Intro
- DenseNet 논문이 발표될 당시 resnet을 비롯한 여러 논문에서의 연구 결과에서 layer에 "shorter connection" 을 포함하고 있다면 network를 좀더 깊게쌓을 수 있고 학습을 용이하게 만든다는 점에서 착안하여 각 layer간 feed-forward 형태로 연결한 Dense Convolution Network(DenseNet) 을 소개하였다.
Dense Block(Dense Connectivity)
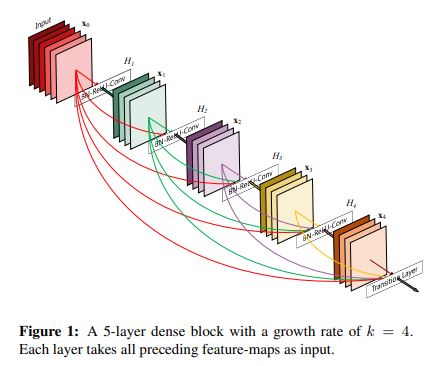
- 위 그림처럼 Dense connection은 dense block내 한 layer의 input feature를 이후 layer의 input에 concatenate 시키는 방식이다.
-
resnet이 위 수식처럼 feature map을 summation 해주는 방식이었다면 densenet은 feature map들을 feed-forward 형태로 concatenate 해주며 이를 통해 layer에서 추가될 정보와 보존해야할 정보가 명시적으로 구분된다.
-
densenet 팀은 Stochastic depth 논문에서 residual block을 random하게 drop해주면 네트워크의 성능을 향상시키는 점에서 deep network에서 수 많은 redundancy layer가 있다는 것을 관찰하였고 densenet의 feature reuse 를 통해 parameter를 최소한으로 사용하면서 network의 최대 potential을 뽑아냈다고 설명한다.
-
또한 이러한 dense connection 구조를 통해 Deeply Supervised Network(DSN)에서 auxiliary classifier 에 의해 internel layer들의 gradient를 강화시켜주는 것 처럼 Implicit Deep Supervision 을 이끈다고 설명한다.
-
Dense block내의 Composite function 은 Resnet의 pre-activation 구조인 BN-ReLU-Conv 순서의 구조를 사용하였다.
Pooling Layer (Transition Layer)
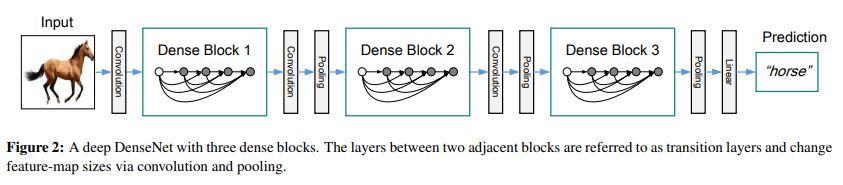
-
위 그림처럼 DenseNet은 하나의 Dense Block후에 feature map을 downsampling하기 위한 Transition Layer를 거친다.
-
Transition Layer는 BN - ReLu - 1x1 Conv - 2x2 average pooling 구조를 갖는다.
-
논문에서는 Transition Layer의 1x1 Conv에서 줄일 channel수를 결정하는 를 hyper-parameter로 사용한다고 하며 experiment때 로 0.5를 사용하여 Transition Layer를 거칠때 feature map의 수 (channel수)를 반으로 줄여주었다고 한다.
Growth rate
-
Figure1 에서 보다시피 각 conv layer는 feature map을 4개씩 생성해주며 이는 input feature와 concatenate되어 다음 layer의 input으로 들어간다.
-
이때 k개씩 증가되는 feature map을 hyper-parameter로 두었으며 과 같이 layer의 feature map수를 나타낼 수 있다.
-
이러한 hyper-parameter k를 Growth rate 라고 하고 논문에서는 DenseNet은 k=12 와 같이 작은 Growth rate를 사용하여 narrow layer 를 갖어 상대적으로 적은 parameter 수를 갖는다고 말한다.
Bottleneck Layer
- ResNet, Inception(GoogLeNet) 에서도 사용된 conv layer 전에 1x1 conv layer를 넣어 channel수를 줄여 연산 효율성을 높힌 bottleneck 구조를 DesNet에서도 사용한다.
