[EECS 498-007 / 598-005] 11. Training Neural Networks(Part 2)

Intro
-
이전 강의(part1) 에선 학습 전에 처리하고 설정해줄 data preprocessing, weights initialization, regularization 을 살펴보았다.
-
part2 에선 training 시키면서 어떻게 model의 perfomance를 향상시킬지에 대한 process를 다룰 것 이다.
Learning Rate Shedules
-
우리가 이전에 보았던 모든 optimization기법들은 learning rate를 hyperparameter로 가지고있었다. 이것은 deep learning model에서 가장 중요한 우선순위의 hyperparameter로 다루어지고있다.
-
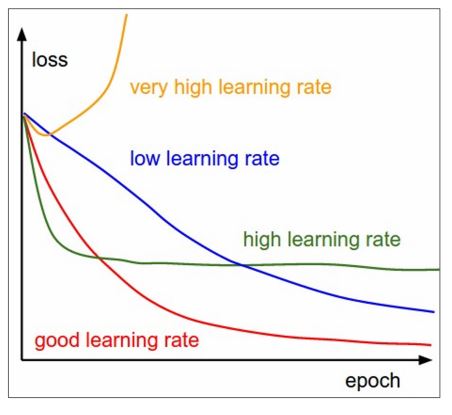
이러한 hyperparameter는 optimization마다 다르게 설정되어야 하며 아래의 그림처럼 몇가지 타입의 learning rate로 나누어 볼 수 있다.
-
그렇다면 우리는 어떻게 최적의 learning rate를 찾아야할까?
: 명확한 답은 없지만 training 초반에는 위 그림에서 green line을 따르는 high learning rate 을 사용하여 빠르게 학습시켜야하고 시간이 지남에 따라 blue line을 보이는 low learning rate 로 learning rate를 decay 시키는 것이 이상적인 방법이다. -
이렇게 training process동안 시간이 지남에 따라 learning rate를 변경시키는것을 learning rate schedule 이라고 한다.
-
흔히 사용되는 몇가지 learning rate schedule이 있는데 하나하나 살펴보자.
Step schedule
- Step learning rate schedule은 residual network에서 흔히 사용되는 learning rate schedule이다.
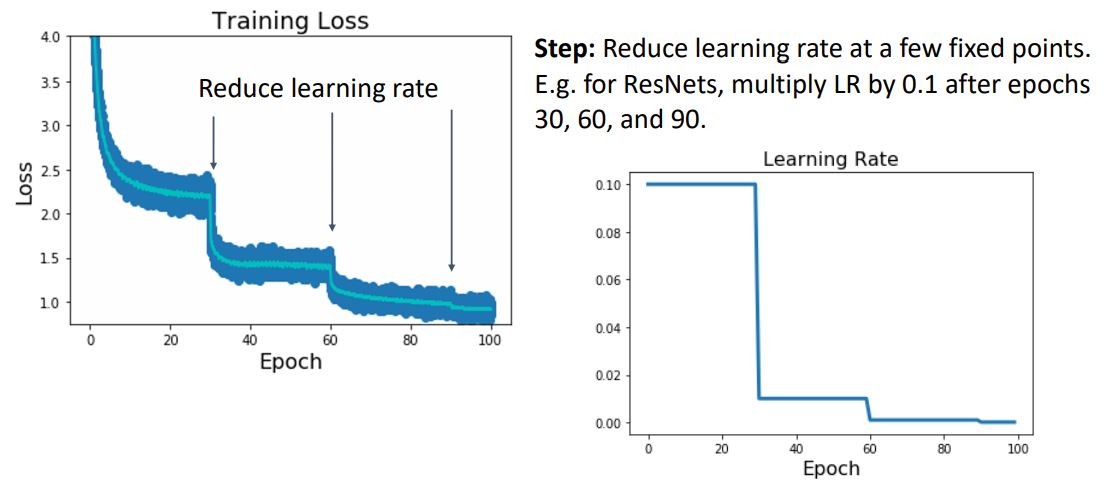
-
위 그림에서 보다시피 일정 범위의 epoch마다 discrete value를 learning rate로 사용하고 점차 decay시켜 계단모양의 learning rate를 보이게 되는 decay schedule이다.
ResNet에서는 0.1을 시작으로 30epoch마다 learning rate를 1/10씩 감쇠시켜 사용한다고 한다.
-
이러한 step learning rate schedule은 step마다 learning rate를 고정시킬 epoch의 범위, step마다 learning rate 를 감쇠시킬 decay rate가 새로운 hyperparameter로 추가되는 문제가 있다.
Cosine schedule
- Cosine learning rate decay schedule은 최근 몇년간 유행하고있는 learning rate schedule이라고 한다.
