
[혼자 공부하는 머신러닝+딥러닝] 책에 기반한 정리글입니다.
전체 소스코드는 아래 Github 링크에서 확인할 수 있습니다.
0. 개요
지금까지 인공 신경망과 심층신경망을 구성하고 다양한 옵티마이저를 통해 성능을 향상시킬 수 있는 방법에 대해 알아보았다.
이번에는 과대적합을 막기 위해 신경망에서 사용하는 규제방법인 드롭아웃, 최상의 훈련된 모델을 자동으로 저장하고 유지하는 콜백과 조기종료를 알아본다.
1. 데이터 준비하기
패션 MNIST 데이터를 표준화 전처리 후 훈련세트와 검증 세트로 나눈다.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size=0.2, random_state=42)2. 심층 신경망 모델 만들기
2-1. 모델을 만드는 함수 정의하기
층을 매개변수로 가지는 모델을 만드는 함수를 정의한다.
def model_fn(a_layer=None) :
model = keras.Sequential() #sequential 객체
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer :
model.add(a_layer) #은닉층 뒤에 또하나의 층 추가
model.add(keras.layers.Dense(10, activation='softmax'))
return model매개변수의 기본값은 None이며, 매개변수가 있을 경우 은닉층 뒤에 하나의 층을 추가하여 모델을 만든다.
2-2. 함수로 신경망 모델 만들고 손실과 정확도 확인하기
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0) #verbose=0 으로 훈련 과정 나타내지 않음
print(history.history.keys())출력 dict_keys(['loss', 'accuracy'])history 객체에는 훈련 측정값이 담겨 있는 history 딕셔너리가 들어 있다.
딕셔너리 안에는 손실과 정확도가 담겨 있다. 이는 에포크마다 계산한 값이 순서대로 들어있다.
에포크에 따른 손실과 정확도를 그래프로 그려본다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()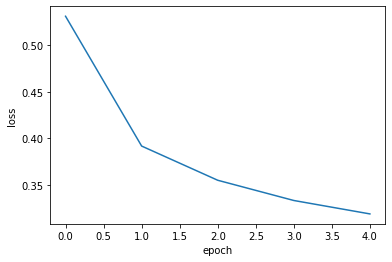
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()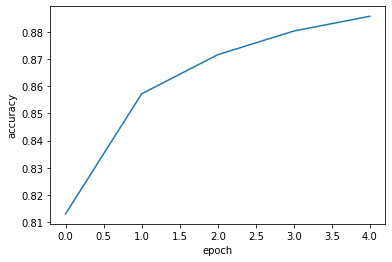
에포크마다 손실이 감소하고 정확도가 상승하는 것을 볼 수 있다.
이번에는 에포크를 20회까지 늘려 관찰한다.
# epochs 20으로 늘려 그래프그리기
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0)
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()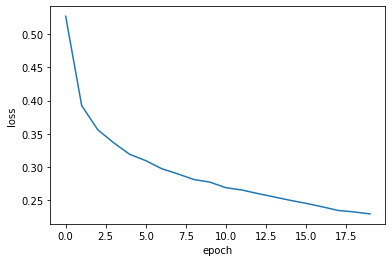
여전히 손실이 잘 감소하고 있지만, 과대적합이 아닌지 알아보아야 한다.
2-3. 검증 손실 확인하기
에포크에 따른 과대적합과 과소적합을 확인하려면 검증 세트에 대한 점수도 필요하다.
여기서는 손실을 사용하여 과대/과소적합을 다룬다.
에포크마다 검증 손실을 계산하기 위해 fit() 메서드에 검증 데이터를 전달할 수 있다. validation_data 매개변수에 입력과 타깃값을 튜플로 만들어 전달한다.
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
print(history.history.keys())출력 dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])검증세트의 손실과 정확도가 딕셔너리에 추가되었다.
