
CS231n강의를 듣고 과제를 하다보니 조금 쳐져서 캐글 필사를 하기로 했다!
간단하게 마스크 디텍션을 해보기로 했다
내가 필사한 커널은 다음과 같다.
Face Mask Detection-Using PyTorch
Colab에서 필사를 진행했다.
세세하게 정리할거라 여러번에 나눠서 포스팅할 예정
About Data
데이터와 그에 대한 설명은 아래 링크에서 확인할 수 있다.
Face Mask Detection
해당 데이터셋은
3개의 클래스에 속한 853개의 이미지로 이루어져 있다.
✅ 3개의 클래스
With mask
Without mask
Mask worn incorrectly
bounding box는 PASCAL VOC 형식.
❓PASCAL VOC란
image detection을 위한 dataset으로 classification, object detection, segmentation 평가 알고리즘을 구축하거나 평가하는데 매우 유명한 데이터 셋
보통은 이래와 같은 형식VOC20XX ├── Annotations ├── ImageSets ├── JPEGImages ├── SegmentationClass └── SegmentationObject인데! 위의 데이터 다운로드 받으면
archive ├── Annotations ├── ImageSets이런 형식으로 되어있음. 우리는 Object Detection만 하기 때문에 Segementation 관련 데이터는 필요 없기 때문
여기서,
-- Annotations: 원본 이미지의 .xml 파일들
-- ImageSets: 이미지들을 test,train,trainval, val 로 구분해서 사용하기 위한 파일들
- 이미지 파일은 PNG,
- Annotation은 XML 형식으로 이루어져 있음.
Import Libraries
사용할 라이브러리들을 임포트
xmltodict 설치하고 임포트 해줌
- xmltodict
- parse function을 사용하면 xml을 JSON으로 변환해줌
👉 parse된 xml_parse를 json.dumps를 통해 dictionary문자열로 바꾼 후에, json.loads를 통해 python에서 읽을 수 있는 dictionary형으로 바꿈!
- unparse function을 사용하면 다시 xml로 바꿀 수 있음
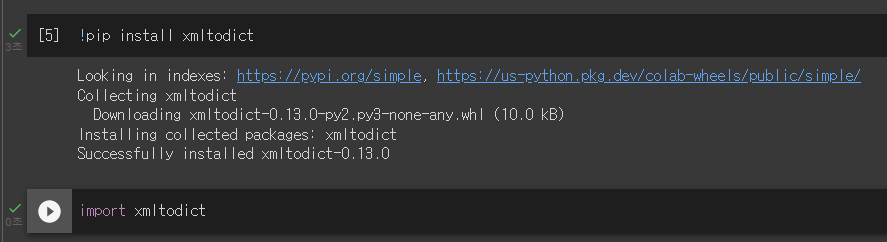
Extraction of Images and Annotaiton
구글 드라이브에 데이터 올려놓고 os.walk로 파일 읽어오기
os.walk()
-- 하위의 폴더들을 for문으로 탐색할 수 있게 해줌.
-- 인자로 전달된 path에 대해서 다음 3개의 값이 있는 tuple을 넘겨줌!
- dirpath : dirnames와 filenames가 있는 path
- dirnames : dirpath 아래에 있는 폴더들 (subdirectory)
- filenames : root 아래에 있는 파일들 (non-directory)
아래 코드에서는
dirpath = dirname
dirnames = _
filenames = filenames if os.path.join(dirname, filename)[-3: ]!="xml":
👉 파일이름을 끝에서부터 3개 읽어서 xml인지 아닌지 확인 (확장자 확인)
xml이 아니면 → 이미지 파일
xml이면 → annotaions

✅ 이미지 파일과 그에 해당하는 annotation파일.
✅ <'annotation'>안에 <'object'>에 class가 정의되어있는 것을 확인할 수 있음.
[1] path_annotations : 어노테이션 파일(.xml)이 저장되어있는 경로
list
[3] 이미지 파일과 어노테이션 파일은 확장자만 다를 뿐 이름은 똑같음
[4] 이미지파일이름에서 마지막 4글자 빼고(.png) 뒤에 .xml 붙여서 엶.