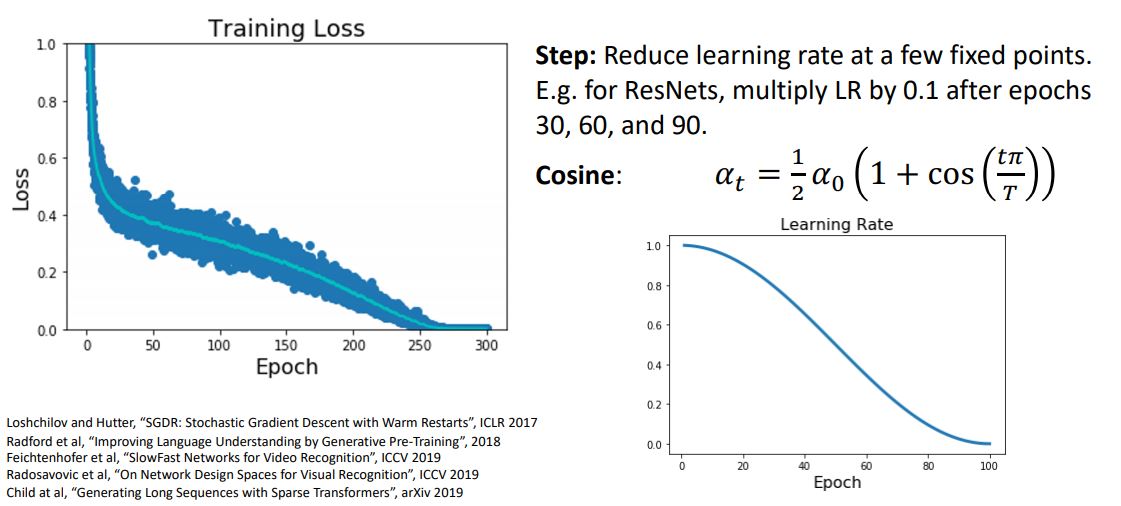
-
직전에 보았던 Step learning rate schedule과는 달리 decay rate나 epoch의 범위를 설정해 줄 필요 없이 위 그림의 공식을 따라 매 epoch마다 learning rate을 decay시키게 된다.
-
위 공식인 Half wave cosine fomula를 따르면 위 그림에서 보다시피 초반에는 high learning rate를 사용하여 학습이 빠르게 진행되고 학습의 끝에서는 learning rate가 0에 가까워지게 감쇠된다.
-
Cosine learning rate decay schedule은 설정해줄 hyperparameter가 딱 두개밖에 없다. 하나는 initial learning rate인 이고 다른 하나는 num of epoch를 결정할 T가 있다
-
이렇게 tuning해주어야 할 hyperparameter가 적기 때문에 최근에 많이 사용된다고한다.
Linear schedule
- 간단하게 사용되는 또다른 learning rate schedule로 linear schedule이 있다.
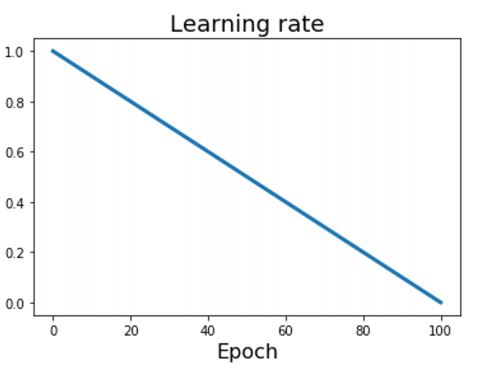
-
위 이미지와 수식에서처럼 linear learning rate schedule은 간단하지만 자주 사용되며 강의에서 justin johnson은 각 model마다, 각 problem마다 사람들이 사용하는 learning rate schedule은 다르며 이런 learning rate schedule들은 어느게 좋은지 비교할 수는 없다고 한다.
-
computer vision분야에서는 직전에 보았던 Cosine learning rate decay schedule을 많이 사용한다고하며 large-scale netural language processing에서는 linear learning rate schedule을 많이 사용한다고 한다.
Inverse Sqrt schedule
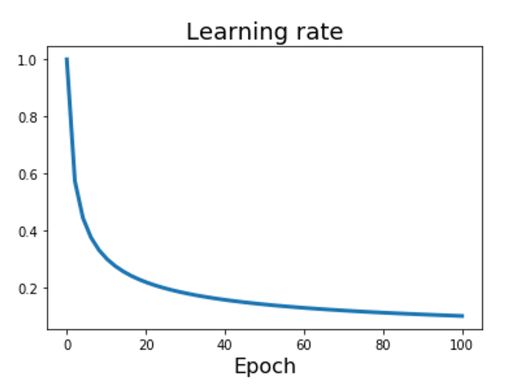
- 또다른 learning rate schedule로 inverse square root learning rate schedule이 있는데 이는 위에서봤던 Cosine schedule, Linear schedule 과 다르게 거의 사용되지 않는다고 한다.
Constant schedule
- 우리가 가장 흔하게 볼 수 있는 learning rate schedule로 Constant schedule이 있다.
