머신러닝이란 컴퓨터가 데이터로부터 학습할 수 있도록 하는 방법을 말한다.
명시적으로 컴퓨터를 프로그래밍하는 대신, 컴퓨터가 데이터로 학습하고 경험을 통해 개선하도록 훈련하는 데 중점을 둔다.
머신러닝에서 알고리즘은 대규모 데이터 세트에서 패턴과 상관관계를 찾고 분석을 토대로 최적의 의사결정과 예측을 수행하도록 훈련된다.

Traditional programming vs Machine Learning
traditional programming
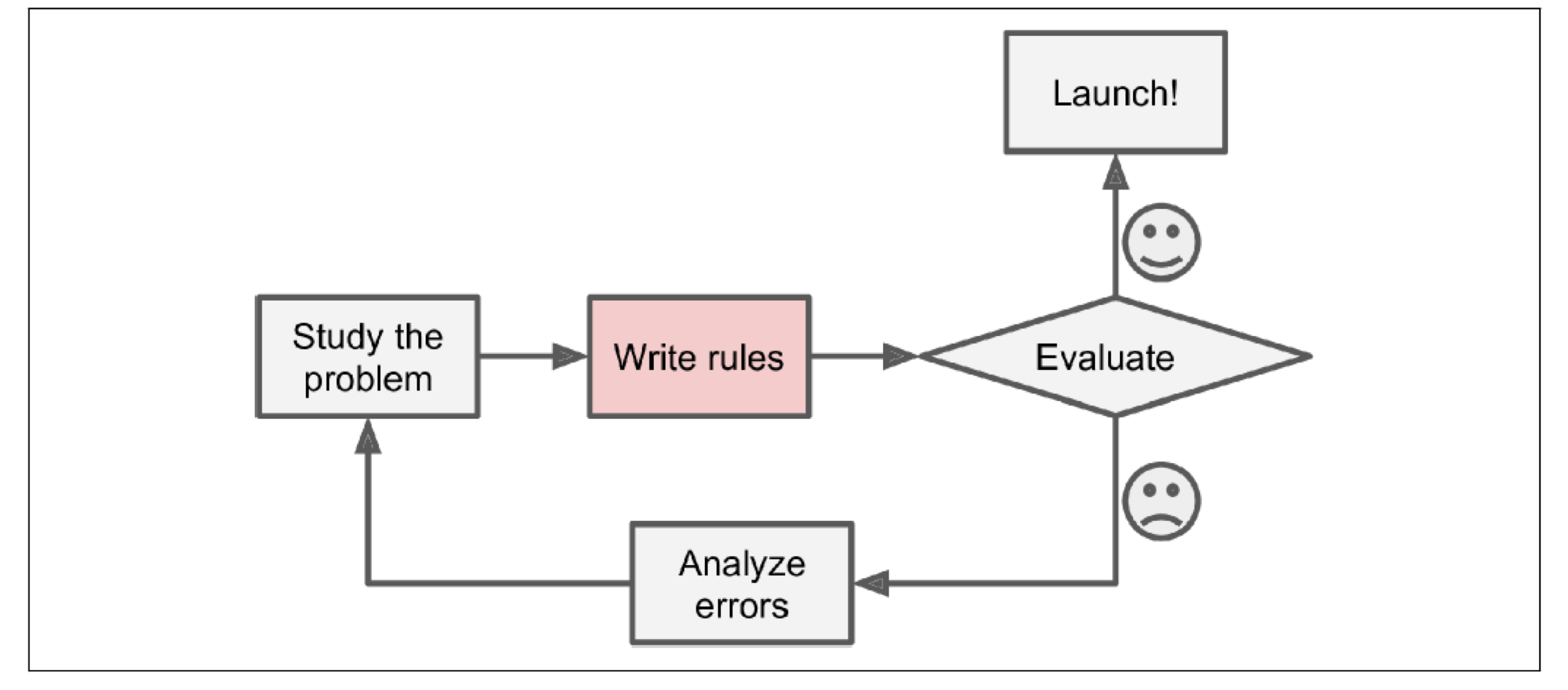
모든 경우에 대한 알고리즘을 작성한다.
-> 문제가 복잡해지면 유지보수 및 관리가 어려워지고 코드를 작성하기에 어렵다.
