[EECS 498-007 / 598-005] 10_1 Training Neural Networks (Activation Function, Weight Initialization)

Intro
-
직전 포스팅이 7강 이었지만 cs231n 과정과 맞추어 나가고자 8강, 9강 은 뒤로 미루고 10강 내용 부터 포스팅합니다.
-
이번 강의는 neural network training의 전체 process 중 trining process 전 과정인 setup 과정에 대해 다룹니다.
-
One time setup 과정은 Activation functions, data preprocession, weight initialization, regularization내용을 포함하고 있다.
Activation Fcuntions
- 디테일한 Activation Fcuntion들에 대해서 알아보기전에 이 전에 보았던 Artificial Neuron을 통해 activation function의 역할을 알아보자.

-
위 그림에서 보시다시피 하나의 Neuron에선 input x와 weights w를 dot product하여 activation function의 input으로 들어가게되고 non-linear activation function을 거쳐 다음 layer로 출력하게 된다.
-
우리는 항상 모든 layer(혹은 node)에서 activation fcuntion을 갖는데 이때 activation fcuntion이 없다면 전체 neural network가 단순한 linear model과 다를바 없게 되기에 activation fcuntion의 역할은 상당히 중요하다.
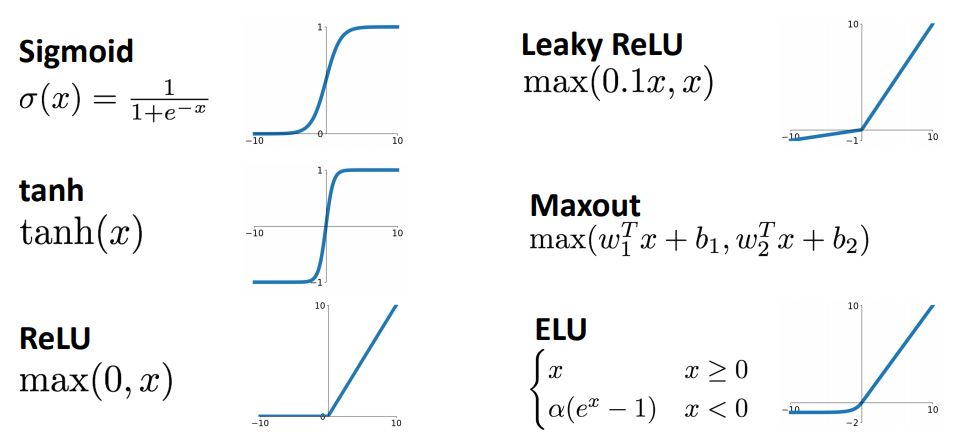
- 위 그림에 나온 여러 activation fcuntion들을 자세히 다루면서
각각의 장단점과 선택시 고려해야할 사항들에 대하여 다루고자 한다.
Sigmoid function

-
우선 neural network에서 사용되는 가장 classic한 activation function인 sigmoid function을 살펴보자.
-
sigmoid function은 0과 1 사이의 output을 출력하기 때문에 output을 확률적으로 접근 할 수 있었고 이는 the presence or absence of a boolean variable의 확률로 해석할수 있었다고 합니다. (뭔소린지 모르겠다ㅎㅎ)
-
sigmoid function은 또한 "firing rate" of a neuron 으로 해석 할 수 있는데 이는 input 의 값에따라 neuron이 off되는 것을 뜻하고 이는 "non-linearly dependent on the total rates of all the inputs coming in" 이라고 한다.
* (뇌피셜) "non-linearly dependent on the total rates of all the inputs coming in"은 input x에 곱해지는 weight들이 0이되게하는 solution (firing rate)을 말하는 듯 하다.
-
sigmoid function이 매우 유명했던 반면에 자주 쓰이지 않는 이유 3가지가 있다.
