[EECS 498-007 / 598-005] 12. Recurrent Neural Networks

Intro
- 우리가 여지껏 보았던 deep neaural network에서 다뤄온 문제들은 "feed-forward"라고 불리는 형태였다.
-
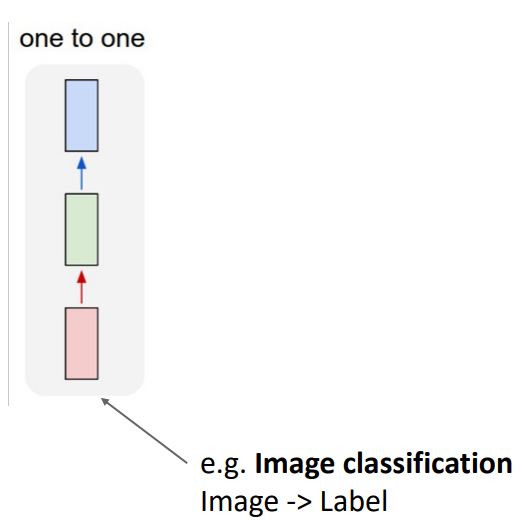
이러한 feed-forward network는 single-input(like single-image)을 받아 여러 형태의 hidden layer들을 거쳐 single-output을 내보내는 형태이고, 이러한 형태의 classical한 예로는 single-image를 input으로 받아 category label을 output으로 내보내는 image classification 이 있다.
-
우리는 deep neural network를 이용하여 feed-forward network형태 말고도 다른 많은 타입의 problem들을 해결하고자 한다.
Recurrent Neural Networks: Process Sequences
-
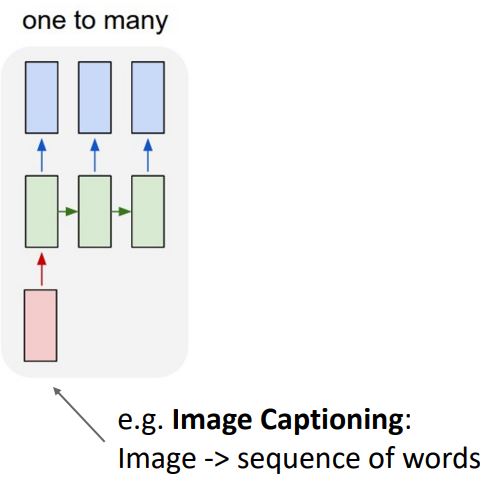
첫번째 예로는 앞에서 본 one-to-one 형태가 아닌 one-to-many형태가 있다.
-
One-to-many는 single-input(image)를 입력으로받아 output을 더이상 lable형태가 아닌 sequence형태로 내보내는 것 이며, 한 예로 single image를 input으로 읽어들여 image 내용을 설명하는 sequence of words를 output으로 내보내는 Image Captioning 이 있다.
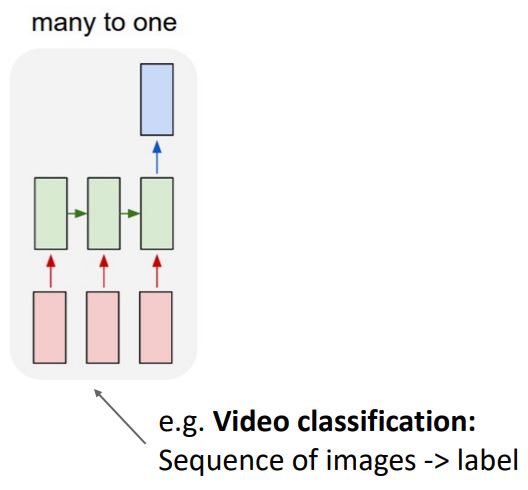
- 또다른 형태로는 many-to-one이 있다. 이는 input이 더이상 single item이 아니라 sequence of video frame과 같은 sequence of items이며 output으로 single label을 출력하며 Video classification 을 한 예로써 들 수 있다.
-
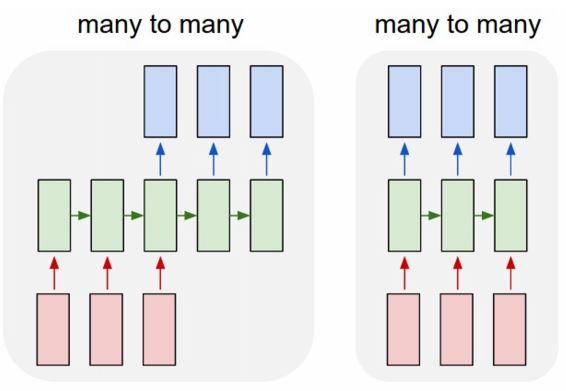
위 그림처럼 input이 sequence이고 output도 sequence인 many-to-many 형태에서는 왼쪽 그림처럼 input sequence와 output sequence의 길이가 다른 경우인 Machine Translation 형태를 볼 수 있으며 이를 sequence-to-sequence problem이라고도 한다.
-
또다른 sequence 2 sequence problem에서는 many-to-one과 다르게 video frame별 classification label을 결정하여 첫 3개의 frame에서는 드리블치는 사람 다음 몇 frame에서는 슛하는 사람 과 같이 sequence of images를 input으로 받아 sequence of labels을 출력으로 보내는 Per-frame video classification 을 한 예로 들 수 있다.
-
우리는 neural network를 one-to-one 형태가 아닌 seq-to-seq 형태로 만들어 사용하여 훨씬 더 일반적이고 다양한 문제들을 다룰 수 있으며 seq-to-seq process의 general tool중 하나인 Recurrent Neural Network 를 이번강의에서 다룬다.
-
Recurrent Neural Network 는 Non-Sequential data에도 유용하게 사용되기도 한다.
Sequential Processing of Non-Sequential Data
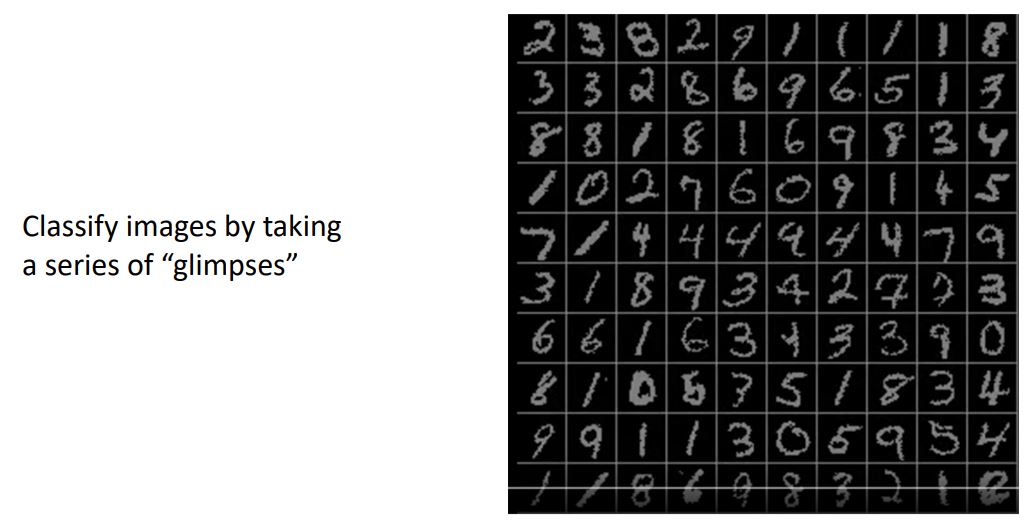

-
위 그림은 Recurrent Neural Network 을 사용해 non-Sequential data를 가지고 sequential processing을 수행하도록 한 예시로 image classification problem에 feed-forward network 대신 위 그림처럼 초록색 박스인 "multiple glimpses"를 취하는 neural network를 사용한다.
-
이러한 형태는 step마다 이미지의 한 부분(glimpses)을 보는 형태인데, 어느 부분을 볼건지는 이전 step에서 수행한 정보를 가지고 판단하여 최종적으로 network가 각 image에 대해 classification decision을 출력하는 형태이다.

-
Non-Sequential data를 가지고 sequential processing을 사용하는 또다른 예로 digits image를 생성하는 neural network가 있다.
-
이전 예시와 다르게 network는 매 step마다 output canvas의 어느 point에 그려야할지 무엇을 그려야할지 판단하게 되며 writing decisions는 이전 예시처럼 시간마다 이전 정보가 통합되어 사용된다.