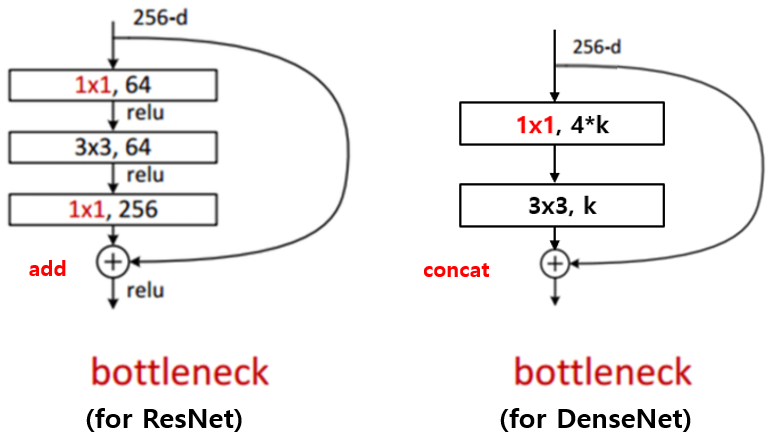
그림 출처 : Hoya012's Research Blog
-
위 그림에서 보다시피 Resnet 에서 1x1 conv를 통해 channel수를 줄이고 3x3 conv연산 후 다시 channel수를 맞춰주는 형태와 조금 다르게 DenseNet 에서는 1x1 conv 에서 4k 만큼의 channel을 생성하여 3x3 conv의 input을 (k일때보다) 증가시켜주고 다시 3x3 conv에서 k만큼 channel을 줄여주는 형태를 갖는다.
- 그림에서 처럼 256 dimension이 input이더라도 해당 layer에서는 k개 만큼의 output channel을 생성해야하는데 k만큼의 input을 받기엔 적었나 1x1 conv를 통해 256-dim을 4k 만큼의 channel로 줄여주게된다.
- DenseNet bottleneck layer는 matrix를 concat해주는 구조이기 때문에 결국 input dimension에서 growth rate(k개)만큼 channel이 증가된다
Implemention Details
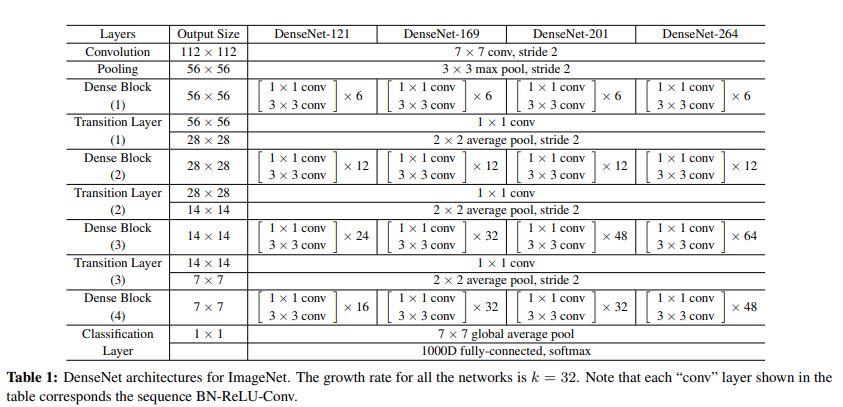
- DenseNet은 ImageNet에대한 아키텍쳐들을 위와같은 표처럼 구현하여 실험하였고
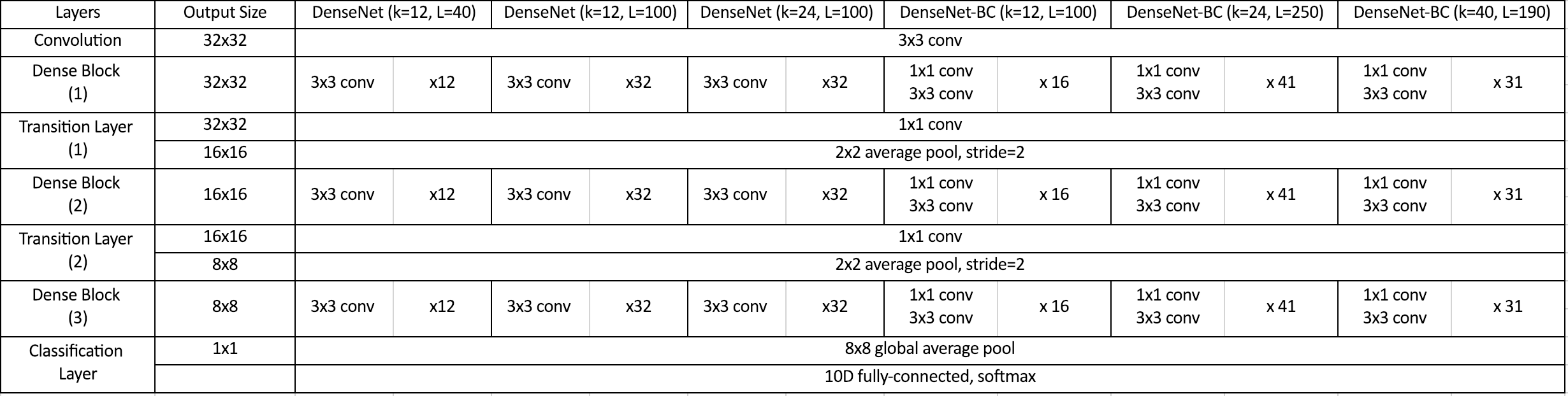
그림 출처 : Hoya012's Research Blog
