[EECS 498-007 / 598-005] 7. Convolutional Networks

Intro...
-
이전까지 보았었던 linear classifier와 neural network model은 pixel값들을 flat하게 펼쳐 연산하였기 때문에* image 의 spatial structure까지 다루지 못한다는 문제점이 있었다.
-
이 전 강의에서 보았던 matrix valued backprop도 matrix form으로 연산을 하지만 결국 flat한 것과 다를바없어 spatial feature를 커버하지 못한다.
-
이러한 문제를 해결하고자 fully connected neural network에 새로운 operator를 정의하여 2-dimentional spatial data인 image에 적용하려 한다.
Convolutional Network
- 우리가 이 전에 보았던 Fully-Connected Network는 크게 두 가지 구조로 나뉘는데 input vector와 matirx multiply를 해주어 ouput vector를 내놓는 "Fully-Connected Layers" 와 non-linear한 data를 linear하게 transform취해주는 "Activation Function" 으로 구성되어 있었다.

- Convolutional Network 에서는 computational graphs에서 사용되는 몇가지의 operation으로 구성되어있다. 이러한 몇가지 operation은 Fully-Connected Network를 Convolutional Network형태로 변환시켜준다. 이 operation들은 다음 그림과 같다.
Fully-Connected Layers to Convolutional Layers
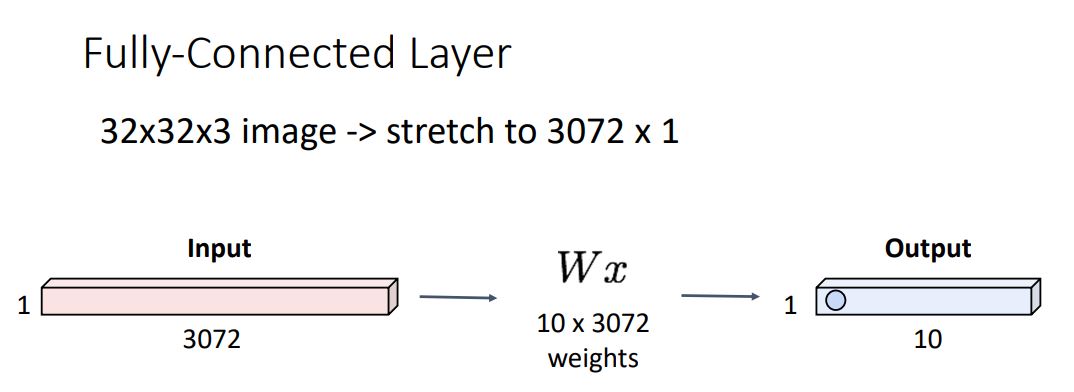
- 위 그림처럼 이전에 보았던 Fully-Connected Layers의 forward pass과정에서 (CIFAR-10 image로 예를 들었을때) 32x32x3 image를 3072개의 scalar element를 갖는 vector로 펼쳐 각 class의 weights matrix와 multiplication해주어 output vector를 뽑아내는 형태였다.

- Convolution layer의 input은 더이상 flattened vector를 사용하지 않고 위 그림과 같이 image matrix와 같은 form인 3-dimensional tensor를 사용한다.
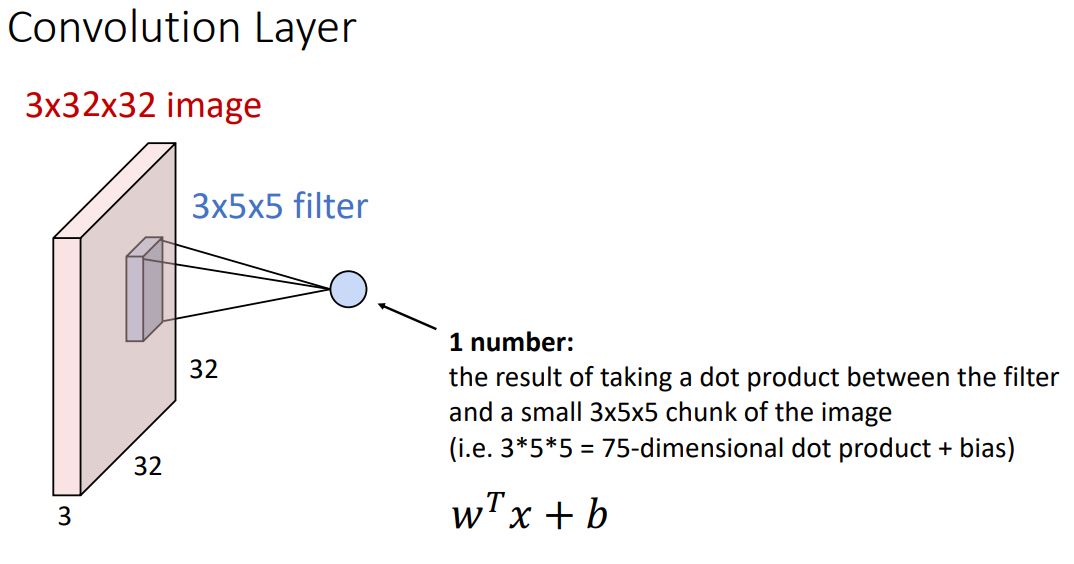
- Weight matrix는 일종의 3-dimensional spatial structure를 갖는데 이러한 weight matrix를 filter 라고 한다. 이때 filter는 input image와 같은 크기의 channel을 갖고 image의 모든 spatial position을 돌아다니며 dot product 연산을한다.
