Introduction
- In 1960,
Rudolf Kalman developed a way to solve some of the practical difficulties that arise when trying to apply Weiner filters
- The three keys to leading to the
Kalman filter
Wiener filter : LMMSE of a signal (only for stationary scalar signals and noises)Sequential LMMSE : sequentially estimate a fixed parameter- State-space models :
dynamical models for varying parameters
Kalman Filter : sequential LMMSE estimation for a time-varying parameter vector, but the time variation is constrained to follow a state-space dynamical model(allow the unknown parameters to evolve in time)Kalman filter is an optimal MMSE estimator for jointly Gaussian case, and is the optimal LMMSE estimator in general
Dynamic Signal Models
Time-varying DC level in WGN examplex[n]=A[n]+w[n]
- Need to estimate A[n],n=0,1,⋯,N−1
- If we model the A[n] as a sequence of unknown deterministic parameters,
MVUE becomes A^[n]=x[n] with variance σ2 (not desirable)
- must model the correlation among A[n]
- A[n] is a realization of a random process :
Bayesian approach
- Let's denote the signal to be estimated as s[n] instead of θ[n]
- Assuming that the mean of the signal is known, we can assume
zero-mean signal and add the mean back later
- A simple model to specify the correlation :
first-order Gauss-Markov processs[n]=as[n−1]+u[n],n≥0
- u[n] : WGN with variance
- σu2 : driving or excitation noise
- s[−1]∼N(μs,σs2), independent of u[n],n≥0
- s[n] : output of LTI system driven by u[n]
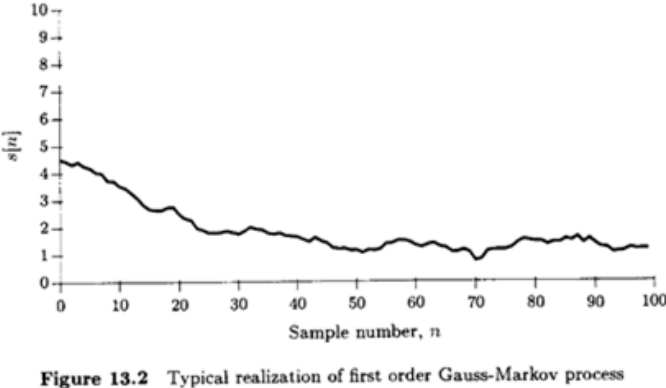
Dynamical or state model : The current output (s[n]) depends only on the state of the system at the previous time (s[n−1]) and the current input (u[n])- In general,
s[n]=an+1s[−1]+k=0∑naku[n−k] linear with s[−1] and u[n−k]'s : Gaussian random process
Gaussian random processE(s[n])=an+1μs
- The
covariance between s[m] and s[n] assuming m≥n iscs[m,n]=E[(s[m]−E(s[m]))(s[n]−E(s[n]))]=E[(am+1(s[−1]−μs)+k=0∑maku[m−k])(an+1(s[−1]−μs)+l=0∑nalu[n−l])]=am+n+2σs2+k=0∑ml=0∑nak+lE(u[m−k]u[n−l])=am+n+2σs2+σu2k=0∑ma2kan−mE(u[m−k]u[n−l])=σu2δ[l−(n−m+k)]=am+n+2σs2+σu2an−mk=0∑n−ma2k→cs[m,n]=cs[n,m]for m<n
- s[n] is not
WSS, but as n→∞,for ∣a∣<1E(s[n])→0,rss[k]=cs[m,n]∣∣∣∣m−n=k→1−a2σu2ak s[n] can be WSS for n>0 if we choose μs,σs2 carefully
- Recursive form
E(s[n])=aE(s[n−1])+E(u[n])=aE(s[n−1])
var(s[n])=E[(s[n]−E(s[n]))2]=E[(as[n−1]+u[n]−aE(s[n−1]))2]=a2var(s[n−1])+σu2
(mean and variance propagation eqns)