- 이전 예시와 비슷한 예시로 Integrate with oil paint simulator가 있는데 이 network는 매 time step마다 어떤 타입의 brush stroke를 사용할지 판단하게 된다.
- 위 몇가지 예시를 통해 recurrent neural network가 non-sequential data를 가지고 어떤식으로 사용되는지 살펴보았는데 본격적으로 recurrent neural network가 무엇이고 어떤식으로 동작하는지 살펴보자.
Recurrent neural network
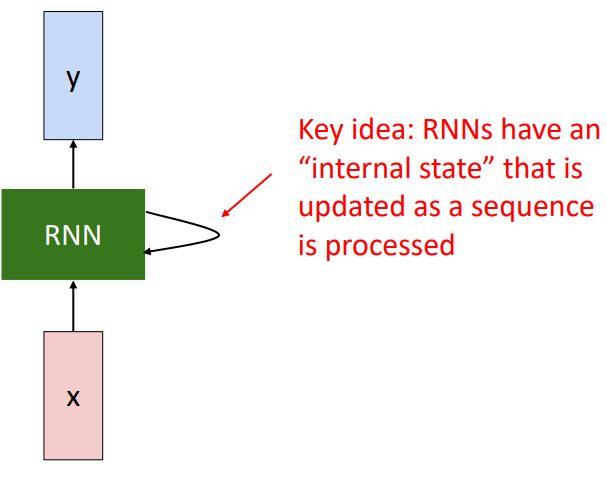
- Recurrent neural network는 매 time step마다 x를 input으로 받아 network 내부의 일종의 vector인 "internal hidden state"를 특정 undate formula를 통해 update해가며 이를 통해 output y를 출력하게 된다.
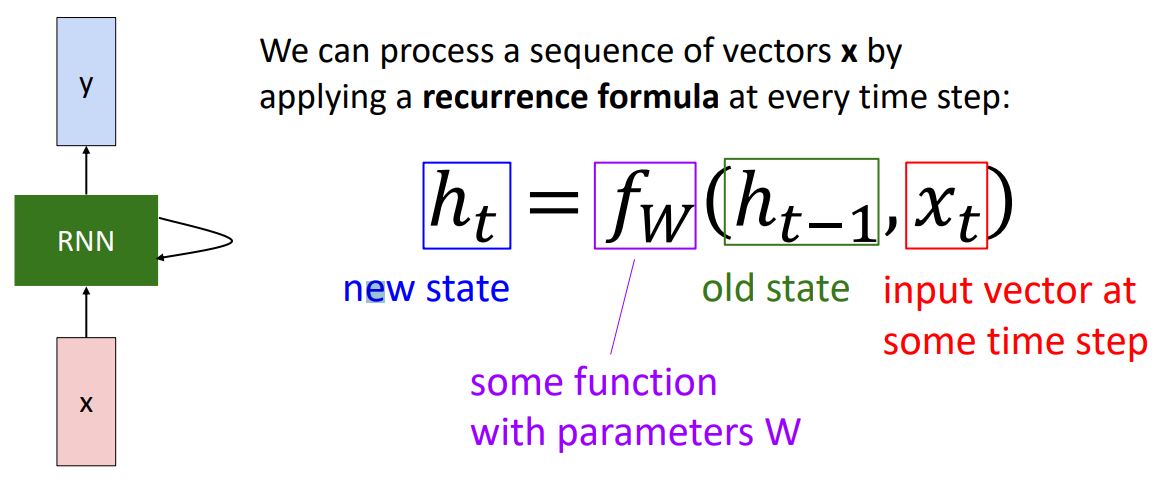
-
Recurrent neural network의 architecture를 정의하기 위해 위 식의 보라생 박스인 recurrent fomula 를 사용한다.
-
위 그림의 식은 t-1 시점의 state와(초록박스) t시점의 input x를(빨간박스) 입력으로 받아 learnable weights W에 의존적인 function f(보라박스)를 통해
new state(파란박스)를 계산하게 되는 식이다. -
이때 를 계산하기 위한 모든 time step에서 같은 function과 같은 weights matrix를 사용한다는 것인데, single weights matrix만을 갖게 하는 이러한 구조가 arbitrary length를 갖는 sequence를 처리할 수 있게 해준다. (*처음 들었을때는 뭔소린가 싶었지만 다시 생각해보니 당연한 소리다...)

-
RNN의 simplest version인 Vanilla RNN에서 output을 구하는 방식은 위 그림과 같다.
-
hidden state를 구하기위하여 과 에 각각 곱해지는 두개의 learnable matirx 가 있으며 두개의 행렬곱을 더해주어 non-linearlity인 tanh를 취해주게된다.
-
출력 를 구하기위해 에 또다른 weight matrix 를 곱해주게 된다.
-
- 이러한 RNN의 기본구조를 computational graph를 통해 살펴보자.
RNN Computational Graph
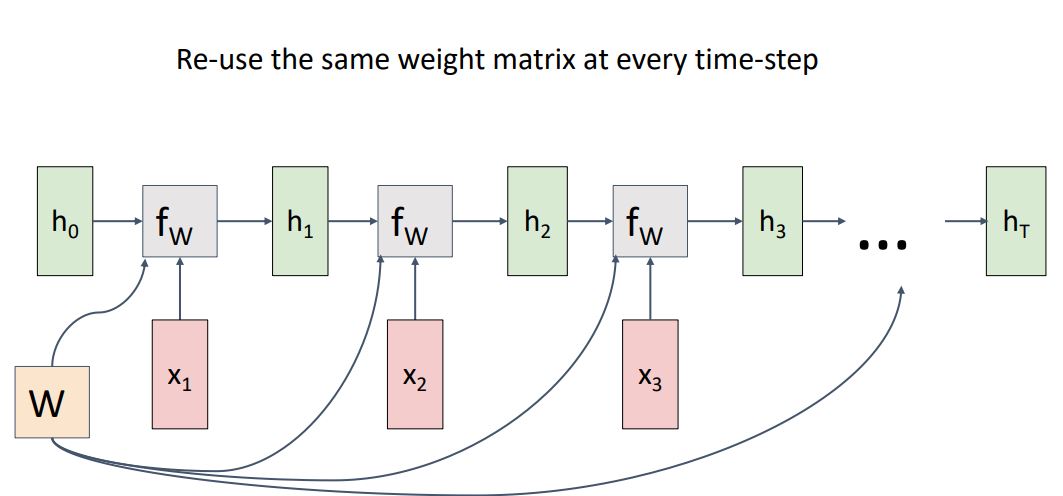
-
RNN은 위 그림처럼 먼저 첫번째 hidden state인 를 0로 initilize하고 와 을 통해 을 출력하는 이러한 과정을 same function, same weight W 를통해 input으로 들어오는 sequence의 길이만큼 반복한다.
-
이때 backporp과정에서 W는 이전 (lec6. backprop) 강의에서 보았던 copy gate로 볼 수 있으며 이는 각 노드(여기선 )의 gradient를 summation 해주는 gradient adder로 볼 수 있다.
-
다시 말하지만 모든 time step in sequence에서 동일한 weight matrix를 사용하기 때문에 하나의 recurrent neural network에서 어떠한 길이의 sequence든 처리할 수 있게된다.
-
이러한 형태는 rnn의 기본 연산이며 이를통해 (one-to-many, many-to-one등)다른 유형의 sequential processing task에 적용시켜보자.
.JPG)
-
Many-to-many는 위 그림처럼 input을 sequence로 받아 각 sequence의 point(time step)마다 output을 출력하는 형태로 이전에 말했던 Per-frame video classification이 이러한 network 형태를 갖는다.
-
그림에는 나와있지 않지만 매 time step마다 output 를 출력하기 위해 weight matrix 가 사용되며 각 output 는 classification을 위해 loss function을 통해 time step별 loss인 가 계산되며 이를 다 더해주어 final loss를 계산하게 된다.
.JPG)
-
Many-to-one network는 위 그림과 같이 sequence를 input으로 받아 하나의 output을 출력하는 형태로 전체 image를 받아 single label을 출력하는 network로 Video classification이 이러한 형태의 network를 갖는다.
-
이때 final hidden state는 전체 input sequence에 영향을 받고 마지막에 하나의 classification decision을 위해 network에서 전체 sequece의 정보들을 encapsulate한 것으로 생각해 볼 수 있다.
.JPG)
- 위 그림과같은 one-to-many는 image captioning이 이러한 형태를 갖으며 이는 하나의 input을 가지고 sequence data를 출력하는 형태이다.
.JPG)
-
위 그림의 RNN의 또다른 application중 하나로 seqence to seqence가 있는데 이는 machine translation 에서 사용된다.
-
Seq2seq network는 encoder 역할을 하는 many-to-one network에서 sequence를 input으로 받아 decoder 역할을하는 one-to-many network로 feeding해주어 decoder에서 sequence를 output하는 형태이다.
-
이는 영어를 프랑스어로 번역하는 network로 보았을때 encoder에서 english sentence를 sequence로 입력받아 이를 요약한 형태인 하나의 hidden vector를 출력하고, decoder에선 encoder의 출력인 hidden single vector를 입력으로 받아 프랑스어 sentence를 output sequence로 출력하는 형태이다.
-
Encoder와 decoder로 network를 분리하여 두개의 weight matrix를 갖게한 이유는 input tokens과 output tokens의 length(num of wards)가 다를 것이기 때문이라고 한다.
-
이러한 seq2seq network가 어떻게 동작하는지 Language Modeling task의 예시를 통해 구체적으로 살펴보자.
Language Modeling
- Language model의 기본 idea는 input data의 stream을 받아서 매 time point별 next character가 무엇인지 예측하는 것이다.

