Difference between Detection and Estimation
Estimation : Continuous set of hypotheses(almost always wrong - minimize error instead)Detection : Discrete set of hypotheses(right or wrong)Classical : Hypotheses/parameters are fixed, non-randomBayesian : Hypotheses/parameters are treated as random variables with assumed priors
Overview
Theory of hypothesis testing
Simple hypothesis testing problem with completely known PDF
Complicated hypothesis testing problem with unknown PDF
Primary approaches :
Classical approach based on the Neyman-Pearson theorem
Bayesian approach based on minimization of the Bayes risk
Mathematical Detection Problem
Binary Hypothesis Test
Noise only hypothesis vs. signal present hypothesis(deterministic signals)H 0 : x [ n ] = w [ n ] , null hypothesis H 1 : x [ n ] = s [ n ] + w [ n ] , alternative hypothesis \mathcal{H}_0: x[n] = w[n], \quad \text{null hypothesis} \\ \mathcal{H}_1: x[n] = s[n] + w[n], \quad \text{alternative hypothesis} H 0 : x [ n ] = w [ n ] , null hypothesis H 1 : x [ n ] = s [ n ] + w [ n ] , alternative hypothesis
Example of the DC level in noise ( A = 1 ) (A=1) ( A = 1 )
s [ n ] = A = 1 s[n]=A=1 s [ n ] = A = 1 w [ n ] w[n] w [ n ] ∼ N ( 0 , σ 2 ) \sim\mathcal{N}(0, \sigma^2) ∼ N ( 0 , σ 2 ) p ( x [ 0 ] ; H 0 ) = 1 2 π σ 2 exp [ − 1 2 σ 2 x [ 0 ] 2 ] p(x[0];\mathcal{H}_0)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left[-\frac{1}{2\sigma^2}x[0]^2\right] p ( x [ 0 ] ; H 0 ) = 2 π σ 2 1 exp [ − 2 σ 2 1 x [ 0 ] 2 ] p ( x [ 0 ] ; H 1 ) = 1 2 π σ 2 exp [ − 1 2 σ 2 ( x [ 0 ] − 1 ) 2 ] p(x[0];\mathcal{H}_1)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\left[-\frac{1}{2\sigma^2}(x[0]-1)^2\right] p ( x [ 0 ] ; H 1 ) = 2 π σ 2 1 exp [ − 2 σ 2 1 ( x [ 0 ] − 1 ) 2 ]
Neyman-Pearson Theorem
Reasonable approachH 1 : x [ 0 ] > 1 / 2 H 0 : otherwise \mathcal{H}_1:x[0]>1/2\\\mathcal{H}_0:\text{otherwise} H 1 : x [ 0 ] > 1 / 2 H 0 : otherwise
Type 1 error : decide H 1 \mathcal{H}_1 H 1 H 0 \mathcal{H}_0 H 0 false alarm)→ \rightarrow → P F A = P ( H 1 ; H 0 ) P_{FA} =P(\mathcal{H}_1;\mathcal{H}_0) P F A = P ( H 1 ; H 0 )
Type 2 error : decide H 0 \mathcal{H}_0 H 0 H 1 \mathcal{H}_1 H 1 → \rightarrow → P M = P ( H 0 ; H 1 ) P_M=P(\mathcal{H}_0;\mathcal{H}_1) P M = P ( H 0 ; H 1 ) → \rightarrow → P D = P ( H 1 ; H 1 ) = 1 − P ( H 0 ; H 1 ) = 1 − P M P_D=P(\mathcal{H}_1;\mathcal{H}_1)=1-P(\mathcal{H}_0;\mathcal{H}_1)=1-P_M P D = P ( H 1 ; H 1 ) = 1 − P ( H 0 ; H 1 ) = 1 − P M
Neyman-Pearson Test