Problem 1. Saturated neurons “kill” the gradients
- sigmoid function은 처음과 끝 부분에 flat한 형태를 갖고있기에 zero-gradient의 saturated regimes (포화 상태)를 가져 이는 사실상 gradient를 죽게하여 network가 robust한 학습을 어렵게 한다.
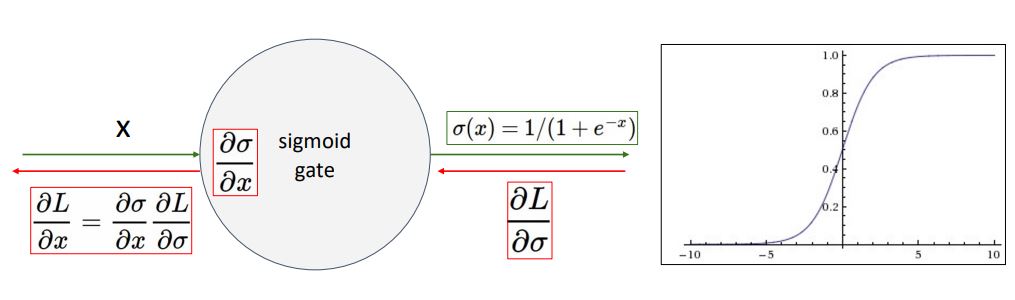
-
input x가 -10보다 작은 값이거나 10이상인 큰 값일 때 sigmoid function이 어떻게 동작할까?
: 이때 backprop과정에서 local gradinet(dL/dw)는 0에 가깝게 수렴하게 되고 이는 upstream gradient가 어떻든간에 chain rule을 통해 downstream gradient가 0에 가까운 매우 작은값만큼 update됨을 뜻한다. 이는 이후의 backprop에서도 layer들도 saturation 되어 w가 매우 작은 값으로 update된다.
* 이러한 saturation을 포함해 w의 gradient가 0으로 수렴해 update가 중지하는 현상을 gradient vanishing이라 한다.
Problem 2. Sigmoid outputs are not zero-centered
-
sigmoid function은 input이 어떻든지 0~1 사이의 positive값을 출력한다
-
이전 layer에서도 sigmoid function을 사용했다고 하였을때 input 는 positive값이 되고 이때 의 gradient는 어떻게 될까??
-> 이 항상 positive이기 때문에 에 대한 local gradient는 항상 positive이다. 하지만 chain rule에 의해 곱해질 upstream gradient는 positive값이 될 수도 negative값이 될 수도 있다. 이는 (update되어야할)downstream gradient가 항상 upstream gradient의 부호(positive or negative)와 같아진다는 것이고 이는 항상 같은 부호를 갖고 (+ or -) update가 되어 아래의 그림과 같은 zigzag pattern현상이 발생하여 학습(update)속도가 느려지게 된다.
-
이러한 현상을 그림으로 표현하면 다음과 같다.
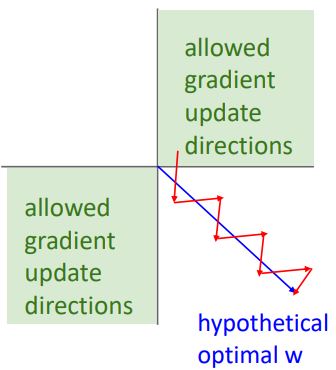
- 위 그림은 w_1, w_2 weight 두개에 대해만 시각화하여 살펴보았지만 D-dim weights로 확장해 보았을때 모든 weight들이 positive or negative 중 한방향으로만 update되어 high dimensional space상에의 사분면(quadrant)중 활용할 수 있는 direction은 두 direction(두개의 사분면) 밖에 없어지게된다.
Problem 3. exp() is a bit compute expensive
- 세번째 문제는 exp term은 연산속도가 느리다는 것인데 이것은 GPU를 사용하지 않고 CPU만을 사용하거나 mobile devices에서 사용할 경우 문제가 된다고 한다.
