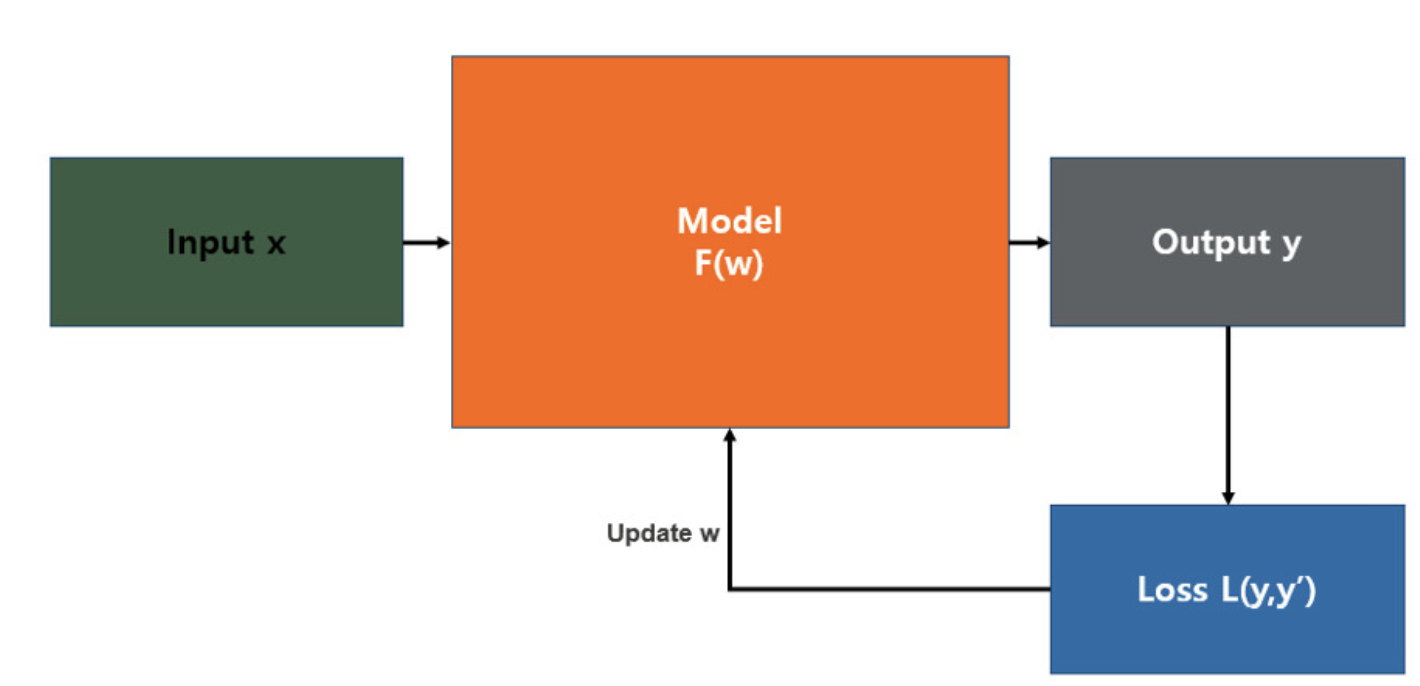
손실 함수(Loss Function)는 지도학습(Supervised Learning) 시 알고리즘이 예측한 값과 실제 정답의 차이를 비교하기 위한 함수이다.
즉, 학습 중에 알고리즘이 얼마나 잘못 예측하는 정도를 확인하기 위한 함수로써 최적화(Optimization)를 위해 최소화하는 것이 목적인 함수이다. 손실 함수는 분야에 따라 목적 함수(Objective Function), 비용 함수(Cost Function), 에너지 함수(Energy Function) 등으로 다양하게 부르기도 한다.
손실 함수를 통해 모델 학습 중에 손실(loss)이 커질수록 학습이 잘 안 되고 있다고 해석할 수 있고, 반대로 손실이 작아질수록 학습이 잘 이루어지고 있다고 해석할 수 있다.
손실 함수는 성능 척도(Performance Measure)와는 다른 개념이다. 성능 척도는 학습된 알고리즘의 성능을 정량적으로 평가하기 위한 지표로써 accuracy, F1 score, percision 등이 있다.
