Overview
Detection of a known signal in Gaussian noise
NP criterion or Bayes risk criterion
The test statistic is a linear function of the data due to the Gaussian noise assumption
The detector resulted from these assumptions is called the matched filter
Matched Filters
Detecting a known deterministic signal s [ n ] , n = 0 , 1 , ⋯ , N − 1 s[n],\;n=0,1,\cdots,N-1 s [ n ] , n = 0 , 1 , ⋯ , N − 1 Neyman-Pearson criterion will be used
Bayesian risk criterion will result in the same test statistic; only the threshold differs
Binary hypothesisH 0 : x [ n ] = w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 s [ n ] : known signal , w [ n ] : WGN with variance σ 2 ACF r w w [ k ] = E ( w [ n ] w [ n + k ] ) = σ 2 δ [ k ] \mathcal{H}_0:x[n]=w[n],\quad n=0,1,\cdots,N-1\\[0.2cm] \mathcal{H}_1:x[n]=s[n]+w[n],\quad n=0,1,\cdots,N-1\\[0.2cm] s[n]:\text{known signal},\;w[n]:\text{WGN with variance }\sigma^2\\[0.2cm] \text{ACF }r_{ww}[k]=E(w[n]w[n+k])=\sigma^2\delta[k] H 0 : x [ n ] = w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 s [ n ] : known signal , w [ n ] : WGN with variance σ 2 ACF r w w [ k ] = E ( w [ n ] w [ n + k ] ) = σ 2 δ [ k ]
NP detector : decide H 1 \mathcal{H}_1 H 1 L ( x ) = p ( x ; H 1 ) p ( x ; H 0 ) > γ → ln p ( x ; H 1 ) ln p ( x ; H 0 ) > ln γ L(\text{x})=\frac{p(\text{x};\mathcal{H}_1)}{p(\text{x};\mathcal{H}_0)}>\gamma\\[0.2cm] \rightarrow\frac{\ln p(\text{x};\mathcal{H}_1)}{\ln p(\text{x};\mathcal{H}_0)}>\ln \gamma L ( x ) = p ( x ; H 0 ) p ( x ; H 1 ) > γ → ln p ( x ; H 0 ) ln p ( x ; H 1 ) > ln γ
p ( x ; H 1 ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − s [ n ] ) 2 ] p ( x ; H 0 ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 x 2 [ n ] ] → L ( x ) = exp [ − 1 2 σ 2 ( ∑ n = 0 N − 1 ( x [ n ] − s [ n ] ) 2 − ∑ n = 0 N − 1 x 2 [ n ] ) ] > γ → l ( x ) = ln L ( x ) = − 1 2 σ 2 ( ∑ n = 0 N − 1 ( x [ n ] − s [ n ] ) 2 − ∑ n = 0 N − 1 x 2 [ n ] ) > ln γ p(x; \mathcal{H}_1) = \frac{1}{(2\pi \sigma^2)^{N/2}} \exp\left[-\frac{1}{2\sigma^2} \sum_{n=0}^{N-1} (x[n] - s[n])^2 \right] \\[0.2cm] p(x; \mathcal{H}_0) = \frac{1}{(2\pi \sigma^2)^{N/2}} \exp\left[-\frac{1}{2\sigma^2} \sum_{n=0}^{N-1} x^2[n] \right] \\[0.2cm] \rightarrow L(x) = \exp\left[-\frac{1}{2\sigma^2} \left(\sum_{n=0}^{N-1} (x[n] - s[n])^2 - \sum_{n=0}^{N-1} x^2[n]\right)\right] > \gamma \\[0.2cm] \rightarrow l(x) = \ln L(x) = -\frac{1}{2\sigma^2} \left(\sum_{n=0}^{N-1} (x[n] - s[n])^2 - \sum_{n=0}^{N-1} x^2[n]\right) > \ln \gamma p ( x ; H 1 ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − s [ n ] ) 2 ] p ( x ; H 0 ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 x 2 [ n ] ] → L ( x ) = exp [ − 2 σ 2 1 ( n = 0 ∑ N − 1 ( x [ n ] − s [ n ] ) 2 − n = 0 ∑ N − 1 x 2 [ n ] ) ] > γ → l ( x ) = ln L ( x ) = − 2 σ 2 1 ( n = 0 ∑ N − 1 ( x [ n ] − s [ n ] ) 2 − n = 0 ∑ N − 1 x 2 [ n ] ) > ln γ
decide H 1 \mathcal{H}_1 H 1 ∑ n = 0 N − 1 x [ n ] s [ n ] − 1 2 σ 2 ∑ n = 0 N − 1 s 2 [ n ] > ln γ → T ( x ) = ∑ n = 0 N − 1 x [ n ] s [ n ] > σ 2 ln γ + 1 2 ∑ n = 0 N − 1 s 2 [ n ] = γ ′ \sum_{n=0}^{N-1} x[n] s[n] - \frac{1}{2\sigma^2} \sum_{n=0}^{N-1} s^2[n] > \ln \gamma \\[0.2cm] \rightarrow T(x) = \sum_{n=0}^{N-1} x[n] s[n] > \sigma^2 \ln \gamma + \frac{1}{2} \sum_{n=0}^{N-1} s^2[n] = \gamma' n = 0 ∑ N − 1 x [ n ] s [ n ] − 2 σ 2 1 n = 0 ∑ N − 1 s 2 [ n ] > ln γ → T ( x ) = n = 0 ∑ N − 1 x [ n ] s [ n ] > σ 2 ln γ + 2 1 n = 0 ∑ N − 1 s 2 [ n ] = γ ′