- 우선 위 그림처럼 input sequence를 'h', 'e', 'l'과 같이 미리 정해놓은 vocabulary를 one-hat encoding 시킨 vector로 변환시킨다.
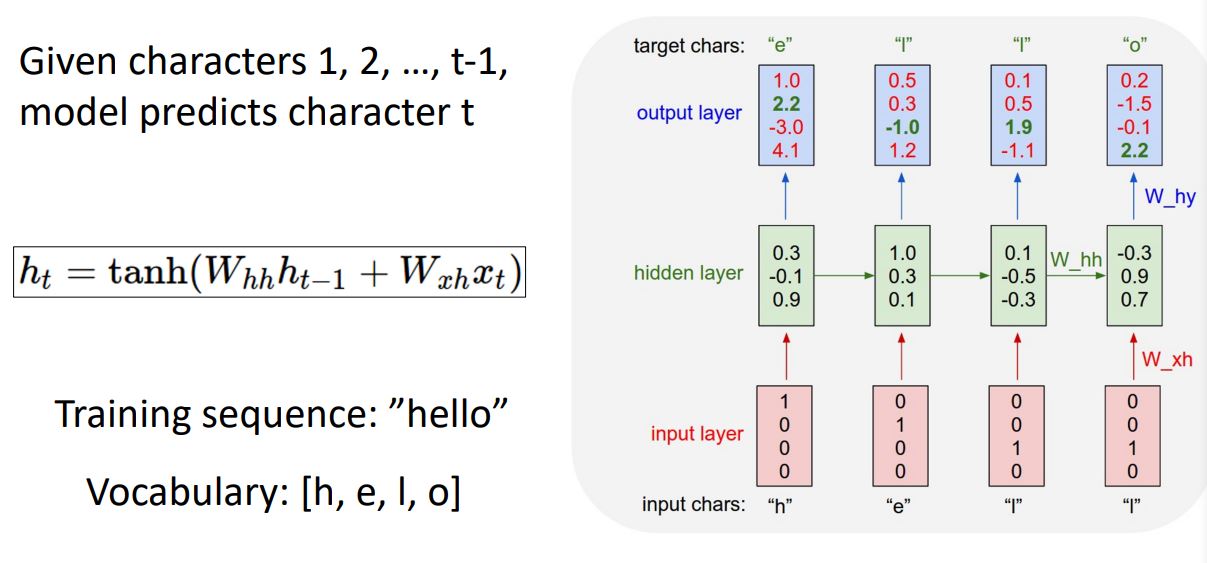
- 이러한 sequence of input vector를 통해 time step별 hidden state를 구하고 각 단어에 대한 예측결과로 output을 출력해준다. 이렇게 network는 매 time point별 next element in the sequence (다음 올 단어)를 예측하게 된다.
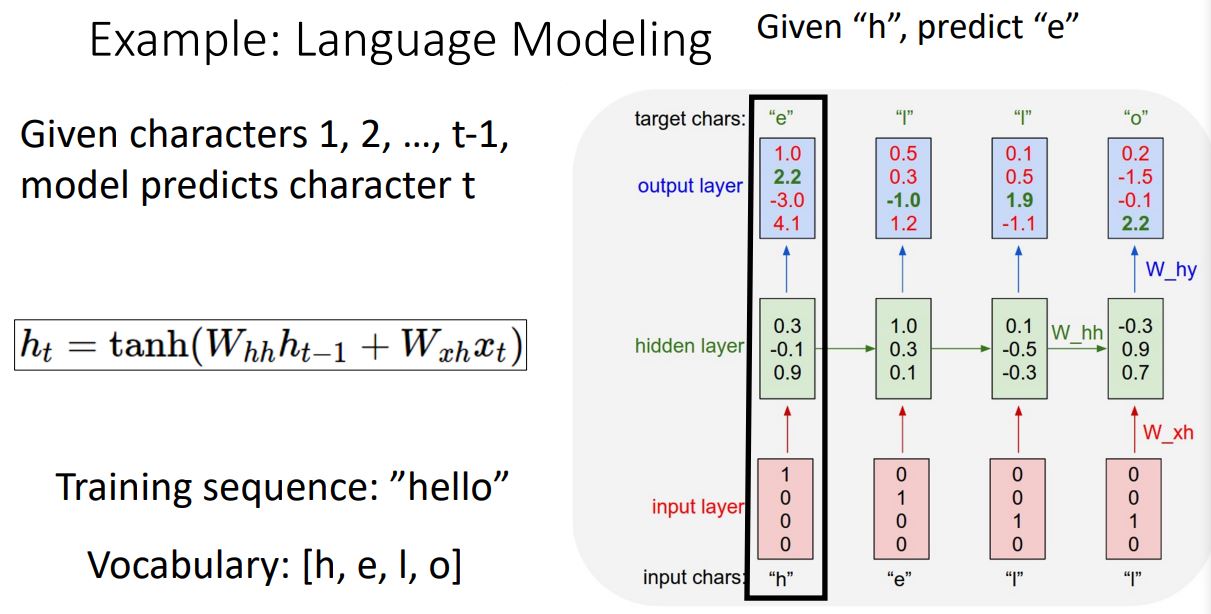
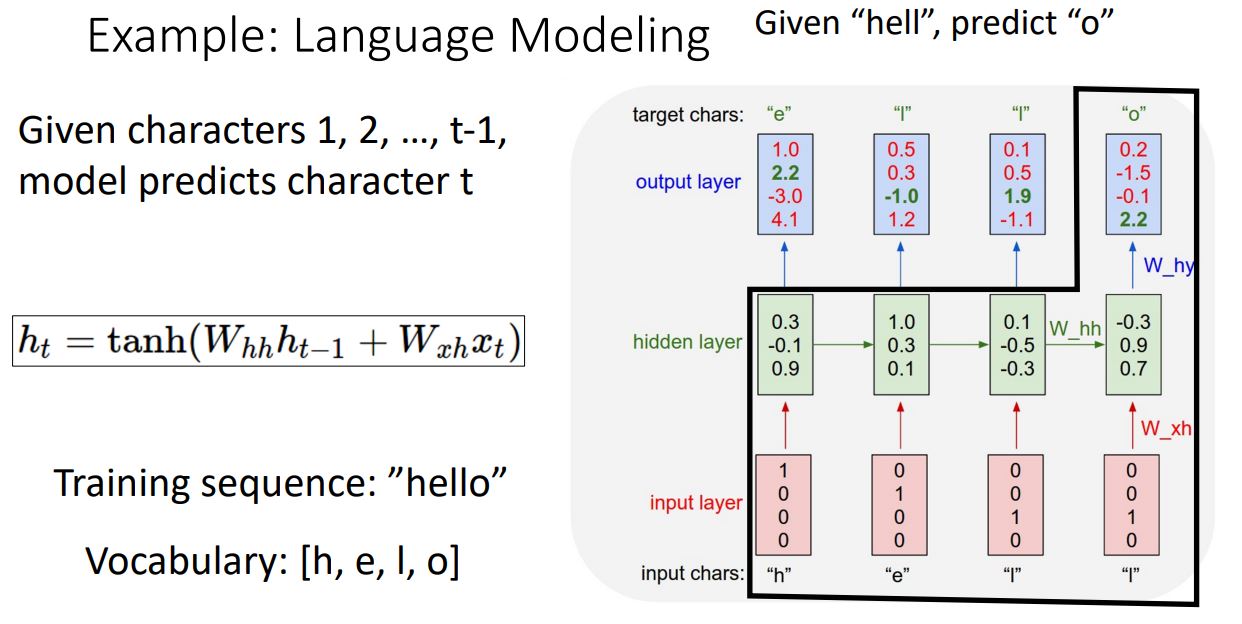
- Input sequence의 첫번째 element인 'h'를 받으면 network는 cross-entropy loss를 통해 next elment인 'e' 를 예측도록 학습하는 형태로 각 time step별로 이전의 hidden state와 input character를 가지고 다음에 올 단어를 예측하도록 학습하게 된다.
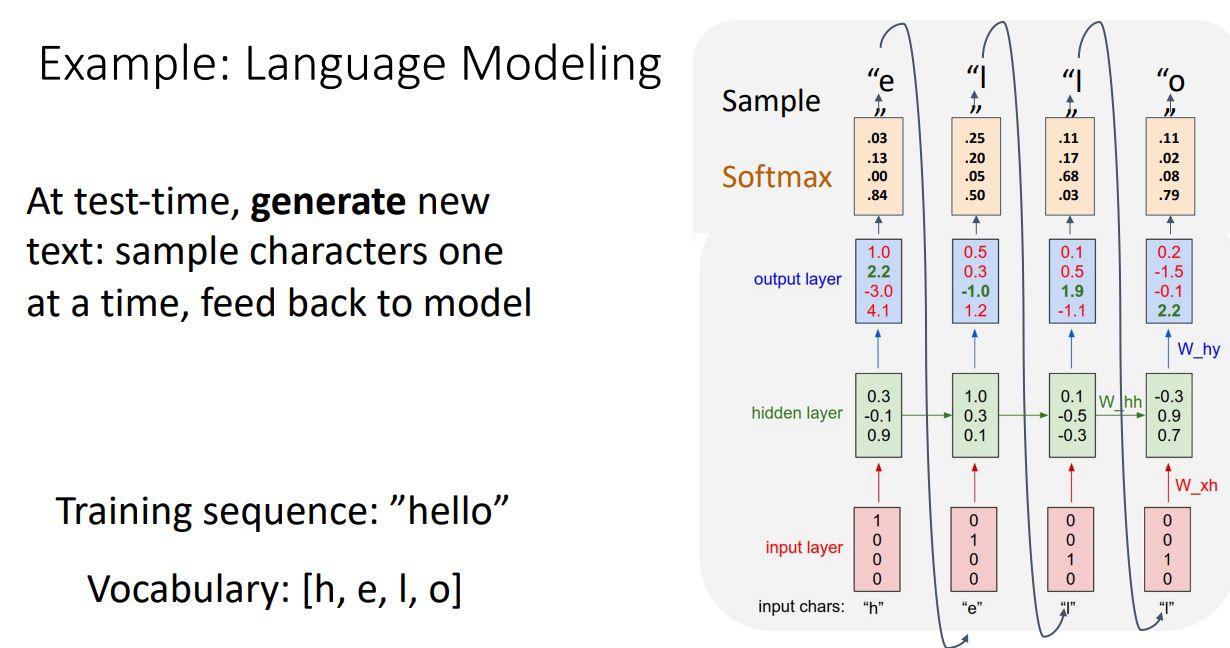
- 위와같이 학습된 language model은 학습된 text의 style을 갖는 새로운 text를 생성하는 형태이므로 test-time시에 (위 그림의 'h'와 같은) initial seed token을 주어야 한다.
.JPG)
- Hidden state를 계산할때 위 그림처럼 input vector인 one-hot vector와 weight matrix를 mutiplication해주는 형태인데 이는 단순히 weight matrix의 column vector중 하나를 추출하는 형태이다.
.JPG)
