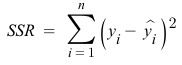머신러닝의 목적은 데이터의 알려진 속성들을 학습하여 예측 모델을 만드는데 있다. 이때 찾아 낼 수 있는 가장 직관적이고 간단한 모델은 선(line)이다.
선형회귀란 데이터를 가장 잘 대변하는 최적의 선을 찾는 과정이다.
이러한 선은 주어져 있지 않은 점의 함수값을 보간하여 예측하는데 도움을 주며, 또한 기존 데이터의 범위를 넘어서는 값을 예측하기 위해 사용된다.
아래 그래프에서 검정색 점은 데이터이다. 이 데이터를 가장 잘 표현하는 선이 파란색 직선이며 이는 형태로 나타난다.
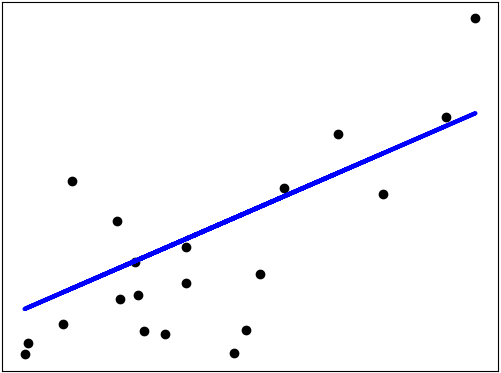
선형회귀 직선은 와 의 관계를 요약해서 설명해준다고 볼 수 있다.
이 때 를 독립 변수라고 하며, 에 의해 영향을 받는 값인 를 종속 변수라고 한다.
- 독립 변수는 Predictor, Explanatory, Feature 등으로 불린다.
- 종속 변수는 Response, Label, Target 등으로 불린다.
선형 회귀는 한개 이상의 독립 변수 와 의 관계를 모델링 하는데, 만약 독립 변수 가 하나라면 simple linear regression 2개 이상이면 multiple linear regression이라고 한다.
- 단순 선형 회귀 분석 :
- 다중 선형 회귀 분석 :
Python code
from sklearn.linear_model import LinearRegression
## 예측모델 인스턴스 생성
model = LinearRegression()
# 특성과 타겟값을 feature,target에 넣고 데이터 생성
X_train = df[feature]
y_train = df[target]
## 모델 학습(fit)
model.fit(X_train, y_train)
## 새로운 데이터를 통한 예측
X_test = [[4000]]
y_pred = model.predict(X_test)
# 계수(coefficient)
model.coef_
>>> array([[107.13035897]])
# 절편(intercept)
model.intercept_
>>> array([18569.02585649])모델 성능 평가지표
1. MSE(평균제곱오차)
오차(error)를 제곱한 값의 평균이다. 오차란 알고리즘이 예측한 값과 실제 정답과의 차이를 의미한다. 즉, 알고리즘이 정답을 잘 맞출수록 MSE 값은 작기때문에 MSE 값은 작을수록 알고리즘의 성능이 좋다고 볼 수 있다.
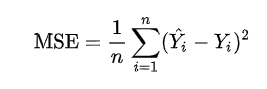
- yi: i번째 학습 데이터의 정답
- yi~: i번째 학습 데이터로 예측한 값
2. MAE(평균절대오차)
모델의 예측값과 실제값의 차이의 절대값을 모두 더한 개념이다.
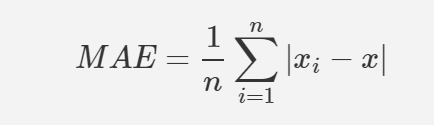
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
y_train = train[target]
y_test = test[target]
# 기준모델을 평균으로
predict = y_train.mean()
# 기준모델로 훈련 에러(MAE)계산
# 기준모델과 y_train의 MAE평가지표를 활용하여 오차 계산하기
y_pred = [predict] * len(y_train)
mae = mean_absolute_error(y_train, y_pred)3. R-squared
R-squared는 현재 사용하고 있는 x변수가 y변수의 분산을 얼마나 줄였는지에 대한 척도이다.
단순히 y평균값 모델(기준모델)을 사용했을때 대비 우리가 가진 x변수를 사용함으로서 얻는 성능 향상의 정도이다.
즉, R-squared 값이 1에 가까우면 데이터를 잘 설명하는 모델이고 0에 가까울수록 설명을 못하는 모델이라고 생각할 수 있다.
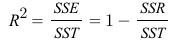
-
SST (Total Sum of Squares): 총제곱합
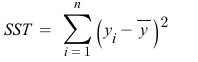
-
SSE (Explained Sum of Squares): 회귀제곱합
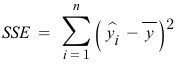
-
SSR (Residual Sum of Squares): 잔차제곱합