Ex) Damped exponential in WGNs [ n ] = r n , 0 < r < 1 → T ( x ) = ∑ n = 0 N − 1 x [ n ] r n s[n]=r^n,0<r<1\\[0.2cm] \rightarrow T(\text{x})=\sum^{N-1}_{n=0}x[n]r^n s [ n ] = r n , 0 < r < 1 → T ( x ) = n = 0 ∑ N − 1 x [ n ] r n Correlator (replica-correlator)T ( x ) = ∑ n = 0 N − 1 x [ n ] s [ n ] T(\text{x})=\sum^{N-1}_{n=0}x[n]s[n] T ( x ) = n = 0 ∑ N − 1 x [ n ] s [ n ]
Alternatively, if x [ n ] x[n] x [ n ] h [ n ] h[n] h [ n ] n = 0 , 1 , ⋯ , N − 1 n=0,1,\cdots,N-1 n = 0 , 1 , ⋯ , N − 1 y [ n ] = ∑ k = 0 n h [ n − k ] x [ k ] y[n]=\sum^n_{k=0}h[n-k]x[k] y [ n ] = k = 0 ∑ n h [ n − k ] x [ k ]
If we let h [ n ] = s [ N − 1 − n ] , n = 0 , 1 , ⋯ , N − 1 h[n]=s[N-1-n],\;n=0,1,\cdots,N-1 h [ n ] = s [ N − 1 − n ] , n = 0 , 1 , ⋯ , N − 1 y [ n ] = ∑ k = 0 n s [ N − 1 − ( n − k ) ] x [ k ] y [ N − 1 ] = ∑ k = 0 N − 1 s [ k ] x [ k ] → Matched Filter y[n]=\sum^n_{k=0}s[N-1-(n-k)]x[k]\\[0.2cm] y[N-1]=\sum^{N-1}_{k=0} s[k]x[k] \rightarrow \text{Matched Filter} y [ n ] = k = 0 ∑ n s [ N − 1 − ( n − k ) ] x [ k ] y [ N − 1 ] = k = 0 ∑ N − 1 s [ k ] x [ k ] → Matched Filter
In the frequency domain
y [ n ] = ∫ − 1 2 1 2 H ( f ) X ( f ) exp ( j 2 π f n ) d f H ( f ) , X ( f ) : discrete-time Fourier transform of h [ n ] , x [ n ] h [ n ] = s [ N − 1 − n ] → H ( f ) = S ∗ ( f ) exp [ − j 2 π f ( N − 1 ) ] y [ n ] = ∫ − 1 2 1 2 S ∗ ( f ) X ( f ) exp ( j 2 π f ( n − ( N − 1 ) ) d f → y [ N − 1 ] = ∫ − 1 2 1 2 S ∗ ( f ) X ( f ) d f y[n]=\int^{\frac{1}{2}}_{-\frac{1}{2}}H(f)X(f)\exp(j2\pi fn)df\\[0.2cm] H(f),X(f):\text{discrete-time Fourier transform of }h[n],x[n]\\[0.2cm] h[n]=s[N-1-n]\rightarrow H(f)=S^*(f)\exp[-j2\pi f(N-1)]\\[0.2cm] y[n]=\int^{\frac{1}{2}}_{-\frac{1}{2}}S^*(f)X(f)\exp(j2\pi f(n-(N-1))df\rightarrow y[N-1]=\int^{\frac{1}{2}}_{-\frac{1}{2}}S^*(f) X(f)df y [ n ] = ∫ − 2 1 2 1 H ( f ) X ( f ) exp ( j 2 π f n ) d f H ( f ) , X ( f ) : discrete-time Fourier transform of h [ n ] , x [ n ] h [ n ] = s [ N − 1 − n ] → H ( f ) = S ∗ ( f ) exp [ − j 2 π f ( N − 1 ) ] y [ n ] = ∫ − 2 1 2 1 S ∗ ( f ) X ( f ) exp ( j 2 π f ( n − ( N − 1 ) ) d f → y [ N − 1 ] = ∫ − 2 1 2 1 S ∗ ( f ) X ( f ) d f
Matched filter emphasizes the band with more signal power
When the noise is absent, the matched filter output is just the signal energy
A filter which maximizes the SNR at the output (η \eta η
η = E 2 ( y [ N − 1 ] ; H 1 ) var ( y [ N − 1 ] ; H 1 ) = ( ∑ k = 0 N − 1 h [ N − 1 − k ] s [ k ] ) 2 E [ ( ∑ k = 0 N − 1 h [ N − 1 − k ] w [ k ] ) 2 ] \eta = \frac{\mathbb{E}^2\left(y[N-1]; \mathcal{H}_1\right)}{\text{var}\left(y[N-1]; \mathcal{H}_1\right)} = \frac{\left(\sum_{k=0}^{N-1} h[N-1-k] s[k]\right)^2} {\mathbb{E}\left[\left(\sum_{k=0}^{N-1} h[N-1-k] w[k]\right)^2\right]} η = var ( y [ N − 1 ] ; H 1 ) E 2 ( y [ N − 1 ] ; H 1 ) = E [ ( ∑ k = 0 N − 1 h [ N − 1 − k ] w [ k ] ) 2 ] ( ∑ k = 0 N − 1 h [ N − 1 − k ] s [ k ] ) 2
