[EECS 498-007 / 598-005] 10_2 Training Neural Networks (Regularization)

Intro
- 우리는 이전까지 보았던 activation function을 설정하고, initializaion을 set-up한 후 training 시켜도 model이 optimizing을 잘 하지 못하고 valid set과 train set의 error차이가 벌어지며 overfit되는 현상을 볼 수 있다.

-
이러한 high variance를 가져 overfit되는 현상을 방지하고자 regularization을 활용하는 것이 하나의 방법이 될 수 있다.
-
우리가 이전에 보았던 L2, L1같은 regularization은 아래 그림과 같이 loss function에 regularization term을 추가하여 weights에 penelty를 주는 방식이 있었다.

- 이와 다른 scheme을 가진 또다른 regularization들을 이번 강의에서 다뤄보려 한다.
Dropout
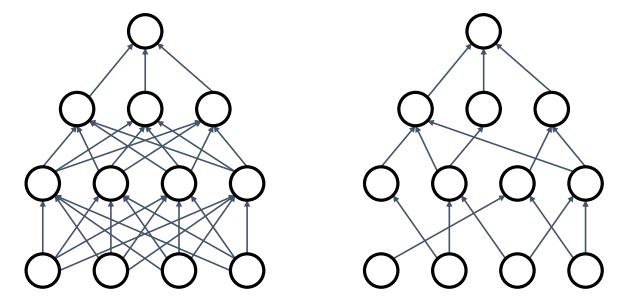
- Dropout은 Neural network의 forward pass에서 각 layer의 neuron(hidden unit)을 ramdom하게 0로 만들어 해당 노드를 삭제(drop)하는 것이 핵심 idea이다.
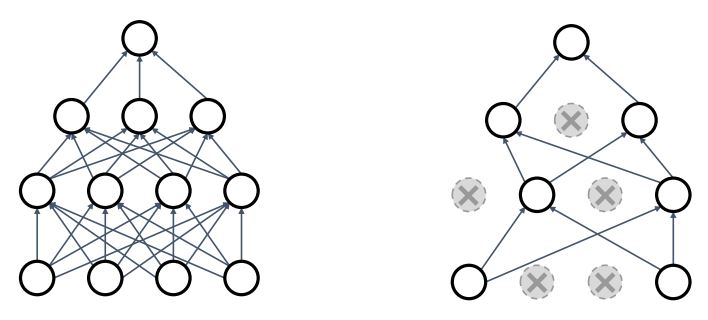
-
각 layer마다 hyperparameter를 통해 독립적인 neuron에 probability of dropping을 적용시키는 것 이다.
-
코드를 통해 자세히 살펴보자.
p = 0.5 # probability of keeping a unit active.
def train_step(X):
''' X contains the data '''
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first(layer) dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second(layer) dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass : compute gradients...
# perform parameter update...
-
위 코드는 3-layer network의 (forward pass중) 각 layer마다 binary mask (p를 0.5로 설정해줬으니 binary) 를 취해주어 drop시키는 형태의 구현이다.
-
그렇다면 왜 이런짓(dropout)을 하는 것일까?
-
첫번째 해석은 dropout이 feature의 co-adaptation을 예방한다는 것이다.
-> 풀어 말하면 randomness를 부여해 모든 feature에 대한 weights를 분산시키는 역할을 하여 model이 많은 feature들 중 특정 feature에 의존하게 되는 현상을 줄이는 것이다*. -
또다른 해석은 "Dropout is training a large ensemble of models" 이다.
-> training시 각 sample마다 다른 mask가 적용되어 하나의 모델이 되어 결국 full-training에선 각 model들의 ensemble이 된다는 것 이다.
-
하지만 dropout은 test-time operation에서 사실상 random output을 만들기에 문제가 된다. 이는 매번 다른 예측을 가져올 수 있다는 것을 뜻하며 우리는 output이 deterministic이기를 원한다.
-
그렇기에 우리는 test-time에서 "average out" the randomness를 해주어야 한다.

-
그렇다면 위 그림과같은 식으로 표현될 수 있는 network가 deterministic하게 만들어주기 위해선 test-time에서 average out을 어떻게 구해줄 것인가?
-
우리는 이러한 output을 z에대한 expectation으로 볼 수 있으며 다음과 같은 식으로 나타낼 수 있다.
-
하지만 실제 구현상에서 이러한 integral 계산은 구현하기 힘들다.
-
이러한 integral의 approximation를 구하기 위해 다음 그림과같은 single neuron에서 생각해보자.

