Abstract
- 기존 transformer는 sequence 길이의 제곱 비례해서 계산, 긴 문장 불가능
- 우리는 이를 해결하기 위해, attention 작업을 sequence 길이에 선형 비례하는 Longformer 소개
- Longformer의 attention 원리는 기존 self-attention에 drop-in replacement
- local windowed attention + task motivated global attention
- Longformer는 text8과 enwik8에서 SOTA 달성
- pre-trained Longformer는 긴 문서 task에서 RoBERTa의 성능을 능가 (Wiki-Hop, TriviaQA에서 SOTA)
- 마지막으로, 긴 문서를 생성하는 Longformer Encoder Decoder(LED)를 소개
1. Introduction
-
기존 Transformer는 다양한 NLP Task에서 SOTA를 기록 (generative language modeling 포함)
-
성능의 핵심인 self-attention이 긴 문장을 작업할 때 너무 expensive하다!
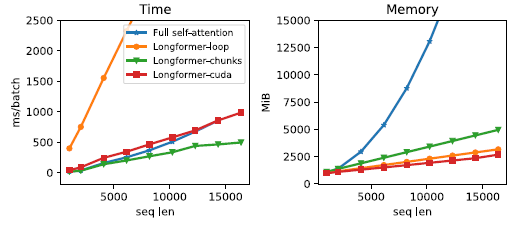
- loop: 벡터화 X
- chunk: 벡터화
- cuda: custom cuda kernel 구현 (
더 자세히) - 3.2에서 detail
-
attention 작업을 sequence 길이에 선형 비례하는 Longformer를 긴 문서 작업에서 다용도로 사용가능
-
기존 방법들
- 긴 sequence를 작은 sequence(512 token 이하)로 분할하는 BERT의 방식은 중요한 cross-partition 정보 손실 위험이 있다.
- 최근 작업들은 Autoregressive(자기회귀) model에만 집중한다. (긴 sequence 해결을 위해)
- 하지만, transfer learning에 적용한 사례가 없다....
-
Longformer attention mechanism
- windowed local-context self-attention
- contextual representation 생성 역할
- end task motivated global attention (task의 귀납적 편향을 encoding한)
- 예측을 위한 전체 sequence representation 생성 역할
- 둘 다 필수! (하나라도 없으면 성능 Down)
- windowed local-context self-attention
-
Longformer는 새롭게 확장된 attention으로 32000개의 단어까지 GPU에 올릴 수 있었다.
- Longformer는 text8과 enwik8에서 SOTA를 달성하고, 긴 문서에 효과적임을 증명
-
Longformer pre-training
- MLM 학습을 적용
- 문서 분류, QA, 상호참조해결(coreference resolution) 등 문서 level task에서 RoBERTa 성능을 능가 (2개 task는 SOTA)
-
Longformer Encoder-Decoder (LED)
- seq2seq learning
- Longformer의 효율적 attention을 encoder에 사용 → 요약, 긴 문서 작업 처리 가능
- arXiv 요약 data로 LED 유효성 증명
💡 inductive bias (귀납적 편향): 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 [더 자세히]
2. Related Work
Long-Document Transformers
-
기존 긴 문서 작업
- left-to-right approach (chunk로 나누고 l-t-r 방향으로 이동)
- autoregressive modeling에서는 성공적
- 양방향 context에는 이점이 없음
- left-to-right approach (chunk로 나누고 l-t-r 방향으로 이동)
-
우리의 approach
- sparse한 attention pattern을 만들어 full attention matrix 곱셈을 피한다.
- Sparse Transformer의 attention pattern(BlockSparse)과 유사
- custom CUDA kernel 포함 → BlockSparse보다 유연하고 유지 관리 용이
- task motivated global attention pattern → 일반적인 NLP task에 적합
- transfer learning setting에서 좋은 성능
-
몇몇 모델은 autoregressive modeling이외의 task 시도 → 1차 평가로 언어 모델링에 초점은 제한된 모델 개발
- BP-Transformer
- 기계 독해에 대해 평가
- pre-train을 시도 X
- Blockwise attention
- pre-train도 했고, QA에 대해 평가도 함
- 그러나, 언어 모델링 포함 X, QA 데이터셋 문장이 비교적 짧은 문서로 구성
- 긴 문서에 잘 작동 모름..