- pth-order Gauss-Markov process
s[n]=−k=1∑pa[k]s[n−k]+u[n]
The state of the system at time n:{s[n],s[n−1],s[n−2],…,s[n−p+1]}
state vectors[n]=⎣⎢⎢⎢⎢⎡s[n−p+1]s[n−p+2]⋮s[n]⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡00⋮−a[p]10⋮−a[p−1]01⋮−a[p−2]⋯⋯⋱⋯00⋮−a[1]⎦⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎡s[n−p]s[n−p+1]⋮s[n−1]⎦⎥⎥⎥⎥⎤+⎣⎢⎢⎢⎢⎡00⋮1⎦⎥⎥⎥⎥⎤u[n]
s[n]=As[n−1]+Bu[n],n≥0(vector Gauss-Markov model)
- Generalized vector Gauss-Markov model
s[n]=As[n−1]+Bu[n],n≥0
- State model, A : state transition matrix p×p
- B:p×r matrix
- s[n]:p×1 signal vector
- u[n]:r×1 driving noise vector
- Statiscal assumptions
- u[n] is a vector WGN sequence, i.e. u[n] is a sequence of uncorrelated jointly Gaussian vectors with E[u[n]]=0
As a result,E(u[m]uT[n])=0,m=nE(u[n]uT[n])=Q
- s[−1]∼N(μs,Cs) and s[−1] independent of u[n],n≥0
- Two DC power supplies example
- Two DC power supply outputs which are independent (in a functional sense)
s1[n]=a1s1[n−1]+u1[n],s2[n]=a2s2[n−1]+u2[n]
s1[−1]∼N(μs1,σs12),s2[−1]∼N(μs2,σs22)
u1[n],u2[n]:WGN with variance σu12 and σu22
- All random variables are
independent of each others[n]=[s1[n]s2[n]]=[a100a2][s1[n−1]s2[n−1]]+[1001][u1[n]u2[n]]
E(u[m]uT[n])=[E(u1[m]u1[n])E(u2[m]u1[n])E(u1[m]u2[n])E(u2[m]u2[n])]=[σu1200σu22]δ[m−n]
Q=[σu1200σu22],s[−1]=[s1[−1]s2[−1]]∼N([μs1μs2],[σs1200σs22])
- Statistical properties of the vector Gauss-Markov model
s[n]=An+1s[−1]+k=0∑nAkBu[n−k] where A0=I→ Gaussian random process, E(s[n])=An+1E(s[−1])=An+1μscs[m,n]=E[(s[m]−E(s[m]))(s[n]−E(s[n]))T]
=E⎣⎢⎡(Am+1(s[−1]−μs)+k=0∑mAkBu[m−k])(An+1(s[−1]−μs)+l=0∑nAlBu[n−l])T⎦⎥⎤
=Am+1CsAn+1T+k=0∑ml=0∑nAkBE(u[m−k]u[n−l]T)BTAlT
=Am+1CsAn+1T+k=0∑mAkBQBTA(n−m+k)T,for m<n
C[n]=Cs[n,n]=An+1CsAn+1T+k=0∑nAkBQBTAkT
In recursive form: E(s[n])=AE(s[n−1]),C[n]=AC[n−1]AT+BQBT
- The
eigenvalues of A must be less than 1 magnitude for a stable process
- If so, as n→∞
E(s[n])=An+1μs→0
- It can be shown that An+1CsAn+1T→0 so that
C[n]→C=k=0∑∞AkBQBTAkT
- Also, for steady state, C[n]=C[n−1]=C in recursion,
C=ACAT+BQBT
- It is also possible to make A, B and Q
time-dependent
Scalar Kalman Filter
- Data Model(scalar Gauss-Markov signal model)
- s[n]=as[n−1]+u[n],n≥0 (scalar state equation)
- x[n]=s[n]+w[n] (scalar observation equation)
- Assumptions
- u[n]∼N(0,σu2),u[n] and u[m] indep. for m=n
- w[n]∼N(0,σn2),w[n] and w[m] indep. for m=n (variance can change with time)
- s[−1]∼N(0,σs2), independent of u[n],w[n],n≥0