Machine Learning
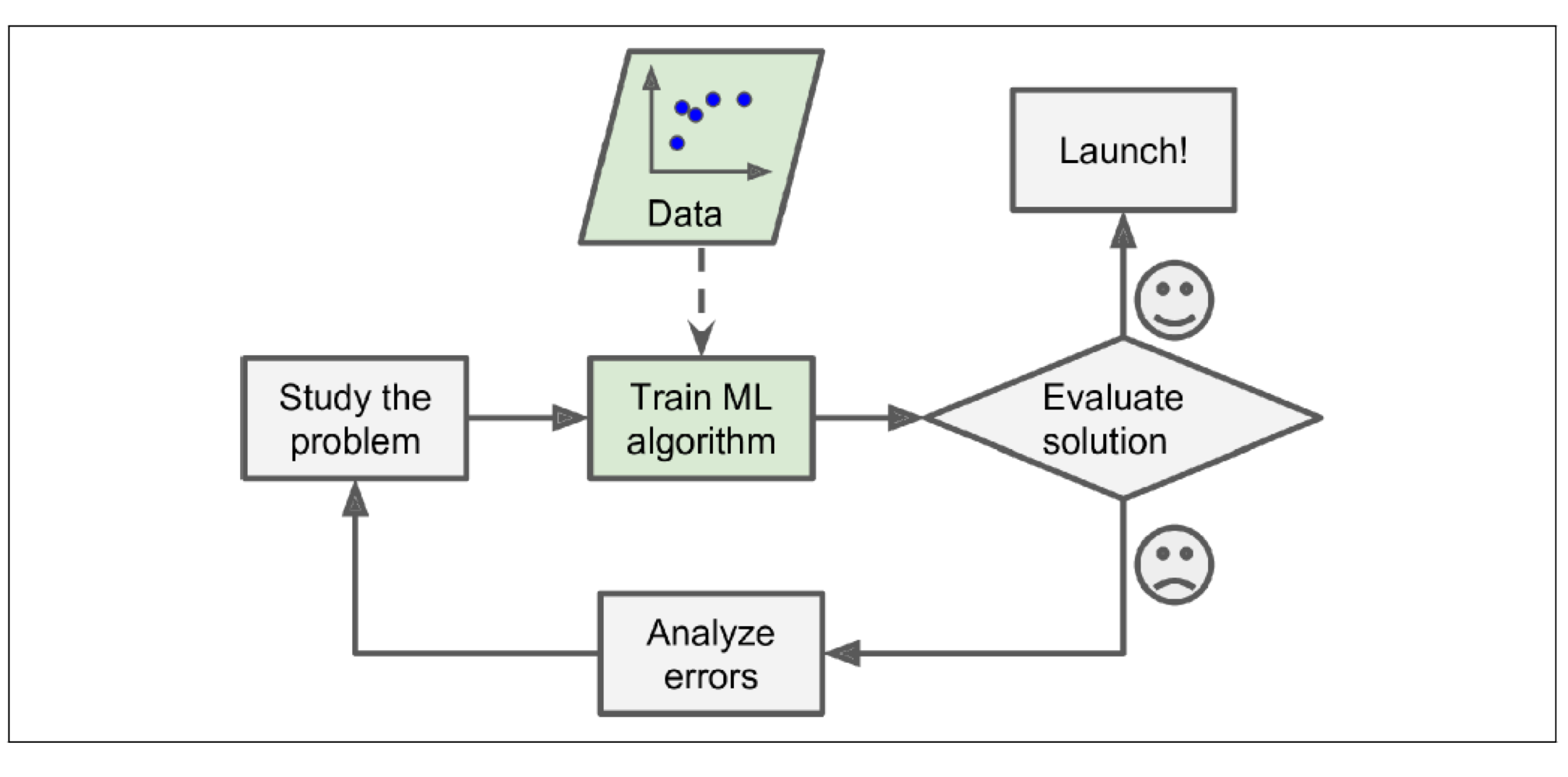
regular mail와 spam mail에 대한 데이터 비교를 통해 컴퓨터가 spam mail 패턴을 스스로 찾는다.
-> 유지보수 및 관리가 쉽고 정확도가 더 높다.
