[EECS 498-007 / 598-005] 13. Attention

Intro
- 지난 강의에선 다른 종류의 task별 sequence vector를 처리하는 RNN에 대해서 알아보았고 이번 강의에선 나아가 Attention에 대해서 다룬다.
Seq2Seq with RNN
-
Attention 개념을 살펴보기전에 지난 시간에 다뤘던 기본적인 seq2seq model을 자세히 살펴보자.
-
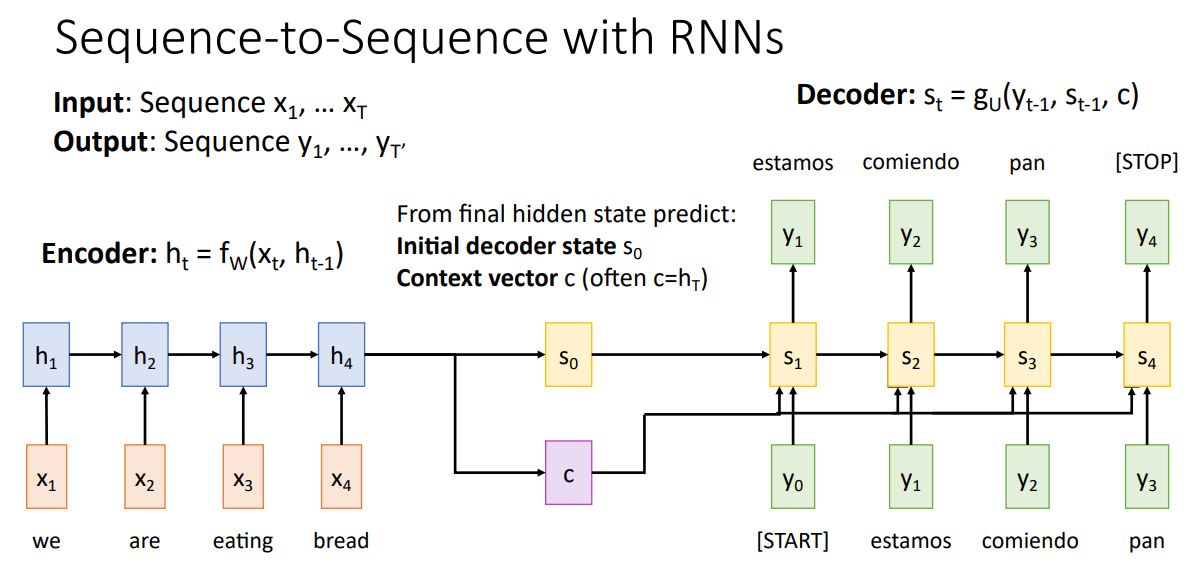
지난시간에 살펴봤듯이 seq2seq은 seqence를 input으로 받아 sequnce를 output으로 출력하며 machine translation task에서 사용된다.
-
위 그림처럼 encoder에서는 input sequence를 받아 t만큼의 step을 거쳐 hidden state를 생산하고 이를 decoder의 첫번째 hidden state 와 context vector로 사용한다.
-
Decoder에서는 input인 START token을 시작으로 이전 state(첫번째에선 )과 context vector를 통해 hidden state 를 생산하고 이를 통해 output 를 계산한다. 이 output을 다시 input으로 넣어 STOP token을 output으로 출력할 때 까지 step을 반복한다.
-
이때 context vector는 input sequence를 요약하여 decoder의 매 step에서 사용되며 encoded sequence와 decoded sequece사이에서 정보를 전달하는 중요한 역할을 한다.
-
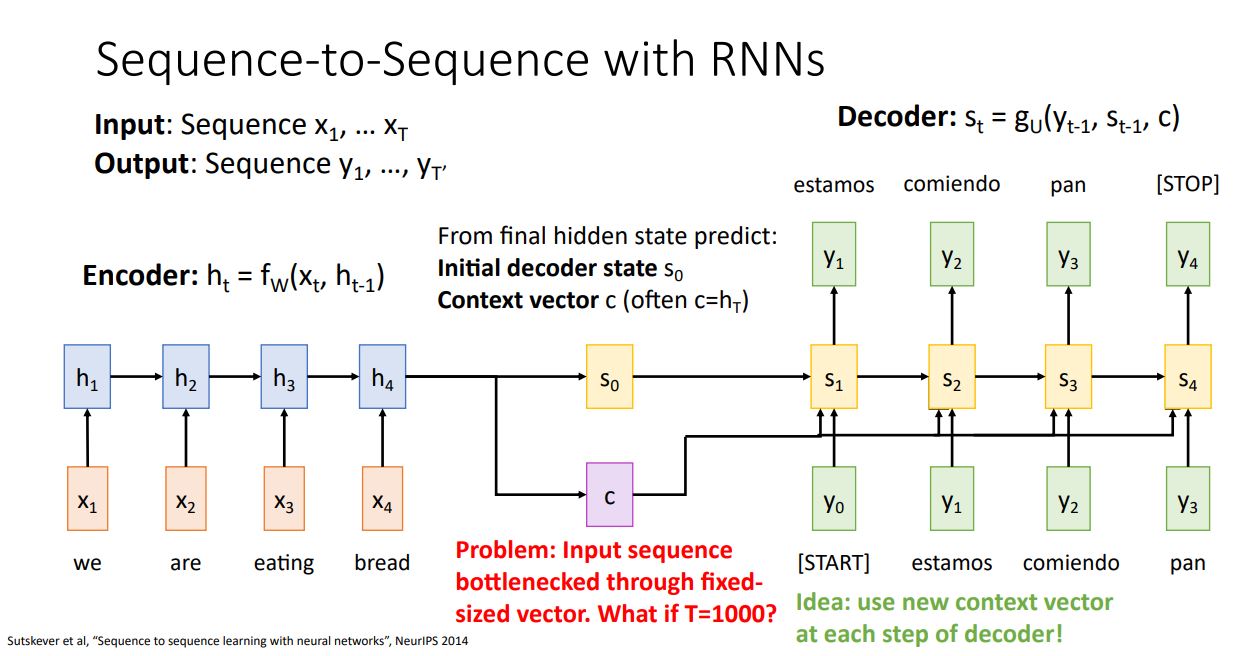
하지만 실제 환경에선 위 그림의 예제처럼 input이 simple sequence가 아니고 text book처럼 input sequence가 매우 클 경우 문제가 발생한다.
-
위 그림에선 이러한 문제를 bottleneck현상으로 설명하지만 자세히 설명하면 다음과같은 문제가있다.
- 첫째, 하나의 context vector에 모든 input 정보를 압축하려고 하니 정보 손실이 발생한다 (Bottleneck 현상 or Long-Term Dependencies problem).
- 둘째, backprop시 gradient vanishing 문제가 발생한다.
-
위와같은 문제를 해결하기 위해 single context vector를 사용하는 것이 아니라 decoder의 매 step별로 context vector를 새로 생성하는 Attention개념을 도입하였다.
Seq2Seq with RNN and Attention
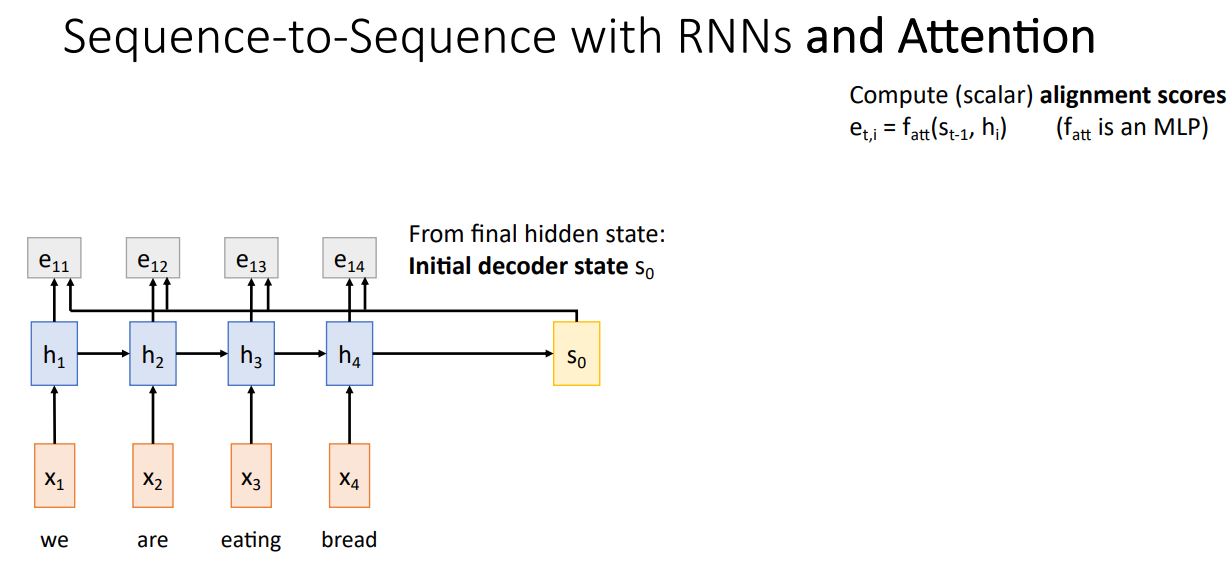
- Attention을 적용한 seq2seq의 Decoder의 매 step별 context vector를 재 생성하는 Attention mechanism을 살펴보자.