-
이러한 image의 spatial position에서의 filter를 통한 연산은 filter의 크기와같은 75-dimensional(vector) dot product + bias 형태로 하나의 scalar를 optput울 출력한다. 이때 output은 해당 position에서 input image가 얼마나 filter와 일치하는지를 나타낸다.
-
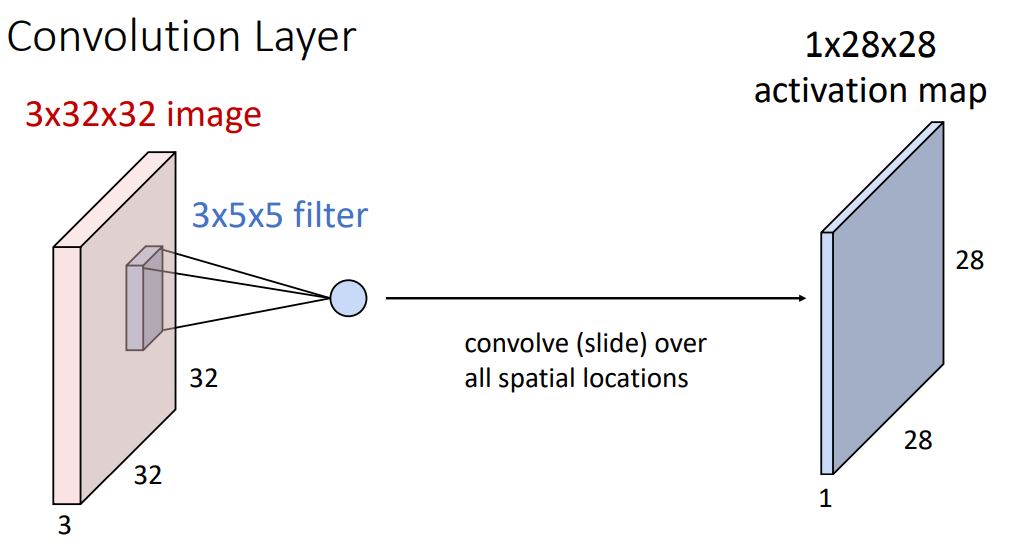
위와같은 연산을 모든 가능한 input spatial postion을 돌며 single number를 생산해내어 1x28x28 크기의 activation map이라는 optput을 뽑아낸다.
- 물론 하나의 convolutional filter만 사용하는 것은 충분치 않기에 아래의 그림처럼 여러개의 서로다른 fliter를 사용하여 filter 수 만큼의 activation map을 만들어 낼 수 있다.
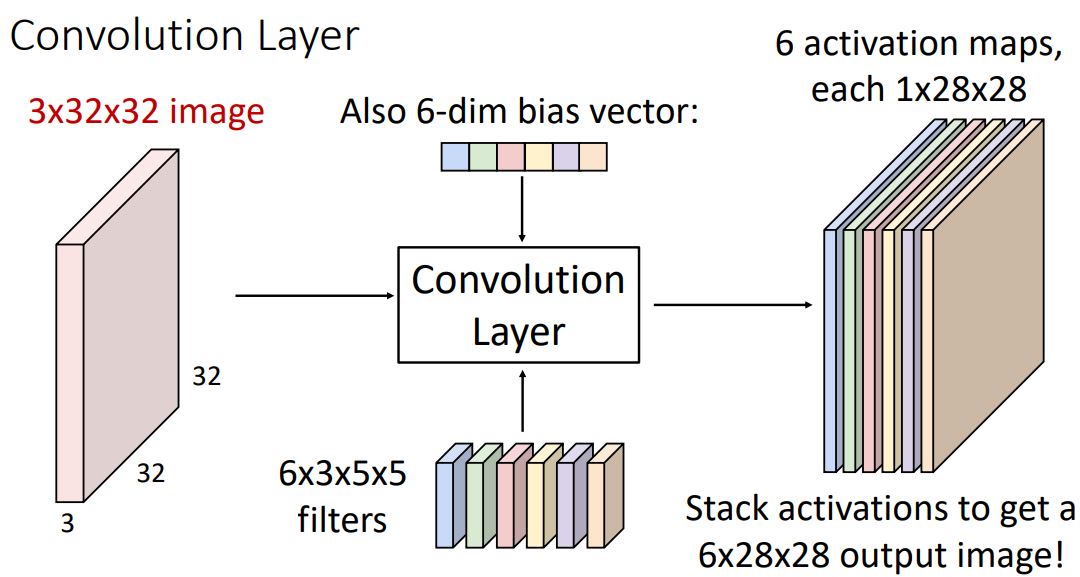
-
이러한 각각의 activation map은 input image의 각 spatial position이 얼마나 각각의 filter에 영향을 받았는가를 나타낸다.
-
이때의 activation map들을 concatenate시켜 하나의 (depth dimension이 3인) 3-dimensional tensor로 나타낼 수 있으며 그림의 예시같은 경우 6x28x28형태를 갖게된다.
-
이러한 output을 또 다른 관점에서 본다면 각 point에서 6-dim feature vector를 가진 28x28 gird로 생각해 볼 수도 있다.