- Sequential MMSE estimator that estimates s[n] based on x[0],x[1],⋯,x[n] as n increases :
filtering
- Goal : recursively compute
s^[n∣n]=E(s[n]∣x[0],x[1],⋯,x[n])
- Minimize E[s[n]−s^[n∣n])2]→s^[n∣n]=E(s[n]∣x[0],x[1],⋯,x[n])
- Since θ=s[n] and x=[x[0]⋯x[n]]T are jointly Gaussian
(linear, identical to LMMSE estimator)s^[n∣n]=CθxCxx−1x
- For non-Gaussian case, it is still a LMMSE estimator
→ similar to sequential LMMSE estimation with vector space approach
- Let's denote X[n]=[x[0]⋯x[n]]T to avoid confusion with vector observations
x~[n]=x[n]−x^[n∣n−1] : innovations^[n∣n]=E(s[n]∣X[n−1],x~[n])=E(s[n]∣X[n−1])+E(s[n]∣x~[n])Orthogonalization=s^[n∣n−1]+E(s[n]∣x~[n])(∗)
- s^[n∣n−1]=E(as[n−1]+u[n]∣X[n−1])=as^[n−1∣n−1]
- E(s[n]∣x~[n]) : MMSE estimator, linear because of the zero mean assumptions
E(s[n]∣x~[n])=K[n]x~[n]=K[n](x[n]−x^[n∣n−1])
where K[n]=E(x~2[n])E(s[n]x~[n]),as θ^=CθxCxx−1x
x^[n∣n−1]=s^[n∣n−1]+w^[n∣n−1]=s^[n∣n−1]
→E(s[n]∣x~[n])=K[n](x[n]−s^[n∣n−1])
(∗)s^[n]=s^[n−1]+K[n](x[n]−s^[n∣n−1])
where s^[n∣n−1]=as^[n−1∣n−1],K[n]=E((x[n]−s^[n∣n−1])2)E(s[n](x[n]−s^[n∣n−1]))
- To evaluate K[n], we have
- E[s[n](x[n]−s^[n∣n−1])]=E[(s[n]−s^[n∣n−1])(x[n]−s^[n∣n−1])]
since s^[n∣n−1], a linear combination of s[n−k], are orthogonal to error
- E[w[n](s[n]−s^[n∣n−1])]=0
K[n]=E((s[n]−s^[n∣n−1]+w[n])2)E((s[n]−s^[n∣n−1])(x[n]−s^[n∣n−1]))
=E((s[n]−s^[n∣n−1])2)+σn2E((s[n]−s^[n∣n−1])2)=M[n∣n−1]+σn2M[n∣n−1]
where M[n∣n−1] is MSE when s[n] is estimated based on previous data
M[n∣n−1]=E[(s[n]−s^[n∣n−1])2]=E[(a(s[n−1]−s^[n−1∣n−1])+u[n])2]
=a2M[n−1∣n−1]+σu2
M[n∣n]=E[(s[n]−s^[n∣n])2]=E[(s[n]−s^[n∣n−1]−K[n](x[n]−s^[n∣n−1]))2]
=E[(s[n]−s^[n∣n−1])2]−2K[n]E[(s[n]−s^[n∣n−1])(x[n]−s^[n∣n−1])]+K[n]2E[(x[n]−s^[n∣n−1])2]
=M[n∣n−1]−2K[n]M[n∣n−1]+K[n]2(M[n∣n−1]+σn2)
=M[n∣n−1](1−K[n])+K[n]2σn2
=(1−K[n])M[n∣n−1]
- Summary
- Prediction : s^[n∣n−1]=as^[n−1∣n−1]
- Minimum Prediction MSE : M[n∣n−1]=a2M[n−1∣n−1]+σu2
- Kalman Gain : K[n]=M[n∣n−1]+σn2M[n∣n−1]
- Correction : s^[n∣n]=s^[n∣n−1]+K[n](x[n]−s^[n∣n−1])
- Minimum MSE : M[n∣n]=(1−K[n])M[n∣n−1]
- The derivation was with μs=0, but the same equations result for μs=0
- Initialization : s^[−1∣−1]=E(s[−1])=μs and M[−1∣−1]=σs2
- K[n](x[n]−s^[n∣n−1]) can be thought as the estimator of u[n]
- s^[n∣n]=as^[n−1∣n−1]+u^[n] where u^[n]=K[n](x[n]−s^[n∣n−1])
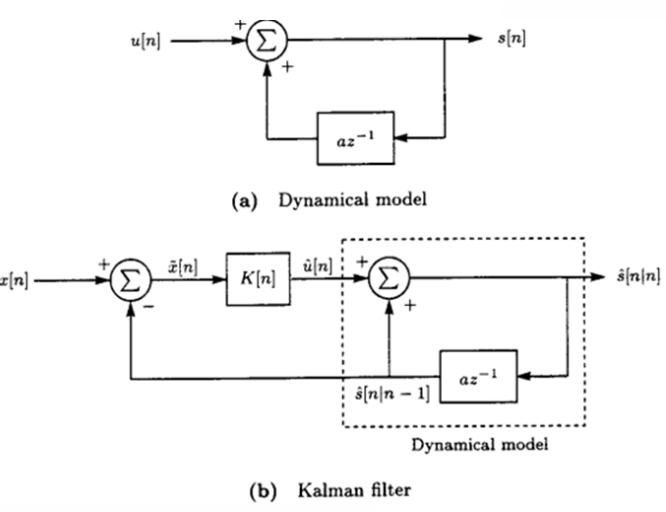
Scalar Kalman Filter - Properties