Let s = [ s [ 0 ] s [ 1 ] … s [ N − 1 ] ] T \mathbf{s} = [s[0] \, s[1] \, \dots \, s[N-1]]^T s = [ s [ 0 ] s [ 1 ] … s [ N − 1 ] ] T
h = [ h [ N − 1 ] h [ N − 2 ] … h [ 0 ] ] T \mathbf{h} = [h[N-1] \, h[N-2] \, \dots \, h[0]]^T h = [ h [ N − 1 ] h [ N − 2 ] … h [ 0 ] ] T
w = [ w [ 0 ] w [ 1 ] … w [ N − 1 ] ] T \mathbf{w} = [w[0] \, w[1] \, \dots \, w[N-1]]^T w = [ w [ 0 ] w [ 1 ] … w [ N − 1 ] ] T
then η = ( h T s ) 2 E [ ( h T w ) 2 ] = ( h T s ) 2 h T E ( w w T ) h = ( h T s ) 2 h T σ 2 I h = 1 σ 2 ( h T s ) 2 h T h \text{then} \quad \eta = \frac{(\mathbf{h}^T \mathbf{s})^2}{\mathbb{E}[(\mathbf{h}^T \mathbf{w})^2]} = \frac{(\mathbf{h}^T \mathbf{s})^2}{\mathbf{h}^T \mathbb{E}(\mathbf{w} \mathbf{w}^T) \mathbf{h}} = \frac{(\mathbf{h}^T \mathbf{s})^2}{\mathbf{h}^T \sigma^2 \mathbf{I} \mathbf{h}} = \frac{1}{\sigma^2} \frac{(\mathbf{h}^T \mathbf{s})^2}{\mathbf{h}^T \mathbf{h}} then η = E [ ( h T w ) 2 ] ( h T s ) 2 = h T E ( w w T ) h ( h T s ) 2 = h T σ 2 I h ( h T s ) 2 = σ 2 1 h T h ( h T s ) 2
By the Cauchy-Schwarz inequality
( h T s ) 2 ≤ ( h T h ) ( s T s ) (\text{h}^T\text{s})^2\leq(\text{h}^T\text{h})(\text{s}^T\text{s}) ( h T s ) 2 ≤ ( h T h ) ( s T s ) with equality if and only if h = c s \text{h}=c\text{s} h = c s
Then
η ≤ 1 σ 2 s T s \eta\leq\frac{1}{\sigma^2}\text{s}^T\text{s} η ≤ σ 2 1 s T s with equality if and only if h = c s \text{h}=c\text{s} h = c s
The maximum SNR is attained for
h [ N − 1 − n ] = s [ n ] or h [ n ] = s [ N − 1 − n ] , n = 0 , 1 , ⋯ , N − 1 h[N-1-n]=s[n]\\[0.2cm] \text{or }h[n]=s[N-1-n],\quad n=0,1,\cdots,N-1 h [ N − 1 − n ] = s [ n ] or h [ n ] = s [ N − 1 − n ] , n = 0 , 1 , ⋯ , N − 1
For WGN, the NP criterion and the maximum SNR criterion lead to the same matched filter
For non-Gaussian case, NP detector is not linear
(P D P_D P D P F A P_{FA} P F A
H 1 \mathcal{H}_1 H 1 T ( x ) = ∑ n = 0 N − 1 x [ n ] s [ n ] > γ 2 T ( x ) is Gaussian E ( T ; H 0 ) = E ( ∑ n = 0 N − 1 w [ n ] s [ n ] ) = 0 , E ( T ; H 1 ) = E ( ∑ n = 0 N − 1 ( s [ n ] + w [ n ] ) s [ n ] ) = ∑ n = 0 N − 1 s 2 [ n ] ≜ E var ( T ; H 0 ) = var ( ∑ n = 0 N − 1 w [ n ] s [ n ] ) = ∑ n = 0 N − 1 var ( w [ n ] ) s 2 [ n ] = σ 2 ∑ n = 0 N − 1 s 2 [ n ] = σ 2 E var ( T ; H 1 ) = var ( T ; H 0 ) T(\text{x})=\sum^{N-1}_{n=0}x[n]s[n]>\gamma^2\\[0.2cm] T(\text{x})\text{ is Gaussian}\\[0.2cm] \mathbb{E}(T; \mathcal{H}_0) = \mathbb{E}\left(\sum_{n=0}^{N-1} w[n] s[n]\right) = 0, \\[0.2cm] \mathbb{E}(T; \mathcal{H}_1) = \mathbb{E}\left(\sum_{n=0}^{N-1} (s[n] + w[n]) s[n]\right) = \sum_{n=0}^{N-1} s^2[n] \triangleq \mathcal{E} \\[0.2cm] \text{var}(T; \mathcal{H}_0) = \text{var}\left(\sum_{n=0}^{N-1} w[n] s[n]\right) = \sum_{n=0}^{N-1} \text{var}(w[n]) s^2[n] = \sigma^2 \sum_{n=0}^{N-1} s^2[n] = \sigma^2 \mathcal{E} \\[0.2cm] \text{var}(T; \mathcal{H}_1) = \text{var}(T; \mathcal{H}_0) T ( x ) = n = 0 ∑ N − 1 x [ n ] s [ n ] > γ 2 T ( x ) is Gaussian E ( T ; H 0 ) = E ( n = 0 ∑ N − 1 w [ n ] s [ n ] ) = 0 , E ( T ; H 1 ) = E ( n = 0 ∑ N − 1 ( s [ n ] + w [ n ] ) s [ n ] ) = n = 0 ∑ N − 1 s 2 [ n ] ≜ E var ( T ; H 0 ) = var ( n = 0 ∑ N − 1 w [ n ] s [ n ] ) = n = 0 ∑ N − 1 var ( w [ n ] ) s 2 [ n ] = σ 2 n = 0 ∑ N − 1 s 2 [ n ] = σ 2 E var ( T ; H 1 ) = var ( T ; H 0 )
The test statistic
