Intro
- 이번 논문 리뷰는 Justin Johnson의 EECS 498-007 / 598-005 Lec8. CNN Architectures 중 Resnet관련 부분의 추가적인 이해가 필요하다싶어 작성하였습니다.
Introduction
-
해당 논문이 발표될 당시 많은 논문들에서 제시된 것처럼 deep model일 수록 성능이 향상된다는 것이 일반적인 견해였다. 이 논문은 그렇다면 "더 많은 layer쌓는것 만큼 network의 성능은 좋아질까?" 라는 질문에서부터 시작된다.
-
위와같은 질문에 가장 먼저 고려해야할 사항은 vanishing/exploding gradients 문제라고 지적하였고 이는 당시 여러 normalization을 통해 개선되어 왔다고 한다.
-
하지만 좀 더 deeper network에서 "degradation" 문제가 드러났고 이는 overfitting과는 다른문제라고 말한다.
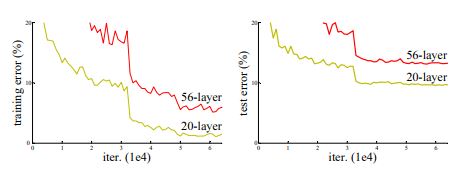
-
위 그림은 CIFAR-10 dataset에 VGG model의 20-layer network와 56-layer network를 학습시킨 실험 결과인데, 56-layer network가 오히려 training, test 둘 다 error rate가 증가했음을 보여주었고 이는 overfitting문제가 아닌것을 보여준다.
-
해당 논문에서는 layer를 깊게 쌓되 많은 layer들이 identity mapping으로 이루어지도록 만든다면 deeper model이 shallow model에 비해 높은 training error를 가지면 안된다는 것이 degradation 문제를 해결하기위한 핵심 idea라고 말한다.
-
논문에선 degradation 문제를 해결하기 위해 a deep residual learning framework 를 제시하였다
Residual Learning
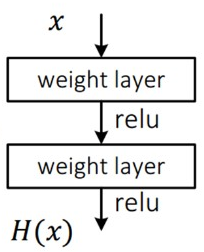
- 기존 neural net의 underlying mapping이 H(x)라면 즉, H(x)를 최소화시키는 것이 학습의 목표였다면 이 논문에서는 F(x) = H(x) - x 를 최소화시키는 Residual mapping으로 H(x)를 재정의 하였다.
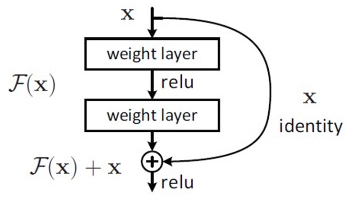
-
이러한 재정의는 기존의 unreferenced mapping인 H(x)를 최적화하는 것 보다 identity mapping시킨 residual mapping F(x)가 더 최적화가 쉽다는 가정에서 시작되었다.
-
극단적으로 보면 identity mapping이 optimal한 해라고 했을때 H(x)가 x가 되도록 학습하는 것 보다 residual인 F(x) 가 0으로 되도록 학습하는 것이 쉬울 것 이라고 말한다.
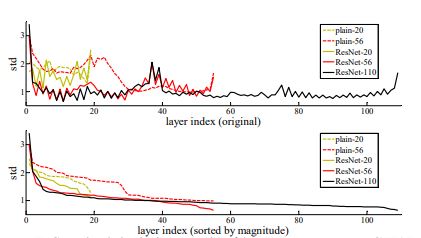
-
위 그림은 original network(plain network)와 residual network에 대해 각 layer에서 response에 대한 std를 살펴본 것으로 residual network가 작은 response값을 가지고있고 이는 학습이 쉬울 것이라는 것을 대변한다.
-
F(x) + x 형태의 Shortcut Connection 은 단순히 identity mapping을 추가함 으로써 추가적인 파라미터도 필요하지 않고 추가적인 복잡도가 증가하지 않는 것이 장점이다.
-
이러한 residual block을 식으로 나타내면 위와이 나타낼 수있고 이것은 두개의 weight layer와 ReLU를 거치기에 와 같이 나타낼 수 있다. (이때 bias는 생략)
-
residual block의 input dimension과 output dimension이 다를경우 input x에 linear projection시켜주어(아래 식에서 ) 다음과같은 식으로 나타낼 수 있다.
Network Architectures
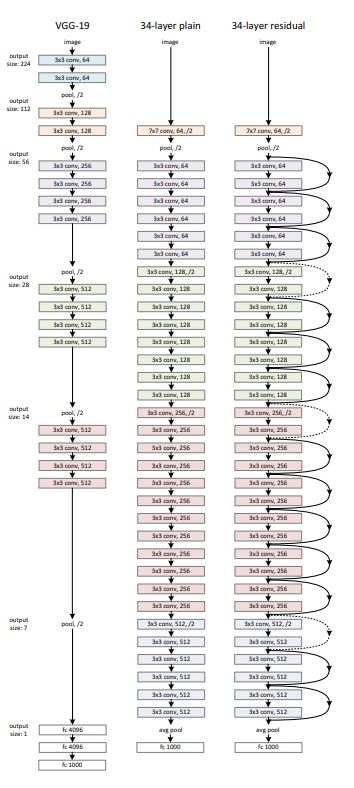
-
ResNet은 VGG에 영감을받아 plain net을 만들었으며 이는 동일한 feature map size를 갖게하기 위해 layer에서 3*3 filter를 사용하였고 stride 2로 downsampling할 때에는 channel수를 두배로 늘려 time complexity를 유지하였다.