-
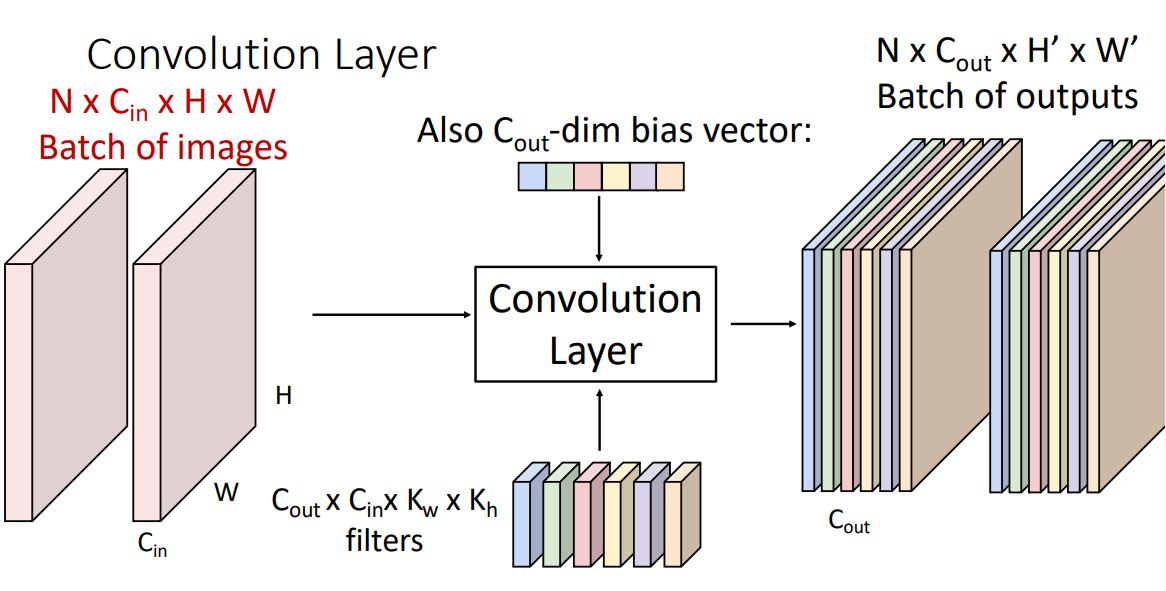
위와같은 input을 위의 그림처럼 batch로 사용할 수도 있다. 이때의 input image, filter, outputs는 4-dimensional tensor가 된다.
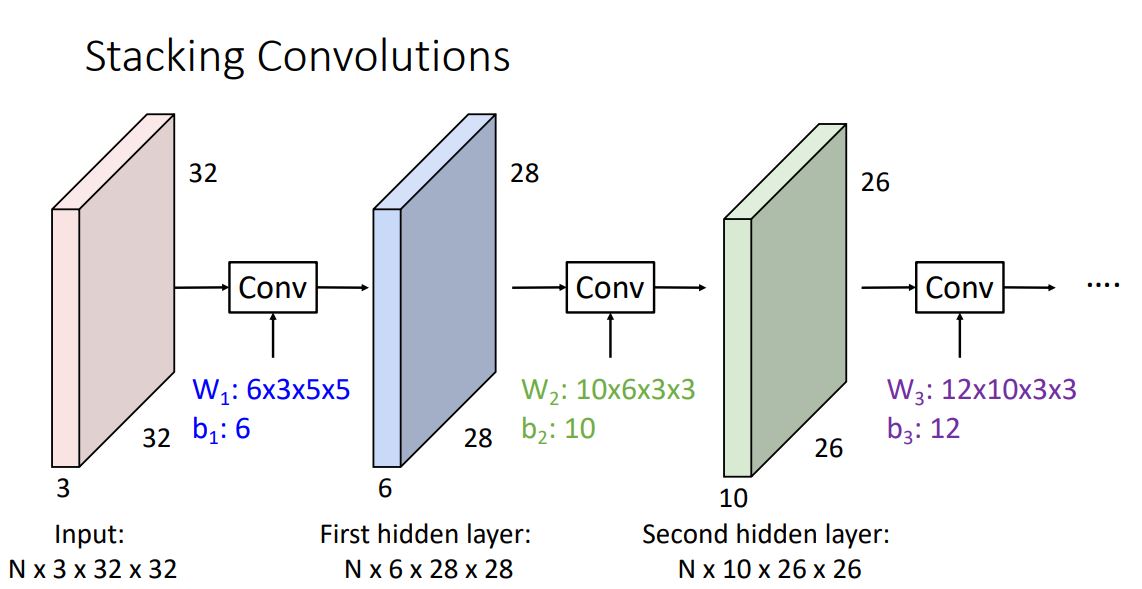
- 이전에 보았던 fully-connected layer가 아닌 convolution layer를 sequence하게 stacking하여 새로운 convolution neural network를 만들어 낼 수 있다.
-
위 그림 처럼 각 conv layer에있는 kernel(filter)의 수 만큼 output이 나오게 되며 이는 다음 layer의 inout으로 들어가게 되는 형태이다.
-
이때 각 layer의 input과 output이 되는 activation map 들은 fully-connected network에서와 같이 hidden layer라고 말한다.
-
하지만 이런 형태의 convolution network는 각각의 convolution operator가 fully-connected network에서의 각 layer와 같이 linear operator에 지나지 않는다. 그렇기에 우리는 아래의 그림처럼 conv operator 직후에 (non-linear인) activation function을 취해준다.