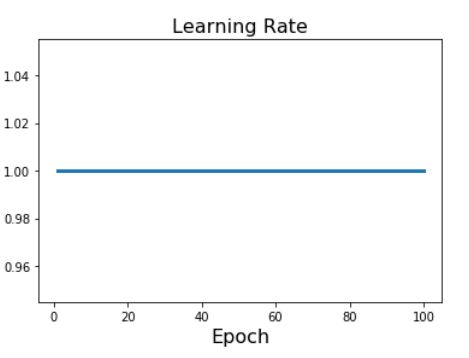
-
Constant learning rate schedule은 가장 흔하게 볼 수 있으며 강의에서 Justin Johnson이 말하길 이 Constant schedule은 다른 복잡한 laerning rate schedule과 비교해 model, problem에 따라 성능이 좋아질 수도 나빠질 수도 있으며, 가능한 빠르게 model을 만들어야 할때는 좋은 선택이 될것이라고 말한다.
-
또한 momentum같은 optimizer를 사용할때는 복잡한 learning rate decay schedule을 사용하는것이 좋지만 Adam or RmsProp를 사용할때는 (Bias correction이 붙었으므로) learning rate decay가 중요하지 않기에 그냥 Constant learning rate를 사용하는것이 좋다고 한다.
Early Stopping
- 우리가 얼만큼의 epoch or iteration으로 model을 훈련시켜야 할 지 모르겠을때 사용할 수 있는 좋은 mechanism으로 Early Stopping이 있다.
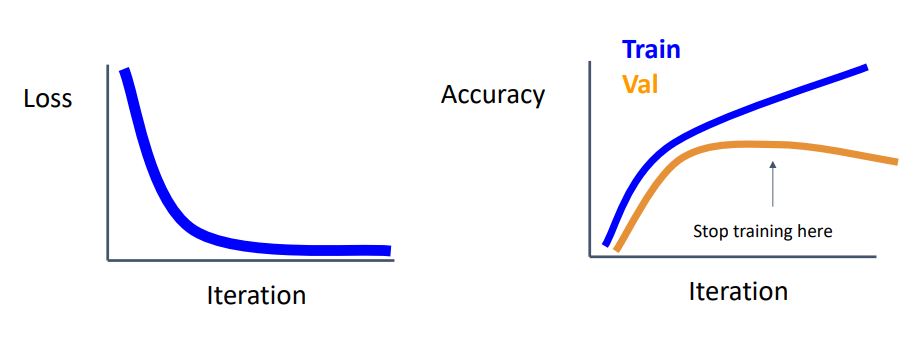
-
우리는 model을 학습시킬 때 왼쪽 그래프와 같이 loss는 이상적으로 감소하지만 오른쪽 그래프처럼 train set의 accuracy (or error)는 계속 증가하는데 val set의 accuracy가 증가하다가 일정 iteration에서부터 accuracy가 감소하면서 둘의 차이가 벌어지는 것을 종종 볼 수 있다.
-
이때 둘의 차이가 벌어지기 전 iteration의 최적점을 찾아 training을 중지시키는 것이 Early Stopping이다.
-
강의에선 Justin Johnson이 Early Stopping을 사용하길 권장하며 자세히 다루지는 않지만 Early Stopping에는 한가지 단점이 있다.
: Early Stopping은 machine learning process중 optimize cost fuction 과정과 regularization을 독립적으로 처리하지 못하게하고 둘을 섞어버려 Orthogonalization하지 못하게 만드며 이는 문제를 더 복잡하게 만든다고 한다.
Choosing Hyperparameters
- 우리는 최적화 알고리즘을 학습하면서 몇몇 설정해야하는 hyperparameter 를 보았다. 이 hyperparameter들을 어떻게 초기화하고 진행 과정에서 적절히 처리해주느냐에 따라 모델의 성능에 지대한 영향을 미친다.