-
위와같이 각 w1, w2가 대응되는 x, y 두개의 input을 받아 single scalar output a를 내보내는 single neuron이 있다.
-
이때 neuron은 test-time의 forward-pass에서 input (x, y)과 weight (w1, w2)을 각각 dot product 실행할 것이며 dropout을 적용할 경우 동일한 확률을 갖는 4개의 다른 mask를 가질 확률을 모두 계산하여 다음과 같이 expectation을 계산할 수 있다.
At test time :
During training :
-
이는 dot product의 single scalar output에 dropdout probability (여기선 0.5)를 곱해준 형태가 된다.
-
이러한 test-time의 forward-pass에서의 output expectation을 코드로 구현하면 다음과 같다.
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p
out = np.dot(W3, H2) + b3- 이러한 test-time에서의 구현은 아래 그림의 코드에서 직관적으로 볼 수 있다시피 training시 dropout을 거친 neuron의 output 기대값과 test-time시 neuron의 output 기대값의 scale이 달라지게되는 문제를 test-time에서 기댓값을 scaling시켜주어 해결 할 수 있게 되는 것을 볼 수 있다.

- 하지만 test-time은 predict를 위한 것이니 우리는 위와같이 결과에 ramdomness가 추가되는 것을 원치 않을 수 있다.

-
위 그림의 코드처럼 test-time은 원래 test와 같이 그대로 유지하고 training에서의 output expectation scale을 맞추고자 mask variable에 dropdout probability(p = 0.5) 를 나누어주어 Inverted scaling시켜주는 형태로 구현한다. 이러한 형태를 "Inverted dropout" 이라고 한다.
* 코드에선 mask variable에 scailing을 시켜주었지만 drop된 후 dot product하기 전 H값들 (즉 neuron의 input이 되는 drop된 )에 p를 나누어주어 scaling시켜주어도 상관 없다. -
그렇다면 이러한 dropout이 CNN architectures에서는 어떻게 사용될까??
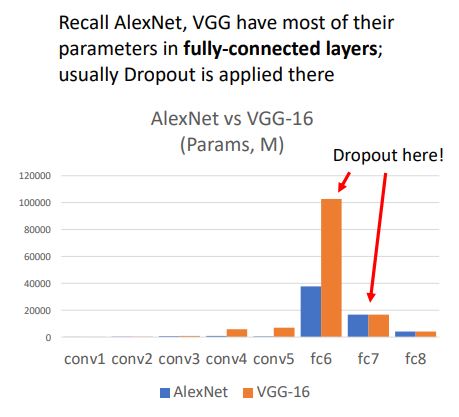
-
위 그림처럼 AlexNet과 VGG 에서는 많은 parameter들이 사용되는 fc layer에서 dropout을 사용한다.
* 보통 regularization을 사용하는 이유는 overfitting을 방지하기 위해서인데 어떤 layer에 hidden unit size가 클 수록 (parameter수가 많아지니) overfitting될 가능성이 높기 때문에 dropout을 사용하며, size가 작은 layer에서는 dropout을 사용하지 않거나 hyperparameter p 를 1로두어 drop되는 unit이 없게한다.
-
하지만 비교적 최근 architecture인 GoogLeNet, ResNet에선 fc layer대신 global polling layer를 사용하기에 dropout을 사용하지 않는다고 한다.
-
이러한 dropout에서 나타나는 것 처럼 neural network의 다른 regularization에서도 찾아볼 수있는 흔한 패턴이 있다.
Regularization Pattern
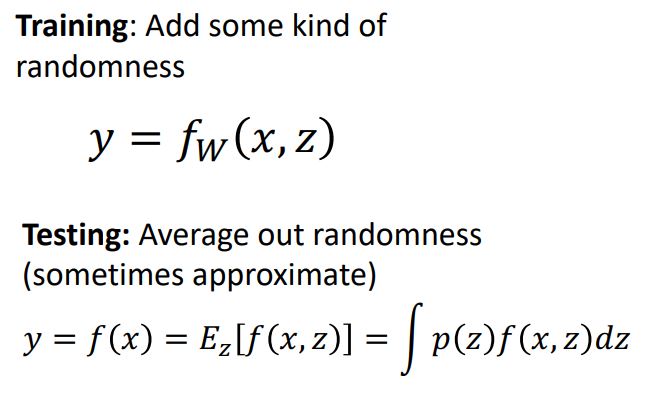
-
위 그림처럼 기본적으로 training시엔 시스템에 randomness를 추가시키고 test시엔 deterministic을 계산하기 위해 randomness를 average out시켜주는 형태가 regularization에서 보이는 흔한 패턴이다.
-
Dropout에서는 ramdom mask를 통해 randomness를 추가시켰지만 다른 regularization들 에서는 다른 ramdomness 형태를 사용하는 것을 볼 수 있다.
-
Batch Normalization을 예로 들어보면 BN은 training-time에서 한 mini-batch속의 sample들은 std와 mean을 취해 output을 구하기에 각 sample들은 서로 dependent한 형태이고 mini-batch는 shuffle됨에 따라 매 iteration마다 randomness가 추가되는 형태이다.
-
또한 BN의 test-time에서는 exponentially weighted average vector를 사용하여 이러한 randomness를 average out시켜주는 형태를 갖는다.
-
이러한 이유 때문에 ResNet과 같은 최근의 architecture에서는 dropout 대신에 L2 weight decay를 사용하며 Batch Normalization을 통해 randomness를 부여하여 대체한다고 한다.
Data Augmentation
- 우리는 training-time에서 randomness를 추가시킬 수 있는 또다른 regularization type으로 Augmentation을 볼 수 있다.
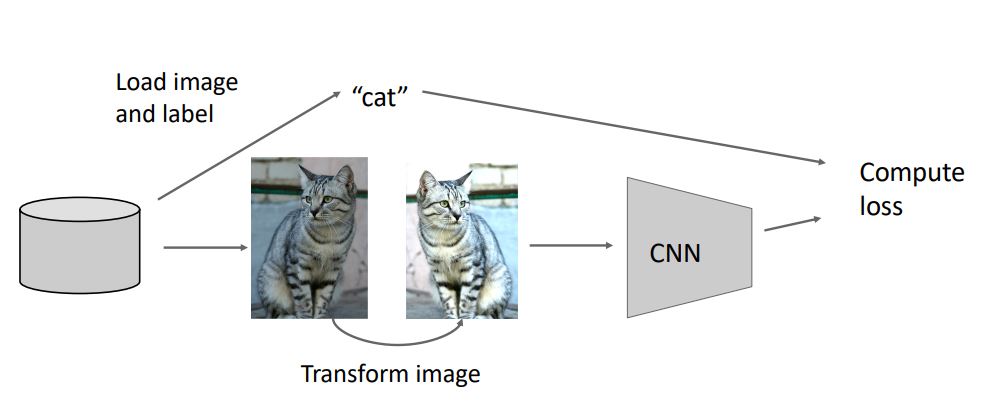
- Augmentation은 아래 그림처럼 training시 image(sample)를 random하게 crop, scale시켜주고 test-time에선 crop set을 고정 값으로 average시키는 형태로 진행된다.
.JPG)
* ResNet에서 testing시에 어떻게 average시킨다는 것인지는 정확히 이해하지 못했다 ㅜㅜ
- 좀더 복잡한 Augmentation인 Color Jitter 방식도 있는데 이는 아래의 그림과 같다.

