Intro
-
Overfeat은 AlexNet이후 ImageNet대회에서 Object Detection task에서 처음으로 CNN을 사용하여 좋은 성능을 보인 논문이다.
- 사실 논문 발표상으로는 R-CNN이 한달 일찍 나왔고 detection에서 훨씬 좋은 성능을 보였지만 ImageNet대회에는 참가하지 않았다고 합니다.
- Overfeat은 ConvNet을 사용하여 row pixel이나 category를 end-to-end로 학습시킬 수 있음을 보여주었고 단일 ConvNet(1-stage)를 사용하여 object detection, localization, recognition 세 task에 모두 접목시킬 수 있음을 보여주었다.
- 또한 기존의 sliding window방식을 ConvNet에 적용하여 연산 효율성을 높혔다
Classification
Model training
-
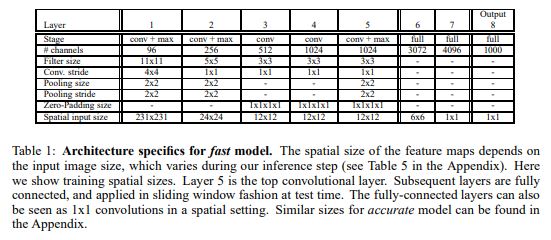
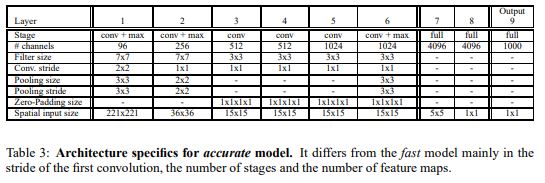
OverFeat은 Fast model과 Accurate model 두개의 버전을 가지고있으며 AlexNet과 유사한 구조를 사용하였고 아래와 같은 학습 세팅을 갖는다.
- Training set : ImageNet 2012
- Input size : 256 x 256 (ImageNet과 동일)
- 221 x 221 size의 5 random crop과 그에대한 horizontal flips
- Batch size : 128
- Use SGD (initial lr = 5x / (30, 50, 60, 70, 80) epochs마다 0.5factor로 decrease)
- FC Layer에서 dropout사용
- L2 decay 1x 사용
- 이때 논문에서는 Layer1~5 까지를 Feature Extractor 라고 부르고 있으며 AlexNet의 overlapped pooling대신 non-overlapped pooling을 사용한다.
Detection
Multi-Scale Classification (evaluation)
- Classification model training시에 사용한 multi-crop voting방식은 image의 많은 부분을 무시하게 되고 필요없는 연산을(동일한 부분의 conv연산) 하게 되며 single scale에 대해서만 적용할 수 있어 dense evaluation 방식을 제안하였다.
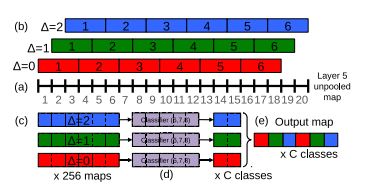
- 논문에선 CNN의 pooling에 의해 downsampling되는 ratio가 36(2x3x2x3) 를 예시로 들며 최종 layer의 output의 1pixel이 input image의 32pixel을 encode하게 되어 (receptive field가 32란 소리) 지나치게 넓은 범위를 한 pixel이 커버하고있어 위 그림처럼 input image에 대한 align이 맞지 않아 10-view voting방식보다 성능이 오히려 떨어진다고한다.
- 논문에서는 이러한 문제를 해결하고자 offset을 주어 offset마다 subsampling을 시켜 resolution을 높히는 새로운 방식의 pooling을 제시하였고 다음과같은 과정을 거친다.

-
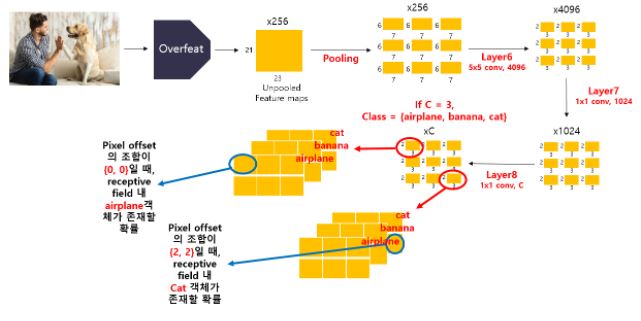
(a) single input image에서 6개의 scale에 대해 extractor로부터 나온 feature map(unpooled map)에 대해 pooling을 진행한다.
-
(b,c) 3x3 kernel을 5x5지역에 region에서 offset에 따라 shift시켜주어 9개의 5x5 feature map을 생성한다.