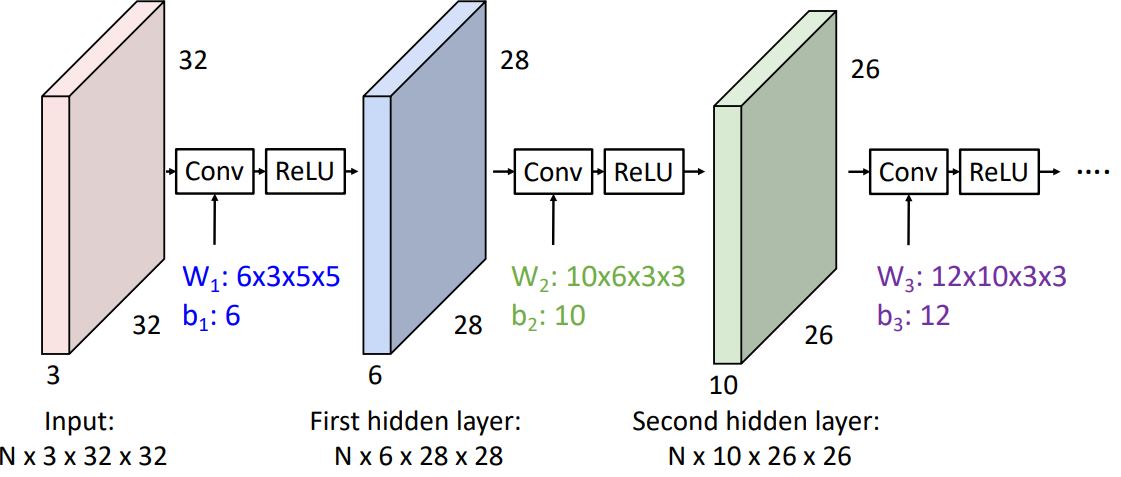
- 이러한 conv network를 이전까지 주구장창 봐왔던 visual viewpoint로 살펴보자.
Visual Viewpoint
1. Linear classifier

- Linear classifier는 클래스별 하나의 weights vector만 가지고있기에 클래스별 하나의 template만 가진 형태로 볼 수 있었다.
2. Fully-connected neural networks

- Fully-connected neural networks의 첫번째 layer만 살펴 본다면
우리가 설정한 first hidden layer의 크기에 대응하는 W1의 크기만큼 여러개의 template을 갖는 (Bank of whole-image templates을 갖는) 형태였다.
3. Convolutional network

-
Convolutional network에서도 비슷한 해석이 가능하다. 위의 그림은 AlexNet의 11x11 RGB image를 학습한 첫번째 layer의 filters이다. 이 각각의 filter들은 oriented edge정보와 opposing color정보등 low-level feature를 학습한 것으로 볼 수 있다.
-
이러한 각각의 filter들은 oriented edge, opposing color로 해석되는 정보를 통해 input image의 각 position이 얼마나 다음 hidden layer에 영향을 미치는 정도를 나타낸다.
-
다른 표현으론 64-dimensional feature vector가 있고 각각의 vector는 하나의 input position에서의 64개의 feature를 학습한 형태로 생각해 볼 수 있다
- 이제 convolutional operation이 어떻게 spatial dimensions에서 작동하는지 디테일하게 살펴보자
Spatial dimensions
<5개 이어붙힌 이미지>
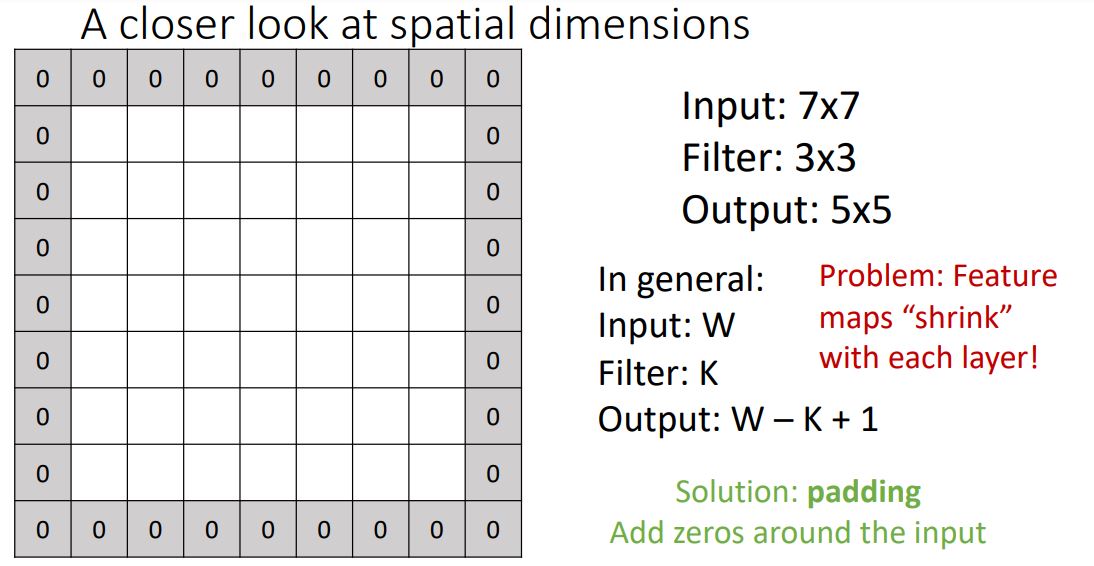
- 위 그림은 7x7 input image에서 3x3 filter가 연산하면서(dot product) 움직이는 형태를 보여준다. 모든 input의 possible spatial position을 vertical, horizontal하게 움직이며 ouput은 5x5형태가 된다.