-
위 그림의 오른쪽 상단의 식처럼 alingment function을 거쳐 의 (scalar) score를 뽑아내게 된다. 이는 와 를 input으로 받는 fully connected network이다.
-
다양한 attention mechanism마다 alingment function은 다르지만 dot product attention은 다음과 같은 alingment function이 사용된다.
-
- 이때 output score는 decoder의 현재 t시점에서 encoder의 각 state에 집중하는 정도를 나타내게 된다(각 ).
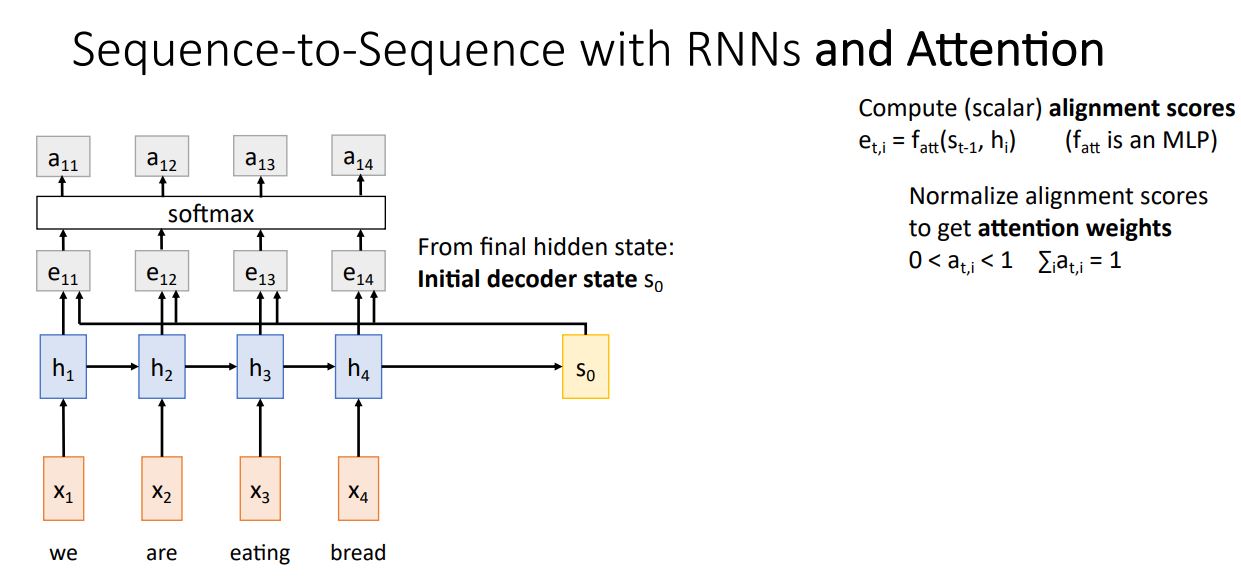
- 이전의 output score ()를 softmax를 통해 0~1사이의 값을 갖는 probability distribution으로 나타내고 이러한 softmax의 output을 attention weights 라고 하고 이는 각 hidden state에 얼마나 가중치를 둘 것이냐를 나타낸다.
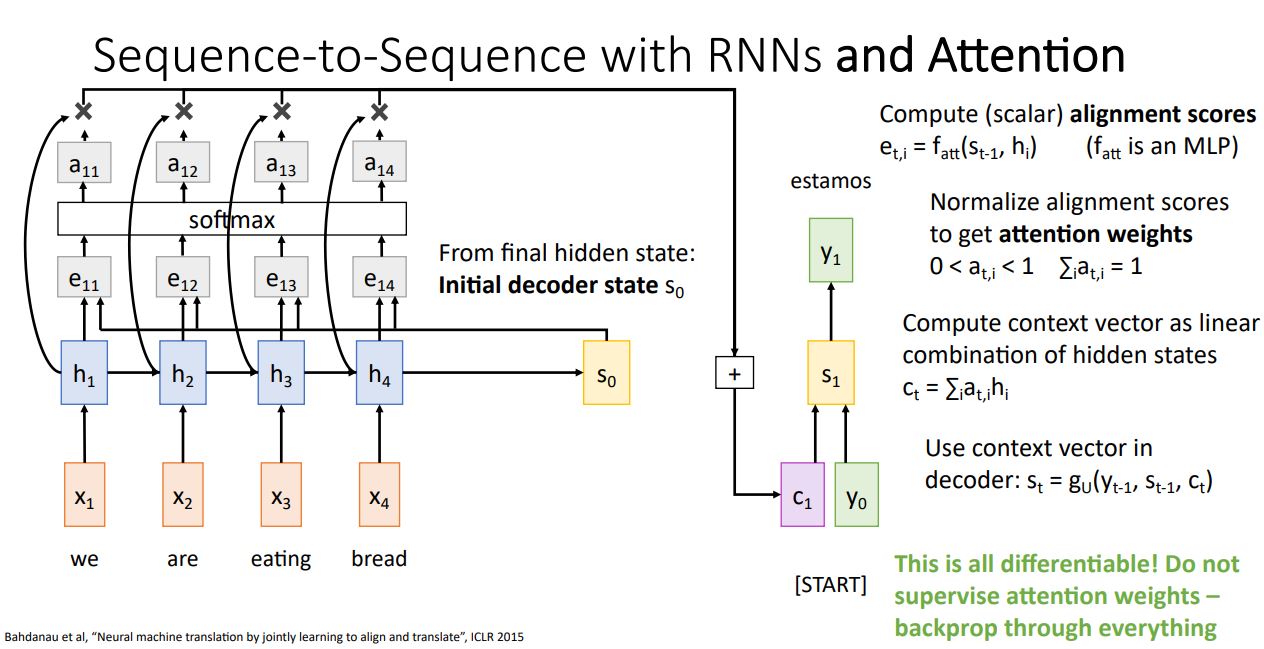
-
Attention weights와 각 hidden state를 weighted sum해주어 () t시점의 새로운 context vector 를 구해준다.
-
Decoder는 이러한 context vector 와 input 이전 state인 을 사용하여 t시점의 state 를 생성하고 이를통해 predict된 output을 생성해준다.
-
위 그림의 computational graph에 나타나는 모든 연산들은 differentiable하기 때문에 backprop이 가능하고 이로인해 network가 알아서 decoder의 time step별 input의 어느 state에 attention 해야하는지 학습하게 된다.