- BP-Transformer
Task-specific Models for Long Documents
- 다양한 task별 approach (BERT 한계 극복을 위한)
-
가장 단순 방법 (문서를 자름)
-
512 길이 chunk로 나누고, 각각을 process
-
2단계 모델 사용 (QA에 널리 사용)
- first stage: 두번째 stage로 전달되는 관련 문서 검색(??)
- second stage: 답변 추출—> 모든 approach 정보 손실 존재
—> Longformer는 정보 손실 X → 단순히 문장을 이어붙이면 됨
-
- Longformer와 비슷한 연구
- ETC
-
local + global attention 사용 (비슷)
-
상대적 위치 embedding 사용
-
pre-training을 위해 추가 train 목적함수 (CPC 로스) 도입
-
global attention 구성 방식 다름
—> 좋은 성능을 보여줌
-
- GMAT
- global memory 역할을 하는 input의 global 위치가 거의 없다는 비슷한 아이디어 사용 (??)
- Big Bird
- ETC 확장 (평가에 요약과 같은 task 추가)
- sparse Transformer가 sequence 함수의 보편적 근사치이며(??), full self attention의 이러한 속성을 보존한다는 것을 보여줌.
- ETC
3. Longformer
-
기존 Transformer self-attention (n: sequence 길이)
- 시간복잡도 → O(n^2)
- 공간복잡도 → O(n)
-
Longformer
- 서로 관련된 input 위치 pair를 지정하는 “attention pattern”에 따라 full self-attention matrix를 희소화 (sparsify)
3.1 Attention Pattern
-
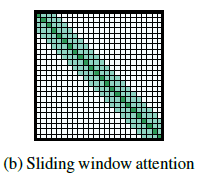
Sliding Window
-
각 token을 둘러싼 고정된 크기의 window attention 사용
-
window attention을 여러 layer를 쌓아서 큰 receptive field(CNN과 유사) 구축
-
윈도우 사이즈: w / layer 수: l
- 특정 토큰 앞뒤로 1/2w만큼의 토큰에 대해 attention 계산 —> O(n*w) : 선형
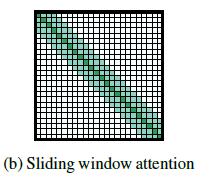
- receptive field size: l * w
- 특정 토큰 앞뒤로 1/2w만큼의 토큰에 대해 attention 계산 —> O(n*w) : 선형
-
layer마다 w를 다르게 사용하면, 효율성과 모델 representation 용량간의 균형 맞춤 (4.2)
-
-
Dilated Sliding Window
- receptive field를 늘리기 위해 window를 ‘확장’시킴 (dilated CNN과 유사)
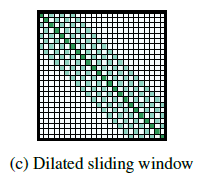
- d: window 사이의 간격
- receptive field size: l d w
- multi-head attention에서 각 head마다 d값을 다르게 주어 성능 향상을 확인
- 몇몇 head는 d를 적게 주어 local context에 집중
- 몇몇 head는 d를 크게 주어 전반적인 context에 집중
- receptive field를 늘리기 위해 window를 ‘확장’시킴 (dilated CNN과 유사)
-
Global Attention
-
기존 BERT의 경우
- task별로 optimal input representation이 다르다.
- MLM의 경우, masked 단어를 주변 단어들을 통해 예측
- 문장 분류의 경우, 전체 sequence의 representation을 special token으로 합침 (ex. BERT의 CLS)
- QA의 경우, 질문과 문서를 concat하여 self-attention을 통해 모델이 질문, 문서 비교
-
우리의 경우
-
window attention이 task별로 학습하기에 유연하지 않다..
