[EECS 498-007 / 598-005] 7_2. Batch Normalization

Intro
- 이번 포스팅에서는 EECS 7강과 더불어 Batch Normalizainput normalization 문제에 해당하지만tion 논문, Andrew ag교수의 강의를 참고하여 작성하였습니다. 해당 링크는 아래~.
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Improving Deep Neural Networks
1. zero-mean & unit variance
-
Batch normalization을 알아보기 전에 0-mean / 1-variance의 개념부터 짚고 넘어가보자.
-
feature들 간의 scale 폭이 (범위가) 차이가 날 경우 학습시 weights간 변화량이 차이가 나 loss의 contour polt을 보면 다음과같은 zig-zag patten이 발생하고 이는 학습률을 낮게하는 원인이 된다.
-
이러한 문제를 해결하기 위해 data를 normalize시켜야 한다. 여러 normalization 방법 중 Standardization 에 대해 살펴보려한다.
-
간단한 data분포도를 통해 normalize 과정을 살펴보자.

- subtract mean (zero-mean)
- 위 식은 한 data sample의 평균을 element-wise로 빼주어 zero-mean을 만들어 주는 것으로 다음과같은 분포로 변경된다.
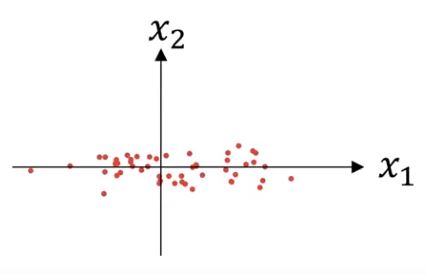
- Normalize variance (unit-variance)
- 위 식은 이전 식을 거쳐 0-mean 을 가진 sample을 element-wise square 취해주어 더한후 m으로 나누어 분산을 구한후 그것을 다사 sample x에 나눠주어 1-variance를 갖게해주는 식이며 다음과 같은 분포를 보여주게 된다.

- 최종 식은 다음과 같다
- 본격적으로 이 와 variance을 뜻하는 를 fully-connected model에서 어떻게 적용시켜 normalization 하는지 알아보자.
2. Normalization with fully-connected model
- 우리는 input만을 scaling 해주어 normailzation 하는 것이 아니라 학습을 빠르게 하기 위해 neural network 전역에있는 layer들에 들어오는 input들에 대해서도 normalize 해주어야한다.
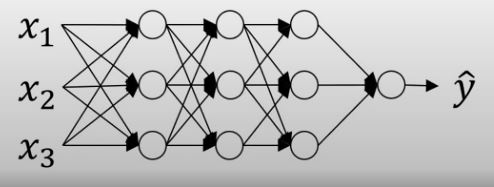
- 위와같은 fully-connected model의 한 layer에서 예를 들어 본다면 학습시 3-hidden layer의 를 빠르게 하기 위해 이 전 layer의 activation function을 거치기 전의 (와 의 linear combination형태)를 normalize 해야한다.
* activation function을 거친 를 normalize 시켜야하는지 를 normalize 시켜야 하는지는 논쟁이 있지만 일반적으론 를 normalize 시킨다고 한다.
- 이전에 x에 대해 정의했던 식을 z에 대한 식으로 바꾸어보자
* 이때 epsilon은 zero-division 문제를 방지하기 위해 붙여졌다.
- 이러한 은 를 zero-mean, unit-variance로 normalization 해주었지만 모든 hidden unit의 input들이 zero-mean, 1-standard deviation 을 갖는것은 좋지 않고 다양한 분포를 가지게 해야 한다.