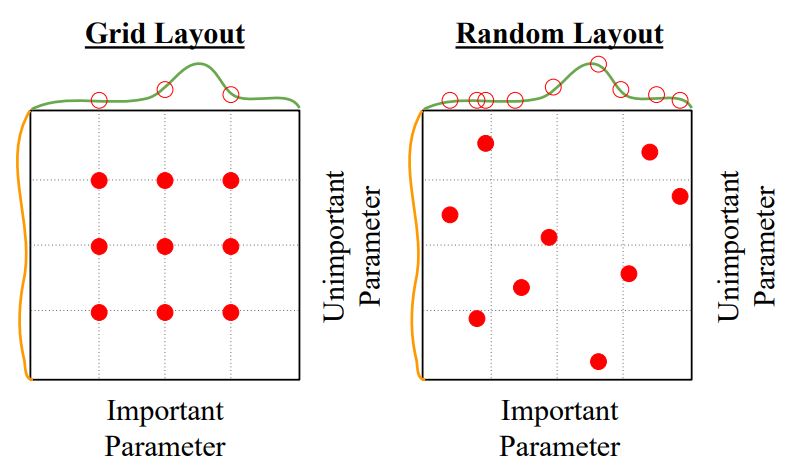
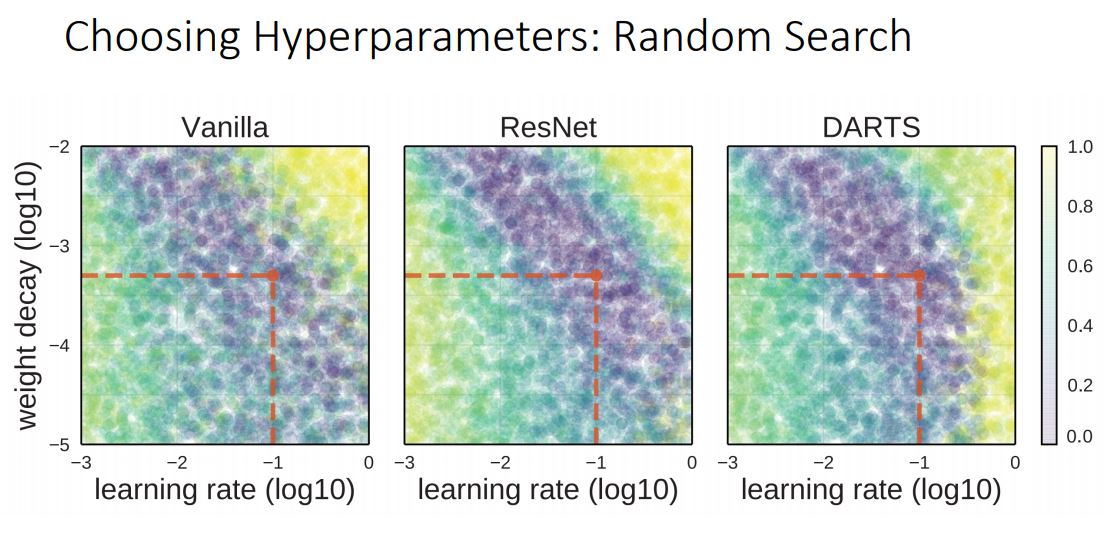
-
위 그림처럼 random search를 통해 많은 hyperparameter중 최적의 값을 찾는일은 많은 GPU resources가 필요한 매우 고비용의 방법이기 때문에 일반적으로 사용하지 못하는 방법이다.
-
그렇기에 우리는 hyperparameter를 어떻게 설정할지 많은 부분에 있어서 경험적인 부분을 적용하게 되는데, 한정된 GPU자원으로 좀더 체계적인 방식을통해 최적의 hyperparameter를 찾아야한다.
-
강의에서 Justin Johnson이 설명하는 hyperparameter tuning process를 살펴보자.
hyperparam tuning process
Stpe1 : Check initial loss.
-
weight decay를 사용하지 않고 sanity check를 통해 random initialization후 첫 iteration에서 계산된 loss와 이론적인 loss의 기대값을 비교한다.
-
cross-entropy loss를 예로 들면 loss의 기대값이 -log(1/C)가 되어야 한다.
Step2 : Overfit a small sample.
-
Regularization을 사용하지 않고 5~10 정도의 미니배치로 크기가 작은 데이터셋에 대해 100%의 train accuracy 가 나오게끔 학습을 시킨다.
-
이때 architecture(num of layer, size of each layer...), learning rate, weight initialization를 매우 작은 set에서 빠르게 interactively하게 조정하여 해당 architecture의 optimization이 올바르게 작동하는지 살펴보는 것이 목적이다.
-
작은 set에서 조정하는 이유는 이때 overfit되지 않는다면 실제 training set에서 fitting되지 않을 것이라는게 포인트이며 overfit되지 않는다면 optimization process에서 문제가 있다는 것을 뜻한다.
Step3 : Find LR that makes loss go down.
-
Step3에선 이전 스텝에서 찾은 architecture에 작은 weight decay를 사용해 모든 training data 에 대해 training 시켜 100정도의 iteration안에 loss가 유의미하게 감소하는지 살펴보며 적절한 learning rate를 찾는다.
-
시도하기에 좋은 learning rate는 1e-1, 1e-2, 1e-3, 1e-4 라고 한다.
Step4 : Coarse hyperparameter grid, train for 1~5 epochs.
-
이전 스텝에서 찾은 learning rate 와 weight decay 를 적용하여 몇개의 모델에 대해 1~5의 epoch 정도를 학습시킨다.
-
이는 training set을 넘어 valid set을 통해 모델의 일반화된 성능을 어느정도 파악할 수 있게 만들어 준다.
-
시도하기에 좋은 weight decay는 1e-4, 1e-5, 0 라고 한다.