즉, 성능 지표는 알고리즘의 학습이 끝났을 때 모델의 성능을 평가하기 위한 지표이기 때문에 알고리즘 학습 중에는 전혀 사용되지 않는다. 반면, 손실 함수는 알고리즘 학습 중에 학습이 얼마나 잘 되고 있는지 평가하기 위한 지표이다.
손실함수 선택 시 고려해야할 사항
-
문제 유형 : 해결하려는 문제의 종류에 따라 적합한 손실 함수를 선택해야한다. Regression문제에서는 MSE를, Classification 문제에서는 주로 Cross-Entropy를 사용한다.
-
데이터의 특성 : 데이터의 분포와 속성에 따라 적합한 손실 함수가 다를 수 있다. 예를 들어 이진 분류 문제에서 클래스의 불균형이 크다면 가중치를 고려한 Cross-Entropy를 사용하는 것이 좋다.
-
모델의 목표 : 모델의 학습 목표에 맞는 손실 함수를 선택해야 한다. 모델이 예측해야 할 값의 특성에 따라 적합한 손실 함수를 선택해야한다.
손실함수의 종류
MSE
예측한 값과 실제 값 사이의 평균 제곱 오차를 정의한다. 공식이 매우 간단하며 차가 커질수록 제곱 연산으로 인해 값이 더욱 뚜렷해진다는 특징있다. 또한 제곱으로 인해 오차가 양수이든 음수이든 누적 값을 증가시킨다.
그렇기 때문에 데이터 셋에 이상치가 많이 존재한다면 MSE의 값도 그만큼 커진다는 단점이 있다.
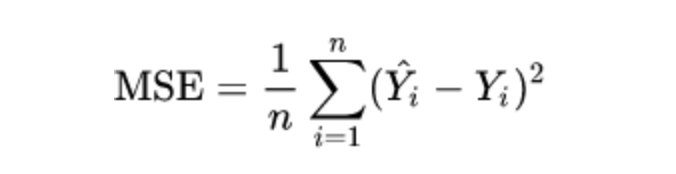
RMSE
MSE에 루트를 씌운 값으로 MSE와 기본적으로 동일하다. RMSE를 사용하는 이유는 MSE값은 오류의 제곱을 구하기 때문에 실제 오류 평균보다 커지는 특성이 있어 MSE에 루트를 씌워 값의 왜곡을 줄여준다.
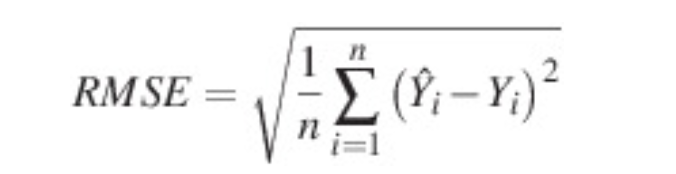
MAE
MAE도 RMSE와 거의 유사한 개념으로 데이터셋에 이상치가 많아 MSE로 평가하기에 문제가 있을때, 사용하는 손실 함수이다. MAE는 평균절대오차로, 실제값과 예측값의 차이를 평균하는 방식으로 에러를 제곱시키지 않기 때문에 MSE에 비해서 이상치에 비교적 영향을 덜 받는다는 장점이 있다.
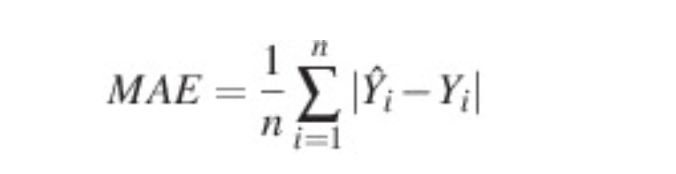
Entropy
지금까지 살펴본 손실함수들은 Regression에서 사용하는 지표들이다. Classification 문제에서도 평가지표로 손실 함수가 쓰인다. 그러나 Classification 문제에서는 예측값과 실제값의 차이를 수치로 나타낼 수 없기 때문에 Entropy를 대신 사용한다.
Entropy는 원래 물리학에서 분자의 무질서함을 측정하는 열역학 개념이지만, 이 개념에 착안해서 정보학에서 엔트로피는 정보의 양으로써 신호를 인식하는 데에 쓰인다. 정보 이론에서 사건 발생 확률이 낮다는 것은 곧 많은 정보를 가지고 있다는 뜻이고, Entropy가 높아진다는 이야기이다. Entropy 식은 아래와 같다.