-
CIFAR-10에 대한 아키텍쳐는 위와 같이 조금 다른 구성을 갖는다.
-
논문에 나와있는 CIFAR-10에 대한 training config는 다음과 같다.
- Epochs : 300
- batch size : 64
- initial learning rate : 0.1
- learning rate decay : divide by 10 at 50%, 75% of total epochs
- weight decay : 0.001
- nestrov momentum : 0.9 without dampening
- weight initialization: He initialization
- without data augmentation
- dropout : 0.2
Experiments
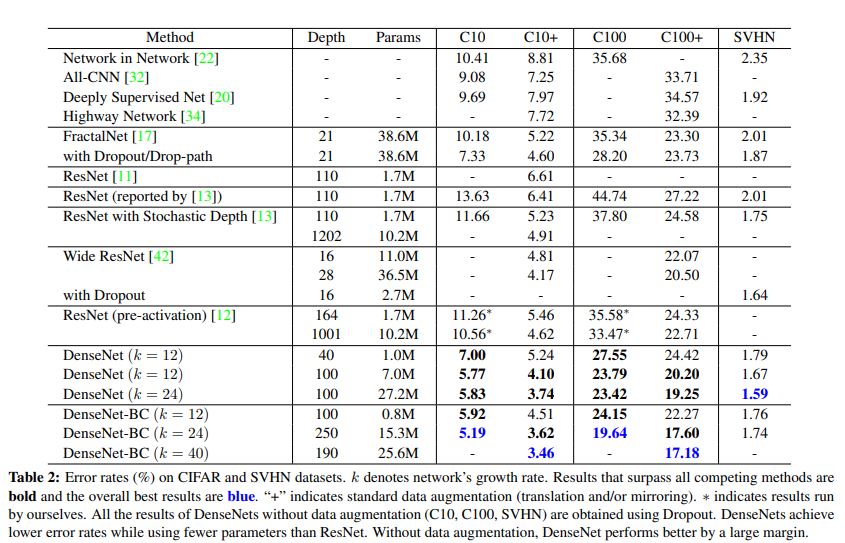
-
위 table을 통해 DenseNet은 ResNet보다 적은 parameter를 사용하며 훨씬 적은 error rate를 보인다.
-
이러한 적은 parameter 사용으로 인해 overfitting이 덜 발생하는 경향을 보인다고 한다.
Outro
- 음... DenseNet은 feed-foward 형태로 connection을 concatenate시켜 파라미터를 줄이고 feature-reuse를 통해 nallow한 network의 potential을 뽑아내어 ResNet보다 좋은 성능을 보였다고 함.
References