- 이러한 비효율적인 sparse one-hot vector multiplication 연산에서 hidden layer와 input layer사이에 embedding layer 를 추가해주어 각 embedding layer의 low에 상응하는 weight matrix의 column을 학습함으로서 sparse하지 않고 separate하게 연산하고 결과적으로 weight matrix가 어떤 column을 추출해야 하는지를 학습하게 된다.
-> 아... 뭔가 써놓긴 했는데 뭔소린지 정확히 그려지지 않는다...
-> 이전 그림에서 보았던 test시 output을 predict할 때 argmax를 쓰지 않고 softmax를 사용하여 distribution에서 sampling해주는 이유와 같은건가 싶다.
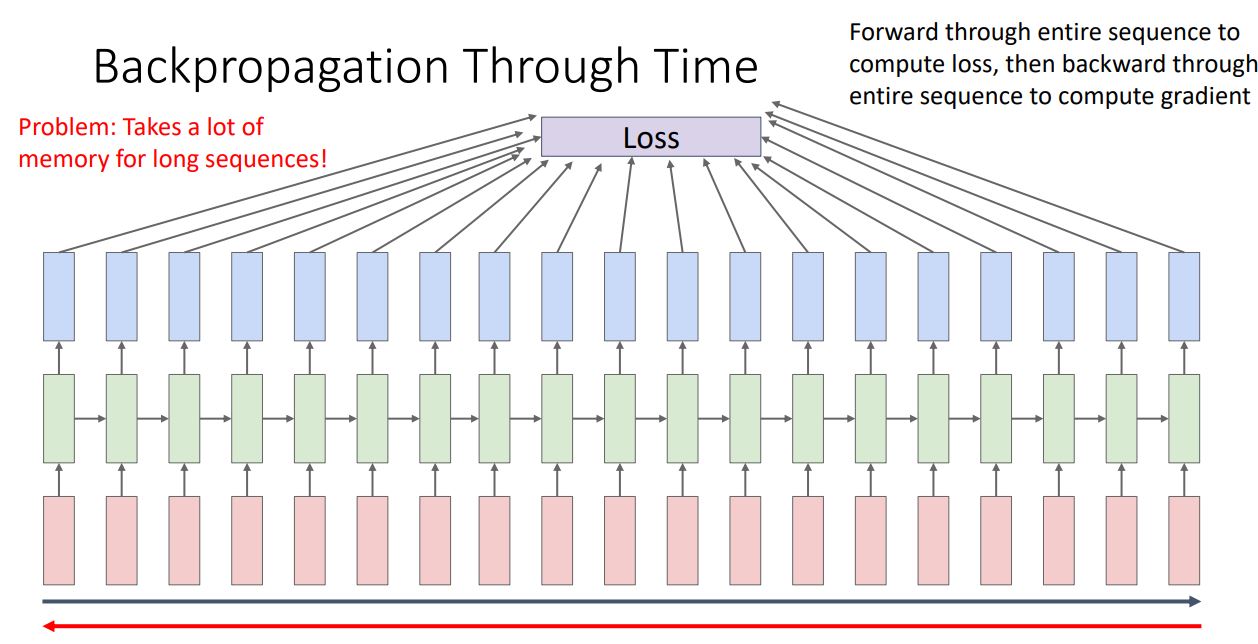
-
RNN language model에서 long sequence를 학습하고자 할때 backporp에서 많은 메모리를 필요로한다는 단점이있다.
-
이러한 문제를 해결하기위해 Truncated backpropagation이라는 alternative approximate algorithmn을 사용한다.
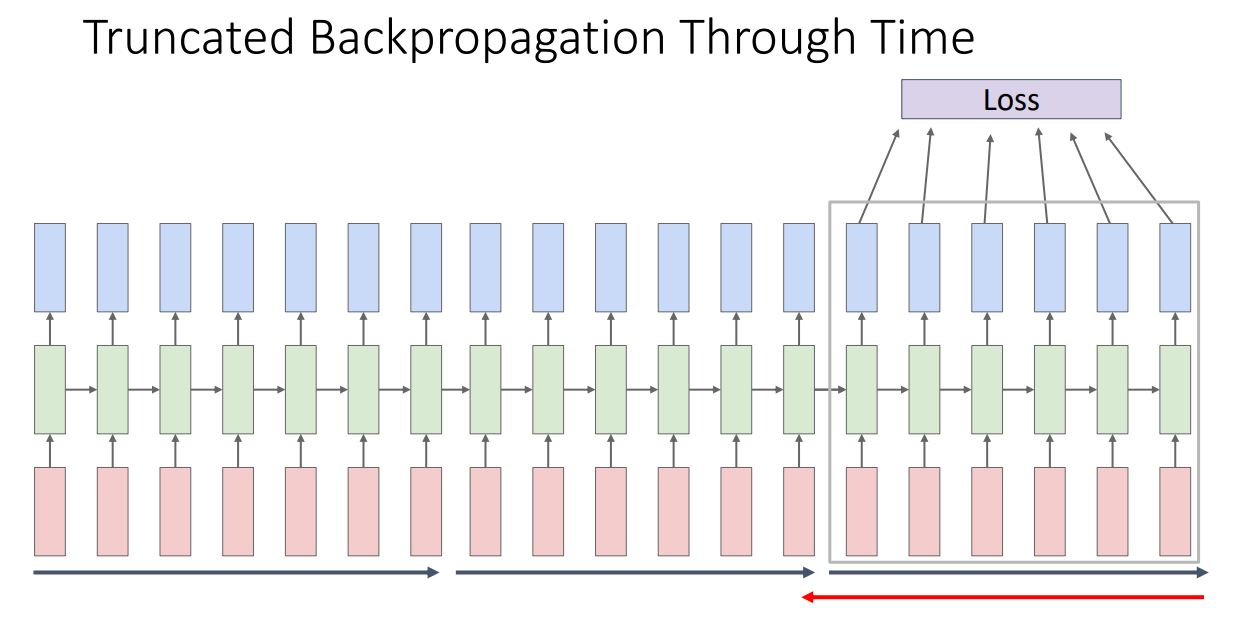
-
위 그림처럼 전체 seqeunce를 학습하지 않고 sequence의 subset(chunk)으로 나누어 학습시키는 방식으로 각 chunk별 마지막 hidden state만 기억하여 다음 chunk로 전달하는 방식이다.
-
결국 각 chunk별 loss를통해 해당 chunk의 weight matrix를 학습하는 형태가 되는 것이다.
-
이와같이 각 chunk만큼의 메모리만 필요로 하기에 한정된 GPU memory 에서도 학습을 수행할 수 있게된다.
-
듣기에는 굉장히 복잡해보이지만 아래 깃헙링크의 코드와같이 pytorch없이 python만으로 122 line만에 구현할 수 있다고 한다.
Language Model Examples
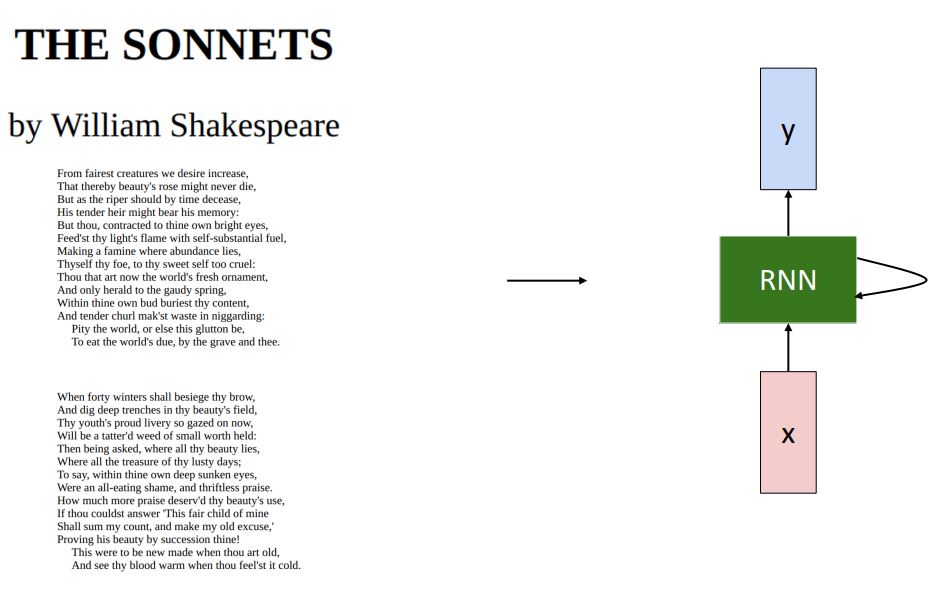
- 지금까지 보았던 language model을 통해 쉐익스피어 작품의 text를 학습하여 100개정도의 character를 주어 next character를 predict해보자.

