 제공하기 위해 CoT의 추론단계에 기반하여 관련 지식을 retreive하는 방법 제안
- CoT 프롬프팅을 복잡한 멀티 스텝 추론에서 필요호하는 오픈 도메인 knowledge-iontensive 태스크를 위해 위키독스를 지속적으로 retrieve함으로써 augment
Coomparison and Discussion
Comparison of LM
- emergent 능력 : 저장된 지식이 일정 수준에 다다르면, 언어모델의 추론능력은 양적변화에서 질적 변화를 겪는데, 모델이 100B보다 클 때 발현되며, 모델 사이즈 뿐만 아니라 사전 학습된 데이터의 퀄리티와도 깊은 관계가 있다.
- 코드는 추론에 더 유사한 텍스트 형식으로, procedure-oriented 프로그래밍은 단계별로 문제를 푸는것과 유사하고, object-oriented 프로그래밍은 복잡한 문제를 간단한 문제로 쪼개는 것과 비슷하다. 이에 코드에 대한 사전학습은 코드 생성/이해 능력을 갖출 수 있었을 뿐만 아니라 CoT로 추론능력을 발현시키는 트리거가 되었다.
- CoT는 학습 데이터가 로컬 구조를 나타내는 경우에만 유용합니다. CoT는 여러 변수를 탐색하여 추론에 대한 전문 지식으로 인해 동일한 컨텍스트에서 거의 발생하지 않은 두 변수 간의 관계를 추론하는 데 탁월합니다. 그러나 훈련 데이터에서 자주 발생하는 변수로 추론할 때 단순한 통계 추정기보다 성능이 좋지 않을 수 있습니다.
Comparison of Prompt
1) Manual
-
Template-based prompt
-
few-shot prompting
2) LM generated prompt
질문에 대한 구체적인 rationale을 커스터마이즈해서 프롬프트로 파인튜닝이나 self-training을 위해 충분한 지식을 제공할 수 있다.
3) Retrieval-based prompt
위키피디아같이 잘 annotated된 외부 자원에 의존하는 것으로 비싼 정보 탐색 비용이 들지만, 생성에 불안정한이슈를 완화해 줄 수 있다. -
퓨샷 프롬프트에 CoT를 포함하고 있는 exemplar들은 초거대언어모델에 숨겨진 추론 능력을 불러일으키는 일종의 instruction으로 볼 수 있다. 이는 instruction finetuning에 CoT를 사용해서 모델 성능을 더 향상시킴으로써 비슷한 결과로 증명된 바가 있다.
-
in-context learning은 일반적인 프롬프트에서 인간이 읽을 수 있는 instruction으로 진화된 중간 단계로 볼 수 있따.
CoT promping은 언어모델이 사람의 추론과정을 모방하는 문장들을 생성하
Resources
- ThoughtSource
- CoT추론 관련된 데이터와 툴에 관한 오픈소스
- https://github.com/OpenBioLink/ThoughtSource
- Langchain
- LLM으로 어플리케이션 개발 가등하도록 돕는 라이브러리
- https://github.com/hwchase17/langchain
- lambdaprompt
- 초거대 언어모델 기반 맞게 self-edit하고 실행코드를 self-write할 수 있는 prompt machine 빌딩
- https://github.com/approximatelabs/lambdaprompt
- EasyInstruct
- GPT-3처럼 LLM을 instruct하기 위한 파이썬 패키지
Conclusion
- LLM은 emergent zero-shot과 추론 능력을 가지고 있다는 것이 증명되었다. 이에 연구자들은 in-context learning과 rationale를 explore하고 있다.
- 효율적인 추론을 하기 위해 큰 언어모델의 능력을 knowledge distillation 깁버을 통해 작은 언어모델로 전이하는 연구와 retrieval augmentation, model editing, delta-tuning 등과 같은 방법들이 연구되고 있다.
- Robust, Faithful and Interpretable Reasoning
- zeroshot CoT는 예상치 않은 toxicity와 biases를 생성할 수 있다.
- Selection-Inference는 신뢰도가 높은 추론을 위해 multi stage로 구성한 것으로 각각의 단계에서의 설명력이 부족할 수 있다.
- Code based는 외부 툴을 사용해야 한다.
- 확률 프로그램
- nueral symbolic approach
- human feedback
- Multimodal Reasoning
- model chain 다른 modality의 모델간의 interactive reasoning을 수행하기 위한 방법으로 GPT-3같은 경우 멘탈 상태, 리액션에 대한 추론이 부족한데, interactive reasoning 방법은 인지 과학과 사회 지능과 같은 도메인에서 영감을 불러일으켰다.
- Generalizable (True) reasoning
analogy reasoning, causal reasnoning, compositional reasoning등과 관련이 있다.
Self consistency
PLM과 CoT 프롬프팅의 결합은 복잡한 추론문제를 푸는데 괄목할만한 성과를 보였다. 다양한 decoding 전략이 있는데, self consistency 방식은 기존의 greedy decoding 방식을 대체하며 훨씬 더 높은 성능을 보인다. 일반적으로 arithmetic과 commonsense reasoning와 같은 정답을 찾는데 다양한 추론과정이 존재하는 복잡한 추론문제에서 강하며, sample-and-rank, beam search, emsemble기반 접근 보다 성능이 높고, temperature, top-k, nuclues 샘플링 전략과 견줄만하며, 완벽하지 않은 프롬프트에 강하다.