Maximize P D = P ( H 1 ; H 1 ) P_D=P(\mathcal{H}_1;\mathcal{H}_1) P D = P ( H 1 ; H 1 ) P F A = P ( H 1 ; H 0 ) = α P_{FA}=P(\mathcal{H}_1;\mathcal{H}_0)=\alpha P F A = P ( H 1 ; H 0 ) = α
Example of the DC level in noiseA = 1 , σ 2 = 1 (standard normal) P F A = P ( H 1 ; H 0 ) = Pr ( x [ 0 ] > γ ; H 0 ) = ∫ γ ∞ 1 2 π exp ( − 1 2 t 2 ) d t = Q ( γ ) P F A = 1 0 − 3 → γ ′ = 3 P D = P ( H 1 ; H 1 ) = Pr ( x [ 0 ] > γ ; H 1 ) = ∫ γ ′ ∞ 1 2 π exp ( − 1 2 ( t − 1 ) 2 ) d t = Q ( γ ′ − 1 ) = Q ( 2 ) = 0.023 Prob of Detection A = 1, \, \sigma^2 = 1 \quad \text{(standard normal)} \\[0.2cm] P_{FA} = P(\mathcal{H}_1; \mathcal{H}_0) = \Pr(x[0] > \gamma; \mathcal{H}_0) = \int_{\gamma}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}t^2\right) dt = Q(\gamma) \\[0.2cm] P_{FA} = 10^{-3} \rightarrow \gamma' = 3 \\[0.2cm] P_D = P(\mathcal{H}_1; \mathcal{H}_1) = \Pr(x[0] > \gamma; \mathcal{H}_1) \\[0.2cm] = \int_{\gamma'}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}(t-1)^2\right) dt = Q(\gamma' - 1) = Q(2) = 0.023\\[0.2cm] \text{Prob of Detection} A = 1 , σ 2 = 1 (standard normal) P F A = P ( H 1 ; H 0 ) = Pr ( x [ 0 ] > γ ; H 0 ) = ∫ γ ∞ 2 π 1 exp ( − 2 1 t 2 ) d t = Q ( γ ) P F A = 1 0 − 3 → γ ′ = 3 P D = P ( H 1 ; H 1 ) = Pr ( x [ 0 ] > γ ; H 1 ) = ∫ γ ′ ∞ 2 π 1 exp ( − 2 1 ( t − 1 ) 2 ) d t = Q ( γ ′ − 1 ) = Q ( 2 ) = 0 . 0 2 3 Prob of Detection
Detector : decide H 0 \mathcal{H}_0 H 0 H 1 \mathcal{H}_1 H 1 x = { x [ 0 ] , ⋯ , x [ n − 1 ] } \text{x}=\{x[0],\cdots,x[n-1]\} x = { x [ 0 ] , ⋯ , x [ n − 1 ] } Decision regionR 1 = { x : decide H 1 or reject H 0 } R 0 = { x : decide H 0 or reject H 1 } R_1=\{\text{x}:\text{decide }\mathcal{H}_1 \text{ or reject }\mathcal{H}_0\}\\[0.2cm] R_0=\{\text{x}:\text{decide }\mathcal{H}_0 \text{ or reject }\mathcal{H}_1\} R 1 = { x : decide H 1 or reject H 0 } R 0 = { x : decide H 0 or reject H 1 }
R 0 ∪ R 1 = R N R_0 \cup R_1=R^N R 0 ∪ R 1 = R N P F A = ∫ R 1 p ( x ; H 0 ) d x = α P_{FA}=\int_{R_1}p(\text{x};\mathcal{H}_0)d\text{x}=\alpha P F A = ∫ R 1 p ( x ; H 0 ) d x = α significance level or sizeP D = ∫ R 1 p ( x ; H 1 ) d x P_D=\int_{R_1}p(\text{x};\mathcal{H}_1)d\text{x} P D = ∫ R 1 p ( x ; H 1 ) d x power of the test Neyman-Pearson TheoremP D P_D P D P F A = α P_{FA} = \alpha P F A = α H 1 \mathcal{H}_1 H 1 L ( x ) = p ( x ; H 1 ) p ( x ; H 0 ) > γ L(\text{x})=\frac{p(\text{x};\mathcal{H}_1)}{p(\text{x};\mathcal{H}_0)}>\gamma L ( x ) = p ( x ; H 0 ) p ( x ; H 1 ) > γ γ \gamma γ P F A = ∫ { x : L ( x ) > γ } p ( x ; H 0 ) d x = α P_{FA}=\int_{\{\text{x}:L(\text{x})>\gamma\}}p(\text{x};\mathcal{H}_0)d\text{x}=\alpha P F A = ∫ { x : L ( x ) > γ } p ( x ; H 0 ) d x = α