- 위 그림처럼 점점 학습 할수록 그럴듯한 text를 예측한다는 것을 볼 수 있다.

- 좀더 long sequece를 통해 오랜시간동안 학습시키면 위 그림과같이 좀더 현실적인 text를 출력하는 것을 볼 수있다.
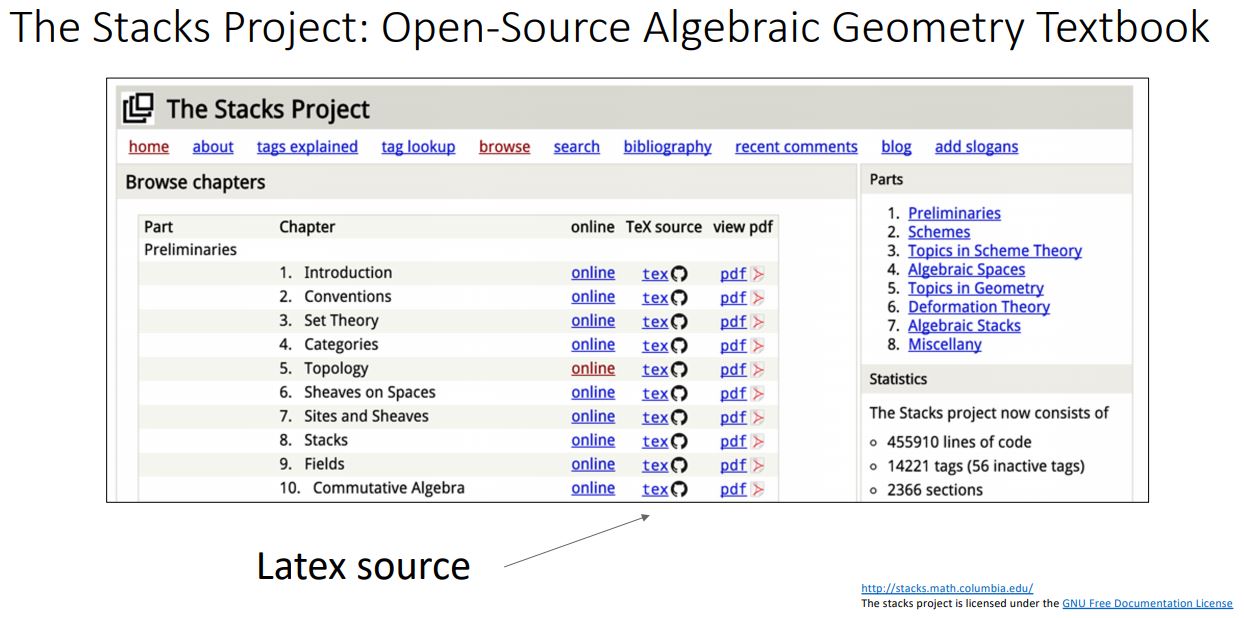
- 그렇다면 수천 page의 algebraic geometry textbook의 LaTex source code를 학습시키면 어떻게 될까??


-
수학적으로 봤을때 말도안되는 형태이지만 위 그림처럼 diagram도 표현하고 증명도 서술되며 그럴듯한 형태로 나타내고있다.
-
이를통해 어떤 종류의 data도 character level rnn을 통해 학습시킬 수 있다는 것을 보여준다.
- 이번엔 리눅스 커널 소스코드를 학습시켜보자.