In general :
-
input size가 W이고 filter size가 K라고 했을때 output size는 W-K+1의 형태가 되는데 이는 input 의 edge(corner) position을 kernel이 커버하지 못하여 매 convolution operation을 거치면서 점점 spatial dimension이 줄면서 pixel의 손실이 일어나 문제가 된다.
-
이러한 문제를 해결하기위해 padding을 image의 테두리에 둘러준다
-
위 그림에서는 zero-padding을 사용한 예시이지만 사용할 image에 따라 다른 형태의 padding을 적용할 수 있다.
-
이 padding은 convolution layer의 추가적인 hyper parameter가 된다. Input image size, filter size, 추가로 stride에 따라 적용할 수 있는 padding size가 정해져있는데 stride개념을 무시했을때(stride가 1일때) 일반적으로 (K - 1) / 2 를 padding size로 사용한다.
Receptive Fields
-
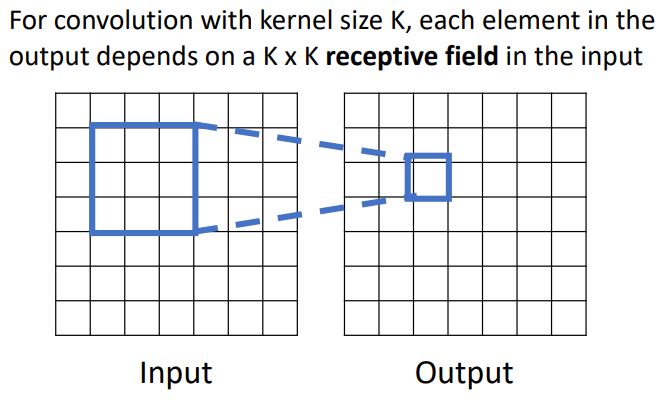
Convolution layer가 무엇을 하는지 생각해볼 수 있는 또다른 방식이 Receptive field 이다. 이는 output image의 각 spatial position이 input image에서 얼만큼의 region에 영향을 받는가를 뜻한다.
-
이를 1-conv layer 관점에서 살펴보면 다음과 같다.
-
위 그림의 예시에선 3x3 region이 receptive field가 된다.
-
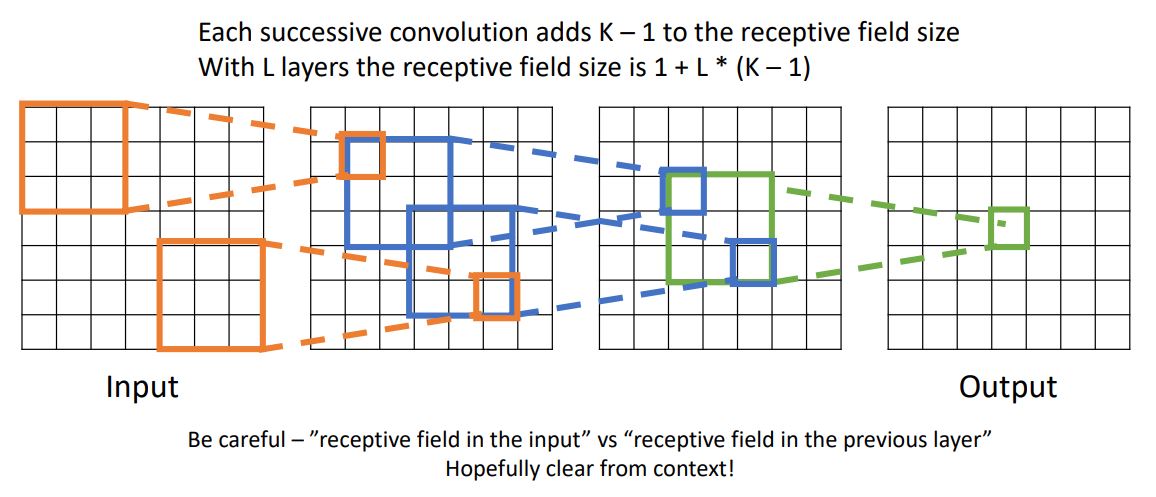
이러한 1-conv layer 를 stacking conv layer관점에서 살펴보자.
-
위 예시는 3-conv layers일때의 receptive field 예시이다. output tensor부터 점점 확장해 나가며 3x3 regin이 5x5 region이 되고 7x7 region이 최종 receptive fild size가 된다.
-
이러한 receptive field size를 1+L*(K-1)으로 계산할 수 있다.
-
하지만 input image의 해상도가 커질수록 그만큼 conv layer가 많아지며 (kernel size가 위와같이 3일경우엔 500개 가량의 convlayer가 필요) output에서 각 spatial position이 매우 큰 receptive field size를 커버한다는 뜻이므로 좋지 않은 형태이다.
-
위와같은 문제를 해결하기 위해 또다른 hyper parameter를 적용하여 downsample을 해줘야 한다.