→ xml 파일 경로명
[5] doc = 해당 xml파일을 parse
[6] temp= 해당 파일의 클래스
[7] temp가 리스트 형식이면 (즉, 하나의 이미지에 여러 클래스들이 존재하면 - 한 이미지에 사람이 여러명)
[8][9] 싹 다 저장
[10][11] 아니면 한개만 저장하면 댐~
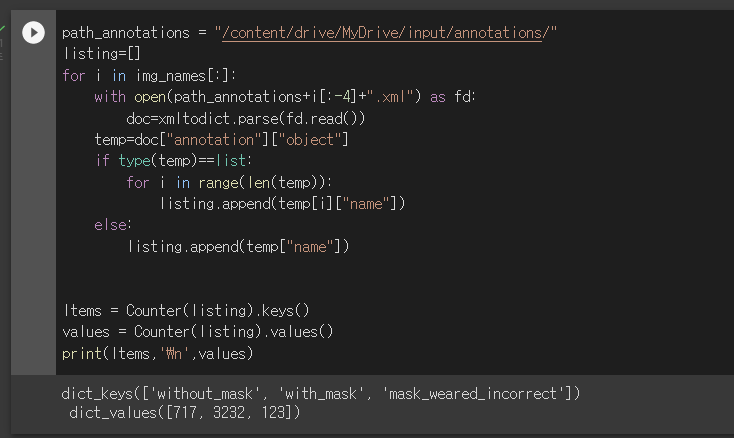
[13] key 개수 = 클래스개수 3
[14] 각 아이템의 개수 = 클래스별 이미지 개수
Visualisation and Analysis of Target Class
subplot
- 여러개의 그래프를 그려주는 함수
- figure (fig) = 전체 사이즈
- axes (ax1, ax2) = 전체 중 낱개의 그래프
pie
- 원 그래프
- parameter
- values = 각 아이템들의 개수(비율)
- wedgeprops = 부채꼴(너비3, 테두리 흰색)
- labels = 이름,
- radius = 그래프 반지름,
- startangle = 시작각도 120,
- autopct = 소수점 2번째까지 표시
bar
- 막대그래프
- parameter
- items = 각 아이템들의 개수
- list(values).color = 막대그래프 색(maroon)
- width = 그래프 너비(0.4) 디폴트 값은 0.8
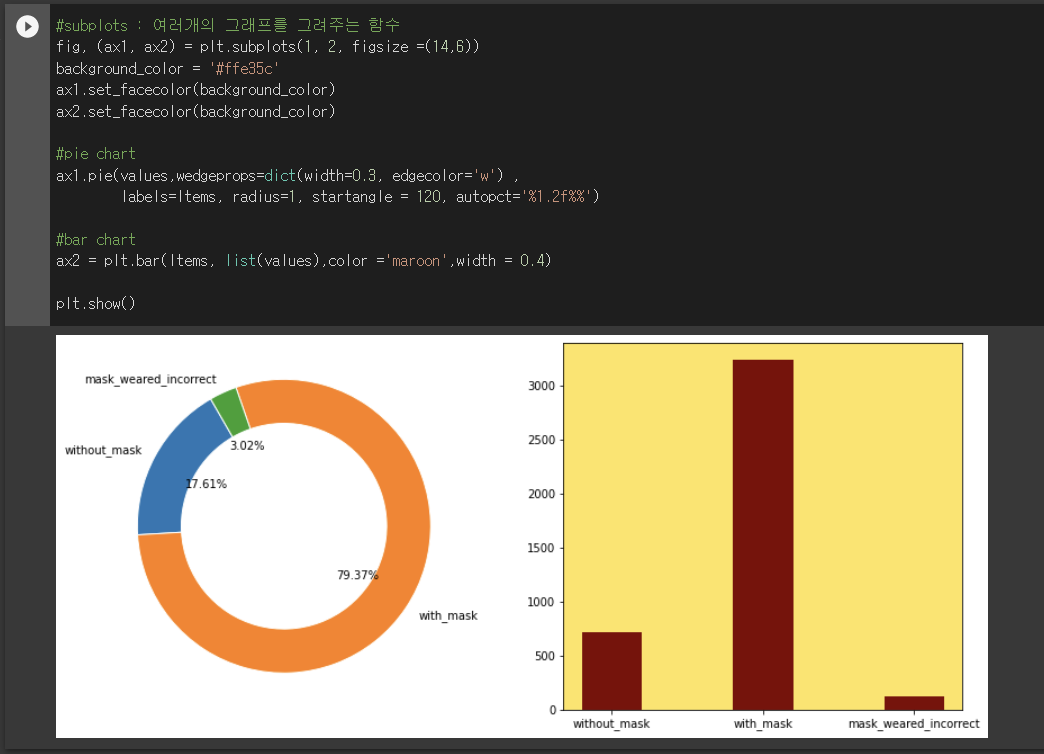
데이터셋이 다음과 같이 구성되어있음을 알 수 있다!
👉 without_mask : 17.61%
👉 with_mask : 79.37%
👉 mask_weared_incorrect : 3.02%
Reference
https://velog.io/@bigjoon/VOC-포맷-데이터-정리하기-1
https://codechacha.com/ko/python-walk-files/