-
변수명, 함수, 인덴트, 메크로 정의 등등 정말 그럴듯한 code를 생성해낸다.
-
그렇다면 이러한 data들을 학습한 rnn은 어떻게 동작하는 것이며 어떤 종류의 representations일까?
Searching for Interpretable Hidden Units
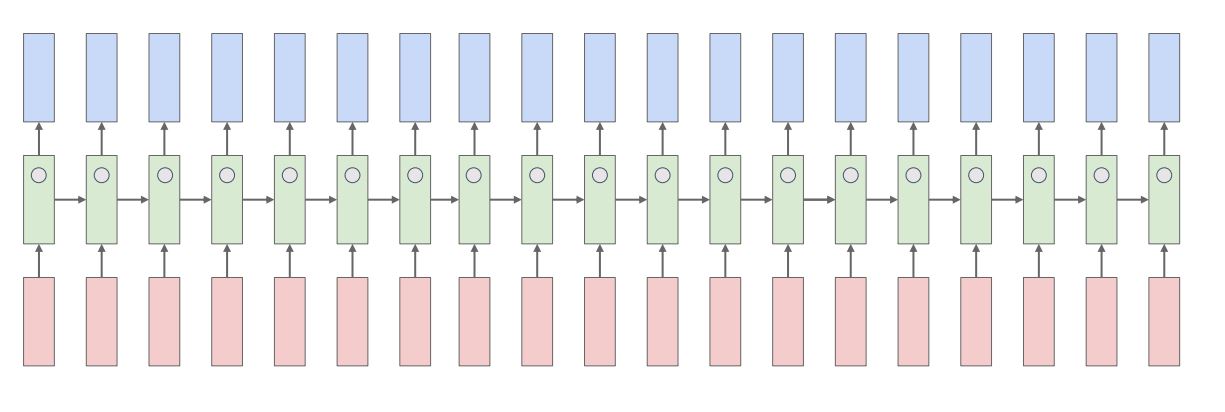
- Justin Johnson은 language model이 다양한 유형의 data에서 무엇을 학습하는지를 연구하였고, RNN을 학습시킨 후 predict과정에서 hidden state vector를 tanh를 거쳐 output을 출력하게 하였고 이 -1 ~ 1 사이의 값을갖는 character값들의 크기를 color강도로 표시하여 hidden state의 element들이 어떻게 다른지 판단할수 있게 하였다.

- 위 그림은 linux kernel을 model이 predict한 결과로 각 state의 값들이 random하게 나타나서 어떤것을 학습하는지에대한 직관을 얻을수 없다고하였다.

- 위 그림은 톨스토이 War and Peace를 학습시킨 model이 predict한 결과로 model은 character들이 따옴표안에 있는지 없는지에 따라 다른 -1 혹은 1에 가까운 state로 예측했다는 것을 보여준다.

- 또 다른 예로는 문장끝에 개행이 들어간 data를 학습시킨 model의 결과인데 이는 model이 개행이 될만한 위치를 학습했다고 생각할 수 있다.


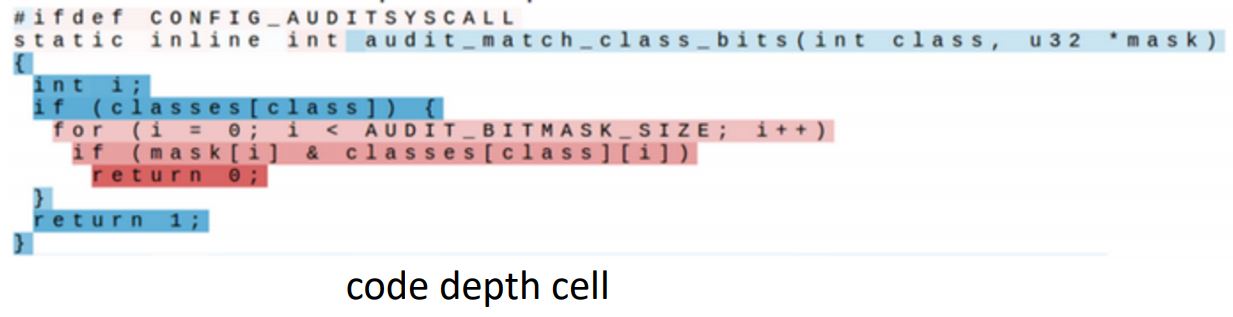
- 위 3개 그림은 linux 소스코드를 학습한 것으로 각각 if문의 조건, 주석, 인덴트 level을 예측한 것으로 보인다.
- 위 실험에대한 결과로 우리는 model이 단순히 다음 문자를 예측하게 학습한 것 뿐만 아니라 학습된 data의 구조에따라 의미있게 학습한다는것을 알 수 있다.
Image Captioning
- RNN language model을 computer vision문제에 적용한 예로 image captioning을 살펴보자
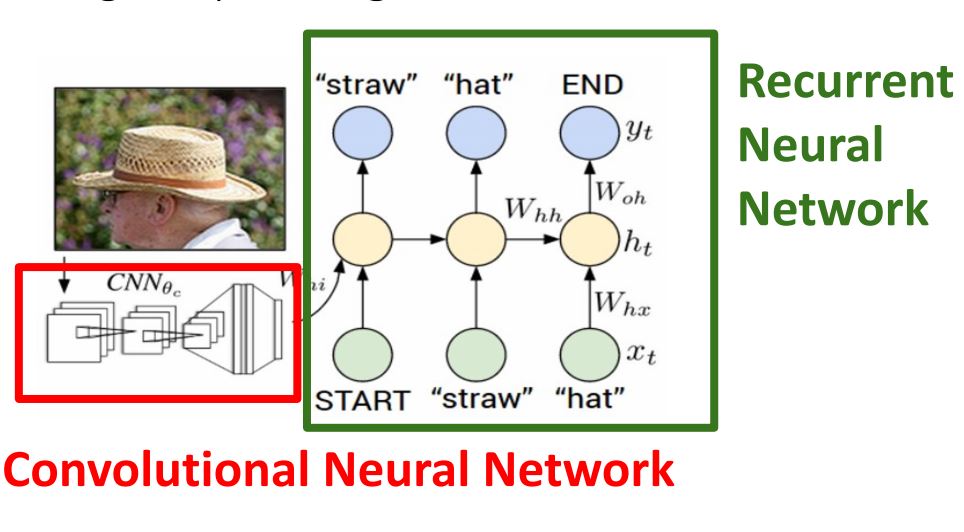
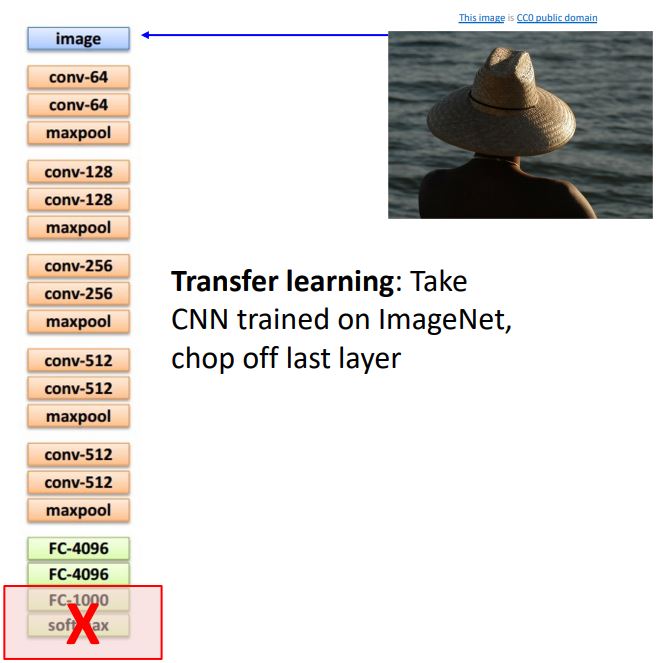
- Image captioning은 위 그림처럼 CNN에 input으로 image를 주고 feature를 추출하여 (one-to-many)RNN language model에 입력으로 넣어 image를 설명하는 wards들을 생성해내는 형태이다.
-
Image captioning은 transfer learning을 사용하여 CNN의 마지막 두layer를 제거한 형태로 사용한다.
-
이 전에봤던 language model이 stream of data에대한 연산과 관련있었다면 Image captioning에서의 language model은 sequece의 START token과 End token에 집중하여 학습하기를 원한다.
![]()
-
CNN과 RNN을 연결시키기위해 recurrent formula를 위 그림처럼 변경해야한다. 기존 input x와 previous state를 linear transform시켜 더해주는 식()에서 CNN에서 출력으로 나온 feature vector v에도 linear transform시켜 () 더해주는 형태이다.
-
즉, 3가지 input의 가중치합을 모두 더해주어 tanh를 취하여 output을 내보내는 형태이다.
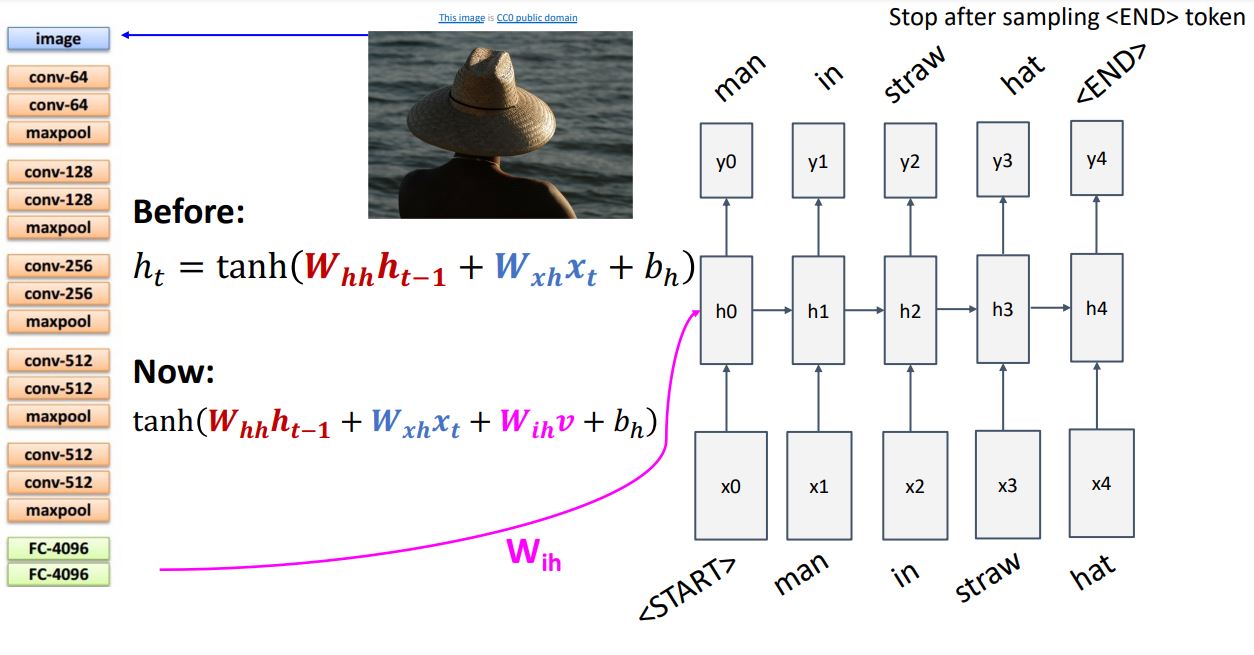
- 위처럼 RNN에서 START 토큰으로 시작하여 반복해서 next 토큰을 예측 하다가 END 토큰을 출력하면 model이 sampling을 멈추는 형태이다.