이제 검증세트의 손실과 훈련세트의 손실을 그래프로 그려본다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()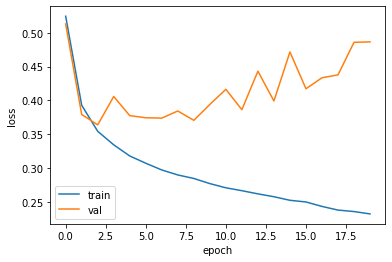
여섯 번째 에포크에 검증손실이 상승하는 것을 파악할 수 있다.
기본 RMSprop 옵티마이저는 많은 문제에서 잘 동작하지만, 다른 옵티마이저를 테스트한다면 Adam 옵티마이저도 있다. 적응적 학습률을 사용하기 때문에 에포크가 진행되면서 학습률을 조절할 수 있다.
Adam 옵티마이저로 모델을 다시 훈련하고 그래프를 그려본다.
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()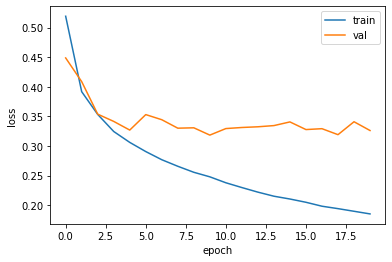
8번째 에포크까지 검증세트의 손실이 감소세를 이어짐을 알 수 있다.
과대적합이 훨씬 줄었기 때문에 Adam 옵티마이저가 이 데이터셋에 더 잘 맞는다.
더 나은 손실 곡선을 얻으려면 학습률을 조정해서 다시 훈련할 수 있다.
3. 드롭아웃
드롭아웃이란 훈련 과정에서 층에 있는 일부 뉴런의 출력을 랜덤하게 0으로 만들어 과대적합을 막는 기법을 의미한다.
일부 뉴런이 랜덤하게 꺼지면 특정 뉴런에 과대하게 의존하는 것을 줄일 수 있고 더 안정적인 예측을 만들 수 있다.
앞서 정의한 model_fn() 함수에 드롭아웃 객체를 전달하여 층을 추가한다.
30% 정도를 드롭아웃 한다.
model = model_fn(keras.layers.Dropout(0.3))
model.summary()출력
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_4 (Flatten) (None, 784) 0
dense_8 (Dense) (None, 100) 78500
dropout (Dropout) (None, 100) 0
dense_9 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________일부 뉴런의 출력을 0으로 만들지만, 전체 출력 배열을 바꾸지는 않는다.
훈련이 끝난 뒤 평가나 예측을 수행할 때는 드롭아웃을 적용하지 말아야 한다.
단, 텐서플로는 평가나 예측시에는 자동으로 드롭아웃을 적용하지 않는다.
모델을 훈련한 뒤 훈련 손실과 검증 손실의 그래프를 비교해 본다.
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()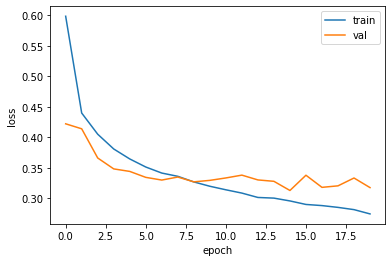
8번째 정도의 에포크에서 검증 손실의 감소가 멈추지만 어느정도 유지된다.
그러나 20번의 에포크동안 훈련했기 때문에 과대적합되어있다.
4. 모델 저장과 복원
에포크 횟수를 10으로 다시 지정하고 모델을 훈련한다. 그리고 이 모델을 저장한다.
훈련된 모델의 파라미터를 저장하는 save_weight() 메서드, 또는 모델 구조와 모델 파라미터를 같이 저장하는 save() 메서드를 사용한다.
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))
#훈련된 모델의 파라미터를 저장
model.save_weights('model-weight.h5')
#모델 구조와 모델 파라미터 같이 저장
model.save('model-whoile.h5')4-1. 저장된 파라미터 불러오기
모델을 만들 때 저장된 파라미터를 불러올 수 있다.
단, 이전에 저장했던 모델과 정확히 같은 구조를 가져야 한다.