Step5 : Refine grid, train longer
- 이전 스텝에서 가장 괜찮은 모델에 대해 조금 더 길게(10~20 epoch)학습을 시켜본다. 이 때 learning rate decay 는 사용하지 않는다.
Step6 : Look at learning curves
- 이전 스텝에서 학습한 model의 learning curves를 살펴본다.
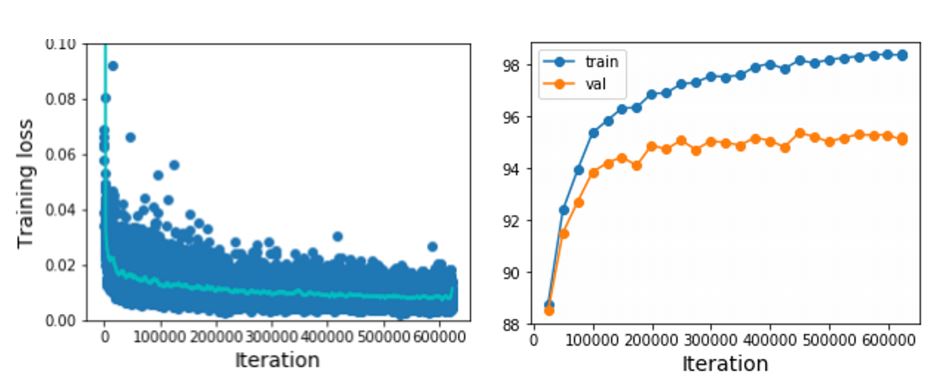
-
이때 왼쪽 그래프와 같이 모든 loss를 scatter plot으로 나타내면 noisy하기에 오른쪽 그래프와 같이 loss에 moving average를 적용하여 그래프를 그려 trend를 살펴봐야 한다.
-
종종 나타날 수 있는 몇개의 learning curve형태를 살펴보자
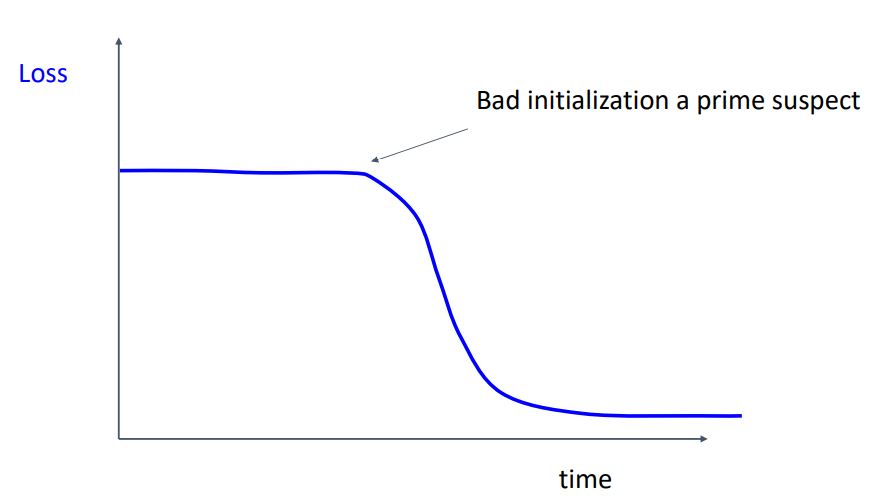
- 위와같이 loss가 처음엔 flat하다가 어느 지점에서 급격하게 감소하는 그래프는 initialization이 잘못된 것을 나타내기에 weight initialization을 다시 시도해봐야 한다.
