✏️학습 정리
3. Sequence to Sequence with Attention
-
Seq2Seq Model
-
many-to-many에 해당
-
기본 구조 (encoder + decoder)
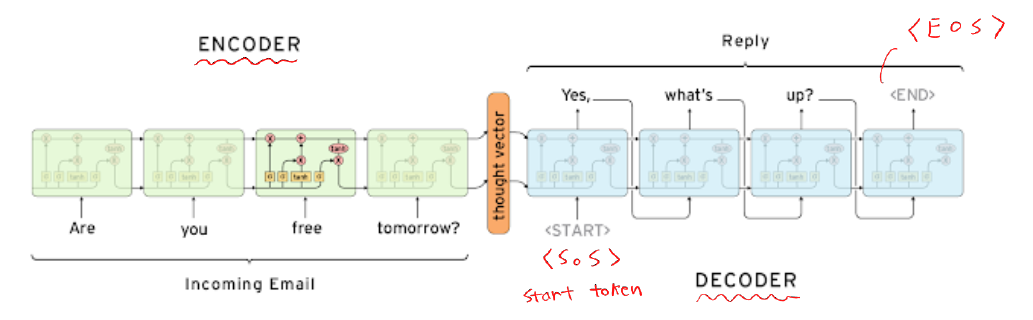
-
Attention
- input sequence의 특정 부분에 집중하는 것이 핵심
-
Seq2Seq Model with Attention
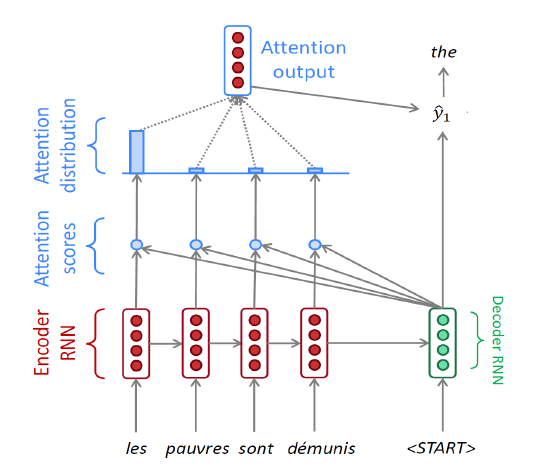
-
Teacher forcing
- train 시점에 직접 예측값을 input으로 넣지 않고 gt를 넣어주는 방식 (실제 환경과 다름)
-
Backpropagation
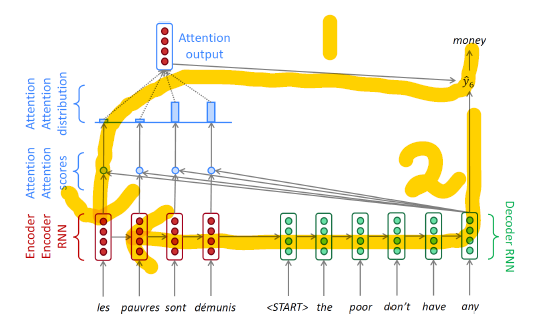
- 1번 경로: attention 모델
- 2번 경로: 일반 RNN 모델
- attention을 적용할 경우 역전파의 과정이 간소화된다.
-
다양한 attention 방법

-
attention 장점
- 기계 번역 성능을 크게 향상시켰다.
- decoder bottleneck 문제 해결
- vanishing gradient 문제 해결 (backpropagation 지름길 제공)
- 해석 가능성 제공 (decoder가 encoder의 어떤 단어에 집중했는지 확인 가능)
-
-
Beam Search
-
Greedy decoding
- 현재 time step에서 최적의 답 도출
- 선택한 최적값이 정답이 아닐 수 있다..
-
Exhaustive search
- 매 time step마다 모든 단어를 확인 (시간복잡도가 너무 높다)
-
Beam search
-
각 time step마다 k개의 최적해를 선택
-
global optimal solution을 제공하지는 않지만, 앞의 두가지 방법보다 효율적이다.
-
예시 (k=2)
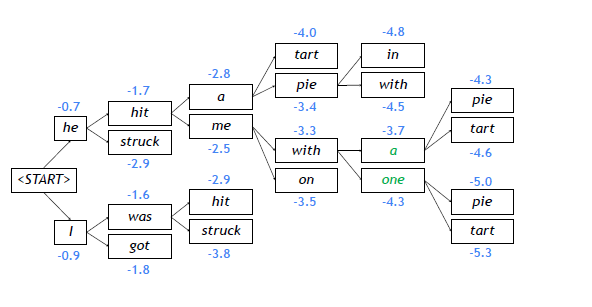
-
종료 조건: 최대 time step T까지, 완료된 hypothesis의 최소 개수 n 이상일 경우
-
평가

-
길이 Normalize

- why? → 단어가 늘어날 때마다 기존 확률을 더해주기 때문에 (길이가 score에 영향)
-
-
-
BLEU score
- 단순 정확도는 기계 번역에서 지표로 쓸 수 없다.