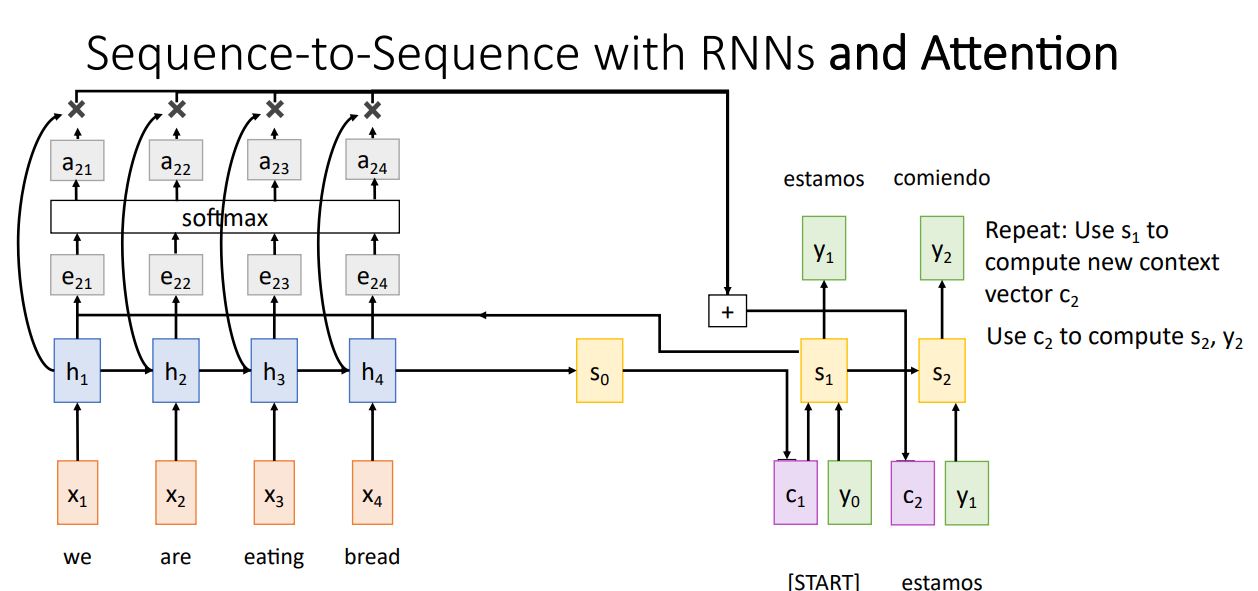
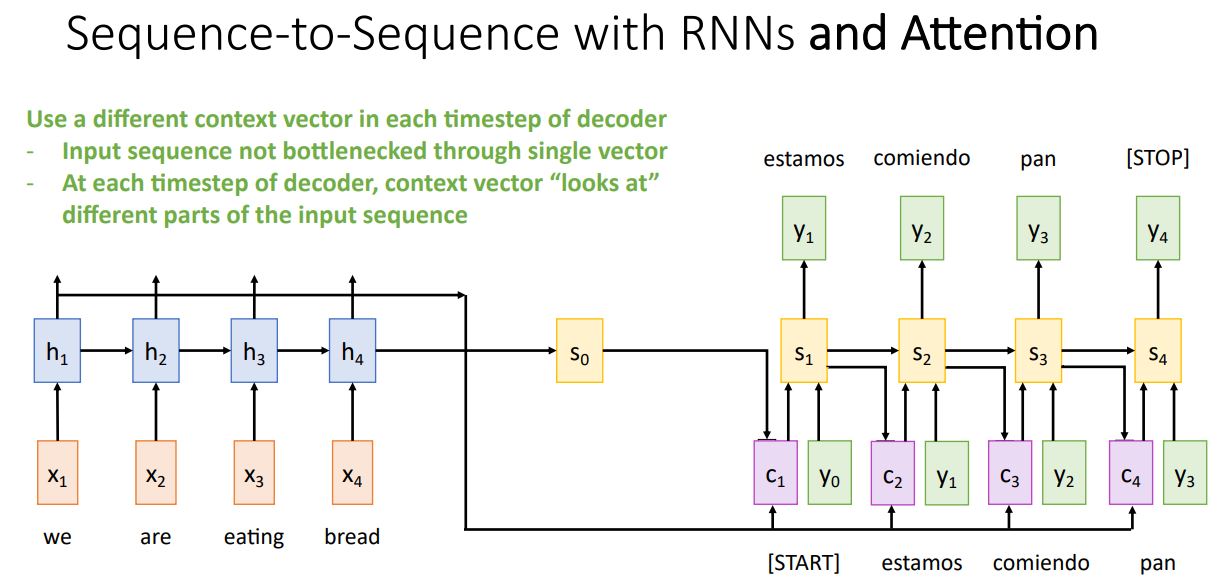
- 이러한 과정을 decoder의 time step마다 반복해서 사용하고 기존의 seq2seq처럼 decoder가 STOP token을 출력하면 멈추게 된다.

- 위 그림은 영어를 프링스어로 번역하는 예시로 seq2swq with attention 모델이 decoder 시점별 단어를 생성해낼 때 attention weights를 나타낸 것으로 모델이 시점별로 input의 어느 state에 집중하고있는지를 보여준다.
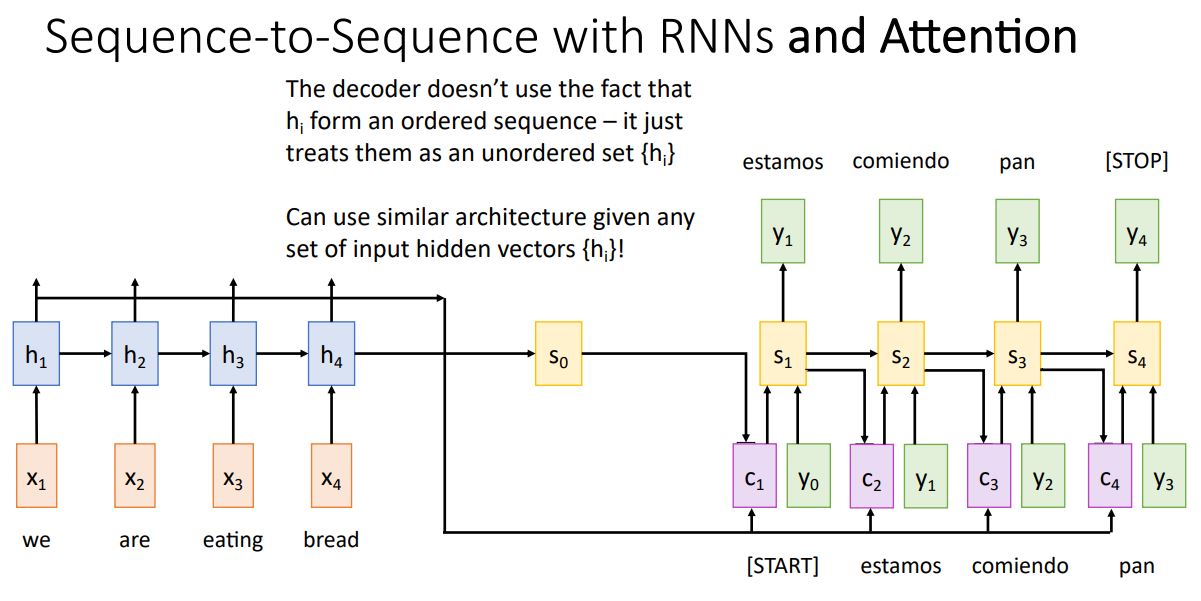
-
지금까지 machine translation에서 사용되는 attetion mechanism은 사실 input에의한 가 ordered sequence인지 상관없고 unordered {} set이면 된다고 한다.
-> Attetion mechanism은 decoder가 어느시점의 input state에 집중할지만 계산하기 때문에 ordered sequence일 필요는 없다. -
이를 통해 seq2seq with attention 모델을 변형하여 input이 sequence가 아닌 {} set에도 사용할 수 있음을 나타낸다.
- 지금까지 살펴본 Attention mechanism은 Bahdanau Attention이고 이 외에도 아래그림과 같이 다양한 Attention mechanism이 있다.

Image Captioning with Attention
- 이전 강의에서 보았던 RNN만을 사용한 image captioning에서 Attention개념을 추가한 모델을 살펴보자.
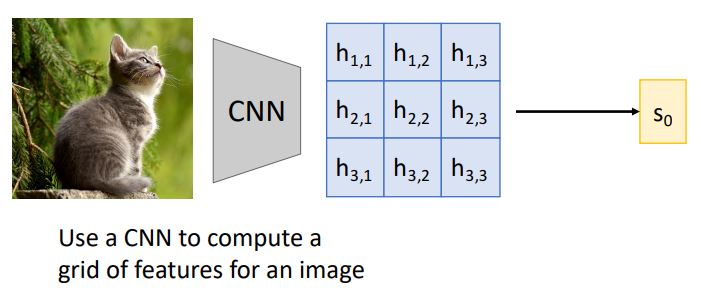
-
일단 RNN만을 사용한 image captioning에서 FC layer를 통한 feature vector(sequece vector)를 RNN모델의 input으로 사용한 것과 다르게 위 그림처럼 CNN에서 grid of feature vectors를 뽑아내 이것을 RNN모델에 input으로 집어넣는다.
-
이때 grid of feature vectors는(~) 각각 spatial position에 해당된다.
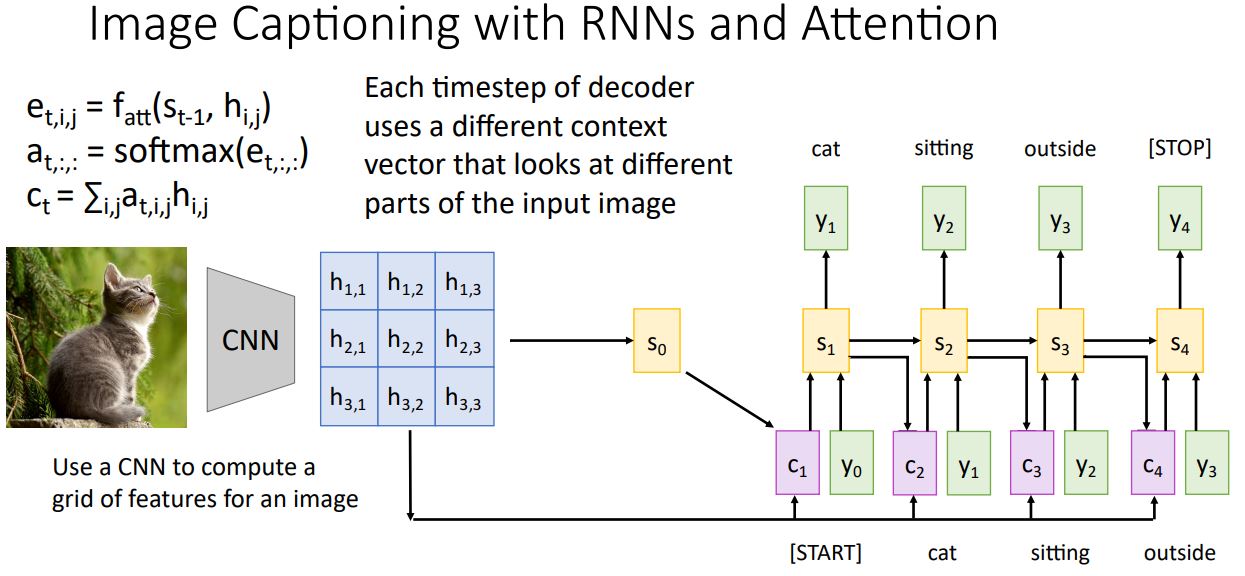
-
Sequence model처럼 현재의 state 를 가지고 alignment function을 통해 alignment score를 계산하고 softmax를 거쳐 attention weights를 생성하고 이것을 hidden state와 weight sum해주어 다음 state의 context vector로 사용한다.