-
마지막 convolutional layer의 output은 global average pooling을 통해서 pooling을 하고, 그 결과를 fully connected layer를 통해 class 개수만큼의 출력으로 변환후 loss function으로 softmax를 사용하였다.
-
이러한 구조로 VGG에 비해 필터의 갯수를 낮추어 parameter수를 낮추었고 복잡도를 낮춰 VGG-19.6 GFLOP 을 3.6 GFLOP으로 연산량을 확 낮추었다.
Implementation
-
구현 환경은 다음과 같다.
- Scale Augmentation : 짧은 쪽 기준 256~480 size로 random resize, 각 이미지마다 224x224로 random crop or 상하로 뒤집은 10장의 데이터 사용
- Color Augmentation : AlexNet에서 사용한 방식 채택
- Batch Normalization : 활성함수와 Conv Layer 사이에 적용
- Weights Initialization : Rectifier networks에서 사용한 방식 채택
- Mini Batch : 256
- Learning Rate : 초기값 0.1에 에러율 변화가 없을 시 1/10으로 감소
- Iteration : 60 x 10^4
- Decay & Momentum : 0.0001, 0.9
- Dropout : 미사용
Experiments
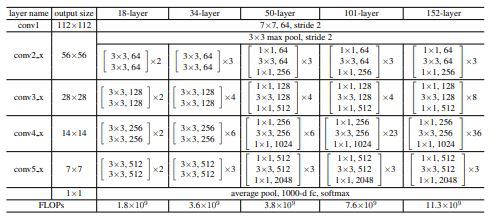
-
실험에선 위 표와같은 구조를 사용하였고 50-layer 이상에서는 조금 다른 구조를 갖고있는데 이는 뒤에서 살펴본다.
-
먼저 18-layer와 34-layer에 대한 plain net과 residual net의 실험 결과를 살펴보면 아래와같다.
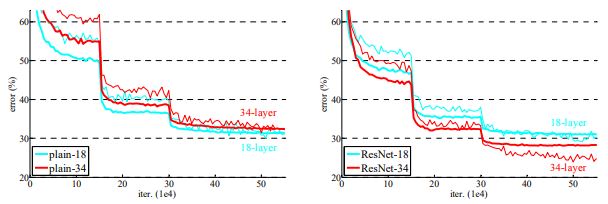
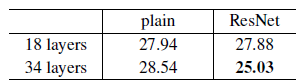
-
위 실험을 토대로 Residual network가(오른쪽 그래프) plain network(왼쪽 그래프)의 degradation 문제를 해결한 것을 나타내며 초기의 수렴 속도도 빠른것을 볼 수 있고 이를 통해 resnet의 optimization이 쉽다는 것을 알 수 있다.
-
Table 1에서 50-layer 이상부터 구조가 조금 달라진 것을 볼 수 있었는데 이는 layer가 많아질 수록 parameter가 많아지게되며 FLOP 수가 늘어나 연산량이 많아지게되어 complexity가 높아져 이를 해결하기위해 bottleneck architecture를 사용하였다.

- Bottleneck은 기본적으로 연산량을 줄이기 위해 사용하며 GoogLeNet의 Inception구조 처럼 demension을 줄이기 위해 1x1 conv를 통해 channel수를 줄였다가 3x3 conv를 거친 후 다시 1x1 conv를 통해 channel수를 늘려주는 방식으로 위 그림에서 보다시피 연산량은 줄임으로서 complexity도 낮추었고 추가로 non-linear(ReLU)도 추가로 수행하여 학습에 도움을 주게된다.
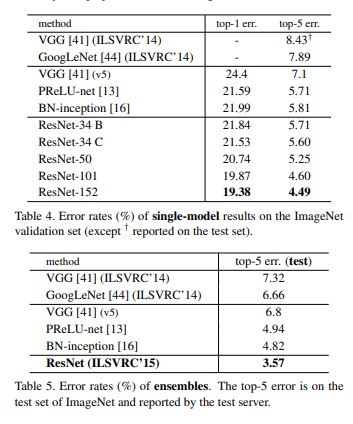
- 위 tabel4를 통해 ImageNet에 대한 single model의 error rate가 resnet의 network가 깊어질 수록 낮아진다는 것을 보여주며 table5를 통해 esemble을 적용하면 성능이 더 좋아지는 것을 보여준다.
Outro...
-
기존의 CNN model을 통해 network가 깊어질 수록 성능이 좋아질것이라 생각했지만 degradation 문제가 발생하여 이를 해결하기위해 ResNet은 shortcut-connection을 사용한 identity mapping으로 degradation 문제를 해결하였다.
-
이 논문 이후에 ResNet 팀은 Identity Mappings in Deep Residual Networks 논문을 통해 Identity mapping에 대한 고찰과 자신들의 architecture에 대해 개선된 architecture를 선보였다.
-
Identity Mappings in Deep Residual Networks 는 바로 리뷰하여 포스팅 할 예정이다.
References