* 예를 들면 hidden layer 마지막 연산에서 activation funtion을 거져야 하는데 위 그림처럼 sigmoid, tanh function같은 경우 data가 0-mean, 1-variance를 갖을때 함수의 linear한 부분만 활용되어 의미가 퇴색되기 때문이다.
-
위 수식의 는 learnable parameter로서 0-mean, 1-variance으로 scaling시킨 data를 새로운 평균과 분산으로 조정 할 수 있게된다.
-
이때 이면 identity function이 되어 가 로 돌아게가 되는 형태이다.
-
이렇게 를 잘 설정하면* hidden unit간 서로다른 평균, 분포를 갖게 만들 수 있게된다.
* 사실 learnable parameter라 학습시 update할 수 있다.
3. Batch Normalization with fully-connected model
- 하나의 mini-batch 에 대한 normalization 과정을 한 sequence로 나타내 보면 다음과 같다.
- mini-batch 를 를 이용하여 linear conbination형태인 로 만든다
- 를 를 이용하여 로 BN (Batch normalization)시킨다.
- 를 activation function취해주어 만든다.
- 의 수식으로 다음 layer의 input을 계산해준다.
- 이러한 과정을 모든 layer에 반복하여 학습한후 다음 batch로 넘어가 동일 과정을 반복한다.
* 로의 BN 과정에서 의 평균을 계산한뒤 빼주기 때문에 상수인 은 평균을 빼주는 과정에서 사라지기에 영향을 미치지 못하므로 b인 bias term을 무시하여도 되고 이 bias term을 대신하게 된다.
4. Advantages of Batch Normalization
1. Helps reduce “internal covariate shift”
-
BN을 시키지 않은 neural network로 보았을때 포스팅 맨 처음에 언급한 weights간 변화량이 차이때문에 zig-zag patten이 발생한다.
-
internal covariate shift란 layer를 통과할 때 마다 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상
(covariate shift)이 발생하면서 입력의 분포가 바뀌는 현상을 말한다. -
이때 Batch Normarlization은 covariate shift문제에서 shift되는 variance의 양? 크기? 변화율? 을 줄여주게 된다.
-
이러한 covariance shift 문제를 간단한 classifier model의 예시로 보이면 다음 그림과 같다.

-
위 그림의 검은 고양이set과 다른고양이set 같이 label은 같지만 두 data간 데이터 분포가 다른경우 covariance shift문제의 예시로 볼 수 있다.
* 물론 이 예시의 경우 엄밀히 보면 batch normalization(internal covariate shift)이 아닌 input normalization(covariate shift) 문제에 해당하지만 어짜피 BN이 포함하는 내용이니 가볍게 보시면 될것같습니다.
2. Networks become more robust to weights initialization
- Batch Normailzation의 를 통해 적절한 mean & variance를 조절하여 Gradient Vanishing / Exploding 문제를 해결하며 학습하는 과정자체를 전체적으로 안정화시켜 깊은 layer들이 보다 robust*하게 만들어 준다.
* machine learning (혹은 통계학)에서 robust 라는 말은 outlier와 error로 부터 영향을 적게 받는 것을 말한다.
3. Acts as regularization during training.
-
Batch normalization 과정에서 mean / variance를 scaling 시키는 과정에서 noise 가 추가되게 된다. 이러한 과정은 dropout과 비슷한 영향을 끼쳐 regularization의 효과를 얻게 된다
-
하지만 regularization 과 batch normalization을 같이 사용하는 것이 좋다고 한다.
5. Disadvantages of Batch Normalization
1. Not well-understood theoretically (yet)
- batch norm이 covarient shift를 해결하는 건 알겠지만 정확히 왜 optimization에 도움이되어 학습이 빨라지는지 이론적으로 증명하지는 못하였다고한다 아직.
2. Behaves differently during training and testing
-
랑 는 매 step에서 batch size만큼의 mean and variance를 구하기 때문에 한번에 한 sample만 처리하는 test-time에서는 사용하지 못한다.
-
또한 지금까지 봐왔던 neural network의 모든 operator들은 batch의 모든 element들을 독립적으로 처리해왔다.
-
또한 multiclass classifier경우에 다른 class를 가진 sample들이 같은 batch에 있을때 different classification scores 를 갖지 못하게 한다고 한다.
-
이러한 training 과 testing에서의 차이의 문제를 해결하고자 testing (or inference)에서 exponentially weighted average vector 를 사용하여 매 layer에서 각 sample에 독립적으로 적용시켜 처리한다.
-
exponentially weighted average는 추후에 포스팅 하겠지만 간략히 설명하면 데이터를 시간의 흐름에맞춰 받아들이며 평균을 계산할 때 오래된 데이터와 최근 데이터의 영향이 비슷해져 원하는 추세를 나타낼 수 없어 시간이 흐름에 따라 지수적으로 감쇠하도록 하는 것 이다.
6. Back to EECS...
- 다시 강의로 돌아와 CNN 관점에서의 Batch Normalization을 살펴보자.

