오늘은 데브코스 스터디에서 논문 발표 주제로 정해진 SRGAN 논문을 읽고 리뷰해볼려고 한다. 사실 대학생 시절에도 논문을 잘 읽은기억은 없어서 거의 처음으로 하는 논문리뷰이다..
Abstract
CNN을 사용하면서 super-resolution 기술의 정확도와 속도가 빨라졌지만
이미지의 해상도를 높이는 업스케일링의 과정에서 텍스처의 디테일을 어떻게 복구할 것인가의 문제는 여전히 남아있다.
이 논문의 SRGAN이라는 새로운 모델을 제시하여 이러한 문제점을 해결하고자 한다.
Introduction
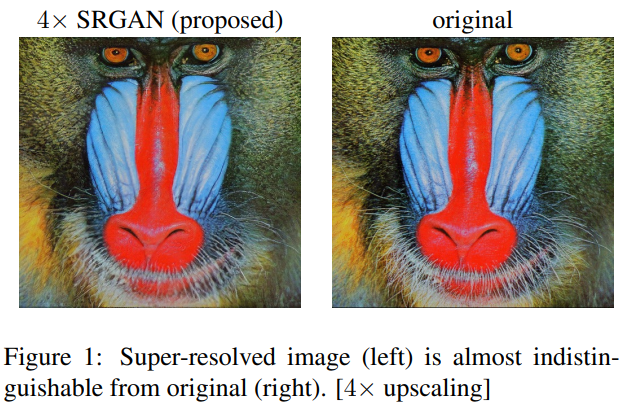
저화질의 이미지를 고화질로 바꾸는 것을 super-resolution(SR)이라고 한다. SR의 문제점은 만들어진 고화질 이미지의 디테일이 부족하다는 점이다.
그 이유로 지도학습 SR 알고리즘들은 목표는 일반적으로 만들어진 고화질 이미지와 실제 이미지 사이의 평균제곱오차(MSE)를 최소화하는 것인데, MSE가 최소화되면서 SR 알고리즘을 평가하고 비교하는 데 사용되는 척도인 피크신호 잡음 비(PSNR)은 최대화된다. 그러나 세부 텍스처 디테일 같이 지각적인 부분과 관련있는 차이에 대해서는 픽셀 단위의 이미지 처리 때문에 매우 제한적이다.

위의 그림에서 처럼 PSNR이 높다고 해서 더 나은 결과를 보장하지는 않는다.
이 논문에서는 MSE 대신 지각적인 유사성에 중점을 둔 loss function을 제시한다.
이는 VGGNet의 high-level feature maps와 지각적으로 구별하기 어려운 솔루션을 장려하는 판별기와 결합하여 loss function을 정의한다.
Contribution
· MSE에 최적화된 16 block depp SRResNet으로 PSNR에 측정된 높은 업스케일링 계수와 구조적 유사성을 가진 이미지 SR에 대한 새로운 최신 기술을 설정함.
· 새로운 지각 손실에 최적화된 GAN 기반 네트워크인 SRGAN을 제안한다. MSE 기반 손실을 VGG 네트워크의 기능 맵에서 계산된 손실로 대체하며, 이는 픽셀 공간의 변화에 더 변하지 않는다.
· 이미지에 대한 광범위한 평균 의견 점수인 MOS 테스트를 통해 SRGAN이 최첨단으로 성능이 좋음을 확인한다.Method
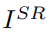
Super resolved image- 추정된 고해상도 이미지(훈련 중에만 사용)
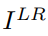
Low resolution image - 저해상도 이미지(입력 이미지)
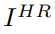
High resolution image - 고해상도 이미지
훈련에서 I(HR)에 가우스 필터를 적용한 다음 다운샘플링 계수 r을 사용한 연산을 통해 I(LR)을 얻는다.
목표는 I(SR)을 추정하는 것이다.
C 컬러를 가진 이미지의 경우, I(LR)은 W x H x C 라면 I(HR)과 I(SR)은 각각 rW x rH x C가 된다. (r은 화질의 배수)
여기서의 궁극적인 목표는 LR 입력으로 HR을 추정하는 생성 함수 G를 훈련하는 것이다.