-
Image Captioning에서의 attention은 결국 image caption의 단어를 생성하는 각 time step에서 grid에서 각각의 feature vector들이 decoder의 현재 state인 와 weighted sum시켜 새롭게 context vector를 만든것이다.
-
여기서 다시 중요하게 생각해볼 점은 attention을 통해 softmax를 거친 normal distribution과 grid의 feature vector들 이 가중합되어 context vector로 사용된다는 것이다.
Examples
- Attention을 적용한 image captioning의 예시를 살펴보자.

- 위 그림은 attention을 적용한 image captioning에서 model이 이미지를 받아 “A bird flying over a body of water.”를 출력하는 과정에서 각 state에서 grid의 어떤 vector에 높은 가중치를 보이는지를 시각화 한 것이다.

- 위 그림은 또다른 예시로 문장의 각 단어들을 생성할때 (그림에서 밑줄쳐있는)한 단어를 생성하는 state에서 input image의 어떤 portion에 높은 가중치가 부여되어 attention하는지를 나타낸다.
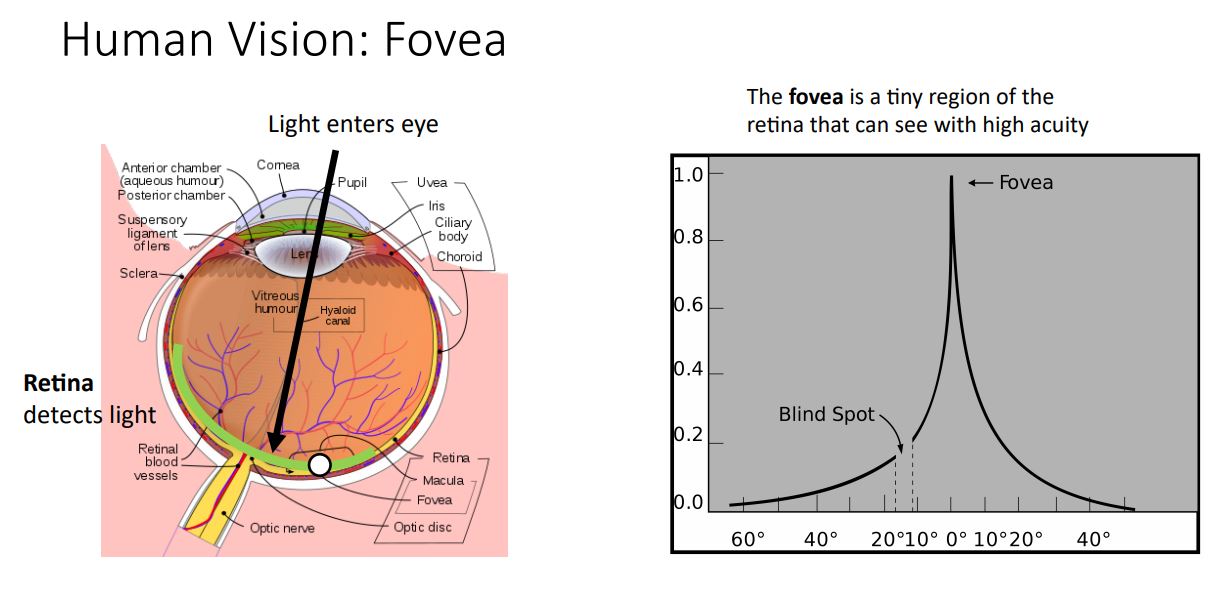
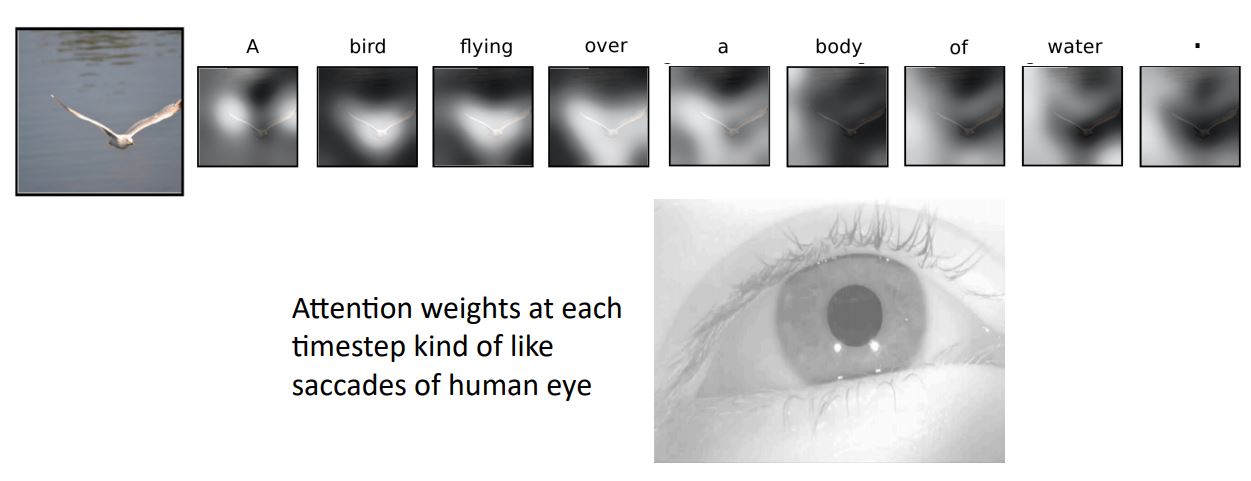
- 이러한 image captioning에서의 attention은 생물학적인 관점으로 보았을때 망막의 fevora라는 영역에 맺히는 상만을 선명하게 볼 수 있는데 이는 초점의 개념으로 생각해볼 수 있고 매 time step별로 빠르게 positional, spatial 가중치가 변화하는 attention과 비슷한 것임을 알 수있다.
Attention Layer
- 지금까지 보았던 attention mechanism을 image captioning, machine translation등 여러 task에 적용시키기 위해 몇개의 step을 거쳐 일반화 시키려고 한다.
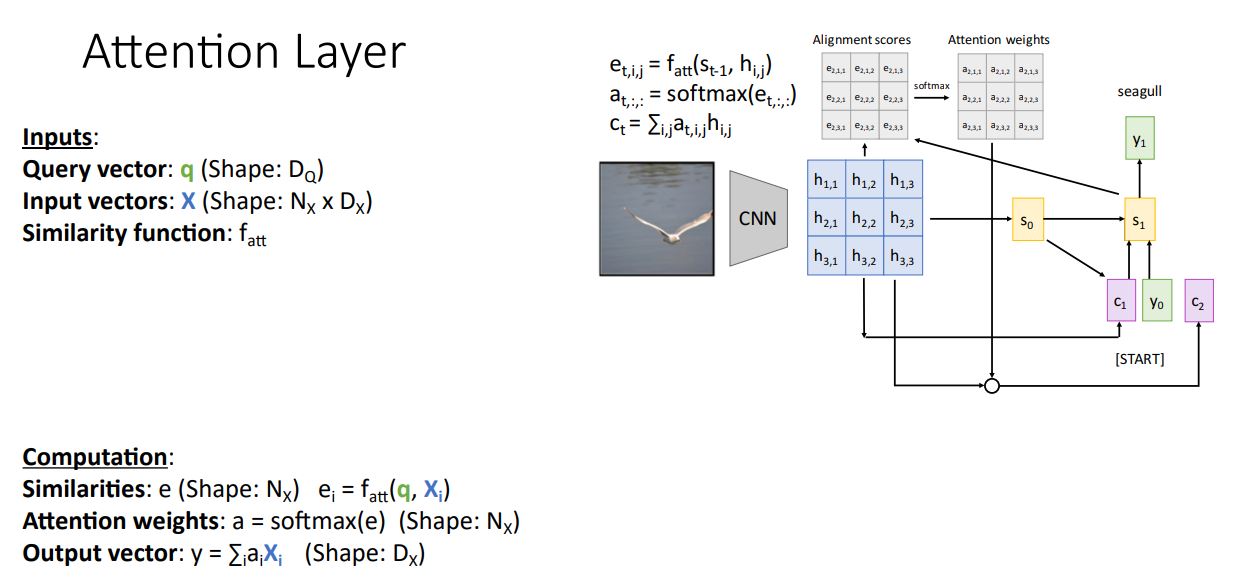
-
"The type of attention mechanism"을 다음과 같은 방식으로 reframe(재정의?)시킨다 (그냥 abstract시키고 일반화 시키기위해 약간만 변형했을 뿐이지 이전에 본 과정이랑 다를바 없다)
- Inputs :
- Query vector : decoder의 현재 시점의 이전 hidden state vector (각각의 들이 t시점의 query vector가 되는것)
- Input Vectors : encoder의 각 hidden state ()의 collection
- Similarity function : query vector와 각 input vector() 를 비교하기 위한 함수.