- 우리는 아래 그림에서 보다시피 여러가지 image transform을 통해 Augmentation을 진행 할 수 있는데, 이는 각 data, 각 problem에따라 다른 transform이 필요할 것이며 명확한 답이 없다고한다.
Another regularizations
DropConnect
-
DropConnect는 dropout과 비슷하지만 zeroing random activations를 취하는 것이 아닌 weight에 random으로 zero를 취해주는 방식이다.
Wan et al, “Regularization of Neural Networks using DropConnect”, ICML 2013
Factional Pooling

-
Factional Pooling은 network의 각 pooling layer에서 receptive field의 size에 randomize를 적용하는 방식으로 training시에 pooling layer에서 kernel size를 2x2 or 1x1 등으로 random하게 취해주고 test시 prediction을 averaging시켜 적용시키는 방식이다.
Graham, “Fractional Max Pooling”, arXiv 2014
Stochastic Depth
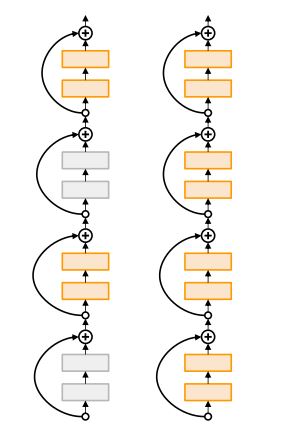
-
Stochastic Depth은 ResNet에서 사용되는 regularization으로 residual block을 skip하는 형태로 randomness가 부여된다.
Huang et al, “Deep Networks with Stochastic Depth”, ECCV 2016
Cutout

-
Cutout은 image에 일정 region을 zero로 만들어 randomness를 부여하는 방식이다. test시엔 whole image를 사용한다고 한다.
DeVries and Taylor, “Improved Regularization of Convolutional Neural Networks with Cutout”, arXiv 2017
Mixup

-
Mixup은 training image를 label별 random한 weight 비율로 blend시키는 방식이다. 이때 sample은 beta distribution을 통해 blend weights가 확률적으로 정해진다고 한다.
Zhang et al, “mixup: Beyond Empirical Risk Minimization”, ICLR 2018
Outro...
-
이번 강의에선 Dropout과 더불어 여러 종류의 regularization을 살펴보았다.
-
각각 regularization의 scheme은 다를 수 있지만 대부분 regularization은 training시에 randomness를 부여하고 test시에 average out시키는형태의 패턴을 갖고있다.
-
결국 regularization은 model이 high variance를 가져 overfitting되는 현상을 완화시키고자 각 regularization마다 (intput값이던, pooling layer의 kernel이건 등등의) 특정 randomness를 부여하여 training시킨다는 것이 핵심이다.