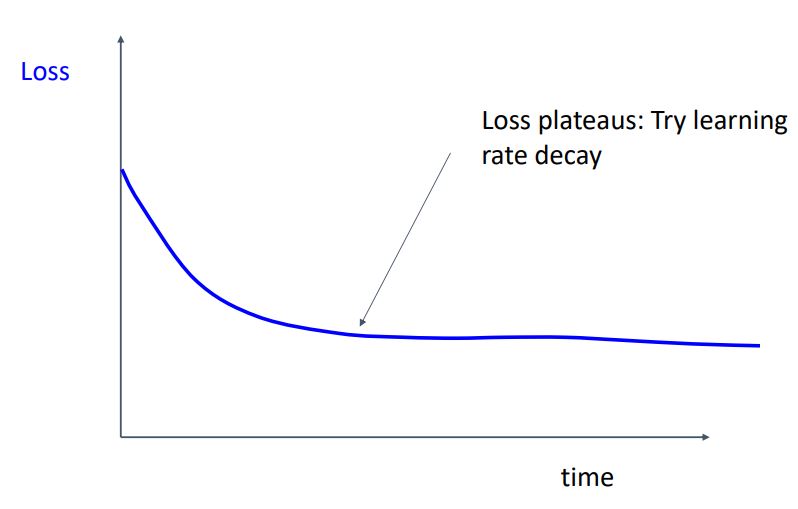
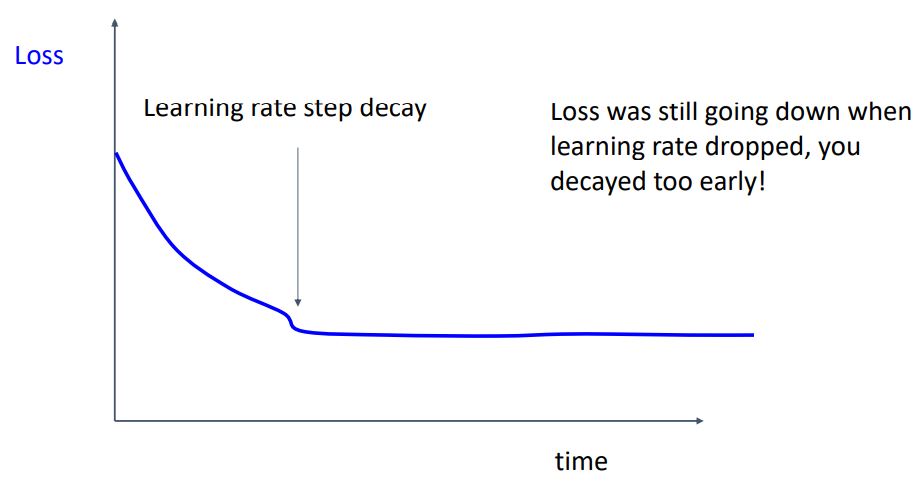
-
위와같이 loss 가 감소하다가 어느 수준에서 평평한 그래프의 형태를 띄게 된다면 learning rate decay에대해 다시 고려해보야야 한다.
-
learning rate decay가 크다면 loss가 감소해야할 지점에서 learning rate를 매우 작게 만들어 학습을 멈춰버리기에 너무 빨리 decay 시키는 것은 좋지 않다.
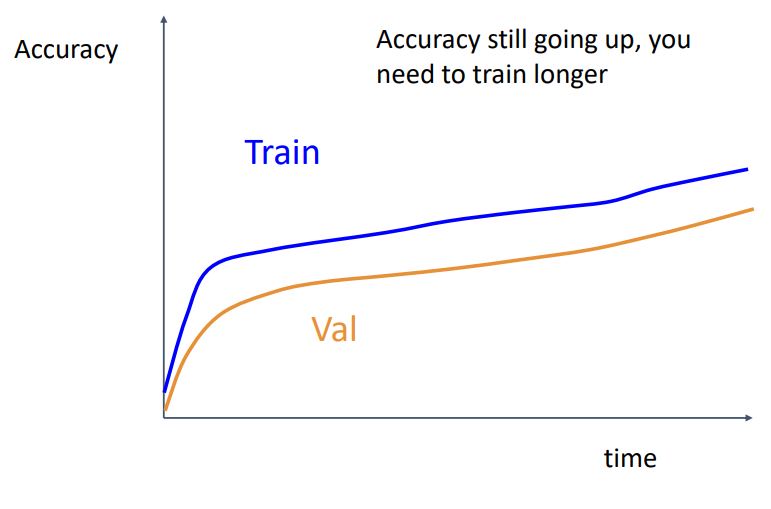
- 위 그림처럼 train accuracy와 valid accuracy가 처음에 exponentially하게 증가하다 일정 gap을두며 linearly하게 천천히 증가한다면 잘 학습되고 있다는 뜻으로 더 길게 학습해야한다.
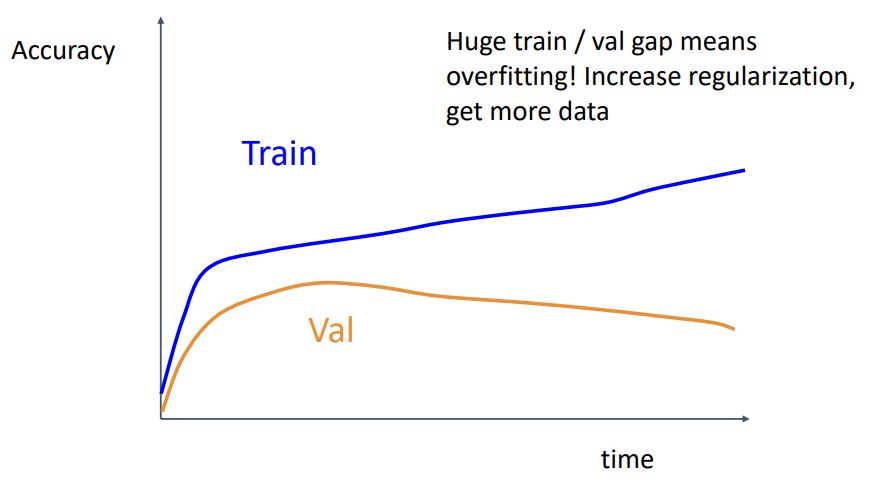
- 위 그림처럼 train, val의 accuracy 차이가 일정 지점에서부터 벌어지고 있다면 이는 overfitting 되고 있다는 뜻이므로 데이터를 더 모으거나 regularization 을 적용하여 모델이 일반적인 성능을 내도록 해야한다.