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weight.h5')이 모델의 검증 정확도를 predict() 메서드로 확인해본다.
predict() 메서드는 샘플마다 10개의 클래스에 대한 확률을 반환한다.
10개 확률 중 가장 큰 값의 인덱스를 골라 타깃 레이블과 비교하여 정확도를 비교해 본다.
import numpy as np
val_labels = np.argmax(model.predict(val_scaled), axis=-1) #axis=-1 : 마지막 차원, 가장 높은 확률 인덱스 반환
print(np.mean(val_labels == val_target)) # 같으면 1, 다르면 0을 평균화출력 0.88354-2. 저장된 모델 불러오기
마찬가지로 저장된 모델을 불러올 수 있다.
model = keras.models.load_model('model-whoile.h5')
model.evaluate(val_scaled, val_target)출력
375/375 [==============================] - 1s 1ms/step - loss: 0.3267 - accuracy: 0.8835
[0.32670801877975464, 0.8834999799728394]같은 모델을 저장하고 불러왔기 때문에 동일한 정확도를 얻는다.
5. 콜백과 조기종료
5-1. ModelCheckpoint 콜백
콜백은 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체로, keras.callbacks 패키지에 있는 클래스이다.
fit() 메서드의 callbacks 매개변수에 리스트로 전달하여 사용한다.
ModelCheckpoint 콜백은 지정된 에포크 횟수동안 최상의 검증 점수를 만드는 모델을 저장한다.
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
#파일 이름 지정하여 콜백 적용, 모델 훈련 후 최상의 검증 점수를 낸 모델이 파일에 저장
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb])
# load_model()로 불러오기
model = keras.models.load_model('best-model.h5')
model.evaluate(val_scaled, val_target)375/375 [==============================] - 0s 1ms/step - loss: 0.3270 - accuracy: 0.8885
[0.32703569531440735, 0.8884999752044678]20번동안의 에포크에서 최상의 검증 점수를 낸 모델을 불러왔다.
5-2. EarlyStopping 콜백
검증 점수가 상승하기 시작하면 그 이후에는 과대적합이 커지기 때문에 훈련을 계속할 필요가 없다. 과대적합이 시작되기 전 훈련을 중지하는 것을 조기종료라고 한다.
keras에는 조기종료를 위한 EarlyStopping 콜백을 제공하며, patience 매개변수에는 검증점수가 향상되지 않더라도 참을 에포크 횟수를 지정한다.
또한 restore_best_weight 매개변수를 True로 지정하면 가장 낮은 검증 손실을 낸 모델 파라미터로 되돌린다.
이 두가지 콜백을 함께 사용하면 가장 낮은 검증 손실의 모델을 파일에 저장하고, 검증 손실이 다시 상승할 때 훈련을 중지할 수 있다.
또한 훈련을 중지한 다음 현재 모델의 파라미터를 최상의 상태로 되돌린다.
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
#checkpoint와 earlyStopping 지정
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
# callbacks에 리스트로 두 콜백 전달
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
# 몇번째 epoch에서 훈련 중지되었는지
print(early_stopping_cb.stopped_epoch)출력 7에포크 횟수는 0부터 시작하기 때문에 7은 8번째 에포크에서 훈련이 중지되었다는 것을 의미한다. patience가 2이기 때문에 최상의 모델은 6번째 에포크일 것이다.
훈련 손실과 검증 손실을 그래프로 확인해본다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()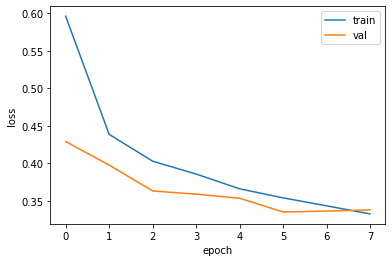
검증 점수를 확인할 수 있다.
model.evaluate(val_scaled, val_target)출력
375/375 [==============================] - 1s 2ms/step - loss: 0.3352 - accuracy: 0.8764
[0.33521145582199097, 0.8764166831970215]최상의 모델이 적용된 것을 확인할 수 있다.