L ( x ) = p ( x ; H 1 ) p ( x ; H 0 ) L(\text{x})=\frac{p(\text{x};\mathcal{H}_1)}{p(\text{x};\mathcal{H}_0)} L ( x ) = p ( x ; H 0 ) p ( x ; H 1 ) likelihood ratio : Likelihood ratio test(LRT)
Neyman-Pearson Therorem - Proof
Using Lagrangian multipliers,F = P D + λ ( P F A − α ) = ∫ R 1 p ( x ; H 1 ) d x + λ ( ∫ R 1 p ( x ; H 0 ) d x − α ) = ∫ R 1 ( p ( x ; H 1 ) + λ p ( x ; H 0 ) ) d x − λ α F=P_D+\lambda(P_{FA}-\alpha)=\int_{R_1}p(\text{x};\mathcal{H}_1)d\text{x}+\lambda\left(\int_{R_1}p(\text{x};\mathcal{H}_0)d\text{x}-\alpha\right)\\[0.2cm] =\int_{R_1}(p(\text{x};\mathcal{H}_1)+\lambda p(\text{x};\mathcal{H}_0))d\text{x}-\lambda\alpha F = P D + λ ( P F A − α ) = ∫ R 1 p ( x ; H 1 ) d x + λ ( ∫ R 1 p ( x ; H 0 ) d x − α ) = ∫ R 1 ( p ( x ; H 1 ) + λ p ( x ; H 0 ) ) d x − λ α
To maximize F F F x \text{x} x H 1 \mathcal{H}_1 H 1 positive, i.e., ifp ( x ; H 1 ) + λ p ( x ; H 0 ) > 0 p(\text{x};\mathcal{H}_1)+\lambda p(\text{x};\mathcal{H}_0) >0 p ( x ; H 1 ) + λ p ( x ; H 0 ) > 0
decide H 1 \mathcal{H}_1 H 1 p ( x ; H 1 ) p ( x ; H 0 ) > − λ \frac{p(\text{x};\mathcal{H}_1)}{p(\text{x};\mathcal{H}_0)} > -\lambda p ( x ; H 0 ) p ( x ; H 1 ) > − λ λ \lambda λ
decide H 1 \mathcal{H}_1 H 1 p ( x ; H 1 ) p ( x ; H 0 ) > γ \frac{p(\text{x};\mathcal{H}_1)}{p(\text{x};\mathcal{H}_0)}>\gamma p ( x ; H 0 ) p ( x ; H 1 ) > γ γ \gamma γ P F A = α P_{FA}=\alpha P F A = α
DC level in noise ( A = 1 ) (A=1) ( A = 1 ) P F A = 1 0 − 3 P_{FA}=10^{-3} P F A = 1 0 − 3 p ( x ; H 1 ) p ( x ; H 0 ) = exp [ − 1 2 ( x [ 0 ] − 1 ) 2 ] exp [ − 1 2 x 2 [ 0 ] ] → γ → exp ( x [ 0 ] − 1 2 ) > γ P F A = Pr { exp ( x [ 0 ] − 1 2 ) > γ ; H 0 } = 1 0 − 3 \frac{p(x; \mathcal{H}_1)}{p(x; \mathcal{H}_0)} = \frac{\exp\left[-\frac{1}{2}(x[0] - 1)^2\right]}{\exp\left[-\frac{1}{2}x^2[0]\right]} \rightarrow \gamma \rightarrow \exp\left(x[0] - \frac{1}{2}\right) > \gamma \\[0.2cm] P_{FA} = \Pr\left\{\exp\left(x[0] - \frac{1}{2}\right) > \gamma; \mathcal{H}_0\right\} = 10^{-3} p ( x ; H 0 ) p ( x ; H 1 ) = exp [ − 2 1 x 2 [ 0 ] ] exp [ − 2 1 ( x [ 0 ] − 1 ) 2 ] → γ → exp ( x [ 0 ] − 2 1 ) > γ P F A = Pr { exp ( x [ 0 ] − 2 1 ) > γ ; H 0 } = 1 0 − 3