—> global attention 추가 (미리 선택된 input 위치에)
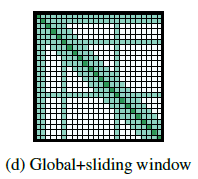
-
global attention이 적용된 토큰은 모든 토큰과 attention을 계산 (대칭적)
-
문장 분류의 경우, CLS 토큰에 global attention 적용
-
QA의 경우, 질문 토큰 전부에 global attention 적용
—> global attention 적용된 token 수가 n보다 작기 때문에 복잡도 O(n)
—> global attention은 귀납적 편향을 추가하기 간단한 방법 (input chunk 변경, 복잡한 아키텍처 추가 방법들보다)
-
-
-
-
Linear Projections for Global Attention
-
기존 Transformer
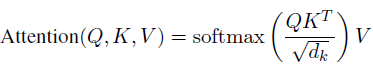
-
Longformer
- sliding window attention
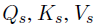
- global attention
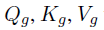
- 두 개의 projection으로 나누어 attention 계산
- sliding window attention
-
3.2 Implementation
-
기존 Transformer
- Q * K 부분이 복잡도가 높다
-
Longformer
- Q, K 모두 고정된 수의 대각선만 계산 → 메모리 효율적
- 현재 Pytorch/Tensorflow에서 띠행렬 곱셈을 지원 X..
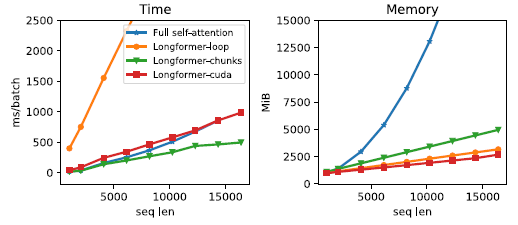
- 3가지 다른 방법
- Loop: 메모리는 효율적이지만, 학습이 매우 느리고 테스트용으로만 사용
- Chunks: 확장되지 않은 경우만 사용가능 (pre-training, fine-tuning 설정에 사용)
- CUDA: TVM을 사용하여 구현된 최적화된 맞춤형 CUDA 커널 사용
💡 TVM: 딥러닝 컴파일러 [더 자세히]
4. Autoregressive Language Modeling
- 기존 Autoregressive LM
-
input에서 이전 단어를 고려하여 단어 확률 분포를 추정하는 것 (느슨한 정의다?)
-
NLP 기본 작업 중 하나이다.
—> Longformer도 Autoregressive LM에 대한 모델을 개발하고 평가
-
4.1 Attention Pattern
- Autoregressive LM
- dilated sliding window attention 사용
- layer마다 다른 window size 사용
-
low layer일수록 작은 size → local 정보 포착
-
high layer일수록 큰 size → 전체 sequence representation 파악
—> 효율과 성능 사이의 균형 조절
-
- dilated 사용
-
low layer 사용 X
-
high layer도 2개의 헤드에만 적용
—> local 정보를 잃지 않고, 멀리 떨어진 token의 정보도 직접 사용할 수 있는 구조
-
4.2 Experiment Setup
-
이전 작업과 비교하기 위해 character-level LM에 집중
-
Training
- 최대 window size와 sequence length로 실험하고 싶었다
- local context 학습하는 것도 많은 gradient update 필요... (너무 오래 걸림)
- 점진적으로 증가하는 방식으로 학습
- 짧은 sequence, 작은 window size부터 시작해서 점점 늘려가는 방식
- 총 5 phase
- sequence 길이: 2,048 → 23,040
- 최대 window size와 sequence length로 실험하고 싶었다
-
Evaluation
- sequence 길이 32,256으로 평가
- sequence를 512개마다 자르고 마지막 512개로 성능 평가
-
Results
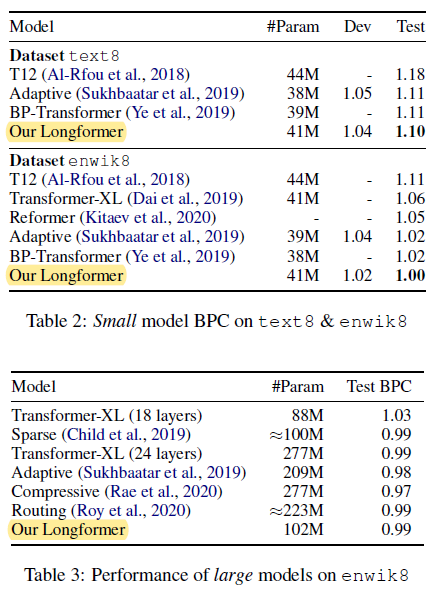
- text8, enwik8에서 SOTA 달성 (small 모델)
- large 모델은 enwik8만 평가
- Transformer-XL보다 성능 좋음
- Sparse 모델과 비슷
- 파라미터가 2배인 모델보다는 살짝 성능이 떨어짐
- Adaptive, Compressive는 pre-training과 fine-tuning과 안 맞아서 패스
4.2.2 Ablation Study
- attention pattern의 중요성

5. Pre-training and Fine-tuning
- 최근 많은 NLP task들의 SOTA는 pre-trained 모델을 fine-tuning한 경우다. (ex. BERT)
- Longformer도 비슷한 구조로 만들려 했다.