Supervised Learning vs Unsupervised Learning
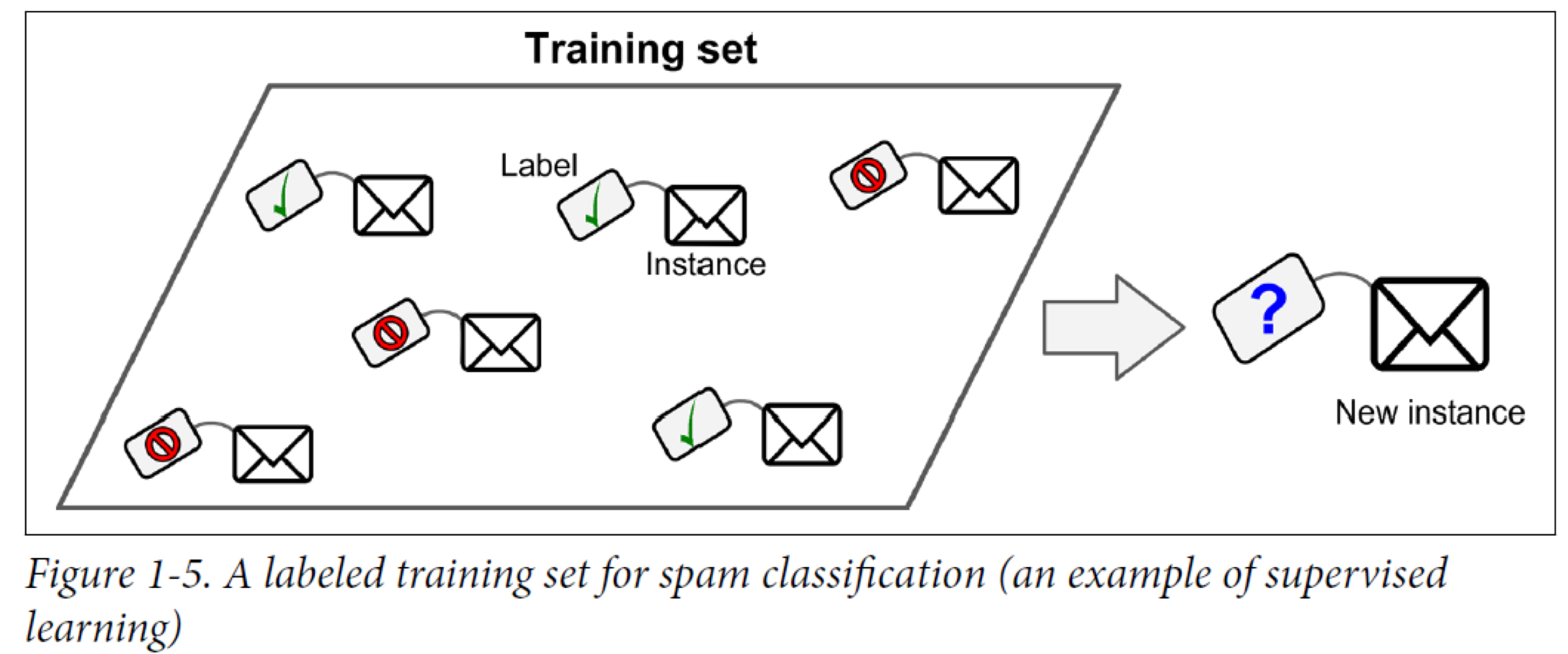
Supervised Learning (지도학습)
지도 학습은 정답(lable)이 있는 데이터를 활용해 데이터를 학습시키는 것이다.
입력 값(X data)이 주어지면 입력값에 대한 Label(Y data)를 주어 학습시키며 대표적으로 classification, regression이 있다.
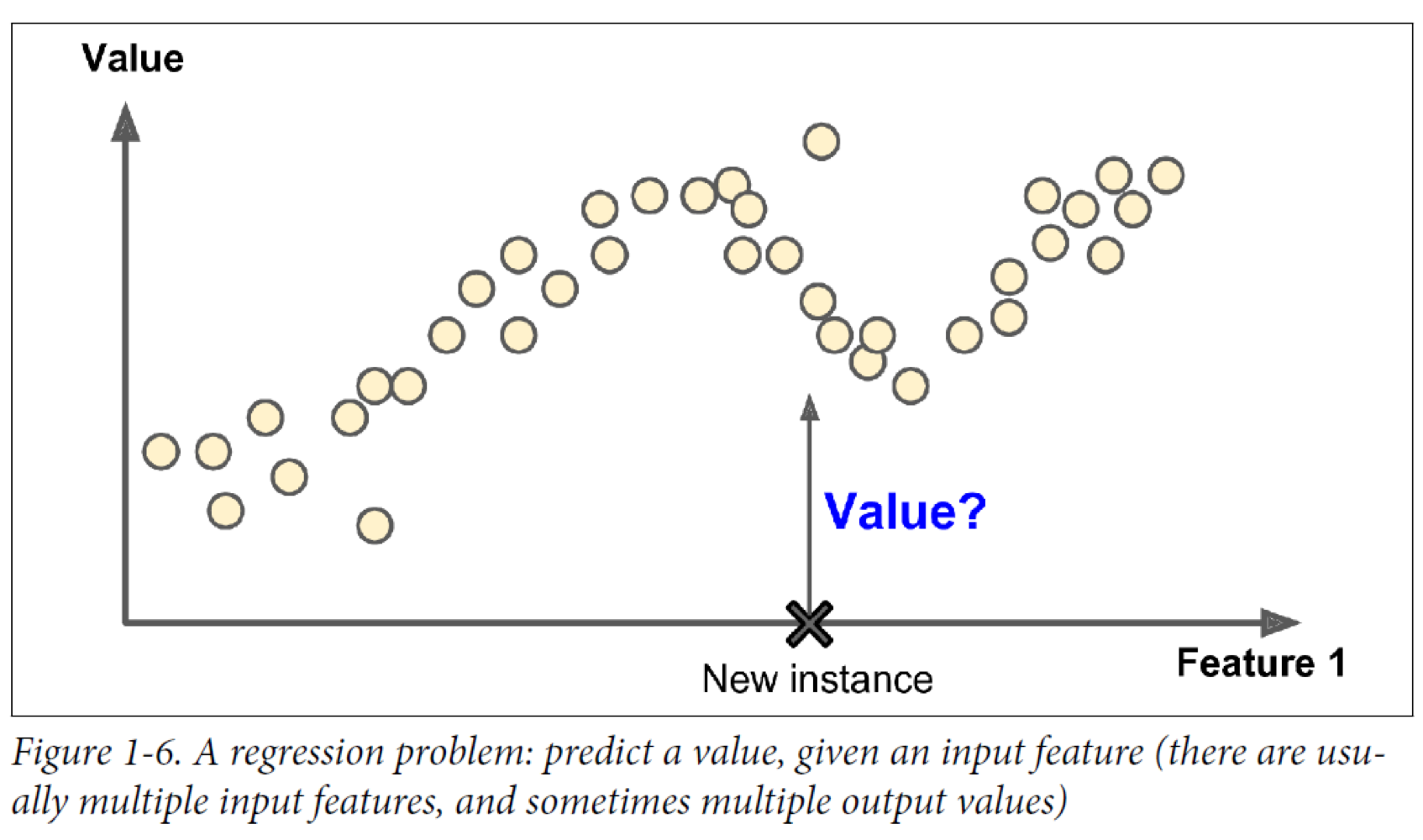
대표적인 supervised learning 알고리즘
- KNN
- Linear Regression
- Logistic Regression