Let γ ′ = ln γ + 1 / 2 \gamma'=\ln\gamma+1/2 γ ′ = ln γ + 1 / 2 P F A = ∫ γ ∞ 1 2 π exp ( − 1 2 t 2 ) d t = 1 0 − 3 → γ ′ = 3 P D = Pr { x [ 0 ] > 3 ; H 1 } = ∫ 3 ∞ 1 2 π exp ( − 1 2 ( t − 1 ) 2 ) d t = 0.023 P_{FA} = \int_{\gamma}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}t^2\right) dt = 10^{-3} \rightarrow \gamma' = 3 \\[0.2cm] P_D = \Pr\{x[0] > 3; \mathcal{H}_1\} = \int_{3}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}(t-1)^2\right) dt = 0.023 P F A = ∫ γ ∞ 2 π 1 exp ( − 2 1 t 2 ) d t = 1 0 − 3 → γ ′ = 3 P D = Pr { x [ 0 ] > 3 ; H 1 } = ∫ 3 ∞ 2 π 1 exp ( − 2 1 ( t − 1 ) 2 ) d t = 0 . 0 2 3
If P F A = 0.5 P_{FA}=0.5 P F A = 0 . 5 P F A = ∫ γ ′ ∞ 1 2 π exp ( − 1 2 t 2 ) d t = 0.5 ⟹ γ ′ = 0 P D = ∫ 0 ∞ 1 2 π exp ( − 1 2 ( t − 1 ) 2 ) d t = Q ( − 1 ) = 1 − Q ( 1 ) = 0.84 P_{FA} = \int_{\gamma'}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}t^2\right) dt = 0.5 \implies \gamma' = 0 \\[0.2cm] P_D = \int_{0}^\infty \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}(t-1)^2\right) dt = Q(-1) = 1 - Q(1) = 0.84 P F A = ∫ γ ′ ∞ 2 π 1 exp ( − 2 1 t 2 ) d t = 0 . 5 ⟹ γ ′ = 0 P D = ∫ 0 ∞ 2 π 1 exp ( − 2 1 ( t − 1 ) 2 ) d t = Q ( − 1 ) = 1 − Q ( 1 ) = 0 . 8 4
Example of the DC level in WGNH 0 : x [ n ] = w [ n ] , n = 0 , 1 , … , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , … , N − 1 w [ n ] ∼ N ( 0 , σ 2 ) , S [ n ] = A H 0 : μ = 0 H 1 : μ = A 1 \mathcal{H}_0: x[n] = w[n], \quad n = 0, 1, \dots, N-1 \\[0.2cm] \mathcal{H}_1: x[n] = s[n] + w[n], \quad n = 0, 1, \dots, N-1 \\[0.2cm] w[n] \sim \mathcal{N}(0, \sigma^2), \quad S[n] = A \\[0.2cm] \mathcal{H}_0: \mu = 0 \\[0.2cm] \mathcal{H}_1: \mu = A1 H 0 : x [ n ] = w [ n ] , n = 0 , 1 , … , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , … , N − 1 w [ n ] ∼ N ( 0 , σ 2 ) , S [ n ] = A H 0 : μ = 0 H 1 : μ = A 1
Decide H 1 \mathcal{H}_1 H 1 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 ] exp [ − 1 2 σ 2 ∑ n = 0 N − 1 x 2 [ n ] ] > γ → − 1 2 σ 2 ( − 2 A ∑ n = 0 N − 1 x [ n ] + N A 2 ) > ln γ A σ 2 ∑ n = 0 N − 1 x [ n ] > ln γ + N A 2 2 σ 2 1 N ∑ n = 0 N − 1 x [ n ] > σ 2 N A ln γ + A 2 = γ ′ T ( x ) = 1 N ∑ n = 0 N − 1 x [ n ] , T ( x ) ∼ { N ( 0 , σ 2 N ) , under H 0 N ( A , σ 2 N ) , under H 1 P F A = Pr ( T ( x ) > γ ′ ; H 0 ) = Q ( γ ′ σ 2 / N ) → γ ′ = σ 2 N Q − 1 ( P F A ) P D = Pr ( T ( x ) > γ ′ ; H 1 ) = Q ( γ ′ − A σ 2 / N ) → P D = Q ( N σ 2 Q − 1 ( P F A ) − N σ 2 A ) = Q ( Q − 1 ( P F A ) − N A 2 σ 2 ) \frac{\exp\left[-\frac{1}{2\sigma^2} \sum_{n=0}^{N-1} (x[n] - A)^2\right]}{\exp\left[-\frac{1}{2\sigma^2} \sum_{n=0}^{N-1} x^2[n]\right]} > \gamma \\[0.2cm] \rightarrow -\frac{1}{2\sigma^2} \left(-2A \sum_{n=0}^{N-1} x[n] + N A^2\right) > \ln \gamma\\[0.2cm] \frac{A}{\sigma^2} \sum_{n=0}^{N-1} x[n] > \ln \gamma + \frac{N