-
(d,e) 각각의 offset output을 Layer6,7,8을 통해 C-dimensional 1x1 을 생성하고 각 offset 들의 최종 output을 concatenate시켜준다.
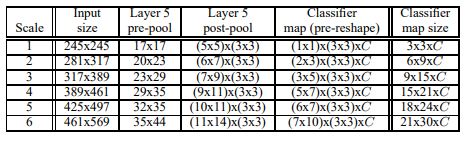
- 위 테이블에 나온 앞서 언급된 6개의 input size 중 두번째 scale에대해 2d로 설명한 그림은 다음과같다.
-
Scale2에 해당하는 281x317을 input으로 받은 extractor가 20x23 feature map을 output으로 출력한다.
-
앞서 언급한데로 offset을 3으로 주어 20x23 feature을 각 offset별로 256-dim 6x7 feature map으로 pooling시키는데 이때 각 offset은 전부 overrap되지 않는 형태이다.
-
layer 6,7,8을 거쳐 C-dim 2x3 feature map 9개를 뽑아내고 이를 combine시켜 이를통해 inference를 진행하게된다.
- 이러한 pooling을 통해 결과적으론 파라미터의 수는 늘어나게 되지만 offset을 주어 최종 output의 한 pixel이 encoding한 input pixel의 범위(receptive field)는 줄어들게되어 resolution을 높힌다고 설명한다.
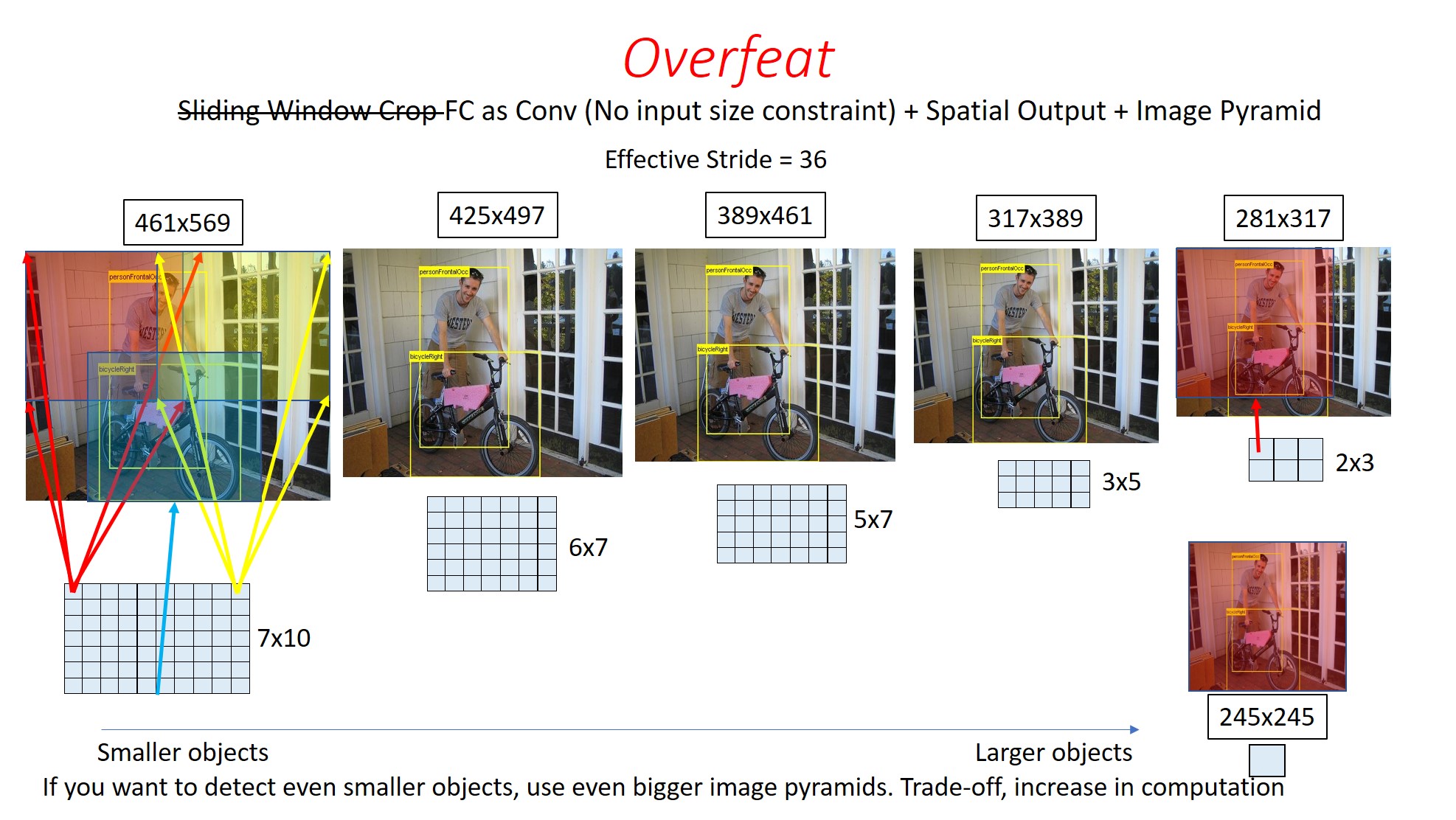
-
위 그림은 논문에서 제안된 6개의 scale image에 대한 spatial output을 나타낸 것 이다.