- Computation :
- Similarites : query vector q와 input vector 를 silimarity function으로 연산으로 이를통해 unnormalized similarity scores를 얻는다.
- Attention weights : silimarity function을 통해 얻은 e를 softmax를 거쳐 normalized probability distribution을 얻는다.
- Output vector : Attention weights와 input vector를 weights sum ->
- Inputs :

-
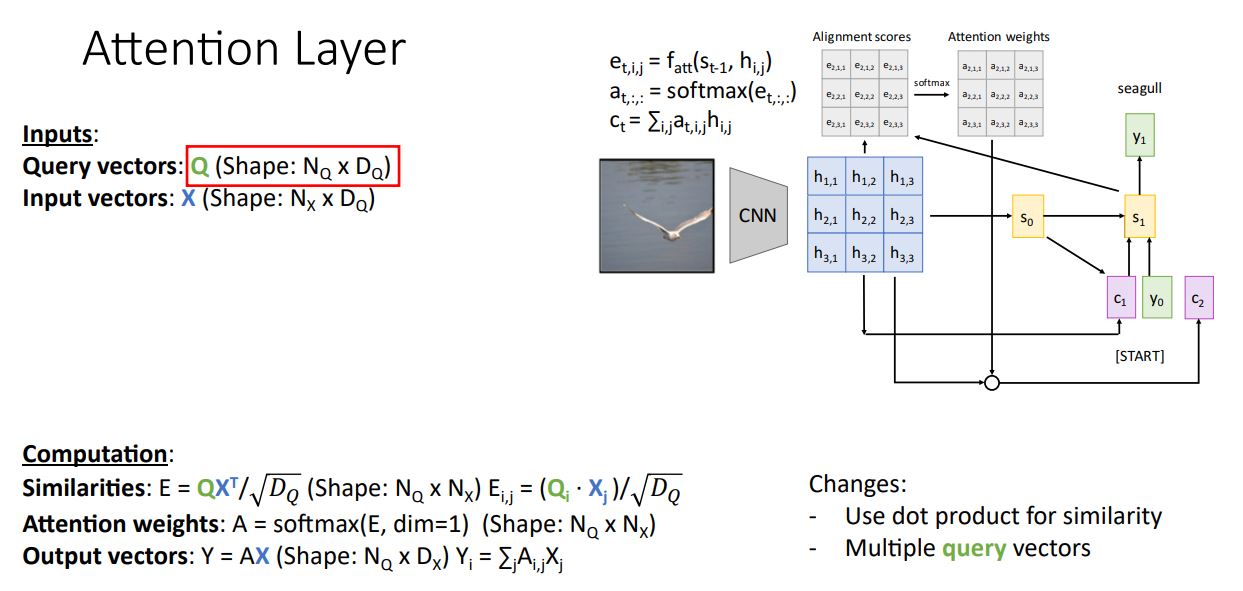
첫번째 generalization 으로 Similarity function을 scaled dot product연산으로 변경하여 matrix multiplication형태로 연산하여 원콤으로 훨씬 효율적으로 연산한다.
- 이때 그냥 dot product와 다르게 sqrt()를 나누어주게 된다. (이때 는 input vector 와 query vector 의 dimension 이다)
-
Scaled dot product를 사용하는 이유는 similarity scores 를 softmax에 input으로 넣게되는데 가 클 수록 즉, 두 벡터의 차원이 클 수록 gradient vanishing문제가 발생하기 때문이다.
- 쉽게 말하면 그냥 Xavier initialization마냥 일반화 시켜준것이다. (만약 한 시점의 한 가 매우 크게되면 e가 softmax를 통과해 i지점에서만 매우 높게 솟은 형태가 되기에 그 부분을 제외한 다른 지점에서의 gradient가 0에 가깝게된다.)
- 또한 듀 벡터가 high dimension을 가질경우 dot porduct결과 매우 큰 values를 갖을 수 있기 때문에 scaling시켜주는 것이다.
-
두번째 일반화 과정으로 multiple query vectos를 허용하는 것 이다.
-
기존에 single query vector 를 input으로 받던 것을 set of query vector 로 받아 모든 similarity socores를 single matrix multiplication operation으로 모든 연산에서 simultaneously하게 원콤으로 계산
- , ,
-
-
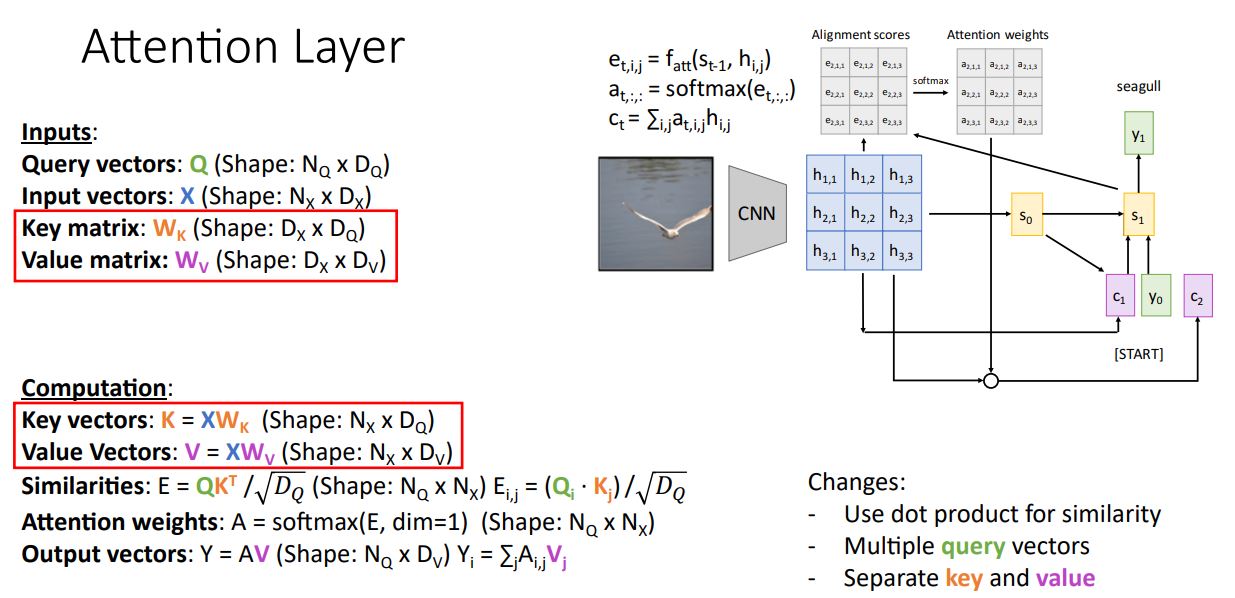
세번제 일반화 과정은 similarity와 output을 계산할때 동일하게 사용되던 input vector 를 각각 Key vector 와 Value vector 로 분리하는 것이다.
-
Input vector 를 Key vectors , Value vectors로 분리하기 위해 X에 와 matrix를 통해 transform시켜주는데 이때 와 는 learnable matrix이다.
-
위 그림의 수식에서 볼 수 있듯이 key vector 를 similarity연산에 적용시키고 () value vector 를 output연산에 적용시킨다().
-
이러한 key,value분리는 model이 좀더 유연성을 갖게한다.
-
좀더 직관적인 예로는 구글에 엠파이어 스테이트 빌딩의 높이를 검색했다고 했을때 이 엠파이어 스테이트 빌딩의 높이가 query가 되고 이에대한 웹페이지들이 output이 되는데 이때 query에 의한 silimarity와 output data는 "sepearate piece of data"이므로 이 둘을 분리하였다.
-> 예시를 들으니 더 햇갈린다...