A^2}{2\sigma^2} \\[0.2cm] \frac{1}{N} \sum_{n=0}^{N-1} x[n] > \frac{\sigma^2}{N A} \ln \gamma + \frac{A}{2} = \gamma' \\[0.2cm] T(\mathbf{x}) = \frac{1}{N} \sum_{n=0}^{N-1} x[n], \quad T(\mathbf{x}) \sim \begin{cases} \mathcal{N}\left(0, \frac{\sigma^2}{N}\right), & \text{under } \mathcal{H}_0 \\[0.2cm] \mathcal{N}\left(A, \frac{\sigma^2}{N}\right), & \text{under } \mathcal{H}_1 \end{cases} \\[0.2cm] P_{FA} = \Pr(T(\mathbf{x}) > \gamma'; \mathcal{H}_0) = Q\left(\frac{\gamma'}{\sqrt{\sigma^2 / N}}\right) \rightarrow \gamma' = \sqrt{\frac{\sigma^2}{N}} Q^{-1}(P_{FA}) \\[0.2cm] P_D = \Pr(T(\mathbf{x}) > \gamma'; \mathcal{H}_1) = Q\left(\frac{\gamma' - A}{\sqrt{\sigma^2 / N}}\right) \\[0.2cm] \rightarrow P_D = Q\left(\sqrt{\frac{N}{\sigma^2}} Q^{-1}(P_{FA}) - \sqrt{\frac{N}{\sigma^2}} A\right) = Q\left(Q^{-1}(P_{FA}) - \sqrt{\frac{N A^2}{\sigma^2}}\right) exp [ − 2 σ 2 1 ∑ n = 0 N − 1 x 2 [ n ] ] exp [ − 2 σ 2 1 ∑ n = 0 N − 1 ( x [ n ] − A ) 2 ] > γ → − 2 σ 2 1 ( − 2 A n = 0 ∑ N − 1 x [ n ] + N A 2 ) > ln γ σ 2 A n = 0 ∑ N − 1 x [ n ] > ln γ + 2 σ 2 N A 2 N 1 n = 0 ∑ N − 1 x [ n ] > N A σ 2 ln γ + 2 A = γ ′ T ( x ) = N 1 n = 0 ∑ N − 1 x [ n ] , T ( x ) ∼ ⎩ ⎪ ⎨ ⎪ ⎧ N ( 0 , N σ 2 ) , N ( A , N σ 2 ) , under H 0 under H 1 P F A = Pr ( T ( x ) > γ ′ ; H 0 ) = Q ( σ 2 / N γ ′ ) → γ ′ = N σ 2 Q − 1 ( P F A ) P D = Pr ( T ( x ) > γ ′ ; H 1 ) = Q ( σ 2 / N γ ′ − A ) → P D = Q ( σ 2 N Q − 1 ( P F A ) − σ 2 N A ) = Q ( Q − 1 ( P F A ) − σ 2 N A 2 )
Deflection coefficient d d d T T T d 2 = ( E ( T ; H 1 ) − E ( T ; H 0 ) ) 2 var ( T ; H 0 ) d^2=\frac{(E(T;\mathcal{H}_1)-E(T;\mathcal{H}_0))^2}{\text{var}(T;\mathcal{H}_0)} d 2 = var ( T ; H 0 ) ( E ( T ; H 1 ) − E ( T ; H 0 ) ) 2
Useful in characterizing the performance of a detector
Usually, the larger the deflection coefficient, the easier it is to differentiate between the two signals, and thus the better the detection performance
For the mean shifted Gaussian problem,T ∼ { N ( μ 0 , σ 2 ) , under H 0 N ( μ 1 , σ 2 ) , under H 1 → d 2 = ( μ 1 − μ 0 ) 2 σ 2 P D = Q ( Q − 1 ( P F A ) − d 2 ) T \sim \begin{cases} \mathcal{N}(\mu_0, \sigma^2), & \text{under } \mathcal{H}_0 \\[0.2cm] \mathcal{N}(\mu_1, \sigma^2), & \text{under } \mathcal{H}_1 \end{cases} \quad \rightarrow \quad d^2 = \frac{(\mu_1 - \mu_0)^2}{\sigma^2} \\[0.2cm] P_D = Q\left(Q^{-1}(P_{FA}) - \sqrt{d^2}\right) T ∼ ⎩ ⎪ ⎨ ⎪ ⎧ N ( μ 0 , σ 2 ) , N ( μ 1 , σ 2 ) , under H 0 under H 1 → d 2 = σ 2 ( μ 1 − μ 0 ) 2 P D = Q ( Q − 1 ( P F A ) − d 2 )
Test statistic and sufficient statistic