- 위 첫번째 그림처럼 image captioning은 좋은 결과를 내기도 한다.
- 하지만 두번째 그림의 예시처럼 model이 잘못된 descript를 출력하기도 하는 것을 봤을 때 image captioning model은 computer vision task를 해결하기에는 아직 멀었다는 것을 알 수 있다.
Vanilla RNN Gradient Flow
-
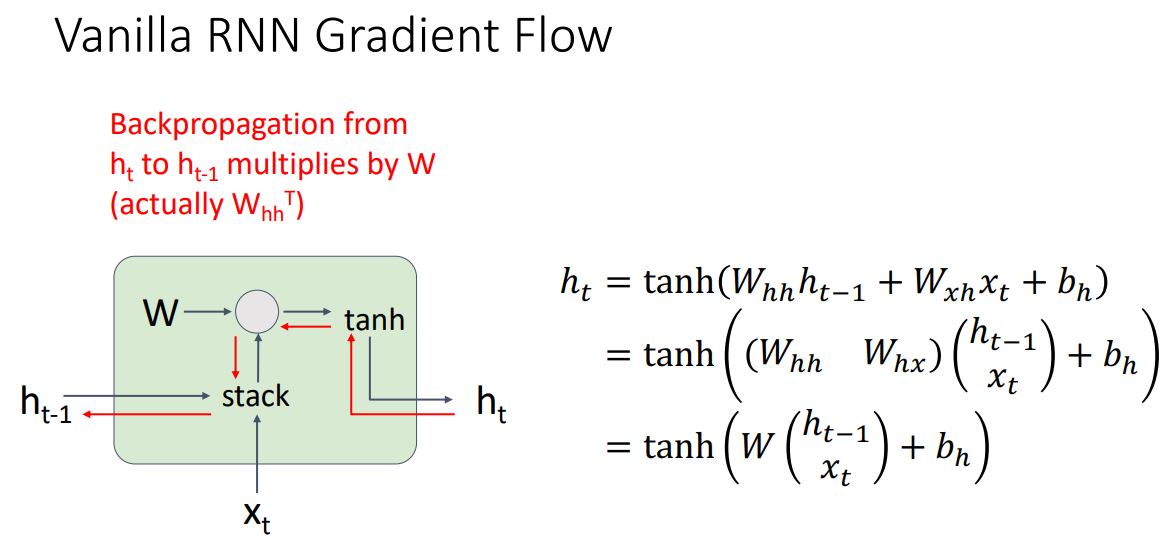
Vanilla RNN에서 의 gradient를 구하기 위해 loss로부터 backprop해서 gradient를 계산해야한다. 하지만 이러한 backprop에는 2가지 문제가있다
- 한가지는 non-linearity로 tanh는 좋지 않다는 것인데 Vanilla RNN은 90년대에 나온것이기에 pass.
- 다른 문제는 backprop시 matrix multiply stage에서 매번 동일한 를 곱해준다는 것이다.
-
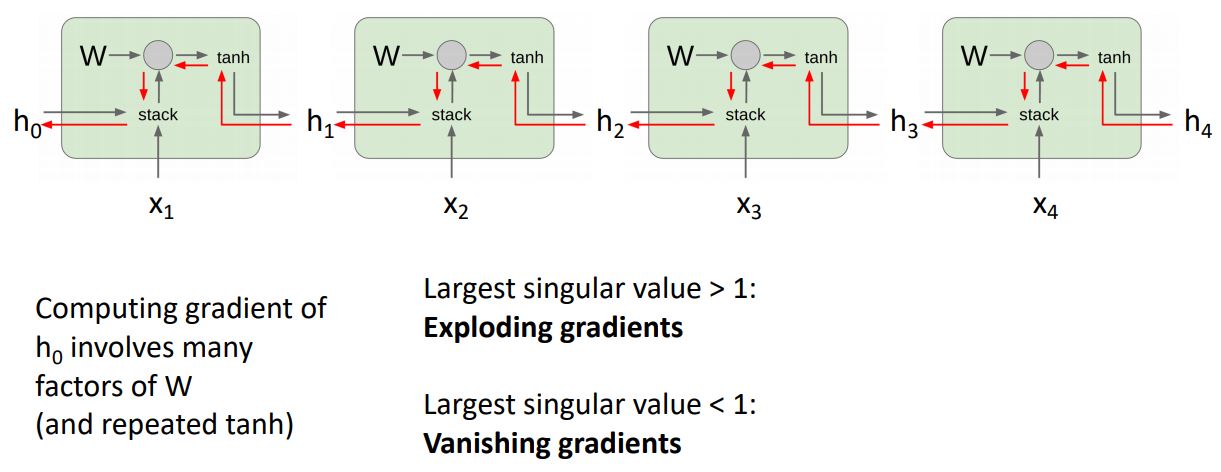
많은 time step으로 이루어진 network를 통해 위 문제를 살펴보자
-
위 그림에서 직관적으로 볼 수 있듯이 backprop시에 매 cell마다 계속해서 동일한 weight matrix X가 upstream gradient와 계속해서 곱해지는 형태로 (backprop 에서의 mul gate pattern을 생각해보면 쉽다) 이는 두가지 안좋은 문제를 발생시킨다.
-
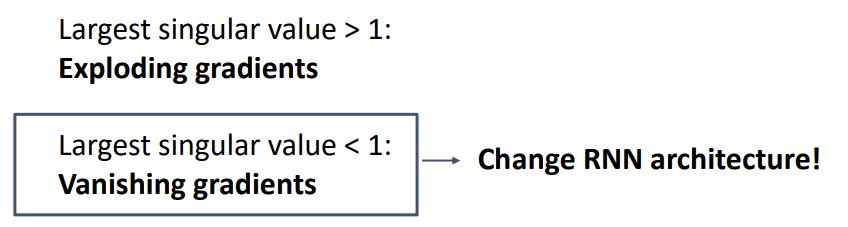
직관적으로 보기위해 weight matrix를 largest sigular value로 판단하였을때 이 값이 1보다 클경우 exploding gradient문제를 발생시키고 1보다 작을경우 vanishing gradient문제를 발생시킨다.
-
이때 largest sigular value가 1일경우에만 제데로 학습이된다고 볼 수 있다.
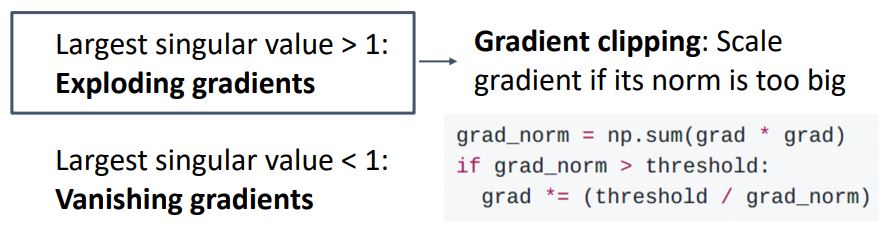
-
Exploding gradient가 발생할 경우 첫번째 그림처럼 clipping을 통해 해결할 수도 있지만 실제 gradient가 아니기에 여전히 문제가 있다고 한다.
-
Vanishing gradient가 발생할 경우는 딱히 방법이 없어 아키텍쳐를 바꿔야한다고 한다.
LSTM
- 우리가 이전까지 보았던 Vanilla RNN을 대신해 흔히 사용되는 LSTM(Long Shor Term Memory)가 있다.
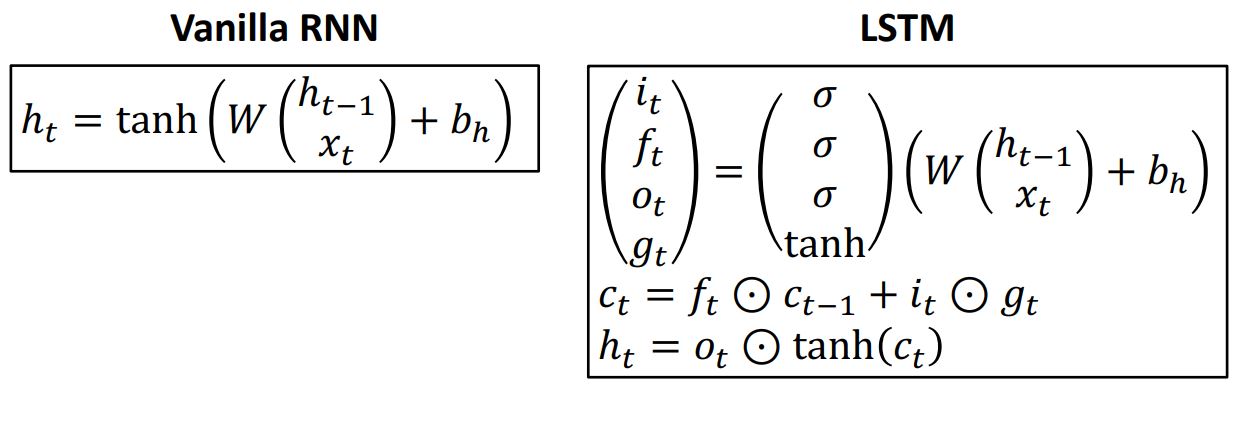
-
Vanilla RNN에 비해 LSTM의 functional form을 보면 이게뭔지 어질어질 할텐데 LSTM의 기본적인 직관은 매 step마다 single hidden state vector를 기억하는 대신에 위 그림처럼 (csll state)와 (hidden state)라는 두개의 state vector를 기억한다.
-
LSTM에선 이전 hidden state 와 current input 를 통해 4개의 다른 gate values를 구하는데 이를통해 위 식처럼 cell state와 hidden state를 계산하게 된다.
-
이러한 functional form이 실제로 무슨일을 하게되는지 자세히 살펴보자.
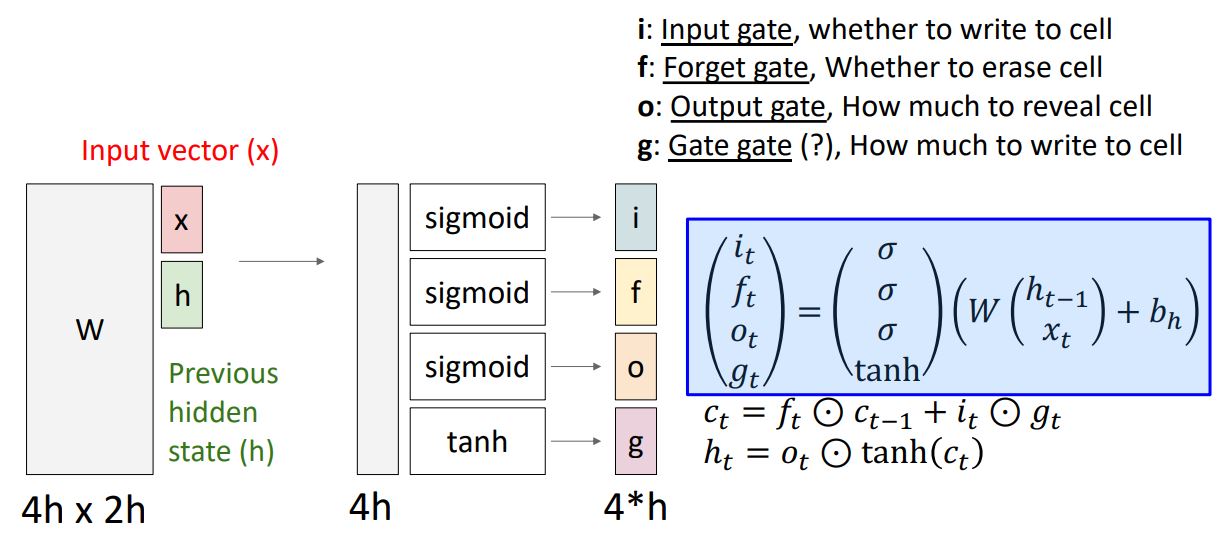
-
위 그림처럼 기존의 Vanilla RNN에서는 intput vector x와 previous hidden vector 을 concatenate시켜 weight matrix W에 multiply시킨 후 tanh를 거쳐 를 구해줬다면
-
LSTM에선 와 을 W와 곱한 결과를 4개의 gate로 출력하는 형태로 이 4개의 gate의 출력값을 가지고 cell state와 hidden state를 계산하게 된다.