T ∼ { N ( 0 , σ 2 E ) under H 0 N ( E , σ 2 E ) under H 1 T \sim \begin{cases} \mathcal{N}(0, \sigma^2 \mathcal{E}) & \text{under } \mathcal{H}_0 \\[0.2cm] \mathcal{N}(\mathcal{E}, \sigma^2 \mathcal{E}) & \text{under } \mathcal{H}_1 \end{cases} T ∼ ⎩ ⎪ ⎨ ⎪ ⎧ N ( 0 , σ 2 E ) N ( E , σ 2 E ) under H 0 under H 1
ThusP F A = Pr { T > γ ′ ; H 0 } = Q ( γ ′ σ 2 E ) P D = Pr { T > γ ′ ; H 1 } = Q ( γ ′ − E σ 2 E ) = Q ( Q − 1 ( P F A ) − E σ 2 ) P_{FA} = \Pr\{T > \gamma'; \mathcal{H}_0\} = Q\left(\frac{\gamma'}{\sqrt{\sigma^2 \mathcal{E}}}\right) \\[0.2cm] P_D = \Pr\{T > \gamma'; \mathcal{H}_1\} = Q\left(\frac{\gamma' - \mathcal{E}}{\sqrt{\sigma^2 \mathcal{E}}}\right) = Q\left(Q^{-1}(P_{FA}) - \sqrt{\frac{\mathcal{E}}{\sigma^2}}\right) P F A = Pr { T > γ ′ ; H 0 } = Q ( σ 2 E γ ′ ) P D = Pr { T > γ ′ ; H 1 } = Q ( σ 2 E γ ′ − E ) = Q ( Q − 1 ( P F A ) − σ 2 E )
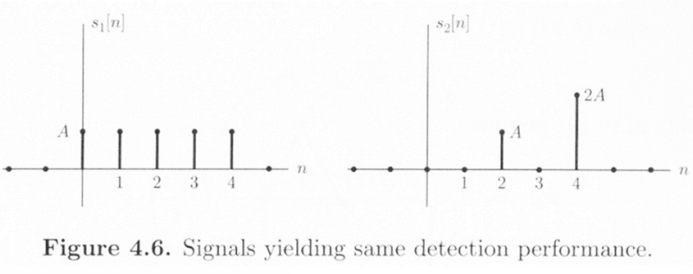
The shape of the signal does not affect the detection performance
Only the ENR matters
But the signal shape affects the performance when the noise is colored
Generalized Matched Filters
Correlated noise : w ∼ N ( 0 , C ) \text{w}\sim \mathcal{N}(0,\text{C}) w ∼ N ( 0 , C )
If the noise is WSS, [ C ] m n = r w w [ m − n ] [\text{C}]_{mn}=r_{ww}[m-n] [ C ] m n = r w w [ m − n ]
If the noise is nonstationary, C \text{C} C p ( x ; H 1 ) = 1 ( 2 π ) N / 2 det C exp ( − 1 2 ( x − s ) T C − 1 ( x − s ) ) p ( x ; H 0 ) = 1 ( 2 π ) N / 2 det C exp ( − 1 2 x T C − 1 x ) p(x; \mathcal{H}_1) = \frac{1}{(2\pi)^{N/2} \sqrt{\det \mathbf{C}}} \exp\left(-\frac{1}{2} (x - s)^T \mathbf{C}^{-1} (x - s)\right) \\[0.2cm] p(x; \mathcal{H}_0) = \frac{1}{(2\pi)^{N/2} \sqrt{\det \mathbf{C}}} \exp\left(-\frac{1}{2} x^T \mathbf{C}^{-1} x\right) p ( x ; H 1 ) = ( 2 π ) N / 2 det C 1 exp ( − 2 1 ( x − s ) T C − 1 ( x − s ) ) p ( x ; H 0 ) = ( 2 π ) N / 2 det C 1 exp ( − 2 1 x T C − 1 x )
LRT : decide H 1 \mathcal{H}_1 H 1 l ( x ) = ln p ( x ; H 1 ) p ( x ; H 0 ) > ln γ , l ( x ) = x T C − 1 s − 1 2 s T C − 1 s l(x) = \ln \frac{p(x; \mathcal{H}_1)}{p(x; \mathcal{H}_0)} > \ln \gamma, \\[0.2cm] l(x) = x^T \mathbf{C}^{-1} s - \frac{1}{2} s^T \mathbf{C}^{-1} s l ( x ) = ln p ( x ; H 0 ) p ( x ; H 1 ) > ln γ , l ( x ) = x T C − 1 s − 2 1 s T C − 1 s
T ( x ) = x T C − 1 s > γ ′ T(\text{x})=\text{x}^T\mathbf{C}^{-1}\text{s}>\gamma' T ( x ) = x T C − 1 s > γ ′ If we let s ′ ′ = C − 1 s , T ( x ) = x T s ′ ′ s''=C^{-1}s,\;T(\text{x})=\text{x}^Ts'' s ′ ′ = C − 1 s , T ( x ) = x T s ′ ′
Prewhitening
For any C \text{C} C C − 1 \text{C}^{-1} C − 1 → C − 1 = D T D \rightarrow C^{-1}=D^TD → C − 1 = D T D D D D T ( x ) = x T C − 1 s = x T D T D s = x ′ T s ′ where x ′ = D x , s ′ = D s T(\text{x})=\text{x}^TC^{-1}s=\text{x}^TD^TDs=\text{x}'^Ts'\\[0.2cm] \text{where }\text{x}'=D\text{x},\;s'=Ds T ( x ) = x T C − 1 s = x T D T D s = x ′ T s ′ where x ′ = D x , s ′ = D s
Prewhitening : w ′ = D w \text{w}'=D\text{w} w ′ = D w C w ′ = E ( w ′ w ′ T ) = D C D T = I C_{\text{w}'}=E(\text{w}'\text{w}'^T)=DCD^T=I C w ′ = E ( w ′ w ′ T ) = D C D T = I If the length N N N T ( x ) = ∫ − 1 / 2 1 / 2 X ( f ) S ∗ ( f ) P ww ( f ) d f T(\text{x})=\int^{1/2}_{-1/2}\frac{X(f)S^*(f)}{P_{\text{w}\text{w}}(f)}df T ( x ) = ∫ − 1 / 2 1 / 2 P w w ( f ) X ( f ) S ∗ ( f ) d f P ww ( f ) P_{\text{w}\text{w}(f)} P w w ( f )