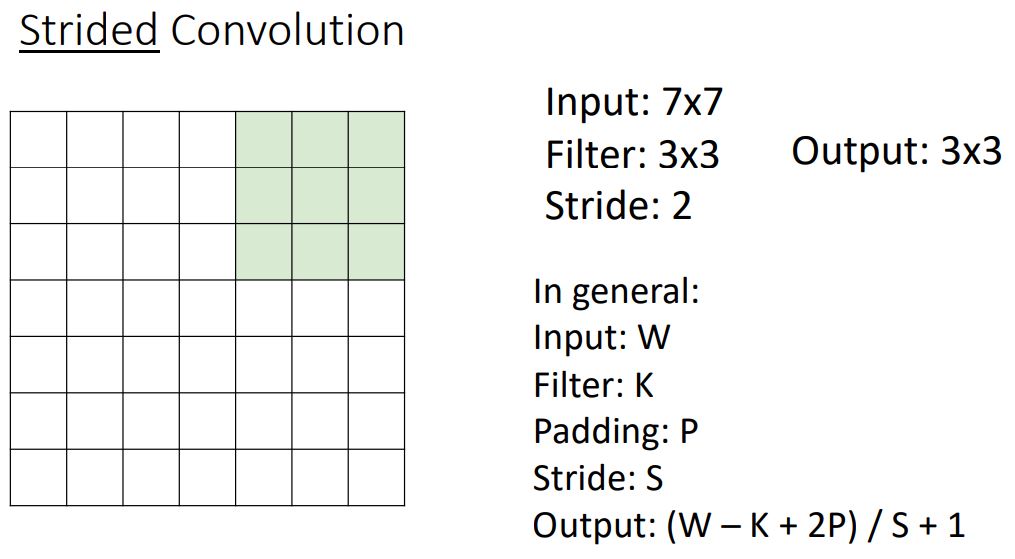
Strided Convolution
<43p 이미지 3개 합친거>
- 그림에서 보다시피 stdide가 2일때 kernel이 두칸씩 건너뛰면서 연산한다. 새로운 hyper parameter인 stride크기에 따라 output size는 다음과 같이 계산된다
Convolution Summary

- 위 그림은 전체적인 convolution summary와 함께 conv layer에서 흔히 사용되는 hyperparameter setting들을 보여준다.
Otehr types of convolution
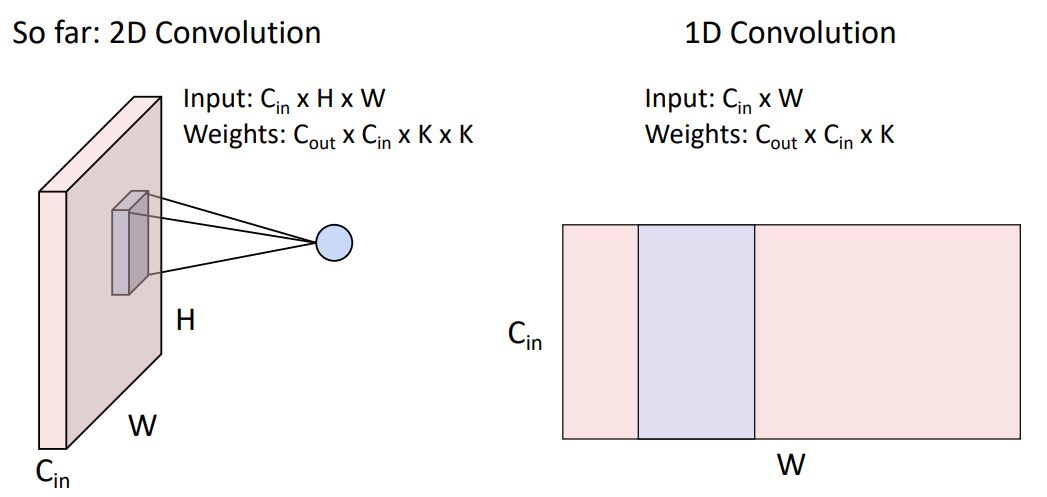
-
우리는 여지껏 2D convolution을 다뤘지만 가끔식 실제로 1D Convolution 형태를 볼 수 있다.
-
1D conv는 2-dimensional input을 갖고 (1-spatial dimension(W)과 num of the channel dimension(C_in)을 갖고) weights matrix는 위 그림의 파란색 영역처럼 C_in x K size의 kernel C_out개를 갖은 형태이다.
-
1D conv는 일반적으로 sequence형태의 textural data와 audio data에 많이 사용된다.
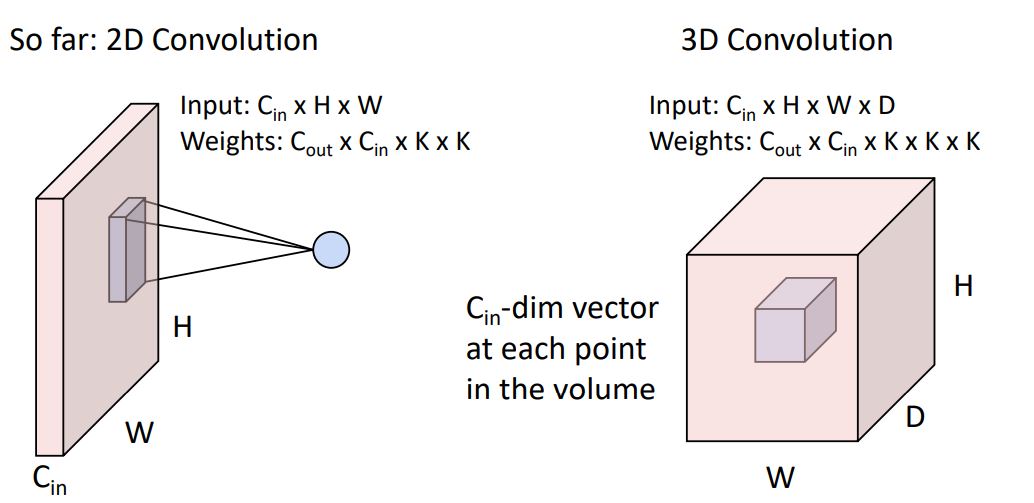
- 우리는 또한 때때로 3D conv를 볼 수 있는데 이는 2D conv에서의 input이 batch형태로 이루어져있다고 생각할 수 있다. 이는 일반적으로 point cloud data 혹은 3d data에 사용된다.