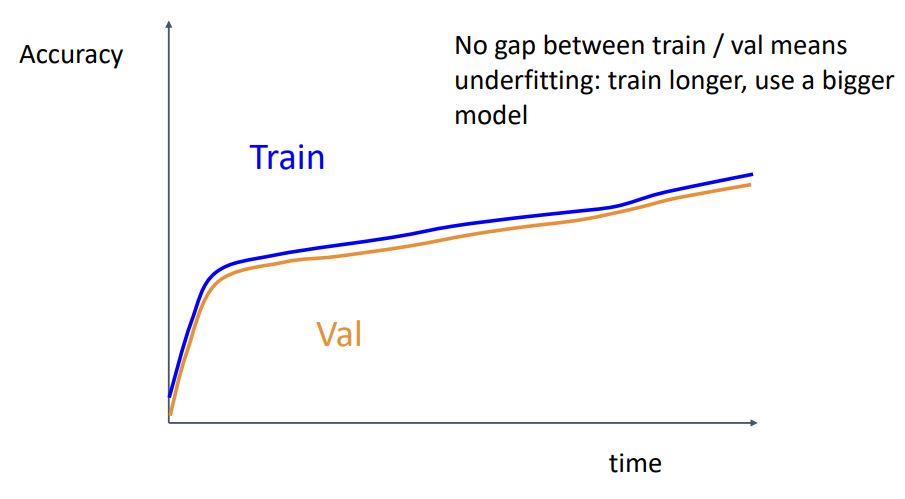
- 위 그림처럼 train, val의 accuracy 차이가 없을 때는 좋아보이지만 이는 underfitting 된 것으로 bigger model 을 사용하거나, regularization을 줄여야 한다.
Step7: GOTO step5.
- 이전 step에서 learning curves를 통해 찾은 문제점을 가지고 step5로 돌아가 적절한 hyperparameter를 설정해준다.
Transfer Learning
- 흔히 CNN과 같은 deep learning model을 학습시킬때 많은 양의 데이터가 필요하다고 생각하고 그렇게 말하지만 transfer learning을 활용하여 해결할 수 있다.
![]()
-
기본 idea는 첫번째로 imagenet 과 같은 큰 data set으로 학습된 CNN model을 가져온다.
-
두번째론 앞선 학습된 model을 가져와 마지막 layer인 fully-connected layer를 삭제하고 학습된 직전의 layer까지를 통해 현재 학습시킬 data의 feature를 추출하여 사용한다
-
이러한 pre-trained된 model을 가져와 transfer learning을 하는 것은 한정된 dataset을 가진 computer vision problem들 에서 성능을 향상시키는데 도움이 된다.
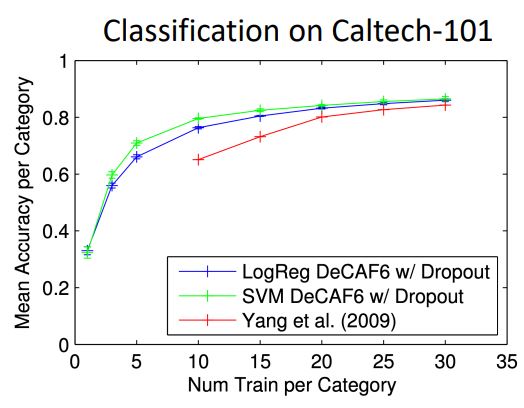
-
위 그림은 "Caltech-101" 이라는 101개의 categories를 가진 적은 양의 dataset의 classification 문제에서 모델별 성능을 나타내는 그래프이다.
-
빨간 그래프는 기존의 Caltech-101 dataset만을 학습시킨 모델의 성능을 나타내고, 파란색과 초록색 그래프는 transfer learning을 활용하여 imagenet을 pre-trained 시킨 AlexNet을 사용하여 feature vector를 뽑아내고, 간단한 logistic regressor와 SVM을 사용하여 train시킨 model이다.
Fine-Tuning
-
우리가 가진 data가 적다면 이전에 보았던 것 처럼 pre-trained CNN model을 feature extractor로 사용하고 output layer만 liniear classifier같은 간단한 algorithm으로 수정하여 사용하였다.
-
하지만 우리가 좀더 큰 dataset을 가지고있다면 Fine-Tuning이라는 과정을 사용하여 transfer learning을 통해 좀더 좋은 성능을 낼 수 있다.

-
Fine-Tuning은 pre-trained entire model을 new dataset에 학습시키는 것으로, 전체 model의 weights들을 backpropagation을 통해 계속 update시켜 성능을 향상시키는 것이다.