T ( x ) = x T C − 1 s : Gaussian E ( T ; H 0 ) = E ( w T C − 1 s ) = 0 E ( T ; H 1 ) = E ( ( s + w ) T C − 1 s ) = s T C − 1 s var ( T ; H 0 ) = E [ ( w T C − 1 s ) 2 ] = s T C − 1 E [ w w T ] C − 1 s = s T C − 1 s var ( T ; H 1 ) = var ( T ; H 0 ) → P D = Q ( Q − 1 ( P F A ) − d 2 ) d 2 = ( E ( T ; H 1 ) − E ( T ; H 0 ) ) 2 var ( T ; H 0 ) = s T C − 1 s : deflection coefficient P D = Q ( Q − 1 ( P F A ) − s T C − 1 s ) T(x) = x^T \mathbf{C}^{-1} s : \text{Gaussian} \\[0.2cm] \mathbb{E}(T; \mathcal{H}_0) = \mathbb{E}(w^T \mathbf{C}^{-1} s) = 0 \\[0.2cm] \mathbb{E}(T; \mathcal{H}_1) = \mathbb{E}((s + w)^T \mathbf{C}^{-1} s) = s^T \mathbf{C}^{-1} s \\[0.2cm] \text{var}(T; \mathcal{H}_0) = \mathbb{E}[(w^T \mathbf{C}^{-1} s)^2] = s^T \mathbf{C}^{-1} \mathbb{E}[ww^T] \mathbf{C}^{-1} s = s^T \mathbf{C}^{-1} s \\[0.2cm] \text{var}(T; \mathcal{H}_1) = \text{var}(T; \mathcal{H}_0) \\[0.2cm] \rightarrow P_D = Q\left(Q^{-1}(P_{FA}) - \sqrt{d^2}\right) \\[0.2cm] d^2 = \frac{\left(\mathbb{E}(T; \mathcal{H}_1) - \mathbb{E}(T; \mathcal{H}_0)\right)^2}{\text{var}(T; \mathcal{H}_0)} = s^T \mathbf{C}^{-1} s : \text{deflection coefficient} \\[0.2cm] P_D = Q\left(Q^{-1}(P_{FA}) - \sqrt{s^T \mathbf{C}^{-1} s}\right) T ( x ) = x T C − 1 s : Gaussian E ( T ; H 0 ) = E ( w T C − 1 s ) = 0 E ( T ; H 1 ) = E ( ( s + w ) T C − 1 s ) = s T C − 1 s var ( T ; H 0 ) = E [ ( w T C − 1 s ) 2 ] = s T C − 1 E [ w w T ] C − 1 s = s T C − 1 s var ( T ; H 1 ) = var ( T ; H 0 ) → P D = Q ( Q − 1 ( P F A ) − d 2 ) d 2 = var ( T ; H 0 ) ( E ( T ; H 1 ) − E ( T ; H 0 ) ) 2 = s T C − 1 s : deflection coefficient P D = Q ( Q − 1 ( P F A ) − s T C − 1 s )
Example of signal design for uncorrelated noise with unequal variancesC − 1 = diag ( 1 σ 0 2 , 1 σ 1 2 , … , 1 σ N − 1 2 ) → s T C − 1 s = ∑ n = 0 N − 1 s 2 [ n ] σ n 2 \mathbf{C}^{-1} = \text{diag}\left(\frac{1}{\sigma_0^2}, \frac{1}{\sigma_1^2}, \dots, \frac{1}{\sigma_{N-1}^2}\right) \rightarrow s^T \mathbf{C}^{-1} s = \sum_{n=0}^{N-1} \frac{s^2[n]}{\sigma_n^2} C − 1 = diag ( σ 0 2 1 , σ 1 2 1 , … , σ N − 1 2 1 ) → s T C − 1 s = n = 0 ∑ N − 1 σ n 2 s 2 [ n ]
We want to maximize d 2 = s T C − 1 s d^2=\text{s}^TC^{-1}\text{s} d 2 = s T C − 1 s ∑ n = 0 N − 1 s 2 [ n ] = E \sum_{n=0}^{N-1} s^2[n] = \mathcal{E} n = 0 ∑ N − 1 s 2 [ n ] = E
By using Lagrangian multipliersF = ∑ n = 0 N − 1 s 2 [ n ] σ n 2 + λ ( E − ∑ n = 0 N − 1 s 2 [ n ] ) ∂ F ∂ s [ k ] = 2 s [ k ] σ k 2 − 2 λ s [ k ] = 2 s [ k ] ( 1 σ k 2 − λ ) = 0 , k = 0 , 1 , … , N − 1 F = \sum_{n=0}^{N-1} \frac{s^2[n]}{\sigma_n^2} + \lambda \left(\mathcal{E} - \sum_{n=0}^{N-1} s^2[n]\right) \\[0.2cm] \frac{\partial F}{\partial s[k]} = \frac{2s[k]}{\sigma_k^2} - 2\lambda s[k] = 2s[k] \left(\frac{1}{\sigma_k^2} - \lambda\right) = 0, \quad k = 0, 1, \dots, N-1 F = n = 0 ∑ N − 1 σ n 2 s 2 [ n ] + λ ( E − n = 0 ∑ N − 1 s 2 [ n ] ) ∂ s [ k ] ∂ F = σ k 2 2 s [ k ] − 2 λ s [ k ] = 2 s [ k ] ( σ k 2 1 − λ ) = 0 , k = 0 , 1 , … , N − 1
Assuming all the σ n 2 \sigma^2_n σ n 2 ( 1 σ k 2 − λ ) = 0 \left(\frac{1}{\sigma^2_k}-\lambda\right)=0 ( σ k 2 1 − λ ) = 0 k k k