- SVM
- Decision Tree, Random Forest
- Neural networks
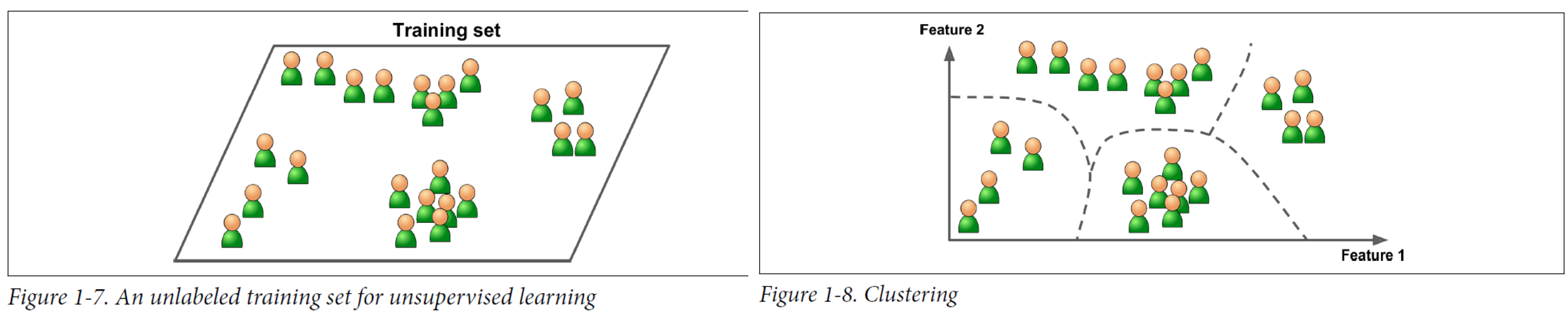
Unsupervised Learning (비지도학습)
정답 라벨이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과를 예측하는 방법
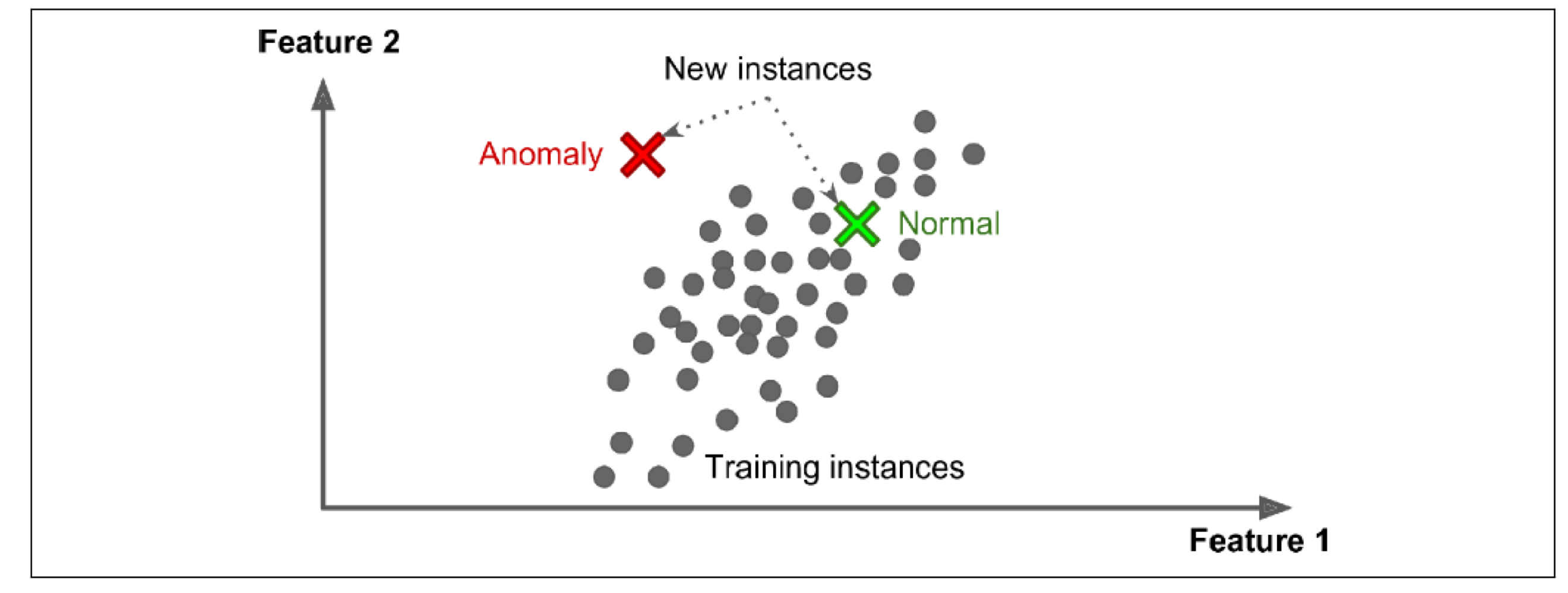
anomaly detection
association rule
큰 data set에서 feature들 사이의 relationship을 찾아내는 방법
ex) 슈퍼마켓에서 바베큐 소스와 감자칩을 같이 산 사람들은 스테이크도 같이 사는 경향이 있다.