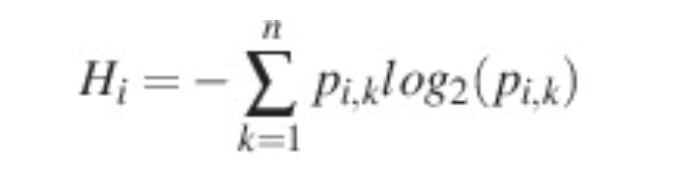
엔트로피는 확률 * log(확률)의 합이다. 예를 들어 이진 분류 문제에서 네 개의 데이터에 대해 레이블이 1일 확률이 [0.4, 0.9, 0.6, 0.1]이 나오고 실제 레이블이 [0, 1, 1, 0] 이라면 엔트로피는 다음과 같다.
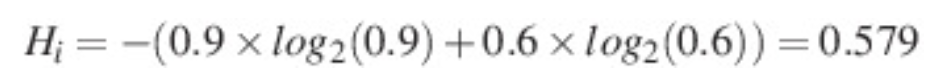
Cross-Entropy
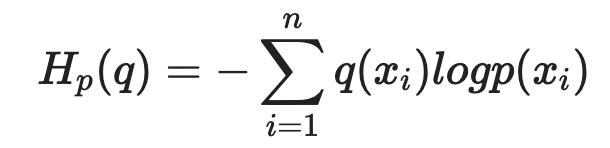
이 때, 이 계산은 이산확률분포를 전제로 한다.
분류 문제에서 Cross-entropy가 사용될 수 있는 이유는 분류기의 결과값이 각 클래스에 속할 확률로써 나타내어질 수 있기 때문이다.
예를 들어 실제 클래스에 대한 분포를 P라고 하고, 예측 클래스에 대한 분포를 Q라고 하자. 그리고 다음과 같이 실제 레이블과 확률이 주어졌다고 가정하자.
p = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
q = [0.8, 0.9, 0.9, 0.6, 0.8, 0.1, 0.4, 0.2, 0.1, 0.3]그러면, Cross-entropy는 다음과 같이 계산된다.
[y=1.0, yhat=0.8] ce: 0.223
[y=1.0, yhat=0.9] ce: 0.105
[y=1.0, yhat=0.9] ce: 0.105
[y=1.0, yhat=0.6] ce: 0.511
[y=1.0, yhat=0.8] ce: 0.223
[y=0.0, yhat=0.1] ce: 0.105
[y=0.0, yhat=0.4] ce: 0.511
[y=0.0, yhat=0.2] ce: 0.223
[y=0.0, yhat=0.1] ce: 0.105
[y=0.0, yhat=0.3] ce: 0.357
Average Cross Entropy: 0.247분류 문제에서는 분류 클래스의 개수에 따라 Cross-entropy를 구하는 방식이 달라지게 된다.
Binary Cross-entropy
Binary cross-entropy는 0과 1의 레이블만 갖는 이진 분류 문제에서 사용된다. 식은 다음과 같다.

Categorical Cross-entropy
Categorical cross-entropy는 MNIST데이터셋과 같은 다중 클래스 분류 문제에서 사용된다. Softmax 함수를 사용하기 때문에 Softmax 손실이라고도 불리고 식은 다음과 같다.
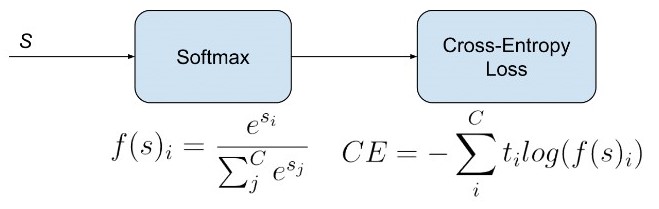
Sparse Categorical Cross-entropy
Sparse categorical cross-entropy는 categorical cross-entropy와 마찬가지로 다중 클래스 분류 문제에서 사용된다. Categorical cross-entropy와 다른 점은 Sparse는 클래스들이 0,1,2 등과 같은 정수일 때 사용한다는 점이다.