Assume that we observe x = [ x [ 0 ] ⋯ x [ n ] ] T \text{x}=[x[0]\;\cdots\;x[n]]^T x = [ x [ 0 ] ⋯ x [ n ] ] T θ , p ( x ; θ ) \theta,p(\text{x};\theta) θ , p ( x ; θ ) H 0 : θ = θ 0 H 1 : θ = θ 1 \mathcal{H}_0:\theta=\theta_0\\[0.2cm] \mathcal{H}_1:\theta=\theta_1 H 0 : θ = θ 0 H 1 : θ = θ 1
By Neyman-Fisher factorization theoremp ( x ; θ ) = g ( T ( x ) , θ ) h ( x ) , where T ( x ) is a sufficient statistic for θ p(\text{x};\theta)=g(T(\text{x}),\theta)h(\text{x}), \text{where }T(\text{x}) \text{ is a sufficient statistic for }\theta p ( x ; θ ) = g ( T ( x ) , θ ) h ( x ) , where T ( x ) is a sufficient statistic for θ
The NP test becomesp ( x ; θ 1 ) p ( x ; θ 0 ) > γ → g ( T ( x ) , θ 1 ) g ( T ( x ) , θ 0 ) > γ \frac{p(\text{x};\theta_1)}{p(\text{x};\theta_0)}>\gamma\rightarrow\frac{g(T(\text{x}),\theta_1)}{g(T(\text{x}),\theta_0)}>\gamma p ( x ; θ 0 ) p ( x ; θ 1 ) > γ → g ( T ( x ) , θ 0 ) g ( T ( x ) , θ 1 ) > γ
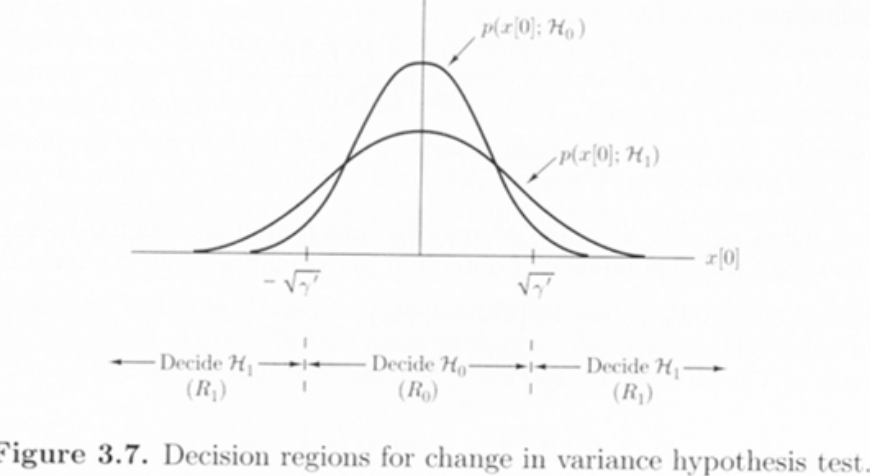
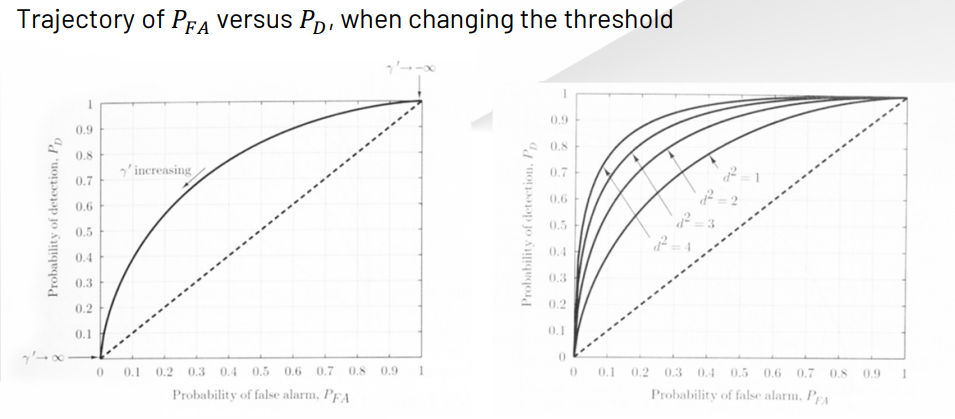
Receiver Operating Characteristics(ROC)
Bayes Risk
P ( H i ) , i = 0 , 1 P(\mathcal{H}_i),\;i=0,1 P ( H i ) , i = 0 , 1 C i j C_{ij} C i j H i \mathcal{H}_i H i H j \mathcal{H}_j H j Bayes riskR = E ( C ) = ∑ i = 0 1 ∑ j = 0 1 C i j P ( H i ∣ H j ) P ( H j ) R=E(C)=\sum^1_{i=0}\sum^1_{j=0}C_{ij}P(\mathcal{H}_i|\mathcal{H}_j)P(\mathcal{H}_j) R = E ( C ) = i = 0 ∑ 1 j = 0 ∑ 1 C i j P ( H i ∣ H j ) P ( H j ) Usually C 00 = C 11 = 0 C_{00}=C_{11}=0 C 0 0 = C 1 1 = 0
If C i j = 1 − δ i j → R = P e C_{ij}=1-\delta_{ij}\rightarrow R=P_e C i j = 1 − δ i j → R = P e P e = P ( H 0 ∣ H 1 ) P ( H 1 ) + P ( H 1 ∣ H 0 ) P ( H 0 ) P_e=P(\mathcal{H}_0|\mathcal{H}_1)P(\mathcal{H}_1)+P(\mathcal{H}_1|\mathcal{H}_0)P(\mathcal{H}_0) P e = P ( H 0 ∣ H 1 ) P ( H 1 ) + P ( H 1 ∣ H 0 ) P ( H 0 )
P e P_e P e
Bayes risk detectorR = C 00 P ( H 0 ) ∫ R 0 p ( x ∣ H 0 ) d x + C 01 P ( H 1 ) ∫ R 0 p ( x ∣ H 1 ) d x + C 10 P ( H 0 ) ∫ R 1 p ( x ∣ H 0 ) d x + C 11 P ( H 1 ) ∫ R 1 p ( x ∣ H 1 ) d x = C 00 P ( H 0 ) + C 01 P ( H 1 ) + ∫ R 1 [ ( C 10 P ( H 0 ) − C 00 P ( H 0 ) ) p ( x ∣ H 0 ) ] d x + ∫ R 1 [ ( C 11 P ( H 1 ) − C 01 P ( H 1 ) ) p ( x ∣ H 1 ) ] d x R = C_{00} P(\mathcal{H}_0) \int_{R_0} p(x|\mathcal{H}_0) dx + C_{01} P(\mathcal{H}_1) \int_{R_0} p(x|\mathcal{H}_1) dx \\[0.2cm] \quad + C_{10} P(\mathcal{H}_0) \int_{R_1} p(x|\mathcal{H}_0) dx + C_{11} P(\mathcal{H}_1) \int_{R_1} p(x|\mathcal{H}_1) dx \\[0.2cm] = C_{00} P(\mathcal{H}_0) + C_{01} P(\mathcal{H}_1) \\[0.2cm] \quad + \int_{R_1} \left[(C_{10} P(\mathcal{H}_0) - C_{00} P(\mathcal{H}_0)) p(x|\mathcal{H}_0)\right] dx \\[0.2cm] \quad + \int_{R_1} \left[(C_{11} P(\mathcal{H}_1) - C_{01} P(\mathcal{H}_1)) p(x|\mathcal{H}_1)\right] dx R = C 0 0 P ( H 0 ) ∫ R 0 p ( x ∣ H 0 ) d x + C 0 1 P ( H 1 ) ∫ R 0 p ( x ∣ H 1 ) d x + C 1 0 P ( H 0 ) ∫ R 1 p ( x ∣ H 0 ) d x + C 1 1 P ( H 1 ) ∫ R 1 p ( x ∣ H 1 ) d x = C 0 0 P ( H 0 ) + C 0 1 P ( H 1 ) + ∫ R 1 [ ( C 1 0 P ( H 0 ) − C 0 0 P ( H 0 ) ) p ( x ∣ H 0 ) ] d x + ∫ R 1 [ ( C 1 1 P ( H 1 ) − C 0 1 P ( H 1 ) ) p ( x ∣ H 1 ) ] d x
Including x \text{x} x R 1 R_1 R 1
Decide H 1 \mathcal{H}_1 H 1 ( C 10 − C 00 ) P ( H 0 ) p ( x ∣ H 0 ) < ( C 01 − C 11 ) P ( H 1 ) p ( x ∣ H 1 ) (C_{10}-C_{00})P(\mathcal{H}_0)p(\text{x}|\mathcal{H}_0) <(C_{01}-C_{11})P(\mathcal{H}_1)p(\text{x}|\mathcal{H}_1) ( C 1 0 − C 0 0 ) P ( H 0 ) p ( x ∣ H 0 ) < ( C 0 1 − C 1 1 ) P ( H 1 ) p ( x ∣ H 1 )
Decide H 1 \mathcal{H}_1 H 1 LRT Bayesian p ( x ∣ H 1 ) p ( x ∣ H 0 ) > ( C 10 − C 00 ) P ( H 0 ) ( C 01 − C 11 ) P ( H 1 ) = γ \text{LRT Bayesian }\frac{p(\text{x}|\mathcal{H}_1)}{p(\text{x}|\mathcal{H}_0)}>\frac{(C_{10}-C_{00})P(\mathcal{H}_0)}{(C_{01}-C_{11})P(\mathcal{H}_1)}=\gamma LRT Bayesian p ( x ∣ H 0 ) p ( x ∣ H 1 ) > ( C 0 1 − C 1 1 ) P ( H 1 ) ( C 1 0 − C 0 0 ) P ( H 0 ) = γ
In Classical γ = α = P F A \gamma=\alpha=P_{FA} γ = α = P F A
Example of DC Level in WGN (Minimum probaility of error criterion)H 0 : x [ n ] = w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 w [ n ] ∼ N ( 0 , σ 2 ) , WGN , P ( H 0 ) = P ( H 1 ) = 1 / 2 \mathcal{H}_0:x[n]=w[n],\;n=0,1,\cdots,N-1\\[0.2cm] \mathcal{H}_1:x[n]=s[n]+w[n],\;n=0,1,\cdots,N-1\\[0.2cm] w[n]\sim\mathcal{N}(0,\sigma^2), \text{WGN},P(\mathcal{H}_0)=P(\mathcal{H}_1)=1/2 H 0 : x [ n ] = w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 w [ n ] ∼ N ( 0 , σ 2 ) , WGN , P ( H 0 ) = P ( H 1 ) = 1 / 2
Minimizing P e P_e P e H 1 \mathcal{H}_1 H 1 L ( x ) = p ( x ∣ H 1 ) p ( x ∣ H 0 ) > ( C 10 − C 00 ) P ( H 0 ) ( C 01 − C 11 ) P ( H 1 ) = 1 = ( 1 − 0 ) 1 / 2 ( 1 − 0 ) 1 / 2 = 1 L(\text{x})=\frac{p(\text{x}|\mathcal{H}_1)}{p(\text{x}|\mathcal{H}_0)}>\frac{(C_{10}-C_{00})P(\mathcal{H}_0)}{(C_{01}-C_{11})P(\mathcal{H}_1)}=1\\[0.2cm] =\frac{(1-0)1/2}{(1-0)1/2}=1 L ( x ) = p ( x ∣ H 0 ) p ( x ∣ H 1 ) > ( C 0 1 − C 1 1 ) P ( H 1 ) ( C 1 0 − C 0 0 ) P ( H 0 ) = 1 = ( 1 − 0 ) 1 / 2 ( 1 − 0 ) 1 / 2 = 1