- 우리가 지금까지 다뤘던 convolution layer들이 PyTorch에 Conv1d,2d,3d class로 구현되어있다.

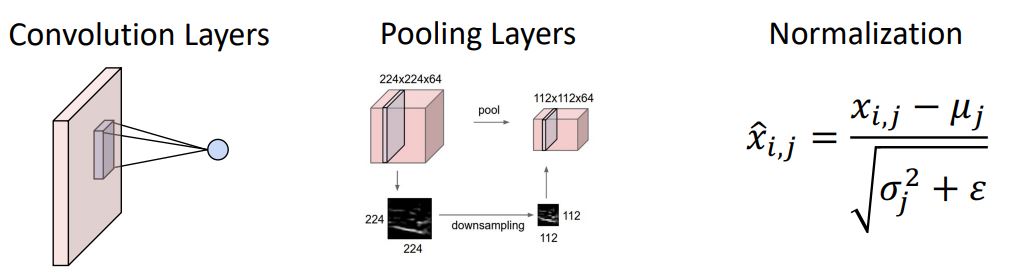
Pooling Layer
- conv network에서 또다른 중요한 요소인 Pooling layer는 이전에 conv layer에서 stride의 역할과 비슷한 또다른 downsample방법이다.
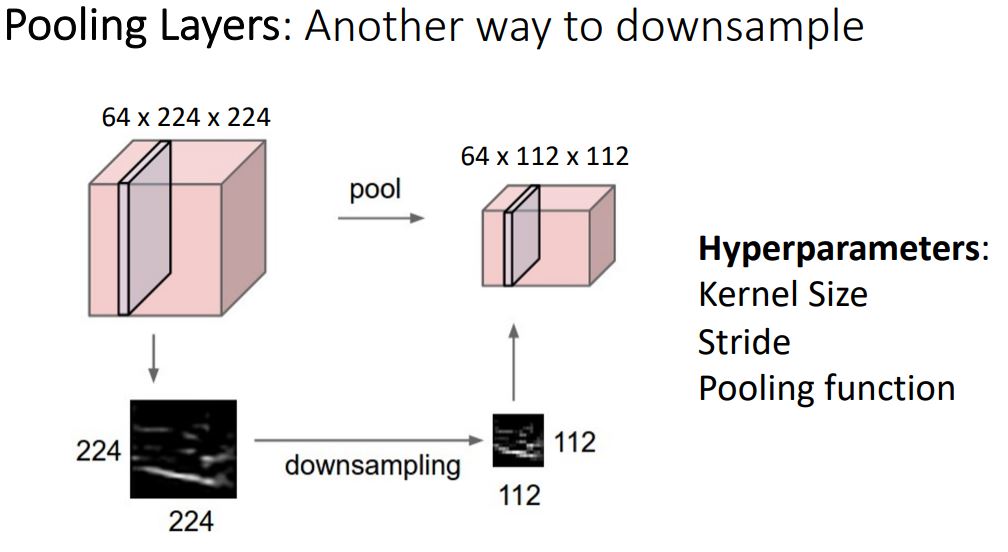
-
이전의 conv layer의 stride와의 다른점은 learnable parameter가 없다는 점이다. pooling layer에서는 hyperparameter로 kernel size와 stride, pooling function만 신경쓰면 된다.
-
간단한 예를 통해 이를 살펴보자.
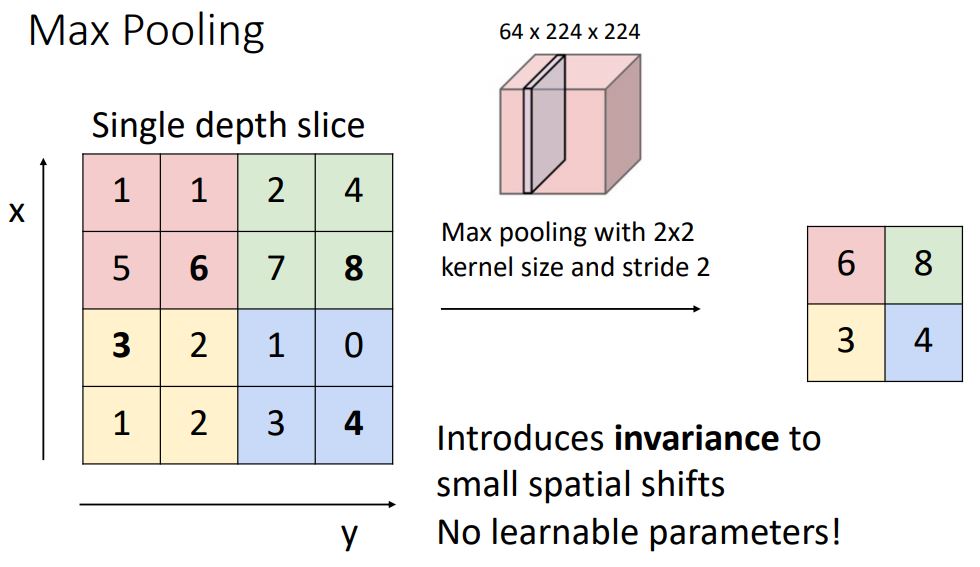
-
위 예시는 kernel size와 stride가 2인 2x2 max pooling을 하는 모습이다. kernel size와 stride가 2로 동일한 이유는 pooling region이 overlapping되지 않게 하기 위함이다 이는 흔하게 사용되는 hyper parameter setting이다. Alexnet에서는 K=3, S=2를 사용한다고 한다.