Kalman filter is an extension to the sequential MMSE estimator (LMMSE for non-Gaussian) where the unknown parameter evolves in time according to the dynamic model. The sequential MMSE estimator is a special case of Kalman filter for a=1 and σu2=0- No matrix inversions are required
- The
Kalman filter is a time varying filters^[n∣n]=as^[n−1∣n−1]+K[n](x[n]−as^[n−1∣n−1])=a(1−K[n])s^[n−1∣n−1]+K[n]x[n] : first order recursive filter with time varying coefficients
- The
Kalman filter provides its own performance measure. Minimum Bayesian MSE is computed as an integral part of the estimator
- The prediction stage increases the error, while the correction stage decreases it. The minimum prediction MSE and the minimum MSE is shown
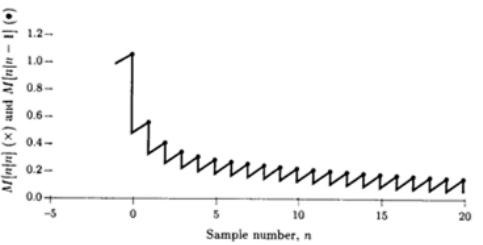
- Predictions is an integral part of the
Kalman filter. One-step prediction is already computed. If we desire the best two-step prediction, we can let σn2→∞ implying x[n] is noisy enough to ignore and obtain s^[n+1∣n−1]=s^[n+1∣n]=as^[n∣n]=as^[n∣n−1]=a2s^[n−1∣n−1]
It can be generalized to the l step predictor
- The
Kalman filter is driven by the uncorrelated innovation sequence and in steady-state can also by viewed as a whitening filters^[n∣n]=as^[n−1∣n−1]+K[n](x[n]−s^[n∣n−1]) If we think the innovationx~[n]=x[n]−s^[n∣n−1] as the Kalman filter output, it is a whitening filter
- For non-Gaussian case, it is still the optimum LMMSE estimator
Vector Kalman Filter
- The p×1 signal vector s[n] evolves in time according to the Gauss-Markov model
x[n]=A[n]s[n−1]+B[n]u[n],n≥0
- A[n],B[n] are known matrices of dimension p×p and p×r, respectively
- u[n] has the PDF u[n]∼N(0,Q[n]) are independent
E(u[m]uT[n])=0, for m=n(u[n] is vector WGN)
- s[−1] has the PDF s[−1]∼N(μs,Cs) and is independent of u[n]
- The M×1 observation vectors x[n] are modeled by the
Bayesian linear modelx[n]=H[n]s[n]+w[n],n≥0
- H[n] is a known M×p observations matrix (which may be time varying)
- w[n] is an M×1 observation noise vector with PDF
- w[n]∼N(0,C[n]) are independent
E(w[m]wT[n])=0,for m=n (If C[n] does not depend on n, w[n] would be vector WGN)
- The MMSE estimator of s[n] based on x[0],x[1],⋯,x[n]
s^[n∣n]=E(s[n]∣x[0],x[1],⋯,x[n])
- Prediction
- Minimum Prediction MSE Matrix (p×p)
M[n∣n−1]=A[n]M[n−1∣n−1]AT[n]+B[n]Q[n]BT[n]
- Kalman Gain Matrix (p×M) :
M[n∣n]=(I−K[n]H[n])M[n∣n−1]
- The recursion is initialized by s^[−1∣−1]=μs, and M[−1∣−1]=Cs
All Content has been written based on lecture of Prof. eui-seok.Hwang in GIST(Detection and Estimation)