Let j j j ( 1 σ j 2 − λ ) = 0 \left(\frac{1}{\sigma^2_j}-\lambda\right)=0 ( σ j 2 1 − λ ) = 0
Then s [ k ] = 0 s[k]=0 s [ k ] = 0 k ≠ j k\neq j k = j s T C − 1 s = s 2 [ j ] σ j 2 = E σ j 2 \text{s}^TC^{-1}\text{s}=\frac{s^2[j]}{\sigma^2_j}=\frac{\mathcal{E}}{\sigma^2_j} s T C − 1 s = σ j 2 s 2 [ j ] = σ j 2 E → \rightarrow → j j j σ j 2 \sigma^2_j σ j 2
For an arbitrary noise covariance matrix
The signal is chosen by maximizing s T C − 1 s \text{s}^TC^{-1}\text{s} s T C − 1 s s T s = E s^Ts=\mathcal{E} s T s = E F = s T C − 1 s + λ ( E − s T s ) ∂ F ∂ s = 2 C − 1 s − 2 λ s = 0 → C − 1 s = λ s → s is an eigenvector of C − 1 s T C − 1 s = s T λ s = λ E F = s^T \mathbf{C}^{-1} s + \lambda \left(\mathcal{E} - s^T s\right) \\[0.2cm] \frac{\partial F}{\partial s} = 2 \mathbf{C}^{-1} s - 2\lambda s = 0 \\[0.2cm] \rightarrow \mathbf{C}^{-1} s = \lambda s \quad \rightarrow \quad s \text{ is an eigenvector of } \mathbf{C}^{-1} \\[0.2cm] s^T \mathbf{C}^{-1} s = s^T \lambda s = \lambda \mathcal{E} F = s T C − 1 s + λ ( E − s T s ) ∂ s ∂ F = 2 C − 1 s − 2 λ s = 0 → C − 1 s = λ s → s is an eigenvector of C − 1 s T C − 1 s = s T λ s = λ E
s \text{s} s C − 1 C^{-1} C − 1 λ \lambda λ Alternatively, C s = 1 λ s Cs=\frac{1}{\lambda}s C s = λ 1 s s s s C C C λ \lambda λ
Example of signal design for colored noise
C = [ 1 ρ ρ 1 ] C=\left[\begin{matrix}1 &\rho\\\rho&1\end{matrix}\right] C = [ 1 ρ ρ 1 ]
Eigenvalues( C − λ i I ) v = 0 → λ 1 = 1 + ρ , λ 2 = 1 − ρ (C-\lambda_iI)\text{v}=0\rightarrow\lambda_1=1+\rho,\;\lambda_2=1-\rho ( C − λ i I ) v = 0 → λ 1 = 1 + ρ , λ 2 = 1 − ρ
Eigenvectorsv 1 = [ 1 / 2 1 / 2 ] , v 2 = [ 1 / 2 − 1 / 2 ] \text{v}_1=\left[\begin{matrix}1/\sqrt{2}\\1/\sqrt{2}\end{matrix}\right],\;\text{v}_2=\left[\begin{matrix}1/\sqrt{2}\\-1/\sqrt{2}\end{matrix}\right] v 1 = [ 1 / 2 1 / 2 ] , v 2 = [ 1 / 2 − 1 / 2 ]
Assuming ρ > 0 , s = E v 2 = E / 2 [ 1 − 1 ] \rho>0,\text{s}=\sqrt{\mathcal{E}}\text{v}_2=\sqrt{\mathcal{E}/2}\left[\begin{matrix}1\\-1\end{matrix}\right] ρ > 0 , s = E v 2 = E / 2 [ 1 − 1 ] → T ( x ) = x T C − 1 s = x T C − 1 E v 2 = E x T 1 λ 2 v 2 = E / 2 1 − ρ ( x [ 0 ] − x [ 1 ] ) \rightarrow T(x) = x^T \mathbf{C}^{-1} s = x^T \mathbf{C}^{-1} \sqrt{\mathcal{E}} v_2 = \sqrt{\mathcal{E}} x^T \frac{1}{\lambda_2} v_2 = \frac{\sqrt{\mathcal{E}/2}}{1 - \rho} \left(x[0] - x[1]\right) → T ( x ) = x T C − 1 s = x T C − 1 E v 2 = E x T λ 2 1 v 2 = 1 − ρ E / 2 ( x [ 0 ] − x [ 1 ] )
Since s [ 1 ] = − s [ 0 ] s[1]=-s[0] s [ 1 ] = − s [ 0 ] ( x [ 0 ] − x [ 1 ] ) (x[0]-x[1]) ( x [ 0 ] − x [ 1 ] ) d 2 = s T C − 1 s = E v 2 T C − 1 v 2 = E v 2 T 1 λ 2 v 2 = E λ 2 = E 1 − ρ d^2 = s^T \mathbf{C}^{-1} s = \mathcal{E} v_2^T \mathbf{C}^{-1} v_2 = \mathcal{E} v_2^T \frac{1}{\lambda_2} v_2 \\[0.2cm] = \frac{\mathcal{E}}{\lambda_2} = \frac{\mathcal{E}}{1 - \rho} d 2 = s T C − 1 s = E v 2 T C − 1 v 2 = E v 2 T λ 2 1 v 2 = λ 2 E = 1 − ρ E
For a large data record and WSS noise,d 2 = ∫ − 1 / 2 1 / 2 ∣ S ( f ) ∣ 2 P w w ( f ) d f d^2 = \int_{-1/2}^{1/2} \frac{|S(f)|^2}{P_{ww}(f)} df d 2 = ∫ − 1 / 2 1 / 2 P w w ( f ) ∣ S ( f ) ∣ 2 d f
Multiple Signals