-
* 위 그림에서 invariance를 입힌다는게 정확히 무엇을 의미하는 지는 모르겠지만 뇌피셜을 말하면 input image가 조금 변화할 경우 pooling kernel의 max값은 영향을 받지 않을 가능성이 크기에 커버가 가능하기 때문인 것 같다.
- 지금까지 본 conv layer와 polling layer를 가지고 classical한 conv net을 만들어볼 수 있다.
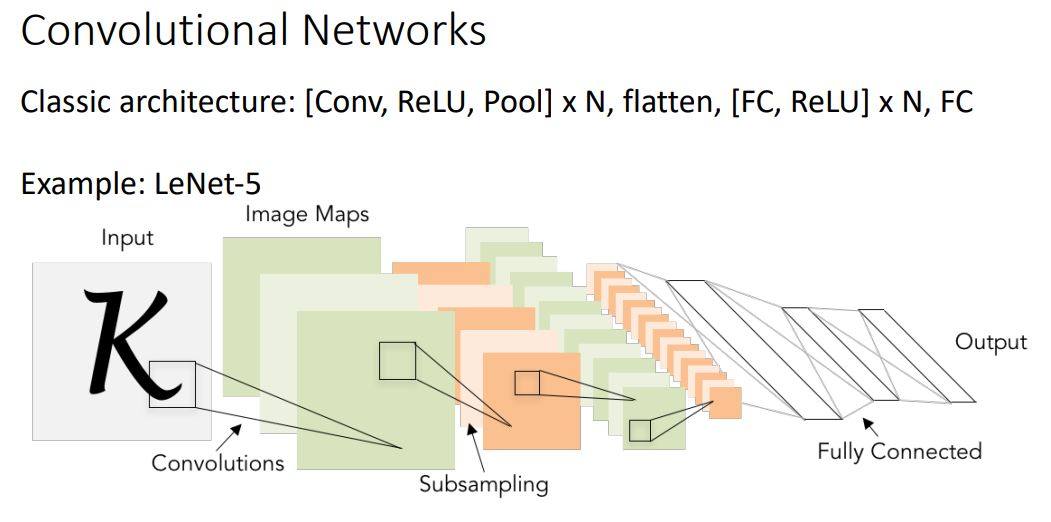
- 이러한 conv net의 classical architecture를 gray-scale image를 input으로 받는 LeNet-5를 예로 살펴보자.
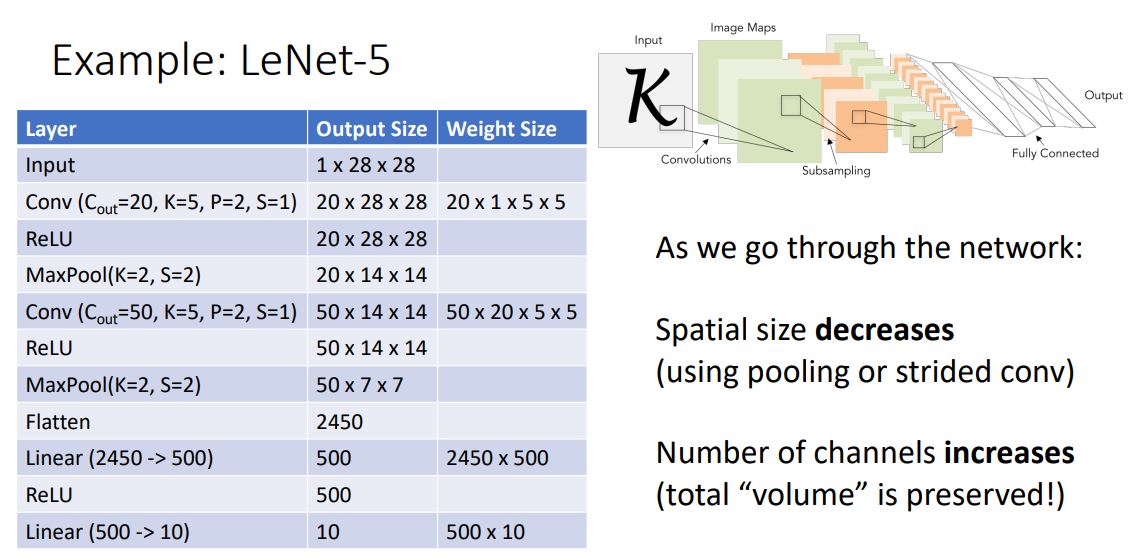
* 해당 강의에서 max-pooling과 non-linearity그리고 ReLU의 상관관계에 대해 잠깐 언급되는데 뭔소린지 모르겠다.
- 이러한 Classical architecture는 매우 커지고 매우 deep해져 매우 큰 data를 학습시키 매우 힘들다는 문제가 있다. 이를 해결하기 위해 normalization 개념이 도입된다.
- normalization은 해당 강의 내용만 보기에는 개괄적이고 이해하기 힘들어 좀더 쉽고 디테일한 내용을 추가해서 따로 포스팅하려한다.