대표적인 unsupervised learning 알고리즘
- Clustering
- Anomaly detection
- demensionality reduction
- Association rule learning
Semisupervised Learning (반지도학습)
labeled data와 unlabeled data가 섞여있는 data set을 학습시킬 때 사용하는 방법

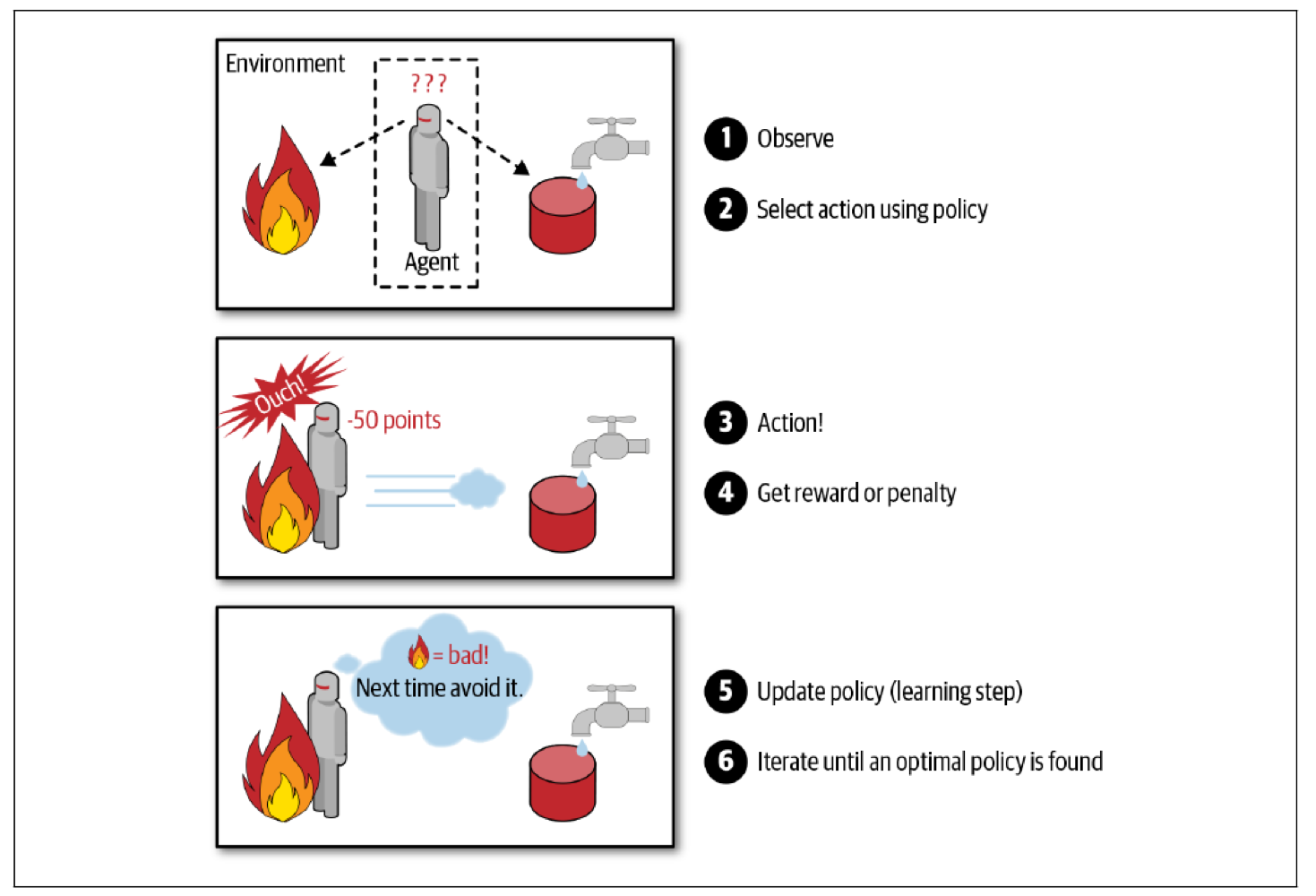
Reinforcement Learning (강화학습)
지도학습, 비지도학습, 반지도학습과는 완전히 다른 별개의 학습 방법으로 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것이다.
