신경망 모델 학습의 목적은 Loss(error)을 최소화하는 과정이다. 이를 위해서 loss function에 대해 gradient descent를 수행했다.
만약에 어떤 데이터셋의 loss function 그래프가 아래와 같이 생겼다고 했을때 동일하게 gradient descent를 따라서 내려가더라도 도달하는 최저점이 다른 것을 알 수 있다.
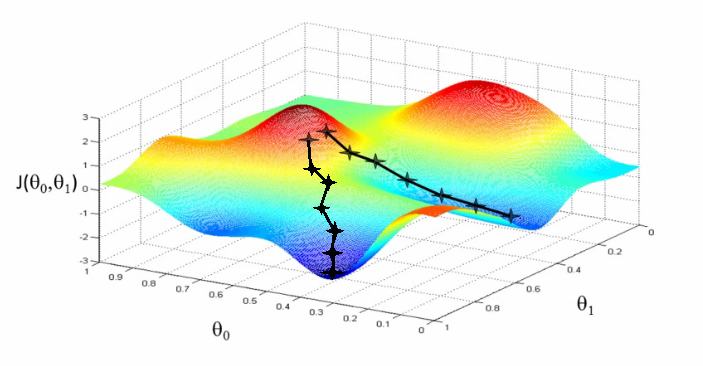
만약에 오른쪽 봉우리 어딘가에서 시작한다면 같은 지점에서 시작한다면 아래 새로 생긴 경로를 따라서 학습될 수도 있다. 이 경로를 따라 나온 최저점은 앞선 두 결과의 최저점보다 훨씬 더 크다.
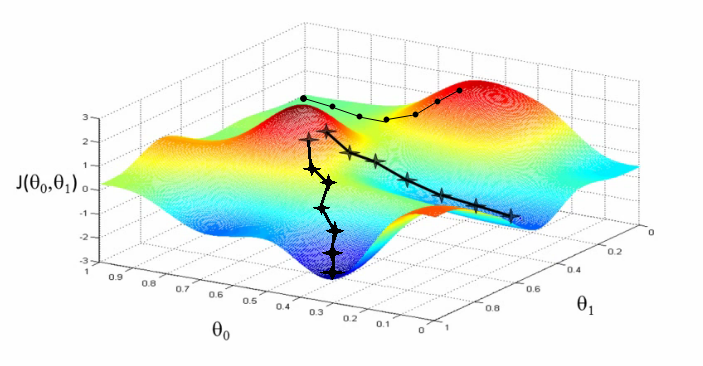
이처럼 첫 위치를 잘 정하는 것은 좋은 학습을 위한 조건 중 하나이고 가중치의 초깃값은 신경망 학습에서 중요한 요소 중 하나이기 때문에 가중치의 초깃값을 어떻게 설정하는지는 신경망 학습에 많은 영향을 끼친다. 그 이유는 각 neuron의 weight를 기반으로 error를 결정하기 때문이고, 정확한 모델을 얻으려면 작은 error를 필요로 하기 때문이다. 따라서 성능이 높은 신경망 모델을 만들기 위해서는 상황에 맞는 적절한 가중치 초기화(Weight initialization) 방법을 사용해야한다.
Zero initialization
Zero initialization은 모든 가중치를 0으로 설정하는 방법이다. 하지만 가중치 값이 모두 같다면 Backpropagation(역전파)를 통해서 가중치를 갱신하더라도 모두 같은 값으로 변하게된다.
결과적으로 층마다 한 개의 노드만을 배치하는 것과 같게되고 이는 여러 개의 노드로 신경망을 구성하는 의미가 사라진다는 것을 의미한다. 따라서 초깃값은 무작위로 설정해야 한다.
Random Initialization
가중치에 다른 값을 부여하기 위해서 가장 쉽게 생각해 볼 수 있는 방법은 확률분포를 사용하는 것이다. 정규분포를 이루는 값을 각 가중치에 배정하여 모두 다르게 설정할 수 있다. 표준편차를 다르게 설정하면서 정규분포로 가중치를 초기화한 신경망의 활성화 함수 출력 값을 시각화해보면 다음과 같다. (신경망은 100개의 노드를 5-layer로 구성하였다.)
아래 그래프는 표준편차가 1인 케이스이다. (활성화 함수로는 sigmoid 함수를 사용하였다.)
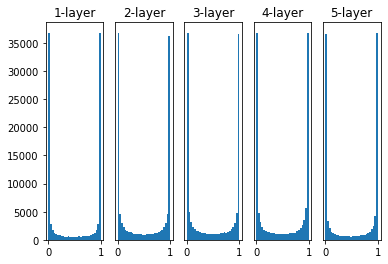
그림으로 보면 활성화 함수로부터 0과 1에 가까운 값만 출력되는 것을 볼 수 있다. 활성화 값이 0과 1에 가까울 때 sigmoid 함수의 미분값은 거의 0에 가깝다. 이렇게 되면 학습이 일어나지 않는 Gradient vanishing 현상이 발생하게 된다.