- MLM으로 pre-train
- 한 번에 4,096 token 가능 (BERT의 8배)
- 우리의 attention pattern은 어떤 pre-trained transformer 모델에도 적용 가능 (모델 아키텍처 유지하면서)
- Longformer도 비슷한 구조로 만들려 했다.
Attention Pattern
- RoBERTa와 계산량 동일, 512 window size 사용
Position Embeddings
- RoBERTa의 경우, 512 길이의 절대 position embedding
- Longformer의 경우, 길이가 4096이기에 512 position embedding 복사해서 초기화 (그냥 랜덤 초기화시 편향된다..??) —> 효과적
Continued MLM Pretraining
- fairseq으로 longformer를 base, large 사이즈로 학습
- 모델이 더 큰 window size와 긴 sequence를 잘 활용하도록 학습한다는 결과 확인
6. Tasks
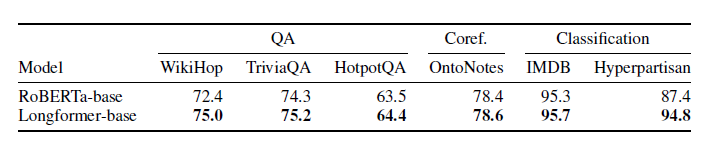
- QA, 상호참조해결, 분류를 포함한 긴 sequence 작업에 Longforemer 적용
7. Longformer-Encoder-Decoder (LED)
- 기본 Transformer는 Encoder - Decoder 형태
- Seq2Seq task를 위해 (요약, 번역 등..)
- Encoder만 있는 Transformer
- 다양한 NLP task에서 효과적
- pre-trained encoder-decoder Transformer model
- BART, T5
- 요약 같은 task에 강함
—> 하지만, 긴 sequence에 대해서는 효과적이지 않음
-
Longformer - Encoder -Decoder (LED)
- Encoder는 local + global attention 적용
- Decoder는 full self attention 적용
- 요약 task arXiv data로 평가 (긴 문서 요약 도메인)
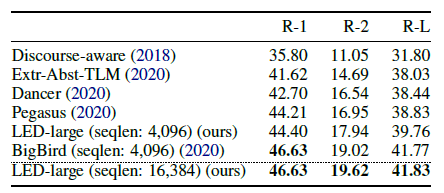
- pre-train 혹은 task-specific 초기화 없이, 긴 input을 처리로 BigBird 보다 좋은 성능
8. Conclusion and Future Work
-
Longformer가 있으면
- input을 자르지 않아도 됨
- 복잡한 아키텍처를 추가하지 않아도 됨
-
Longformer는
- local + global attention pattern을 사용
- text8, enwik8에서 SOTA 달성
- pre-train을 하면, 긴 문서에서 RoBERTa 성능을 능가하고 WikiHop, TriviaQA에서 SOTA
-
LED
- arXiv 긴 문서 요약 task에서 SOTA 달성
-
더 나아가
- LED의 pre-train objective를 더욱 연구할 것이다.
- sequence 길이를 늘리며 우리 모델이 이점을 얻을 수 있는 다른 task를 탐색할 것이다.