행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지는데, 이러한 보상을 최대화 하는 방향으로 학습이 진행된다
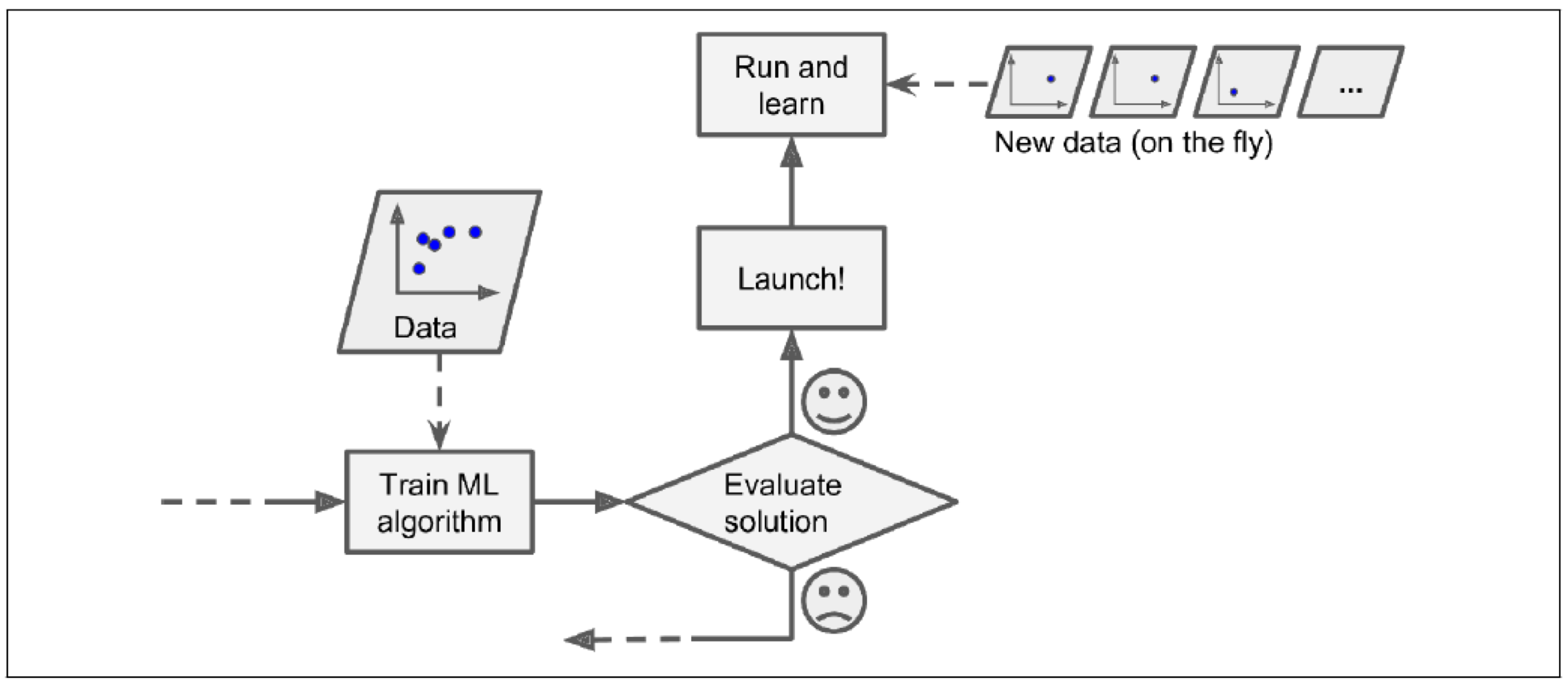
Batch Learning vs Online Learning
Batch Learning
offline learning이라고도 불리는 Batch Learning 시스템에서는 incrementally하게 학습을 할 수 없고, 모든 데이터들을 이용해서 학습을 한다. 이러한 시스템에서 새로운 데이터가 추가되었을때에는 전체 데이터셋을 다시 학습해야 한다.