Decide H 1 \mathcal{H}_1 H 1 x ˉ > A 2 (the same as NP criterion except the threshold) x ˉ ∼ { N ( 0 , σ 2 / N ) under H 0 N ( A , σ 2 / N ) under H 1 P e = 1 2 [ P ( H 0 ∣ H 1 ) + P ( H 1 ∣ H 0 ) ] = 1 2 [ Pr { x ˉ < A / 2 ∣ H 1 } + Pr { x ˉ > A / 2 ∣ H 0 } ] = 1 2 [ ( 1 − Q ( A / 2 − A σ 2 / N ) ) + Q ( A / 2 σ 2 / N ) ] = Q ( A / 2 σ 2 / N ) = Q ( N A 2 4 σ 2 ) \bar x>\frac{A}{2}\text{ (the same as NP criterion except the threshold)}\\[0.2cm] \bar x\sim\begin{cases} \mathcal{N}(0,\sigma^2/N) \text{ under }\mathcal{H}_0\\ \mathcal{N}(A,\sigma^2/N)\text{ under }\mathcal{H}_1 \end{cases}\\[0.2cm] P_e=\frac{1}{2}\left[P(\mathcal{H}_0|\mathcal{H}_1)+P(\mathcal{H}_1|\mathcal{H}_0)\right]\\[0.2cm] =\frac{1}{2}\left[\Pr\{\bar x<A/2|\mathcal{H}_1\} + \Pr\{\bar x > A/2|\mathcal{H}_0\}\right]\\[0.2cm] =\frac{1}{2}\left[\left(1-Q\left(\frac{A/2-A}{\sqrt{\sigma^2/N}}\right)\right)+Q\left(\frac{A/2}{\sqrt{\sigma^2/N}}\right)\right]\\[0.2cm] =Q\left(\frac{A/2}{\sqrt{\sigma^2/N}}\right)=Q\left(\sqrt{\frac{NA^2}{4\sigma^2}}\right) x ˉ > 2 A (the same as NP criterion except the threshold) x ˉ ∼ { N ( 0 , σ 2 / N ) under H 0 N ( A , σ 2 / N ) under H 1 P e = 2 1 [ P ( H 0 ∣ H 1 ) + P ( H 1 ∣ H 0 ) ] = 2 1 [ Pr { x ˉ < A / 2 ∣ H 1 } + Pr { x ˉ > A / 2 ∣ H 0 } ] = 2 1 [ ( 1 − Q ( σ 2 / N A / 2 − A ) ) + Q ( σ 2 / N A / 2 ) ] = Q ( σ 2 / N A / 2 ) = Q ( 4 σ 2 N A 2 )
Large A A A σ 2 \sigma^2 σ 2
Multiple Hypothesis Testing
M M M
Bayes riskR = ∑ i = 0 M − 1 ∑ j = 0 M − 1 C i j P ( H i ∣ H j ) P ( H j ) R=\sum^{M-1}_{i=0}\sum^{M-1}_{j=0}C_{ij}P(\mathcal{H}_i|\mathcal{H}_j)P(\mathcal{H}_j) R = i = 0 ∑ M − 1 j = 0 ∑ M − 1 C i j P ( H i ∣ H j ) P ( H j ) Decision rule : Choose the hypothesis that minimizesC i ( x ) = ∑ j = 0 M − 1 C i j P ( H j ∣ x ) over i = 0 , 1 , ⋯ M − 1 C_i(\text{x})=\sum^{M-1}_{j=0}C_{ij}P(\mathcal{H}_j|\text{x})\text{ over }i=0,1,\cdots M-1 C i ( x ) = j = 0 ∑ M − 1 C i j P ( H j ∣ x ) over i = 0 , 1 , ⋯ M − 1
Decision rule to minimize P e P_e P e C i ( x ) = ∑ j = 0 M − 1 P ( H j ∣ x ) − P ( H i ∣ x ) C_i(\text{x})=\sum^{M-1}_{j=0}P(\mathcal{H}_j|\text{x})-P(\mathcal{H}_i|\text{x}) C i ( x ) = j = 0 ∑ M − 1 P ( H j ∣ x ) − P ( H i ∣ x ) P ( H i ∣ x ) P(\mathcal{H}_i|\text{x}) P ( H i ∣ x ) max i P ( H i ∣ x ) = max i P ( x ∣ H i ) P ( H i ) → ML rule if P ( H i ) are all equal \max_iP(\mathcal{H}_i|\text{x})=\max_iP(\text{x}|\mathcal{H}_i)P(\mathcal{H}_i) \rightarrow \text{ML rule if }P(\mathcal{H}_i) \text{ are all equal} i max P ( H i ∣ x ) = i max P ( x ∣ H i ) P ( H i ) → ML rule if P ( H i ) are all equal
Maximum Likelihood
All Content has been written based on lecture of Prof. eui-seok.Hwang in GIST(Detection and Estimation)