Generator network
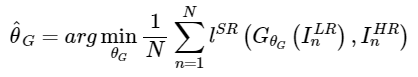
GAN 모델은 보통 위조지폐에 많이 비유되는데 생성자(Generator)가 위조지폐를 생성하고, 판별자(Discriminator)가 위조지폐를 구분하는 과정의 반복을 통해 생성자는 진짜 같은 위조지폐를, 판별자는 위조지폐를 판별하는 능력을 키우는 방향으로 학습을 한다.
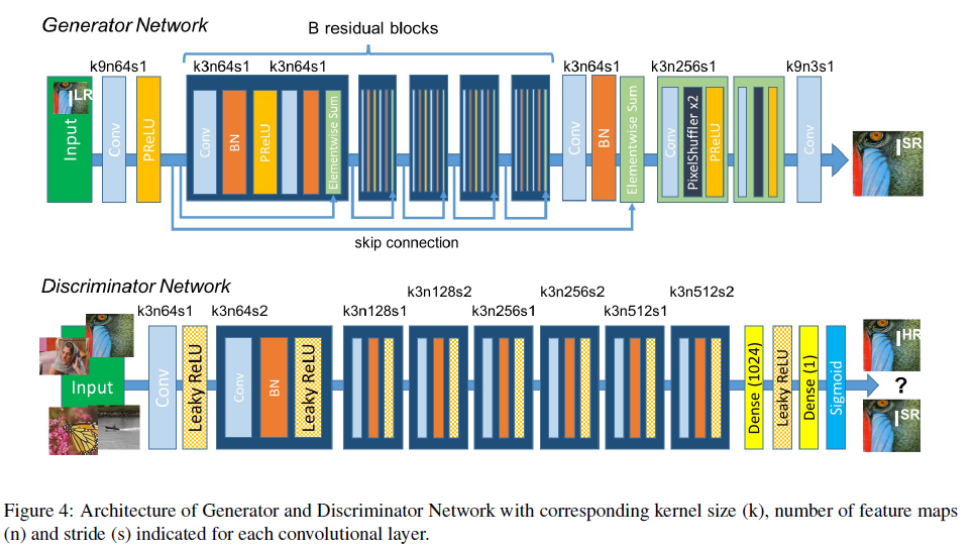
해당 모델에서는 sr된 이미지를 실제 이미지와 구분하기 위해 훈련된 판별자 D를 속이기 위해 생성자 G를 학습한다.
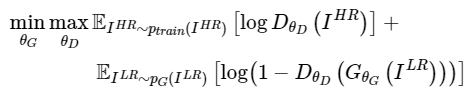
생성자와 판별자의 구조
Perceptual loss function
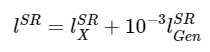
일반적인 SR모델들은 MSE에 기반하여 설계되지만, 그렇게 되면 사람의 눈에는 이상한 경우가 있다. 이 논문에서는 그 문제점을 해결하기 위해 이 loss function을 사용한다. Perceptual loss는 content loss와 adversarial loss의 합으로 정의된다.

Content loss
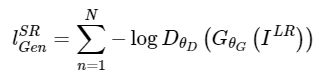
Adversarial loss
Experiments
모든 실험은 저화질 이미지와 고화질 이미지 사이에서 4배의 scale factor로 진행된다. (pixel 크기 16배 감소)
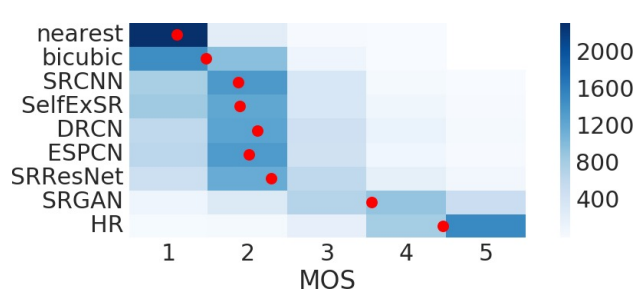
지각적으로 설득력을 정량화 하기 위해 MOS TEST를 진행
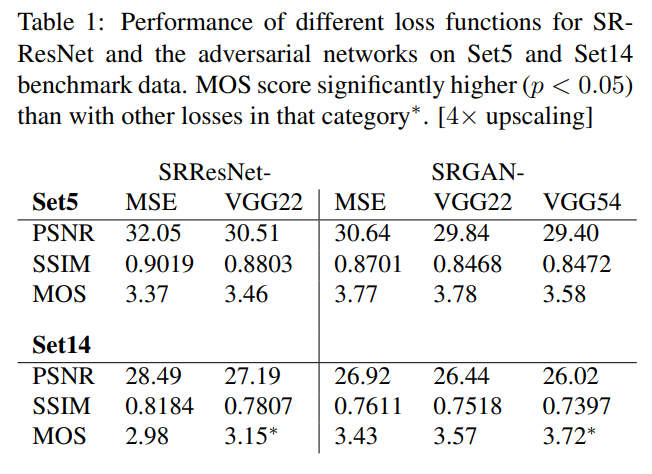
SRGAN-MSE: 표준 MSE를 손실로 사용
SRGAN-VGG22: 하위 레벨의 특징을 나타내는 피쳐 맵에 정의된 손실
SRGAN-VGG54: 이미지 컨텐츠에 더 집중하도록 네트워크의 깊은 계층에서 더 높은 수준의 피쳐 맵에 정의된 손실(SRGAN)
MSE를 이용한 모델들이 좋은 PSNR값을 얻는 경향을 보인다.
SET 14에서 SRGAN-VGG54는 MOS측면에서 다른 모델들을 크게 능가했다.

결과를 시각적으로 비교해봤을때 SRGAN-VGG54가 디테일한 부분을 더 잘 표현한 것을 확인할 수 있다.
Discussion and future work
SRGAN이 지각적인 지표인 MOS Testing에서 우수한 성능을 보임을 확인할 수 있다.
네트워크 구조가 깊을 수록 더 좋은 성능을 보이지만, high-frequency artifact 문제로 학습하기가 힘들다.
느낀점
기존의 SRCNN과 비교하였을 때 SRGAN은 SR분야에서 획기적이다 할 수 있을정도로 높은 성능 향상을 보인다.
GAN을 처음 접했을 때 부터 신기하고 흥미롭다는 생각은 가지고 있었지만, 이렇게 까지 성능이 좋을지는 몰랐다.
깊게 연구해볼 가치가 있는 모델이라고 생각된다.