-
-
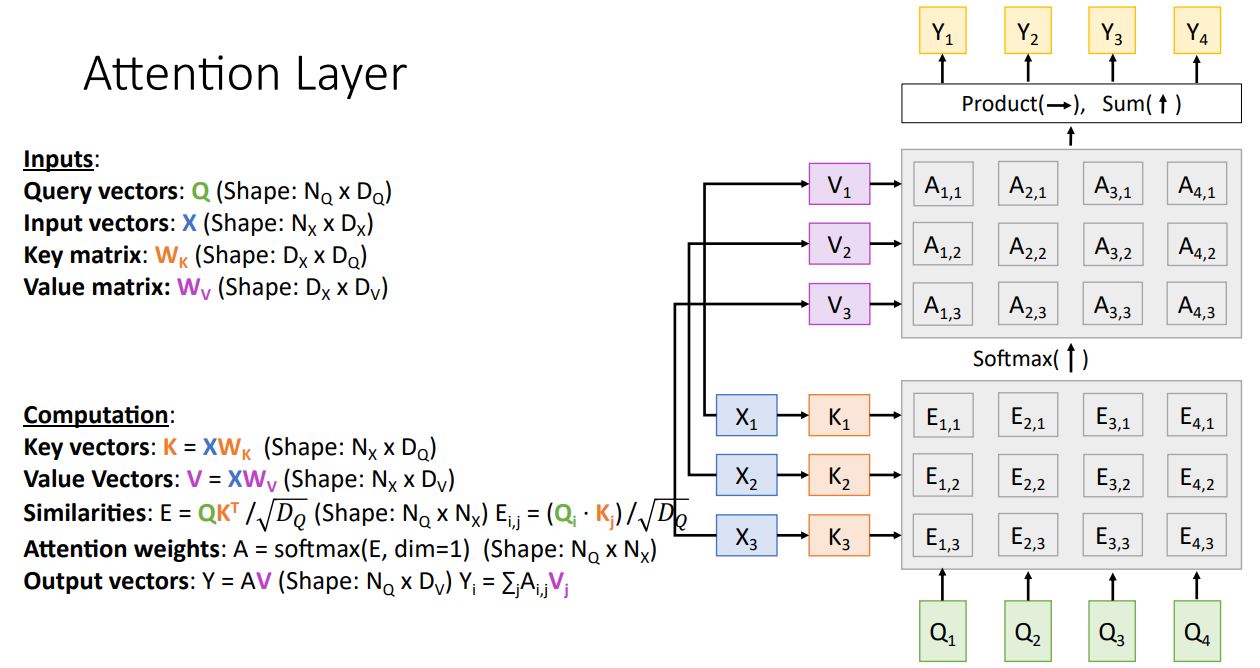
지금까지 살펴본 변경사항들을 적용한 일반화된 Attention layer는 다음과같은 그림으로 원콤으로 동작한다.
-
이때 query에 대해 key vector와 연산하여 그림에서 vertical하게 들이 softmax를 거치게 되어 들로 각 input 에 대한 probability distribution (column of alignment matrix)을 생산하게 된다.
-
그리고 를 통한 weights sum 연산으로 각 query vector 에 대한 output vector 를 생산하게 된다.
-
* 그럼 일반화시킨 attention layer에서 쿼리벡터 갯수는 혹은 Key, Value벡터 수는 고정인가? 아님 하이퍼파라미터로 사용되나??? 나중에 알아보자~
Self-Attention Layer
- Attention Layer의 특별 case인 Self-Attention Layer는 input set을 입력으로 받아 각 input vectors끼리 비교하는 형태이다.
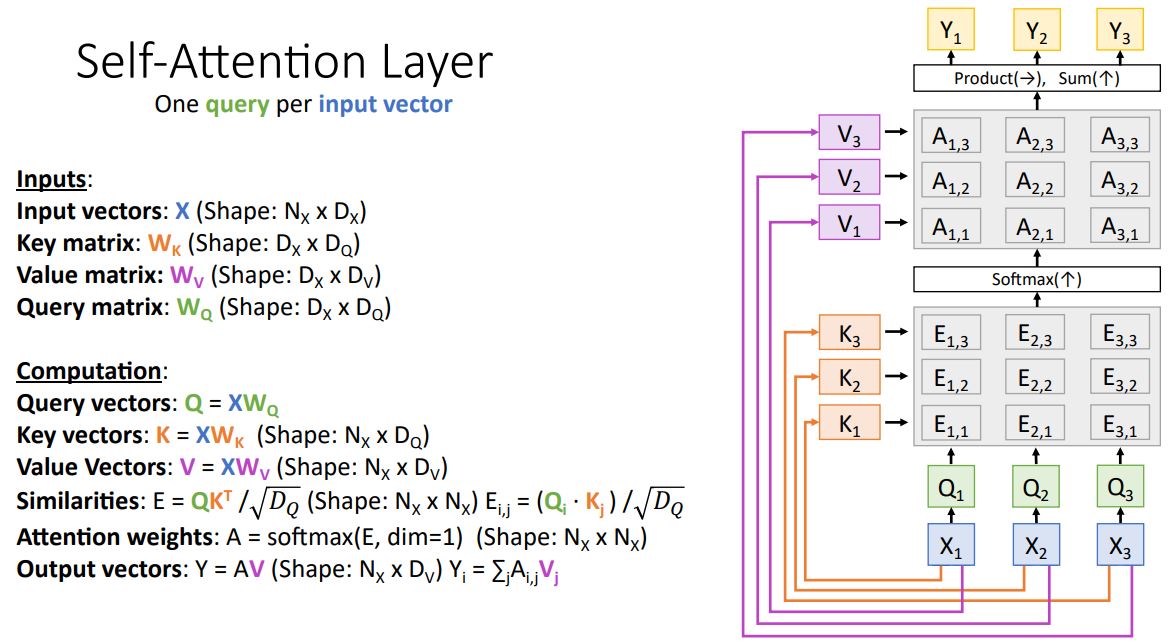
-
Attention Layer에서 input vector를 weights matrix를 통해 transform시켜 key vector, value vector를 뽑아낸 것 처럼 query vector를 input으로 받는 대신에 또 다른 weights matrix를 통해 input vector query vector로 transforming 시켜준다.
-
나머지 메커니즘은 이전의 Attention Layer와 동일하다.
-
이러한 Self-Attention Layer에서 input vector의 순서를 바꾸는 permuting을 적용해 볼 수도 있다.
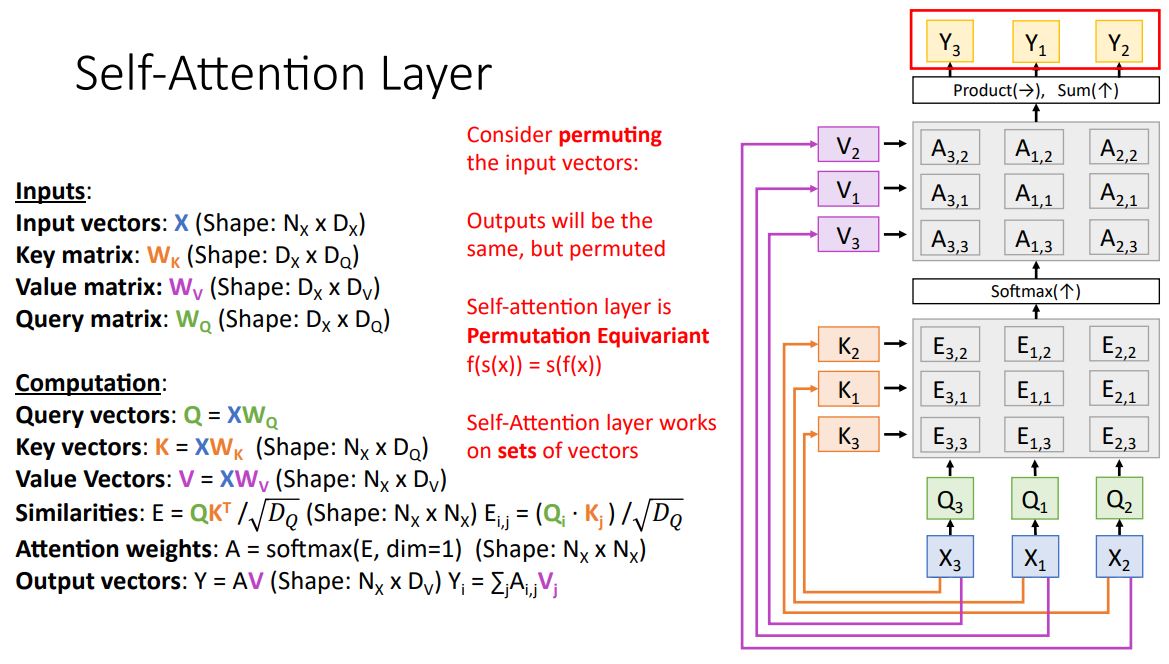
-
Input vector를 permuting시키게 되면 query, value, output의 각 vector는 동일하지만 permute된 형태이다.
-
이때 Self-Attention Layer는 permutation equivalent라고 할 수 있고 s()를 permutation, f()를 self-attention이라고 하였을때 다음과 같은 식으로 표현된다.