- Precision (정밀도)
-
위치와 상관없이 gt와 겹치는 단어 개수 (확률), 분모가 예측 문장
-
검색 결과 예측 (예측한 결과가 올바르게 나왔나?)
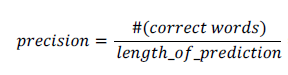
-
- Recall (재현율)
-
분모가 gt 문장
-
실제로 검색했을 때 결과로 나온 문서들이 예측한 문서에 나왔는가?

-
- F-measure (조화 평균)

- BLEU score
-
N-gram 사용
- 연속된 N개의 단어(문장, 문단)가 gt와 얼마나 겹치는 지 계산
-
n-gram으로 precision만 계산 (번역시 gt와 완전히 동일하지 않아도 좋은 번역일 수 있어서 recall 고려 X)

-
brevity penalty: 길이가 너무 짧은 번역들에 대한 penalty
-
- 단순 정확도는 기계 번역에서 지표로 쓸 수 없다.
🗣️피어세션
- BPTT 이외에 RNN/LSTM/GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법
-
Truncated BPTT
- sliding window 방식으로 앞 뒤 n개의 batch만 가지고 역전파
- https://github.com/hyunbool/deep_learning_seminar/blob/master/deep_learning_from_scratch2_chap5.pdf
-
Gradient Clipping
- loss fn의 gradient 값이 임계치(threshold)를 넘을 경우, threshold 값으로 줄이는 방법
- https://sanghyu.tistory.com/87
-
활성화 함수로 ReLU를 사용
- RELU:
- Leaky ReLU:
- https://casa-de-feel.tistory.com/36
-
가중치 초기화
- Xavier Initialization
- He Initialization
- 적절한 가중치 초기화 솔루션은 그 자체로 Gradient 문제 해결에 도움이 된다.
-
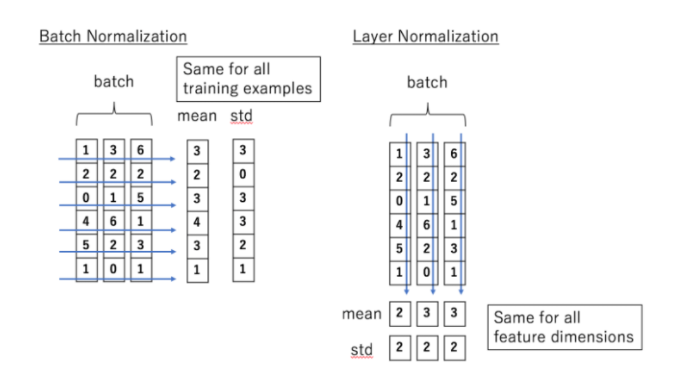
Layer Normalization
-
- RNN 계열 함수에서 ReLU를 사용하지 않는 경우
- RELU의 경우 값이 매우 커질 수도 있기 때문에(output exploding)
- Tanh 기울기 ⇒ 0~1 사이
- https://machinelearningmastery.com/choose-an-activation-function-for-deep-learning/
- Neural Network에서 Bias가 갖는 의미는 무엇인가?
-
좌표평면 예시
- bias가 없다(=0) → 함수가 원점을 벗어나지 못한다 → 다양성이 줄어든다
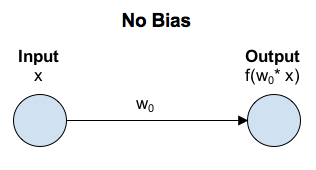
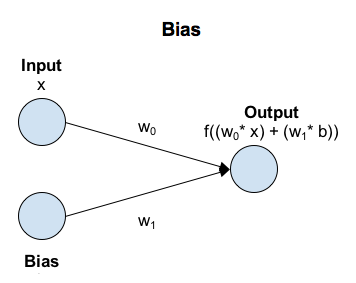
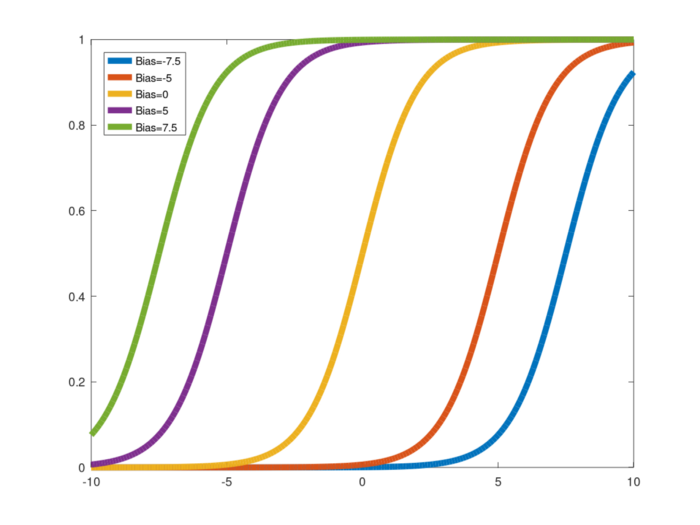
ref. https://towardsdatascience.com/why-we-need-bias-in-neural-networks-db8f7e07cb98
-