-
위 그림 아래서 언급한 것 처럼 좀더 큰 image scale pyramid를 사용하게되면 좀더 작은 region을 커버할수 있게되고 이 spatial output은 결국 하나의 bounding box라고 생각해볼 수 있다.
ConvNets and Sliding Window Efficiency
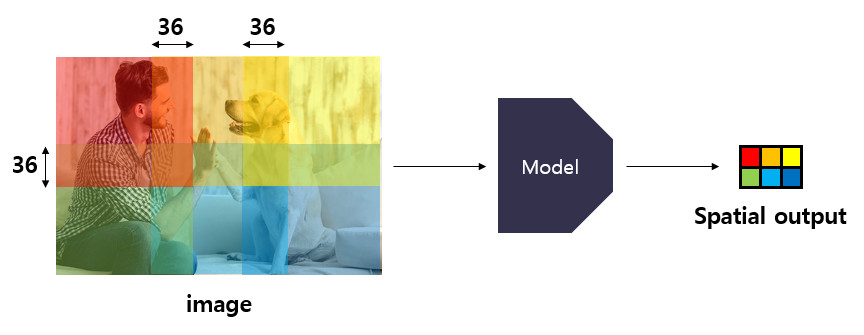
- OverFeat 논문에서는 layer7,8을 1x1으로 대체하여 기존의 fc-layer의 input size가 고정되어야 한다는 제약을 1x1 convolution을 통해 없애버리고 multi-scale input을 가능하게 하였다.
![]()
-
위 그림은 feature extractor의 output feature map을 pooling을 거쳐 Classifier에 해당하는 layer 7,8을 1x1 convolution으로 대체한 것을 보여준다.
-
상단의 그림은 14x14 output에 대해 classifier를 학습시키는 모습을 보여주며 하단의 그림으로 input size가 변해도 output feature의 한 pixel이 갖는 receptive field는 같은 것을 알 수 있다.
Localization
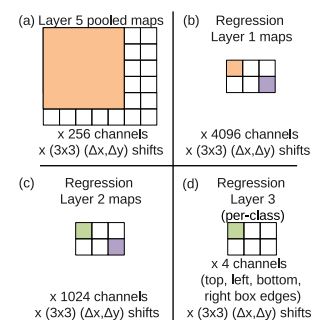
- Bounding box를 예측하는 regressor는 위에서 본 classifier 구조에서 output을 1x1x4xC (c는 calss, 4는 box좌표) feature map을 만들어 L2 loss를 통해 학습시키는 구조이다.

-
학습된 regressor는 6개의 input size별 수많은 bounding box를 얻게되는데 논문에선 수많은 bounding box를 병합하는 gready merge algorithm을 사용하여 prediction하고 이는 다음과같다.
- 이때 GT(ground-truth)에 대한 IoU가 0.5 미만인 box는 버린다.
-
- 이미지에 해당하는 class를 할당한다.
-
- box별로 할당한 class에 대한 confidence score를 구한다.
-
- box두개를 뽑아 로 놓고 간 central point사이 거리와 박스간 IoU를 합하여 계산한 값인 match_score와 이전의 match_score 과 argmin을 계산하여 작은걸 로 넣어준다
-
- 의 match_score가 정해준 threshold값인 t보다 커지게되면 멈추고
-
- 그렇지 않으면 의 평균을 계산하여 boxmerge를 시키고 계속 진행한다.
- 논문에서는 위와같은 gready merge방식은 전통적인 NMS 방식보다 좋은 성능을 보인다고 설명한다.
Outro
-
OverFeat 논문은 동일 시기에 나온 R-CNN보다 detection task에서 낮은 성능을 보였지만 1-stage detector모델로서 이후의 많은 모델에 영향을 준것 같고 spatial output에대한 intuition을 주는 것 같아 읽어볼만한 가치가 충분히 있었다.
-
하지만 내가 실력이 미천한 탓인지 논문이 체계적인 단계로 설명을 해주지 않는 것 처럼 느꼈고 자세하게 설명해주지 않아 이해하는데 오래걸렸다 ㅜㅜ.
References
