
Training set의 목적
Training set은 모델을 학습하는데 사용된다.
Training set으로 모델을 만든 뒤 동일한 데이터로 성능을 평가해보기도 하지만, 이는 cheating이 되기 때문에 유효한 평가는 아니다. 마치 모의고사와 동일한 수능 문제지를 만들어 대입 점수를 매기는 것과 같다.
Training set은 Test set이 아닌 나머지 데이터 set을 의미하기도 하며, Training set 내에서 또 다시 쪼갠 Validation set이 아닌 나머지 데이터 set을 의미하기도 한다. 문맥상 Test set과 구분하기 위해 사용되는지, Validation과 구분하기 위해 사용되는지를 확인해야 한다.
Validation set의 목적
Validation set은 training set으로 만들어진 모델의 성능을 측정하기 위해 사용된다. 일반적으로 어떤 모델이 가장 데이터에 적합한지 찾아내기 위해서 다양한 파라미터와 모델을 사용해보게 되며, 그 중 validation set으로 가장 성능이 좋았던 모델을 선택한다.
Test set의 목적
Test set은 validation set으로 사용할 모델이 결정 된 후, 마지막으로 딱 한번 해당 모델의 예상되는 성능을 측정하기 위해 사용된다. 이미 validation set은 여러 모델에 반복적으로 사용되었고 그중 운 좋게 성능이 보다 더 뛰어난 것으로 측정되어 모델이 선택되었을 가능성이 있다. 때문에 이러한 오차를 줄이기 위해 한 번도 사용해본 적 없는 test set을 사용하여 최종 모델의 성능을 측정하게 된다.
Validation set과 Test set의 차이
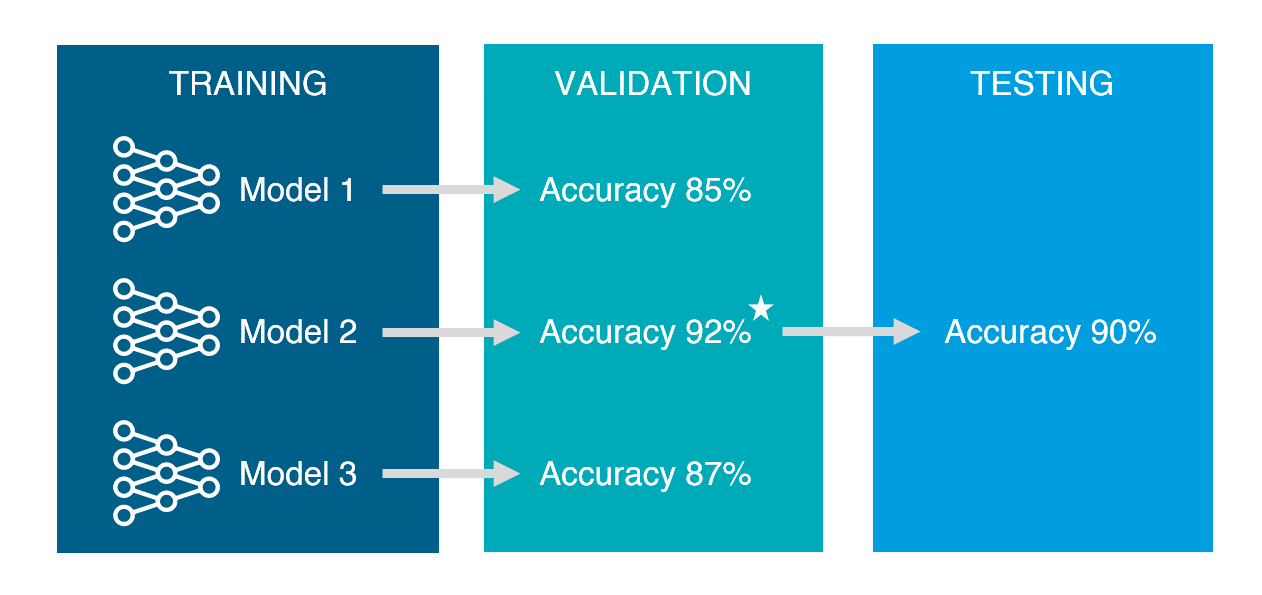
Validation set은 여러 모델들 각각에 적용되어 성능을 측정하며, 최종 모델을 선정하기 위해 사용된다. 반면 test set은 최종 모델에 대해 단 한번 성능을 측정하며, 앞으로 기대되는 성능을 예측하기 위해 사용된다.
Training set, Validation set, Test set 비율
정해진 룰은 없지만 데이터를 충분히 크게 모을 수 있는 다음과 같은 비율을 일반적으로 사용한다.
Training set : Validation set : Test sets = 60 : 20 : 20
실제 모델의 사용
Training set으로 모델들을 만든 뒤, validation set으로 최종 모델을 선택하게 된다. 최종 모델의 예상되는 성능을 보기 위해 test set을 사용하여 마지막으로 성능을 평가한다. 그 뒤 실제 사용하기 전에는 쪼개서 사용하였던 training set, validation set, test set 을 모두 합쳐 다시 모델을 training 하여 최종 모델을 만든다. 기존 training set만을 사용하였던 모델의 파라미터와 구조는 그대로 사용하지만, 전체 데이터를 사용하여 다시 학습시킴으로써 모델이 조금 더 튜닝되도록 만든다.
혹은 data modeling을 진행하는 동안 새로운 데이터를 계속 축적하는 방법도 있다. 최종 모델이 결정 되었을 때 새로 축적된 data를 test data로 사용하여 성능평가를 할 수도 있다.
Training sets, Validation sets, Test sets split
MNIST 숫자 필기체 데이터에 대해 SVM(Support Vector Machine) 모델에서 SVM의 파라미터 중 하나인 gamma값을 바꿔 가며 어떤 gamma값을 가진 모델이 가장 성능이 좋은지 평가해본다.
import matplotlib.pyplot as plt
from pandas import DataFrame
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split
# 8x8 Images of digits
digits = datasets.load_digits()
images_and_labels = list(zip(digits.images, digits.target))
# Plot sample images
_, axes = plt.subplots(1, 4)
for ax, (image, label) in zip(axes[:], images_and_labels[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Training: %i' % label)
print('---------Sample---------')
plt.show()
# flattened to (samples, feature) matrix:
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# Split data into train, valid and test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.2, random_state=1)
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=1)
gmm_list = [0.1, 0.01, 0.001]
score_list = []
# Validation
for gmm in gmm_list:
# Support vector classifier
classifier = svm.SVC(gamma=gmm)
classifier.fit(X_train, y_train)
# Score with validation set
predicted = classifier.predict(X_val)
score = metrics.accuracy_score(predicted, y_val)
score_list.append(score)
result = list(map(list, zip(gmm_list, score_list)))
result_df = DataFrame(result,columns=['gamma', 'score'])
print('-------Validation-------')
print(result_df)
print('')
print('----------Test----------')
# Test
best_gmm = result_df.iloc[result_df['score'].argmax()]['gamma']
classifier = svm.SVC(gamma=best_gmm)
classifier.fit(X_train, y_train)
predicted = classifier.predict(X_test)
test_score = metrics.accuracy_score(predicted, y_test)
print('Test Score :', test_score)