-
Fine-Tuning을 사용하면 learning rate는 작게 줘야한다고 한다.
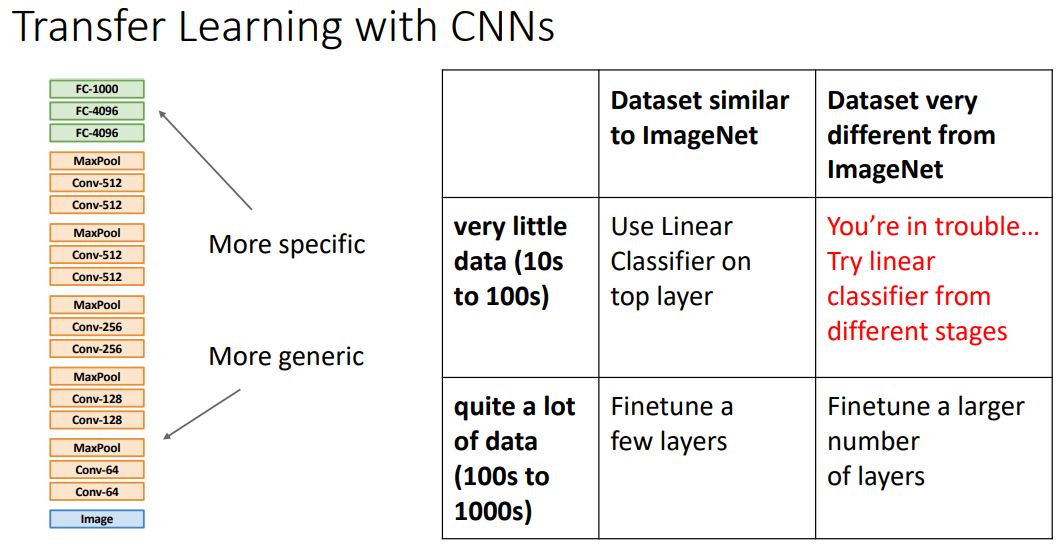
- 위 그림에서의 표는 현재 갖고있는 data set의 크기가 작을때, 클때 그리고 ImageNet과 비슷한 유형의 dataset일때 아닐때의 transfer learning방법을 정리한 것이다. 직관적으로 정리되어있으므로 설명은 하지 아니하겠습니다~.
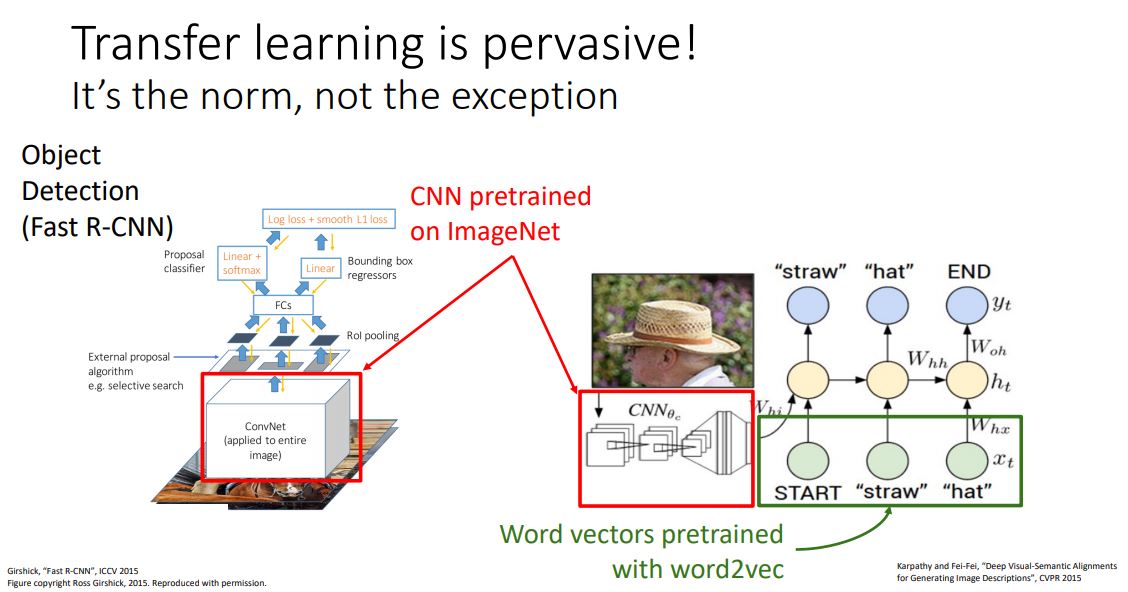
- 위 그림은 Transfer learning이 object detection, image captioning과 같은 main stream computer vision 문제에서 많이 사용된다는 것을 보여주고있다.
Summary
- 없음.