Sonar/radar systems : detection of a known signal in noise
Binary case
Minimum probability of error criterion & equal prior probabilitiesH 0 : x [ n ] = s 0 [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s 1 [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 s 0 [ n ] , s 1 [ n ] : known deterministic signals, w [ n ] : WGN with variance σ 2 \mathcal{H}_0 : x[n] = s_0[n] + w[n], \quad n = 0, 1, \cdots, N-1 \\[0.2cm] \mathcal{H}_1 : x[n] = s_1[n] + w[n], \quad n = 0, 1, \cdots, N-1 \\[0.2cm] s_0[n], s_1[n] : \text{known deterministic signals,} \quad w[n] : \text{WGN with variance } \sigma^2 H 0 : x [ n ] = s 0 [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 H 1 : x [ n ] = s 1 [ n ] + w [ n ] , n = 0 , 1 , ⋯ , N − 1 s 0 [ n ] , s 1 [ n ] : known deterministic signals, w [ n ] : WGN with variance σ 2
Decide H 1 \mathcal{H}_1 H 1 p ( x ∣ H 1 ) p ( x ∣ H 0 ) > γ = ( C 10 − C 00 ) P ( H 0 ) ( C 01 − C 11 ) P ( H 1 ) = 1 , p ( x ∣ H i ) = 1 ( 2 π σ 2 ) N / 2 exp [ − 1 2 σ 2 ∑ n = 0 N − 1 ( x [ n ] − s i [ n ] ) 2 ] \frac{p(x | \mathcal{H}_1)}{p(x | \mathcal{H}_0)} > \gamma = \frac{(C_{10} - C_{00})P(\mathcal{H}_0)}{(C_{01} - C_{11})P(\mathcal{H}_1)} = 1, \\[0.2cm] p(x | \mathcal{H}_i) = \frac{1}{(2\pi\sigma^2)^{N/2}} \exp \left[ -\frac{1}{2\sigma^2} \sum_{n=0}^{N-1} \left(x[n] - s_i[n]\right)^2 \right] p ( x ∣ H 0 ) p ( x ∣ H 1 ) > γ = ( C 0 1 − C 1 1 ) P ( H 1 ) ( C 1 0 − C 0 0 ) P ( H 0 ) = 1 , p ( x ∣ H i ) = ( 2 π σ 2 ) N / 2 1 exp [ − 2 σ 2 1 n = 0 ∑ N − 1 ( x [ n ] − s i [ n ] ) 2 ]
Decide H i \mathcal{H}_i H i D i 2 = ∑ n = 0 N − 1 ( x [ n ] − s i [ n ] ) 2 is minimum. → minimum distance criterion D i 2 = ( x − s i ) T ( x − s i ) = ∥ x − s i ∥ 2 : squared Euclidean distance → Choose the hypothesis whose signal vector is closest to x Decide H i for which T i ( x ) = ∑ n = 0 N − 1 x [ n ] s i [ n ] − 1 2 ∑ n = 0 N − 1 s i 2 [ n ] = ∑ n = 0 N − 1 x [ n ] s i [ n ] − 1 2 E i D_i^2 = \sum_{n=0}^{N-1} \left(x[n] - s_i[n]\right)^2 \text{ is minimum.} \\[0.2cm] \rightarrow \text{minimum distance criterion} \\[0.2cm] D_i^2 = \left(x - s_i\right)^T \left(x - s_i\right) = \|x - s_i\|^2 \\[0.2cm] \text{: squared Euclidean distance} \\[0.2cm] \rightarrow \text{Choose the hypothesis whose signal vector is closest to } x \\[0.2cm] \text{Decide } \mathcal{H}_i \text{ for which} \\[0.2cm] T_i(x) = \sum_{n=0}^{N-1} x[n]s_i[n] - \frac{1}{2} \sum_{n=0}^{N-1} s_i^2[n] = \sum_{n=0}^{N-1} x[n]s_i[n] - \frac{1}{2}\mathcal{E}_i D i 2 = n = 0 ∑ N − 1 ( x [ n ] − s i [ n ] ) 2 is minimum. → minimum distance criterion D i 2 = ( x − s i ) T ( x − s i ) = ∥ x − s i ∥ 2 : squared Euclidean distance → Choose the hypothesis whose signal vector is closest to x Decide H i for which T i ( x ) = n = 0 ∑ N − 1 x [ n ] s i [ n ] − 2 1 n = 0 ∑ N − 1 s i 2 [ n ] = n = 0 ∑ N − 1 x [ n ] s i [ n ] − 2 1 E i