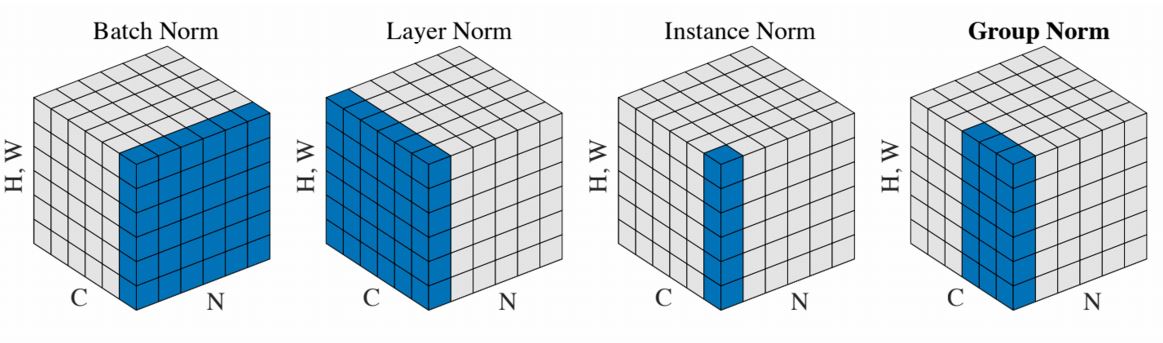
- 그림에서 보다시피 이전에 보았던 fully-connected networks에선 N x D의 input x 를 batch N에 대해 averaging(scale and shift) 시켜 D-dim vector에 normalize시켰다면 Conv net에선 batch dimension N에대해 averaging 시킬뿐 만아니라 모든 spatial dimension인 H,W에 대해서도 averaging 하여 C-dim vector 에 normalize시켜준다.
* 와 을 통해 averaging 시키는 것이랑 와 그리고 를통해 output을 산출하여 normalize시키는 것은 다르니 혼동하면 안된다.
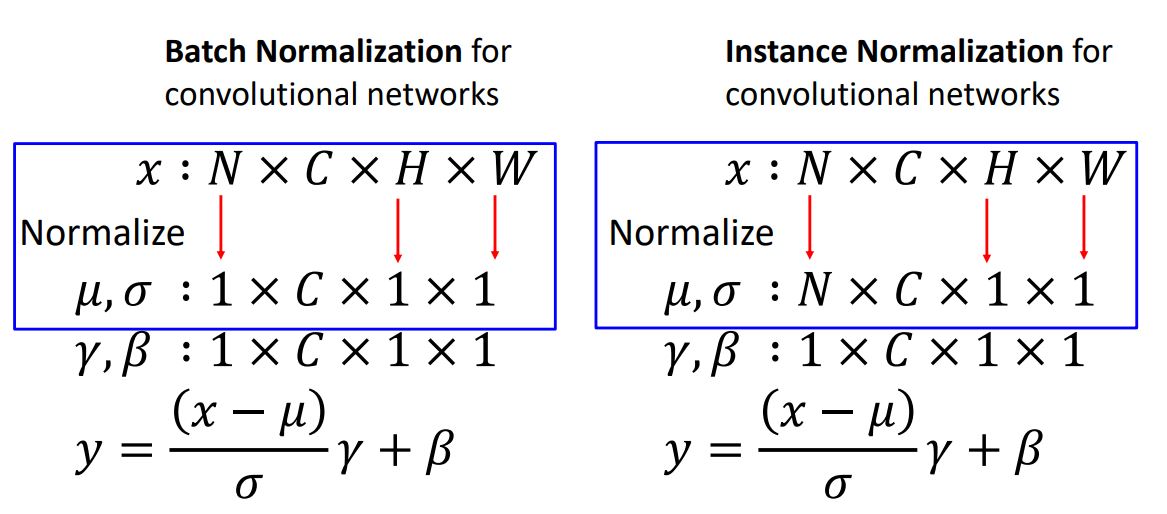
-
직전에 보았듯이 batch전체를 averaging시켜 normalize하는것은 testing 과정에서 허용되지 않는다. 그래서 Conv net에서는 Instance Normalization을 해 준다.
-
Instance Normalization은 batch와 spartial dimension에 averaging해주지 않고 spatial dimension에만 averaging 시켜 normalizing 해 주고. 추가로 exponentially weighted average를 적용시킨다(test시에).
-
이러한 다른 type별 normalization을 그림으로 나타내면 다음과 같다.
뜬금없이 끝~