-
이러한 결과를 통해 Self-Attention Layer는 input의 순서에 영향을 받지 않는다는것을 알 수 있다.
- 단지 set of vectors를 input으로 input vectos끼리 서로 비교하여 또다른 set of vectors를 출력하는 것 이다.
-
하지만 machine translation, image captioning task와 같이 몇몇 경우엔 intput vector의 순서를 알아야 한다.

-
기본적으로 permutation으로 순서가 바뀐 input은 model이 각 inputt vector의 순서를 모르기에 어떤 유용한 signal을 통해 model에게 각input vector의 position을 알려줘야한다.
-
이때 positional encoding을 통해 input vector에 position 정보를 추가하게된다.
-
"Attention is all you need" 논문에서는 다음과같은 positional encoding을 제안하였다.
-
위 식을 통해 각 positional encoding의 각 dimension은 sinusoid에 대응되며 파장은 2 부터 10000*2까지 기하학적 수열의 형태를 갖으며 cos, sin함수를 나누어 사용하였기 때문에 모델이 상대적인 position을 학습하기 쉬워진다고 논문에서 말한다.
- 다시말해 어떠한 pos의 vector를 linear transform을 통해 pos + ϕ 로 표현할수 있다는 것이다.

-
Self-Attention Layer의 또다른 변형 버전인 Masked Self-Attention Layer은 모델이 과거 정보만 사용하도록 강제하는 것이다.
-
이는 language model에서 현재 시점의 예측에서 현재 시점보다 미래에 있는 token들을 참고하지 못하도록하기 위함이며 이를 "Look-ahead mask"라고 한다.
-
위 그림처럼 Similarity Matrix E에 를 집어넣어 softmax를 통해 Attention Weight Matrix A에서 해당 position값이 0으로 설정되게 하여 해당 position정보룰 참고할 수 없게 하는 것이다.
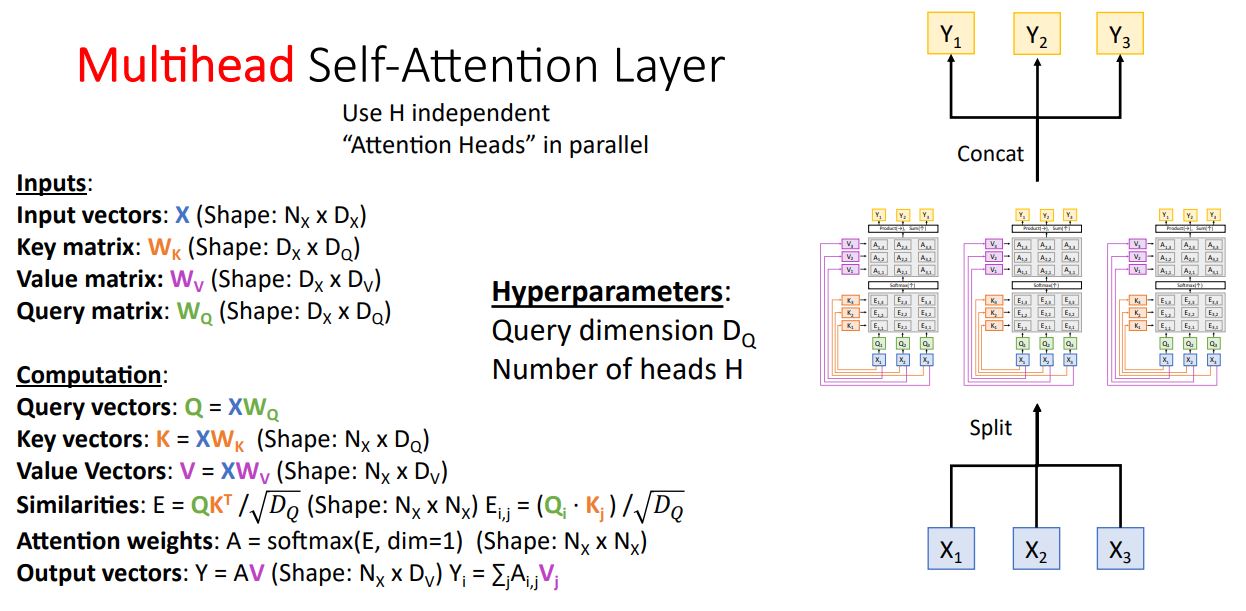
-
Self-Attention Layer의 또다른 변형 버전인 Multihead Self-Attention Layer은 위 그림처럼 H개의 Self-Attention Layer를 독립적으로 병렬로 처리하기위한 방법이다.
-
논문에서는 Multihead Self-Attention을 다음과같은 식으로 나타내었다.
- Multihead Self-Attention Layer는 Query dimension , Num of head H 두개의 하이퍼파라미터를 갖는다.
Example: CNN with Self-Attention
- 지금까지 살펴본 Self-Attention Layer를 CNN에 적용시킨 예를 살펴보자.
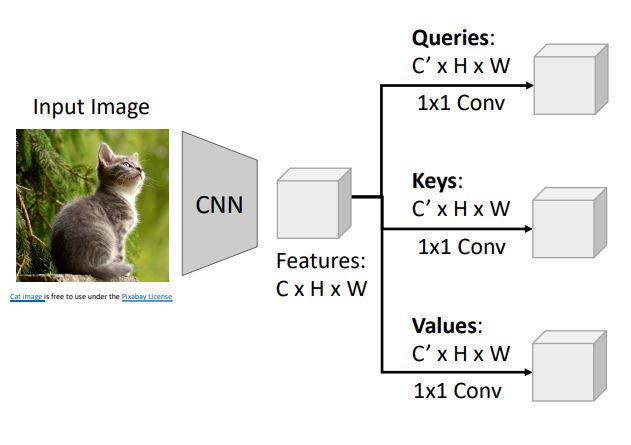
-
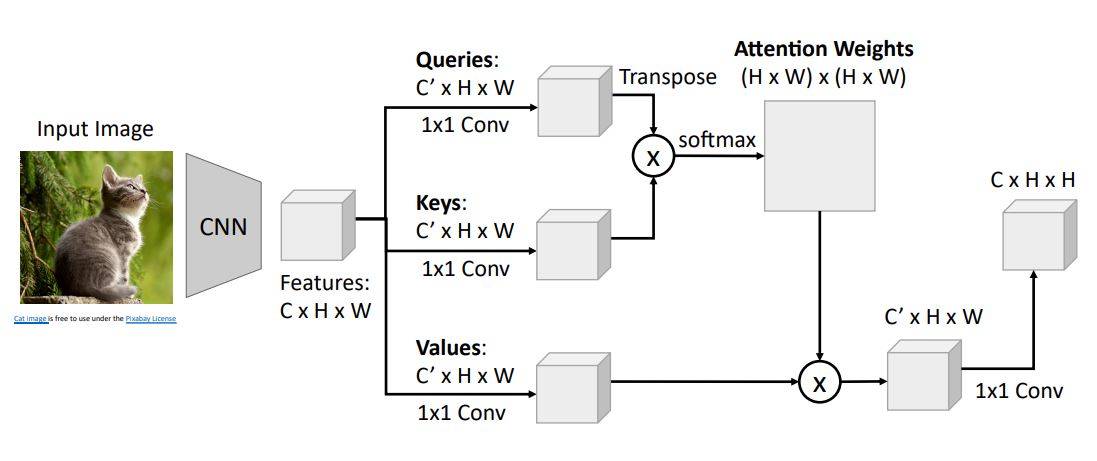
우선 이전 image captioning에서 처럼 CNN을 통해 image에서 CxHxW size의 feature vector를 뽑아낸다.
-
추출한 feature vector를 1x1 convloution시켜 grid of Queries, grid of keys, grid of Values러 변환시킨다. 이때 각각의 weights를 가지고 병렬적으로 1x1 conv시킨다.
-
그리고 생성된 Queries와 Keys를 inner product시킨후 softmax를 거쳐 (HxW)x(HxW) 사이즈를 갖는 Attention weights를 생성한다.
- 이때 이 Attention weights의 각 position은 input image에서 다른 position보다 얼마나 더 집중하기를(attend 할건지) 원하는지를 나타내게 된다.
-
다음으론 이 Attention weights와 Value vectors의 weighted linear
combination을 통해 C'xHxW size의 new grid of feature vector를 생성한다.- 이때 new grid of feature vector의 모든 position의 feature vector는 input vector의 모든 position의 feature vector에 의존적이게 된다.