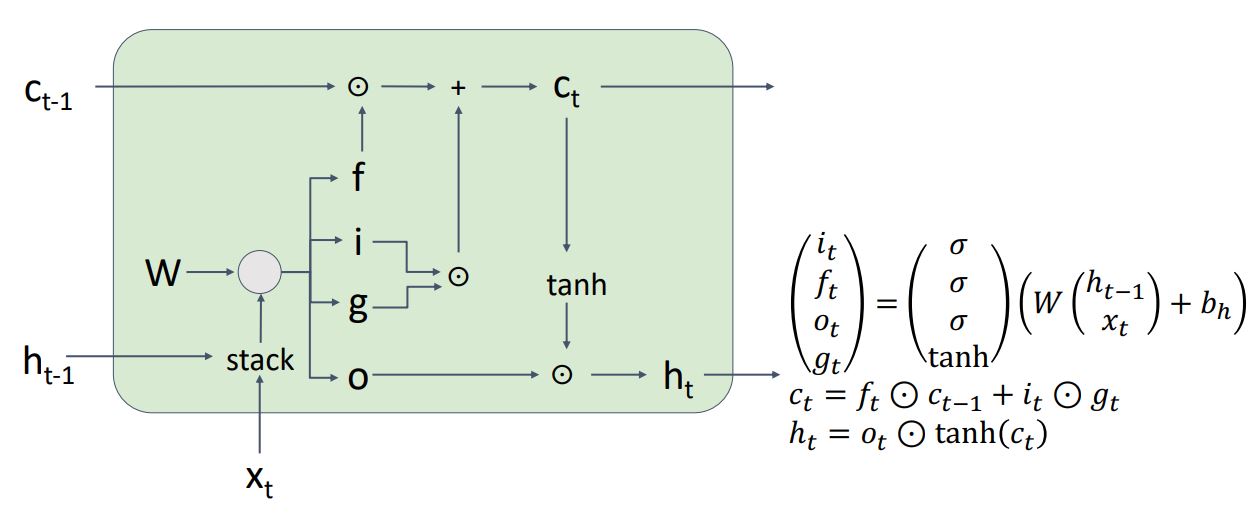
-
식에 대한 해석은 다음과같다.
-
먼저 f 와 를 element-wise 곱셈 하는데 이때 forget gate인 f는 sigmoid를 거쳐 0~1의 값을 가지므로 f가 0일 경우 를 element-wise하게 0으로 만들어 전파하고 1일경우 온전한 값을 전파한다는 의미이다.
-
와 의 element-wise곱 에서는 g gate가 -1~1값을 갖으므로 값을 빼고싶은지 더하고싶은지 결정하고, i gate는 0~1값을 갖으므로 g gate 값의 크기를 정하게된다. 즉, 와 의 element-wise곱은 값을 cell state에 얼마나 반영할지를 결정한다.
-
- 마지막으로 를 구하기위해 output gate와 tanh()를 element-wise곱 해주는데 이는 최종적으로 얻어진 cell state인
에서 (0~1값)을 통해 원하는 element만 내보내는 fitering된 output값을 계산하게된다. 이값은 또한 로 next cell에 전달된다.
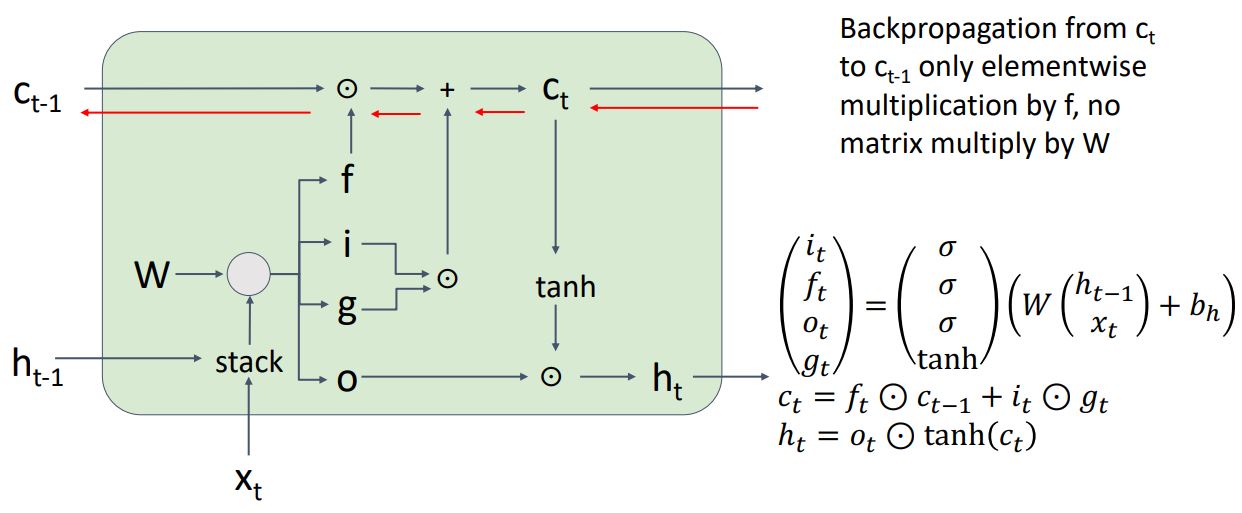
- LSTM의 cell state를 통한 backprop에서의 gradient flow를 삺펴보면 먼저 gradient distributor역할을 하는 add node를 통해 gradient가 그대로 전달되고 f gate와 element-wise곱해주는 node는 기본적으로 f gate를 통해 0~1로 constant scaling 된다고 생각해 보았을때 f gate를 통한 값이 0에 가까우면 정보손실이 있기는 하지만 non-linearlity를 직접적으로 거치는 것이 아니기에 vanishing문제라고 볼 수 없다.
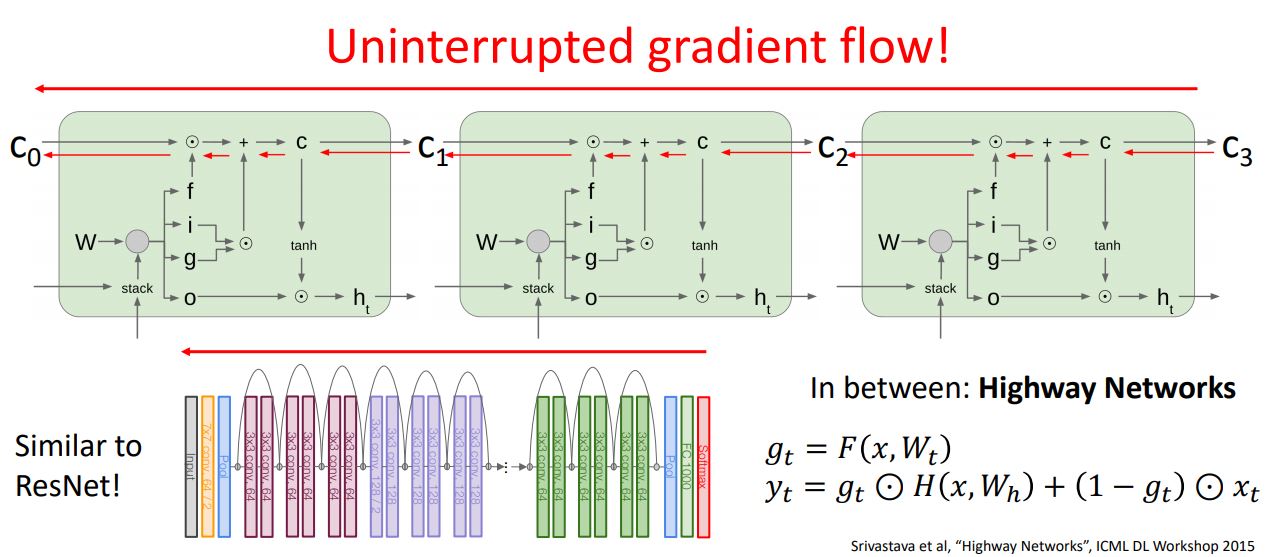
-
위 그림처럼 여러개의 cell을 통해 보아도 cell state는 weight matrix인 W와 곱해지는 부분도 없고 어떠한 non-linearlity도 거치지 않는다.
-
이는 resnet의 shortcut의 개념과 유사한 형태로 가 어떠한 W와 non-linearlity에 영향을 받지않고 directly하게 propagate된다는 것을 보장하여 Vanilla RNN의 Long-Term Dependency 문제(resnet 논문에서의 plain net과 동일한 문제)를 해결하였다.
* 논문을통해 이해한 resnet identity mapping개념이 LSTM을 이해하는데 도움이 될줄이야... 여러분 논문읽으세요 ㅎㅎㅎㅎㅎㅎ
Multi-layer RNNs
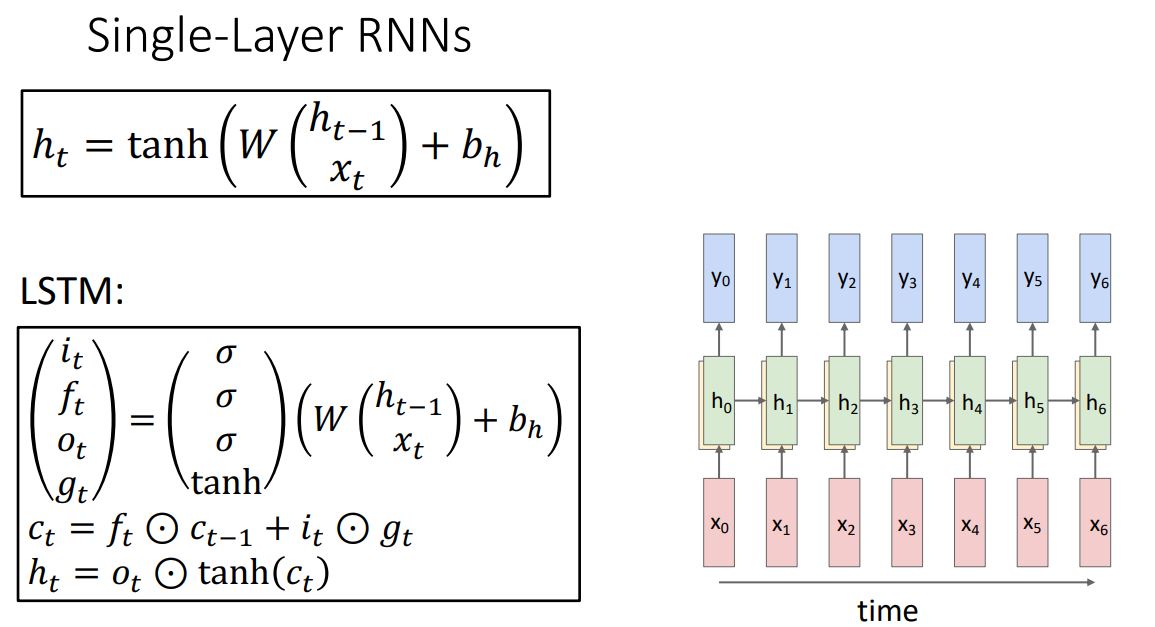
- 위 그림처럼 지금까지 살펴본 seqnece 처리를 하는 single-layer RNN에 이미지 처리를 하는 CNN에서 more layer가 성능을 향상시킨다는 일반적인 견해를 적용시켜보자.
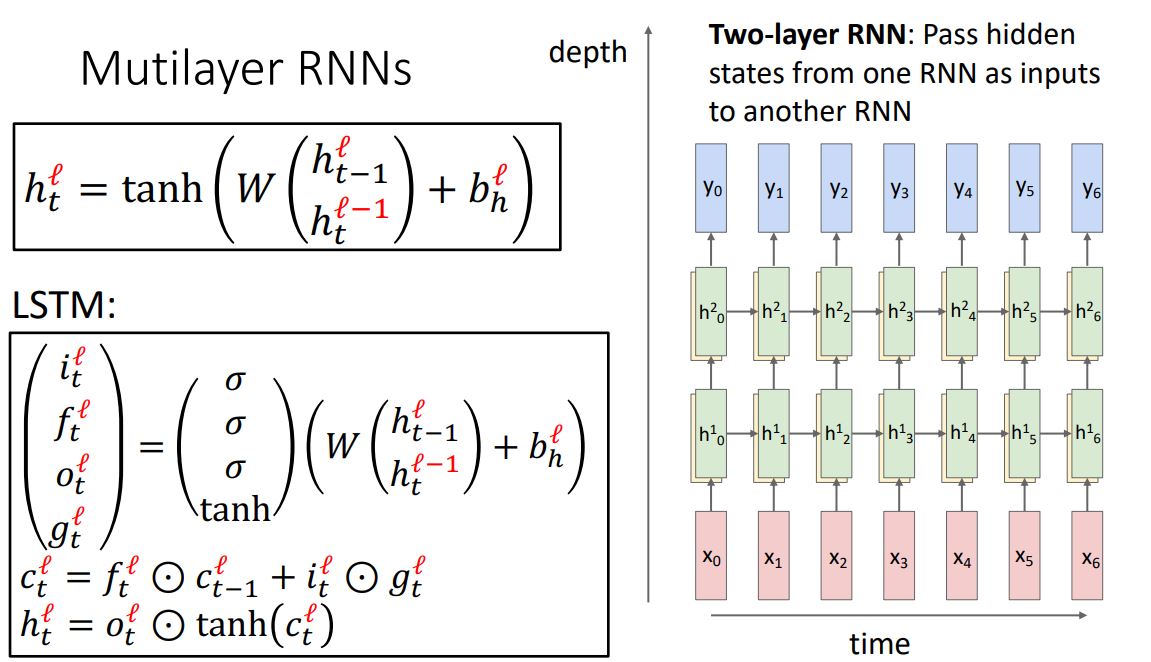
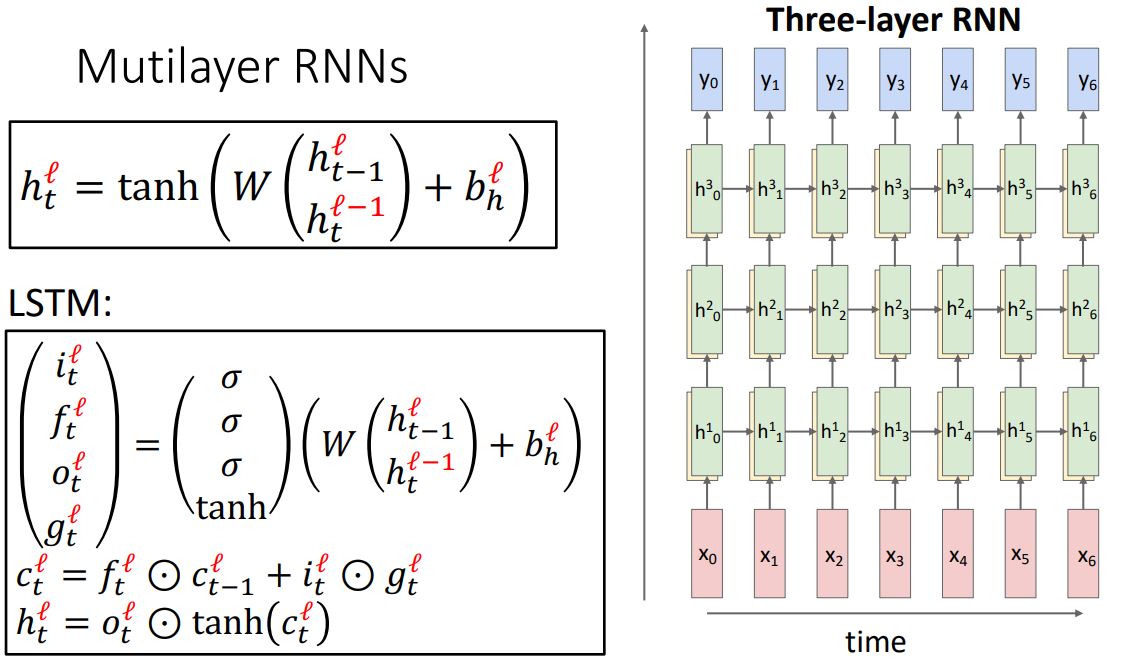
- 위 그림처럼 RNN에 layer를 깊게 쌓으면 성능이 향상되기는 하지만
일반적으론 CNN마냥 layer를 미친듯이 stacking하지는 않고 3~5정도의 layer만으로 구성한다고 한다.

- RNN model중 GRU(Gated Recurrent Unit)라는 LSTM을 단순화시킨 형태의 model이 있는데 이는 강의에서 다루지 않고 논문을 찾아 알아서 공부하라고한다. 나는 하지 않는다 ㅎㅎ.
Outro...
- 이번 강의에선 Vanilla RNN과 LSTM을 통해 RNN model의 구조를 살펴보았는데 왜인지 모르겠지만 너무 빡셌다 다음 강의인 Attention은 더빡신데 언제쯤 포스팅하게될지 모르겠다.........