이 방법은 매우 느리고 많은 컴퓨터 자원을 필요로 한다.
Online Learning
Online Learning 시스템에서는 incremantal한 학습이 가능하다. 데이터를 순차적으로, 개별적으로 혹은 mini-batch라고 불리는 작은 그룹으로 학습 시키는 것이 가능하다.
만약 Online Learning 시스템에서 새로운 data가 추가된다면 새롭게 추가된 data에 대해서만 학습을 시켜주면 된다.
이러한 방법은 전체 data set을 모두 학습하는 batch learning system과는 반대로 빠르고 적은 컴퓨터 자원을 필요로 한다.
최근에는 data set의 크기가 큰 경우가 많아 컴퓨터의 memory가 감당할 수 없는 경우가 많기 때문에 데이터를 쪼개서 학습시킬 수 있는 online learning 방식이 많이 이용된다.
online learning 방식의 단점은 data set에 outlier나 bad data가 포함되어 있으면 성능에 큰 영향을 받는다.
-> 학습이 진행되는 상황을 monitoring하거나 anomaly detection algorithm을 사용해 해결 가능하다.
Instance-Based Learning vs Model-Based Learning
머신러닝의 목적은 새로운 data에 대한 예측을 잘 하는 것이기 때문에 training data로 부터 규칙을 잘 찾는것이 중요하다.
-> generalization이 잘 되어 있을수록 머신러닝 모델의 성능이 더 향상된다.
Instance-Based Learning
새로운 인스턴스를 예측할때 training data의 인스턴스들과 비교해서 판단하는 방법
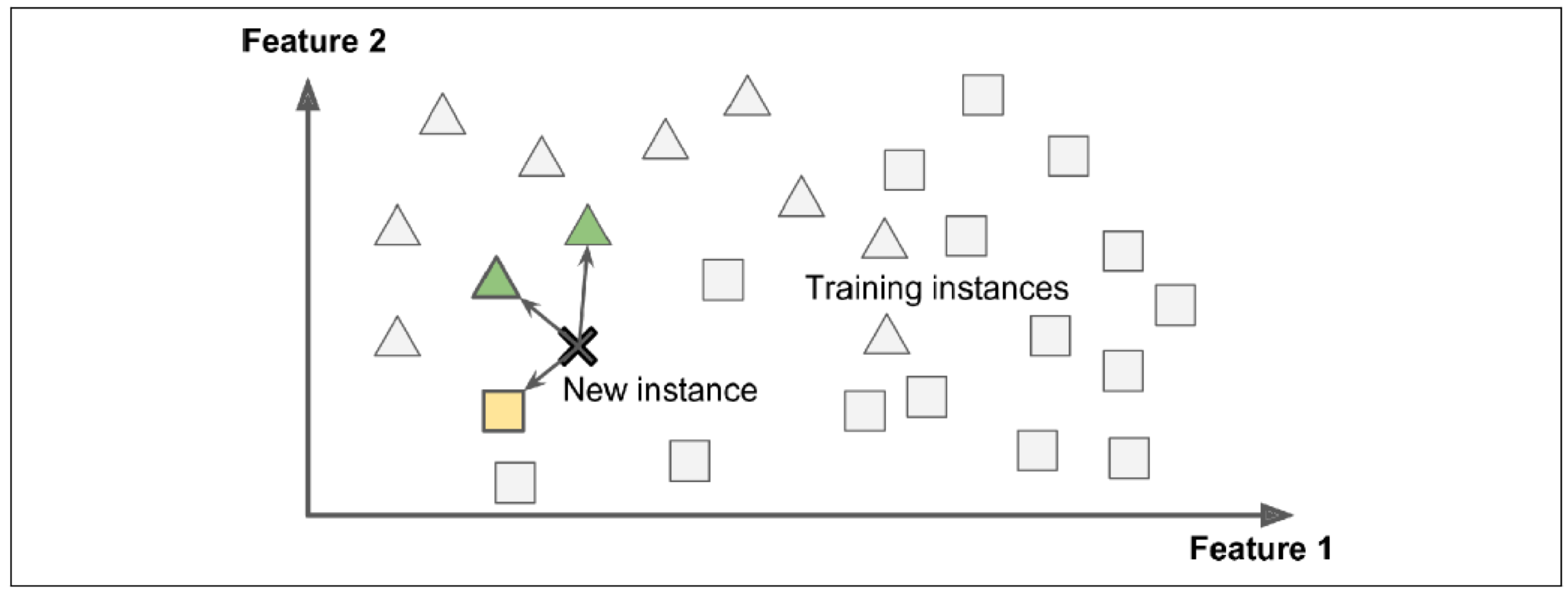
Model-Based Learning
training data로부터 일종의 가설과 같은 모델을 만들어 판단하는 방법
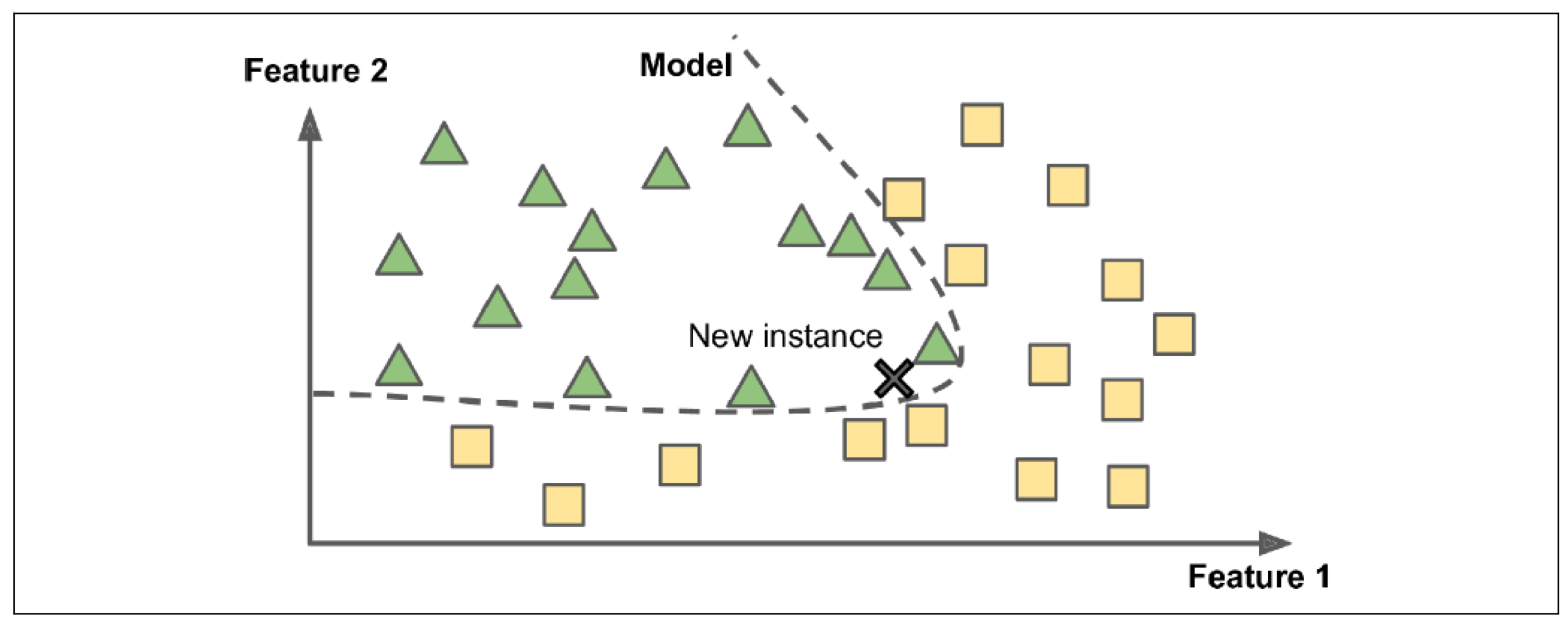 새로운 인스턴스가 만들어낸 모델의 그 범위(desicion boundary) 안에 있는지, 없는지에 따라 결과값이 정해진다.
새로운 인스턴스가 만들어낸 모델의 그 범위(desicion boundary) 안에 있는지, 없는지에 따라 결과값이 정해진다.