-
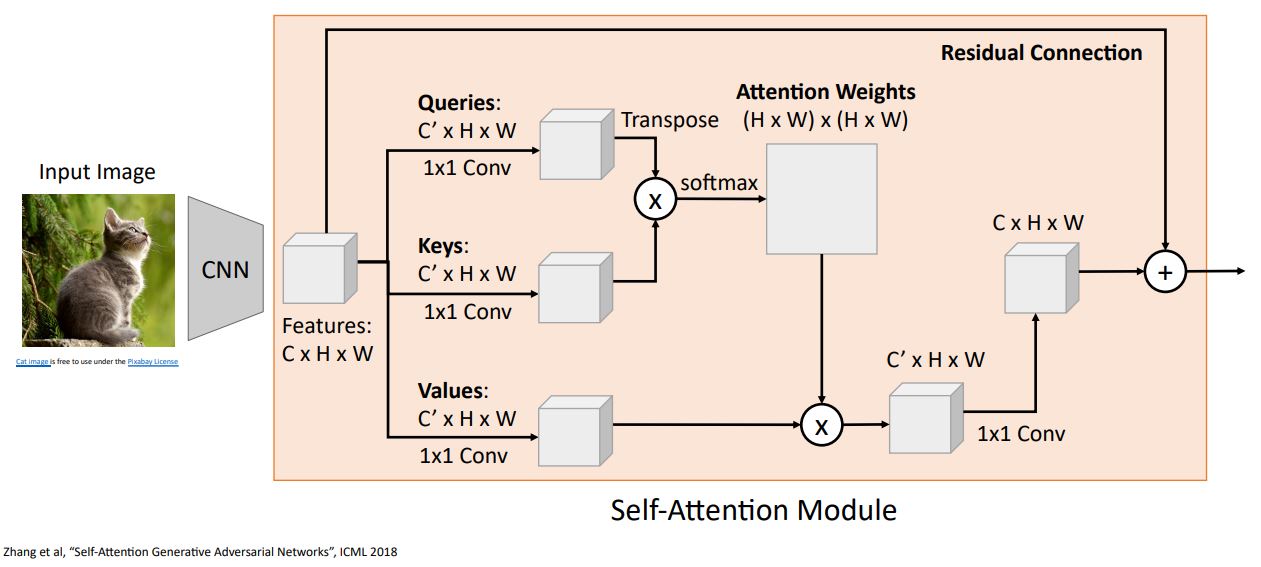
그리고는 또다른 1x1 convolution을 통해 input feature와 channel dimension을 맞춰주게 된다.
-
또한 Residual Connection을 적용시켜 효율성을 높힐 수 있다.
-
이러한 모든 과정을 하나로 모아 위 그림처럼 self-attention module로써 neural net에 하나의 layer로 stacking할 수 있게된다.
Three Ways of Processing Sequences
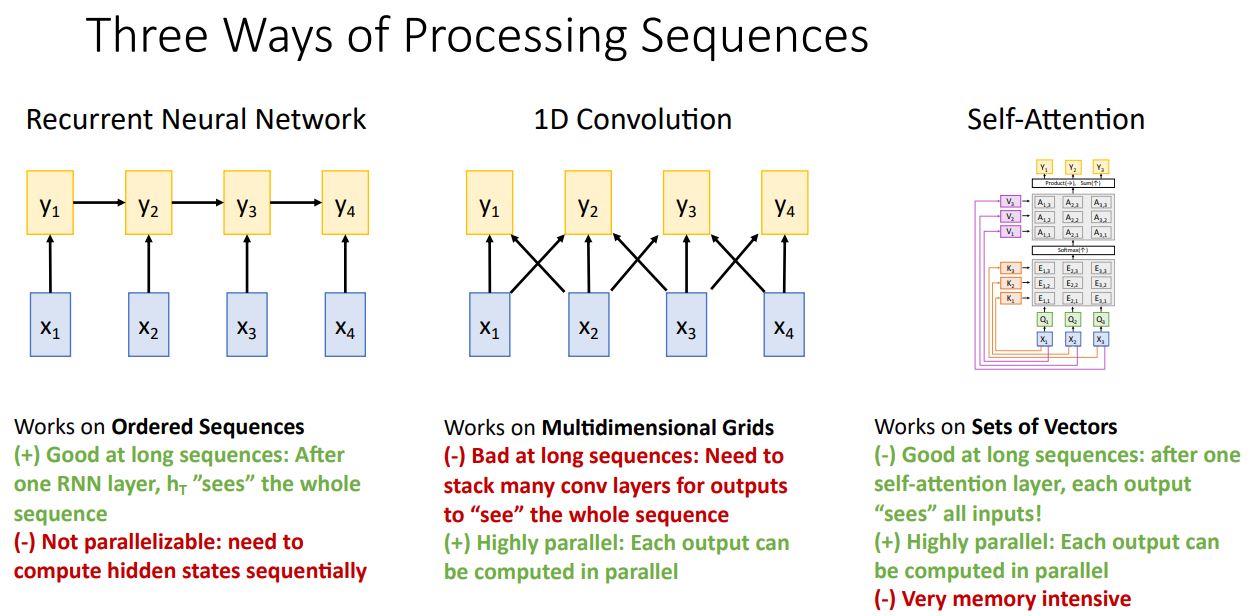
- Sequences of vectors를 처리히는 3가지 다른 primitives 방법들의 장단점을 살펴보며 비교해보자.
-
- Recurrent Neural Network(RNN)
-
RNN의 final hidden state or output 는 input sequence 전체에 영향을 받기 때문에("depend on the entire input sequence") input sequence에 대해 일종의 summarize를 한다고 생각할 수 있으며, LSTM과 같은 경우 long sequence를 다루는데 용이하다.
-
하지만 RNN의 기본 메커니즘상 input sequece를 time step마다 순환하며 를 계산하는 시스템이므로 GPU를 통한 병렬화가 불가능하다.
-
- 1D Convolution
-
1D Convolution은 (output 를 계산하기 위한) 각각의 kernel들을 독립적으로 연산할 수 있어 병렬화가 가능하다.
-
하지만 1D Convolution은 위 그림처럼 output 가 3개의 local(adjacent) input에 영향을 받으며 RNN처럼 output이 input sequence전체에 depend on 하기 위해서는 여러개의 layer를 쌓아야 하며 (sequenctial dependency를 깨트린다는 소리)
이것은 long sequence의 input에 그다지 좋지 못한 상황이다. (CNN에서의 receptive field개념으로 생각해보자)
-
- Self-Attention
-
새로운 메커니즘인 킹갓제네럴 Self-Attention은 위 두가지 방법의 단점을 모두 극복하였다.
-
한 input vector set이 주어졌을 때 각 vector들 끼리 qeury하여 비교하므로 각 output은 각 input들에 영향을 받는다 ("each output depends on each input") 그렇기에 long sequence를 다루기에도 좋다.
-
또한 Self-Attention Layer는 단지 몇개의 matrix multipliers + 하나의 softmax operation으로 이루어져 있기에 highly highly paralyzable하다. 이는 GPU연산에 매우 적합하다.
-
- 그렇다면 위 3개지 메커니즘을 조합해 더킹갓엠페러제네럴충무공마제스티 모델을 만들 수 없을까??

- “Attention is all you need"가 다 해결해줍니다~
The Transformer
- 위 “Attention is all you need" 논문은 Self-Attention만 사용하여 transformer block 이라는 새로운 primitive block type을 제시하였다.
![]()
-
input을 sequece로 받아 self-attention을 거치고 residual connection을 합친 Multi-head인 Self-Attention Layer는 이전에 보았던 것과 같다.
-
Transformer에서는 Layer Normalization이 추가되는데 이는 일종의 BN으로서 각각의 output vectors들에대해 독립적으로 normalization해주는 형태이다. 이전 강의에서 슬라이드를 참고하여 쉽게 이해해볼 수 있다.
- Transformer는 또한 위 그림처럼 MLP(multi-layer perceptron(FC-layer))을 Layer Normalization의 output set에 대해 독립적으로 수행하는 Feed Forward Neural Networks가 츄가된다.
![]()
-
위에서 살펴본 과정을 하나의 block으로 나타내어 위 그림처럼 transformer block
으로 사용된다. -
Transformer의 Self-Attention Block의 가장 중요한 특징은 Self-Attention Layer에서만 input vectors간 interaction이 행해지고 Layer Normalization과 MLP에서는 각 vectors들이 독립적으로 처리된다는 것이다.
-
이러한 특징 덕에 highly parallelizable하며 amenable to GPU 하다.
![]()
-
Transformer는 위의 Self-Attention Block을 쌓아서 sequence하게 사용한다
-
이때 모델의 depth(num of blocks)를 나타내는 D와 multi-head수를 나타내는 heads 를 hyperparameter로 사용할 수 있다.
![]()
- Transformer는 NLP에서 vision분야의 ImageNet과 같은 Moment를 보여왔으며 pretraining & finetuning을 수행하는 basic architecture가 되었다.
![]()
-
위 그림과 같이 Transformer를 기반으로 더 deep한 모델들이 연구되었으며 이를통해 나온 model중 BERT, GPT, Megatron같은 것들이 있다.
-
위 그림에서 볼 수 있듯이 layer를 많이 쌓고 큰 qeury를 사용하여 파라미터 수를 늘리고 더 큰 multi-head를 사용 할 수록 모델을 학습시키는 시간과 비용이 비싸지지는 것을 볼 수 있다...