Tanh function
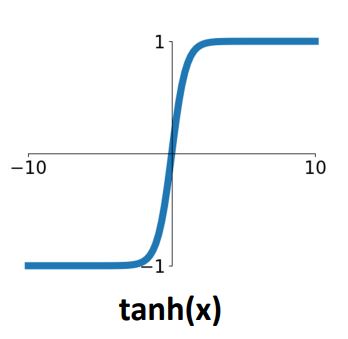
- Tanh function은 기본적으로 scaled and shifted version of sigmoid으로 zero-centered 문제는 해결하였지만 여전히 saturation현상을 갖게된다. 또한 수식에서 보듯이 exp term이 4개라 연산속도가 느리다.
ReLU function
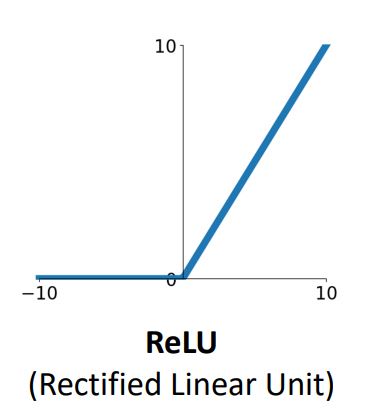
-
ReLU function은 non-linear하면서 가장 심플하여 가장 빠른* activation function이다
* AlexNet 에 따르면 sigmoid, tanh에 6배가량 빠르게 loss에 수렴한다고 한다.
-
ReLU는 또한 input이 positive일 때 saturation문제를 발생시키지 않는다.
-
하지만 ReLU function도 output이 positive한 값만을 갖기에 not zero-centered ouput 문제를 갖어 여전히 zig-zag pattern 현상을 갖는다.
-
그렇다면 input x가 0보다 작을때는 어떻게될까?
-> local gradient가 0 이 되어 downstream gradient가 0이 되고 이는 때때로 sigmoid보다 좋지못한 결과를 가져온다. 이유는 sigmoid는 0에 수렴한 값을 갖지만(output으로) ReLU는 명백히 zero-gradient를 갖기에 아예 update가 멈추게된다. -
Negative input에서 saturation문제는 막을 수 없지만 sigmoid, tanh보다 saturation 영역(gradient가 0에 가깝거나 0이되는 곳)이 적어 ReLU를 사용한다.
Leaky ReLU
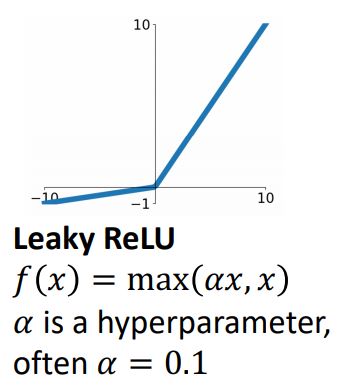
-
ReLU의 두가지 문제를 해결하고자하는 업그레이드 버전인 Leaky ReLU가 있다.
-
위 그림과 수식에서 보다시피 negative regime의 saturation문제를 해결하고자 negative regime에서 0이아닌 를 optput으로 갖게한다. 이때 hyperparameter인 alpha값은 작은값을 주어 small positve slope를 갖게한다.
-
또한 Leaky ReLU는 zero-centered 문제를 해결하여 dead ReLU를 없애버렸다.
-
안그래도 initial setup할게 많은데 hyperparameter가 많아지면 더 골아파지니 hyperparameter인 alpha를 learnable parameter로 바꾼 PReLU도 있다.

-
이러한 ReLU와 Leaky ReLU도 zero point에서 미분가능하지 않다는 문제가있다
* 사실 확률적으로 x가 정확히 0이올 확률은 드물기때문에 보통 이러한 문제는 무시하고 사용 한다고 한다.