그렇다면 이렇게 값이 양 극단으로 치우치지 않도록 표준편차를 줄여보았다. 아래는 표준편차를 0.01 인 정규분포로 가중치를 초기화한 뒤에 활성화 함수의 출력값을 시각화한 것이다.
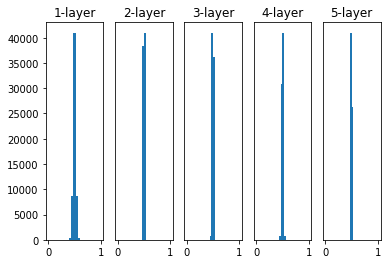
하고자 했던 대로 기울기 소실 효과는 발생하지 않았지만 대부분의 출력값이 0.5 주변에 위치하고 있다는 것을 알 수 있다. Zero initialization에서도 말했던 것처럼 모든 layer의 활성화 함수의 출력값(갱신된 weight)이 비슷하면 layer를 여러 개로 구성하는 의미가 사라지게 된다.
Xavier Initialization
Xavier initialization는 위에서 발생했던 문제를 해결하기 위해 고안된 초기화 방법이다. Xavier initialization에서는 고정된 표준편차를 사용하지 않고 이전 은닉층의 노드 수에 맞추어 변화시킨다. 이전 은닉층의 노드의 개수가 n 개이고 현재 은닉층의 노드가 m 개일 때, 2n+m√ 을 표준편차로 하는 정규분포로 가중치를 초기화한다.
이전과 동일한 신경망에 가중치를 사비에르 초깃값으로 초기화한 뒤 활성화 값 그래프를 시각화 해보면 다음과 같다.
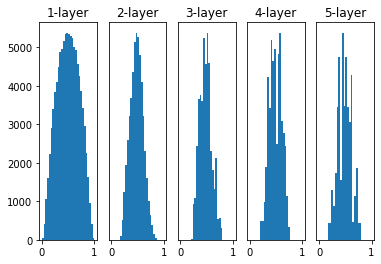
활성값이 이전 두 방법보다 훨씬 더 고르게 퍼져있음을 볼 수 있다. 층마다 노드 개수를 다르게 설정하더라도 이에 맞게 가중치가 초기화되기 때문에 고정된 표준편차를 사용하는 것보다 훨씬 더 Robust하다.
tensorflow와 pytorch에서는 각각 아래와 같이 Xavier initialization를 적용할 수 있다.
# TensorFlow
tf.keras.initializers.GlorotNormal()
# PyTorch
torch.nn.init.xavier_normal_()He Initialization
He Initialization은 ReLU함수를 활성화 함수로 사용할 때 추천되는 초기화 방법이다. He 초기화는 2/√n 를 표준편차로 하는 정규분포로 wegith를 초기화한다.
아래는 활성화 함수가 ReLU 함수인 5층 신경망에서 사비에르 초기화를 적용했을 때 활성값이 어떻게 변하는 지를 나타낸 그래프이다.
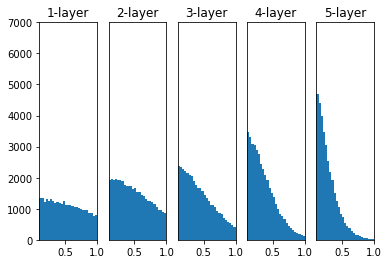
첫 번째 층에서는 활성화 값이 골고루 분포되어 있지만 층이 깊어질수록 분포가 치우치는 것을 볼 수 있다. 만약 층이 더 깊어진다면 거의 모든 값이 0에 가까워지면서 기울기 소실이 발생하게 된다.
아래는 He Initialization를 사용했을 때의 활성값 변화를 나타낸 그래프이다.
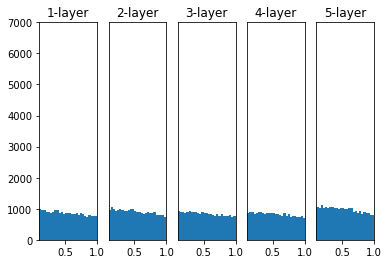
층이 깊어지더라도 모든 활성값이 고른 분포를 보이는 것을 알 수 있다.
텐서플로우와 파이토치에서는 각각 아래와 같이 He 초기화를 적용할 수 있다.
# TensorFlow
tf.keras.initializers.HeNormal()
# PyTorch
torch.nn.init.kaiming_normal_()지금까지 살펴본 것처럼 사용하는 활성화 함수에 따라 적절한 초기화 방법이 달라질 수 있다. 일반적으로 활성화 함수가 sigmoid 함수일 때는 Xavier initialization를, ReLU류의 함수일 때는 He Initialization를 사용한다.