저자는 sample-and-marginalize 디코딩 절차를 아래와 같이 제안하며, 이로써 반복과 local-optimality를 피할 수 있다.
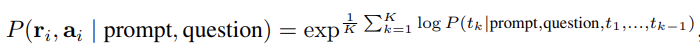
- 언어모델은 manually 쓰여진 cot examplar로 프롬프팅
- 다양한 candidate reasoning paths를 생성하기 위해 디코더에서 candidate output 샘플링
(다양한 reasoning paths는 다양한 final answer) - 샘플링된 reasoning path를 marginalize out 하여 가장 일관된 대답 선택
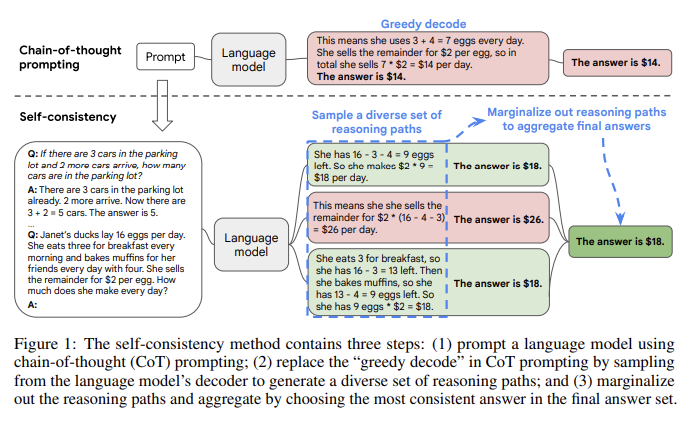
self consistency는 비지도이고 추가적으로 어노테이션, 학습, 파인튜닝 등이 필요하지 않으며, self-ensemble과는 다르다.
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Chain-of-thought(CoT) 프롬프트는 다양한 자연어 추론 태스크에서 놀랄만한 성과를 보였지만, 프롬프트에서 봤던 exemplar보다 어려운 문제를 푸는데에 있어서는 저조한 성능을 보입니다.
이에 본 논문에서 제안하는 leas-to-most prompting 방법은 복잡한 문제를 간단한 서브 문제들로 쪼갠 후, 이전 단계의 서브 문제에 대한 답을 이용해서 문제를 푸는 전략입니다.
symbolic manipulation, compositional generalization, math reasoning와 같이 easy-to-hard generalization 문제의 경우 일반적으로 프롬프트에서 본 것보다 훨씬 어려운 문제를 풀기 때문에 least-to-most prompting에 높은 성능을 보인다.
아래 두 단계로 진행되는데, 각각의 단계는 모두 퓨샷 프롬프팅으로 진행되기 때문에 training이나 파인튜닝이 필요 없다.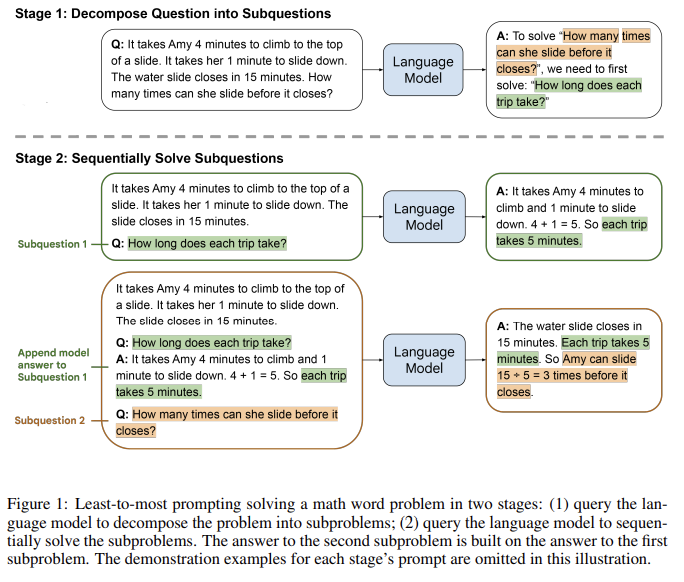
1. 분해 : 언어모델은 원래 문제를 서브 문제로 나누고, 모델을 통과한 프롬프트는 분해되야 하는 구체적인 문제에 따라 복잡한 문제를 어떻게 분해하는지 설명한 예제로 구성된다.
2. 서브문제 풀기 : 언어보델이 서브 문제를 순차적으로 풀며 나온 대답은 다음 모델에 프롬프트로 구성된다.
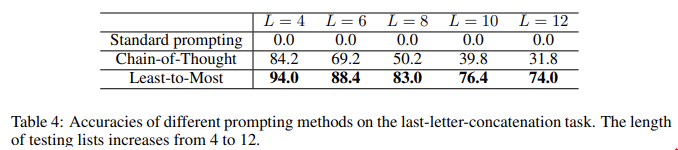


composite prompting
Reference
https://arxiv.org/abs/2212.09597
https://arxiv.org/abs/2203.11171
https://arxiv.org/abs/2205.10625