Exponentail Linear Unit (ELU)
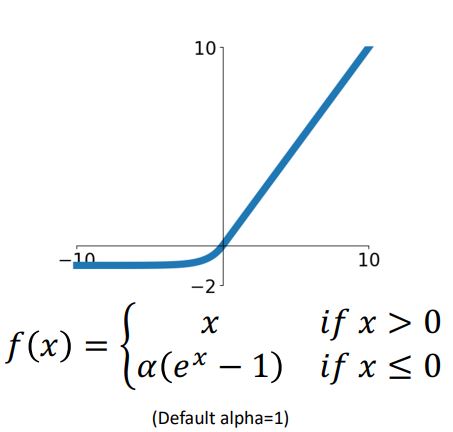
-
ELU는 ReLU, Leaky ReLU의 not differentialbe한 문제를 해결하였지만 exp term이 추가되어 또다시 연산이 느려지게 되는 문제가 있고 또한 hyperparameter인 가 추가되어 골아프게한다.
-
또한 ELU에 하나의 hyperparameter가 추가되 자체 normalization도 겸비하여 output의 분산을 일정하게 해주는 SELU라는 activation function도 있는데 아래의 그림에서 보다시피 91page의 논문은 당장 나의 골이 아파오게 하는 문제가있어 다루지 않는다.

- 다음은 CIFAR10 dataset을 가지고 3개의 다른 architecture에서 다른 activation function의 성능을 비교하는 그림이다.
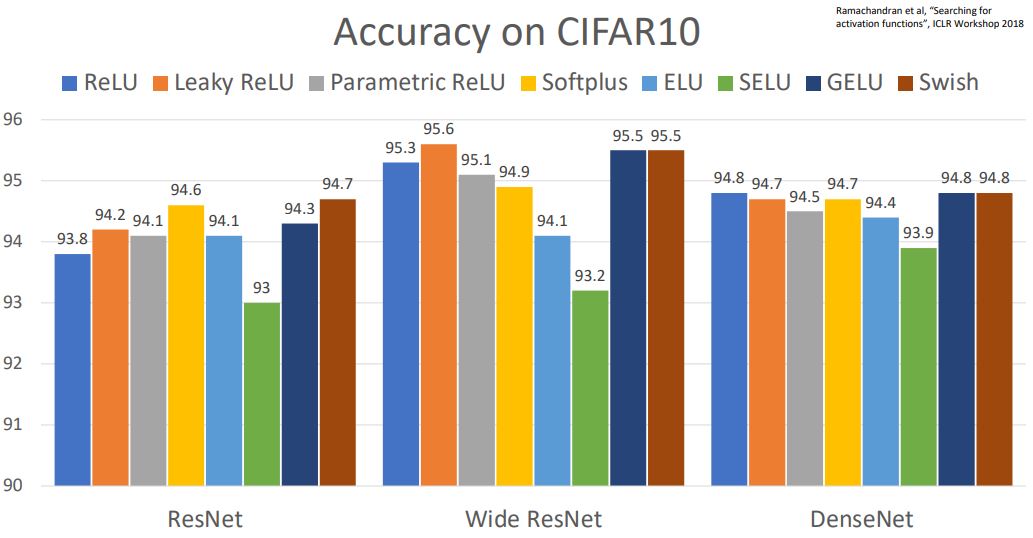
- 강의에서 Justin Johnson 말하길 ReLU나 다른거나 큰 차이 없으니까 그냥 일단 default로 사용하고 activation function을 선택하는데 너무 스트레스 받지 말라고 하신다!!!!!!!!!!!!!
Data Preprocessing
-
이 부분은 바로전 posting인 Batch Normalization에서 대부분 다룬 내용이기에 스킵한다.
-
한가지만 짚고 넘어가자면 image data가 아닌 경우 pre-processing으로 PCA와 Whitening을 할 수 있는데 이는 각각 decorrelated data, whitened data를 뜻한다.
Weight Initialization
- 우리는 neural network를 학습시키기 전에 어찌되었든 weights를 initailization 해야한다.
zero-init / constant-init
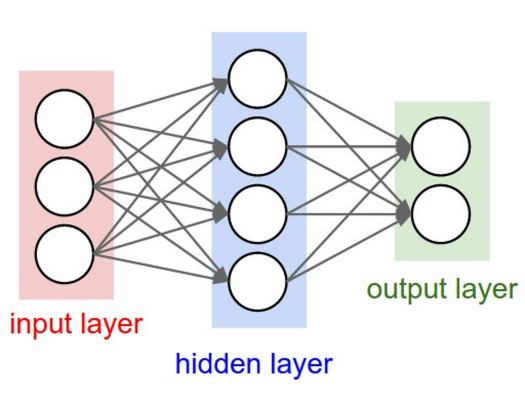
-
위 그림과 같은 fully-connected network에서 W와 B를 모두 0으로 initialization 시킨다면 어떻게될까? (B는 무시해도 무방하다)
-
해당 layer의 output이 input에 상관 없이 모두 zero가 될 것이이며 (activation funcion이 ReLU일 경우) gradient도 zero가 될 것이다. 이는 weights update가 되지 않는다는 뜻이고 학습이 되지 않는다.
-
Constant로 초기화 해도 모든 neuron의 gradient가 같아질 것이기 때문에 강의에서는 이를 "not having symmetry breaking" 이라고도 표현하고 이는 어느 neuron(one hidden unit)이던 forward pass에선 모든 input feature에 대해 같은 weights로 반응하며 backprop 에선 모든 feature에 대응하는 weights들이 same gradient가 적용되어 같은 크기로 update된다는 것을 의미한다.
Initialize with small random values
-
이전 zero initialization의 문제점을 보완하고자 small random values로 초기화하려 한다.
-
강의에선 W를 정규분포로 sampling 시키고 작은 값(small value)으로 scaling시켜주는 RandomNormal initalization을 설명한다.
* RandomNormal initalization 말고 RandomUniform과 TruncatedNormal initalization같은 방법들이 있다.
w = 0.01 * np.random.randn(Din, Dout)-
위 코드는 zero-mean, unit-std를 갖는 가우시안 분포를 따르는 값들을 0.01 scaling 시켜주어 (std=0.01 로 만듦) 초기화시켜준 것이다.
-
이러한 방식은 작은 network에서는 잘 동작하지만 layer가 많아질 수록 문제가 발생하게 된다. 이를 코드와 데이터 분포 시각화를 통해 살펴보자.
dims = [4096] * 7 # hidden unit size = 4096
hs = []
x = np.random.randn(16, dims[0]) # input vector dim(size) = 16
for Din, Dout in zip(dims[:-1], dims[1:]):
W = 0.01 * np.random.randn(Din,Dout) # weights initilize with 0.01-std
x = np.tanh(x.dot(W))
hs.append(x)-
위 코드는 간단하게 RandomNormal initalization을 취한 6-layer net의 forward pass에서 각 hidden layer의 activate(tanh) output을 저장하여주는 코드이다.
-
각 layer의 output을 가진 hs를 visualization 해보면 다음과 같다.
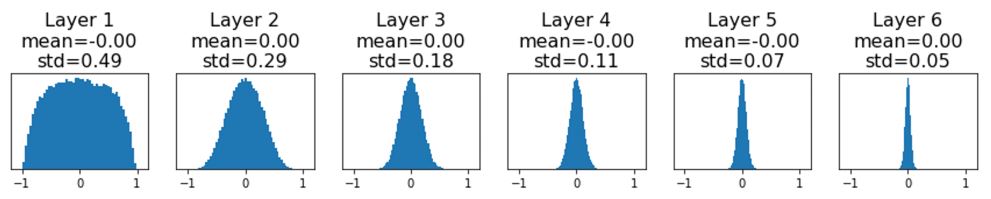
-
위 그림에서 보다시피 깊은 layer로 갈 수록 layer의 ouput의 std가 0에 가까워지는 것을 볼 수 있다.
-
이때 깊은 layer일 수록 std가 0에 가까워 지면서 0에 가까운 값을 가진 input 들로 인해 의 gradient도 0에 가까워 질 것이기에 update가 작아지며 학습이 매우 느리게 진행 될 것이다. -> backprop에서의 multiplication node pattern을 생각해보면 쉽다.
-
이번에는 weights의 std를 0.01이 아닌 좀 더 큰 값인 0.05로 초기화 해보자.
dims = [4096] * 7 # hidden unit size = 4096
hs = []
x = np.random.randn(16, dims[0]) # input vector dim(size) = 16
for Din, Dout in zip(dims[:-1], dims[1:]):
W = 0.05 * np.random.randn(Din,Dout) # weights initilize with 0.05-std
x = np.tanh(x.dot(W))
hs.append(x)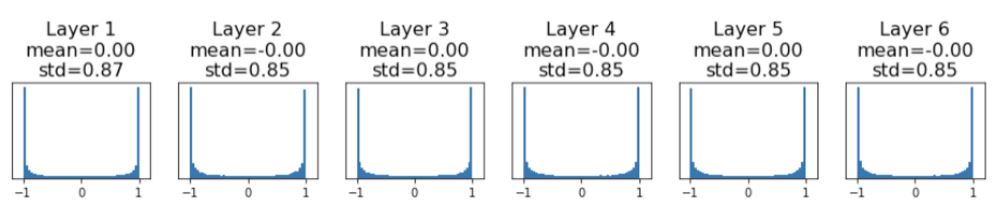
-
위 그림에서 보다시피 이번에는 output값들이 -1 과 1 에 몰려있다는 것을 볼 수있고 이는 강의 초반 tanh activation function에서 보았듯이 saturating regimes에 있다는 것을 뜻한다.
-
결국 대부분의 weight는 saturating되어 gradient가 0에 수렴 할 것이고 이는 weight update가 일어나지 않게 된다는 것을 의미한다.
-
우리는 크지도, 작지도않은 적절한 weight std를 찾아내야 한다.
* 밑에서 설명하겠지만 위 두 과정을 자세히 살펴보면 한 layer의 variance of output은 해당 layer의 input dimension과도 연관이 있다.
-> 1. wx dot product과정중 에서 한번 input dimension에 따른 scaling, 2. activation fcuntion (tanh일 경우) 에서 한번 down-scaling이 있다.
Xavier initialization
- 이 전처럼 std를 hyperparameter로 쓰는 것 이 아닌 input dimesion의 std를 나누어주어 scaling시켜주어 initialize 해준다. 코드로 살펴보자.
dims = [4096] * 7 # hidden unit size = 4096
hs = []
x = np.random.randn(16, dims[0]) # input vector dim(size) = 16
for Din, Dout in zip(dims[:-1], dims[1:]):
W = np.random.randn(Din,Dout) / np.sqrt(Din)
x = np.tanh(x.dot(W))
hs.append(x)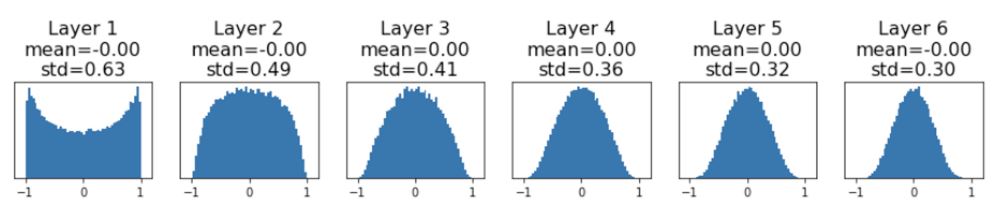
-
Xavier initialization 의 핵심은 해당 layer의 variance of input에 variance of ouput을 맞추어 weight initialize하겠다는 것으로
-
Dot product neuron인 에서 x와 w를 dot product시켜 input의 dimension만큼 더해지기에(sum)
가 input dimension크기에 비례해 scaling되는 만큼 weight의 std를 1/으로 scaling 시켜주어 input과 output의 variance를 맞춰주겠다는 것이다.
* 한마디로 input dimension의 사이즈가 커질 수록 초기화 값의 분산을 작게 만들자는 것이다.
- 수식으로 표현하면 다음과 같다.
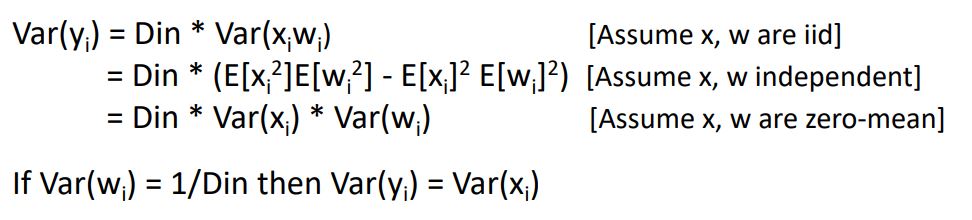
- 하지만 이런 xavier initialization도 ReLU에서는 문제가 발생한다.
dims = [4096] * 7 # hidden unit size = 4096
hs = []
x = np.random.randn(16, dims[0]) # input vector dim(size) = 16
for Din, Dout in zip(dims[:-1], dims[1:]):
W = np.random.randn(Din,Dout) / np.sqrt(Din)
x = np.Maximum(0, x.dot(W)) # using ReLU
hs.append(x)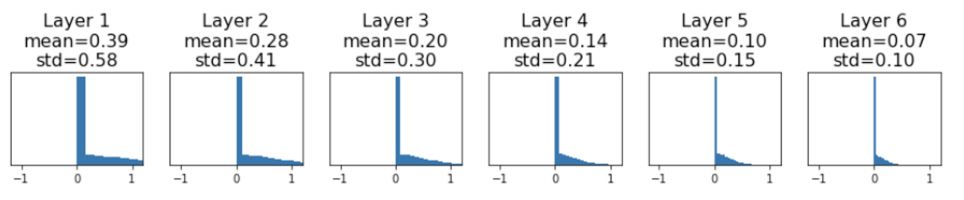
-
위 histogram에서 보다시피 ReLU는 data 분포의 절반(negative value)을 날려버리고 점점 deep layer로 갈 수록 다시 0으로 수렴한다는 것을 볼 수 있다. 이는 또 update가 잘 되지 않는 다는 것을 의미한다.
* 사실 Xavier 논문에서는 해당 layer에서 input과 output의 dimension을 모두 고려해주어 아래와 같은 형태로 normal distribution initialization해준다.
W = np.random.randn(Din,Dout) / np.sqrt((Din + Dout) / 2) # weights initilize with 0.05-std* 뇌피셜 이지만 Xavier initialization이 현재 많이 사용되고 일반적인 의미에서의 용어로 사용되어 (마치 SGD처럼) 강의에선 일반적인 의미를 설명하는 듯 하다. 해당 논문은 아래 링크에 들어가서 보세요~
Understanding the difficulty of training deep feedforward neural networks , Xavier et al, 2010
He initialization
- Xavier initialization의 ReLU에서의 문제를 해결하고자 He initialization 에서는 아래 코드처럼 input dim에 2를 나누어주어 std를 계산하는 형태로 결국 Xavier initialization에서 scaling 시켜준 형태이다.
W = np.random.randn(Din,Dout) / np.sqrt(Din / 2) 해당 논문은 아래 링크에서 확인 하세요~
delving deep into rectifier, he et al, 2010
- 이 외에도 Xavier initialization 이후의 여러 research paper들이 있다.

10_2 에서 계속 됩니다~