P e = P ( H 1 ∣ H 0 ) P ( H 0 ) + P ( H 0 ∣ H 1 ) P ( H 1 ) = 1 2 [ P ( H 1 ∣ H 0 ) + P ( H 0 ∣ H 1 ) ] = 1 2 [ Pr { T 1 ( x ) > T 0 ( x ) ∣ H 0 } + Pr { T 0 ( x ) > T 1 ( x ) ∣ H 1 } ] Let T ( x ) = T 1 ( x ) − T 0 ( x ) = ∑ n = 0 N − 1 x [ n ] ( s 1 [ n ] − s 0 [ n ] ) − 1 2 ( E 1 − E 0 ) : Gaussian random variable conditioned on either hypothesis P_e = P(\mathcal{H}_1|\mathcal{H}_0)P(\mathcal{H}_0) + P(\mathcal{H}_0|\mathcal{H}_1)P(\mathcal{H}_1) \\[0.2cm] = \frac{1}{2} \left[ P(\mathcal{H}_1|\mathcal{H}_0) + P(\mathcal{H}_0|\mathcal{H}_1) \right] \\[0.2cm] = \frac{1}{2} \left[ \text{Pr}\{T_1(x) > T_0(x)|\mathcal{H}_0\} + \text{Pr}\{T_0(x) > T_1(x)|\mathcal{H}_1\} \right] \\[0.2cm] \text{Let} \\[0.2cm] T(x) = T_1(x) - T_0(x) = \sum_{n=0}^{N-1} x[n]\left(s_1[n] - s_0[n]\right) - \frac{1}{2} \left(\mathcal{E}_1 - \mathcal{E}_0\right) \\[0.2cm] \text{: Gaussian random variable conditioned on either hypothesis} P e = P ( H 1 ∣ H 0 ) P ( H 0 ) + P ( H 0 ∣ H 1 ) P ( H 1 ) = 2 1 [ P ( H 1 ∣ H 0 ) + P ( H 0 ∣ H 1 ) ] = 2 1 [ Pr { T 1 ( x ) > T 0 ( x ) ∣ H 0 } + Pr { T 0 ( x ) > T 1 ( x ) ∣ H 1 } ] Let T ( x ) = T 1 ( x ) − T 0 ( x ) = n = 0 ∑ N − 1 x [ n ] ( s 1 [ n ] − s 0 [ n ] ) − 2 1 ( E 1 − E 0 ) : Gaussian random variable conditioned on either hypothesis E ( T ∣ H 0 ) = ∑ n = 0 N − 1 s 0 [ n ] ( s 1 [ n ] − s 0 [ n ] ) − 1 2 ( E 1 − E 0 ) = ∑ n = 0 N − 1 s 0 [ n ] s 1 [ n ] − 1 2 ∑ n = 0 N − 1 s 0 2 [ n ] − 1 2 ∑ n = 0 N − 1 s 1 2 [ n ] = − 1 2 ∑ n = 0 N − 1 ( s 1 [ n ] − s 0 [ n ] ) 2 = − 1 2 ∥ s 1 − s 0 ∥ 2 E ( T ∣ H 1 ) = 1 2 ∥ s 1 − s 0 ∥ 2 = − E ( T ∣ H 0 ) var ( T ∣ H 0 ) = var ( ∑ n = 0 N − 1 x [ n ] ( s 1 [ n ] − s 0 [ n ] ) ∣ H 0 ) = ∑ n = 0 N − 1 var ( x [ n ] ) ( s 1 [ n ] − s 0 [ n ] ) 2 = σ 2 ∥ s 1 − s 0 ∥ 2 var ( T ∣ H 1 ) = var ( T ∣ H 0 ) = σ 2 ∥ s 1 − s 0 ∥ 2 E(T|\mathcal{H}_0) = \sum_{n=0}^{N-1} s_0[n](s_1[n] - s_0[n]) - \frac{1}{2}(\mathcal{E}_1 - \mathcal{E}_0) \\[0.2cm] = \sum_{n=0}^{N-1} s_0[n]s_1[n] - \frac{1}{2} \sum_{n=0}^{N-1} s_0^2[n] - \frac{1}{2} \sum_{n=0}^{N-1} s_1^2[n] \\[0.2cm] = -\frac{1}{2} \sum_{n=0}^{N-1} (s_1[n] - s_0[n])^2 = -\frac{1}{2} \| s_1 - s_0 \|^2 \\[0.2cm] E(T|\mathcal{H}_1) = \frac{1}{2} \| s_1 - s_0 \|^2 = -E(T|\mathcal{H}_0) \\[0.2cm] \text{var}(T|\mathcal{H}_0) = \text{var} \left( \sum_{n=0}^{N-1} x[n](s_1[n] - s_0[n]) \big| \mathcal{H}_0 \right) \\[0.2cm] = \sum_{n=0}^{N-1} \text{var}(x[n]) (s_1[n] - s_0[n])^2 \\[0.2cm] = \sigma^2 \| s_1 - s_0 \|^2 \\[0.2cm] \text{var}(T|\mathcal{H}_1) = \text{var}(T|\mathcal{H}_0) = \sigma^2 \| s_1 - s_0 \|^2 E ( T ∣ H 0 ) = n = 0 ∑ N − 1 s 0 [ n ] ( s 1 [ n ] − s 0 [ n ] ) − 2 1 ( E 1 − E 0 ) = n = 0 ∑ N − 1 s 0 [ n ] s 1 [ n ] − 2 1 n = 0 ∑ N − 1 s 0 2 [ n ] − 2 1 n = 0 ∑ N − 1 s 1 2 [ n ] = − 2 1 n = 0 ∑ N − 1 ( s 1 [ n ] − s 0 [ n ] ) 2 = − 2 1 ∥ s 1 − s 0 ∥ 2 E ( T ∣ H 1 ) = 2 1 ∥ s 1 − s 0 ∥ 2 = − E ( T ∣ H 0 ) var ( T ∣ H 0 ) = var ( n = 0 ∑ N − 1 x [ n ] ( s 1 [ n ] − s 0 [ n ] ) ∣ ∣ ∣ H 0 ) = n = 0 ∑ N − 1 var ( x [ n ] ) ( s 1 [ n ] − s 0 [ n ] ) 2 = σ 2 ∥ s 1 − s 0 ∥ 2 var ( T ∣ H 1 ) = var ( T ∣ H 0 ) = σ 2 ∥ s 1 − s 0 ∥ 2 P e = Pr { T > 0 ; H 0 } = Q ( 1 2 ∥ s 1 − s 0 ∥ 2 σ 2 ∥ s 1 − s 0 ∥ 2 ) = Q ( 1 2 ∥ s 1 − s 0 ∥ 2 σ ∥ s 1 − s 0 ∥ ) = Q ( 1 2 ∥ s 1 − s 0 ∥ 2 σ 2 ) Assuming the constraint on the average signal energy E ˉ = 1 2 ( E 0 + E 1 ) , ∥ s 1 − s 0 ∥ 2 = 2 E ˉ − 2 s 1 T s 0 = 2 E ˉ ( 1 − ρ s ) where ρ s = s 1 T s 0 E ˉ : correlation coefficient (different from Pearson correlation coefficient) P e = Q ( E ˉ ( 1 − ρ s ) 2 σ 2 ) P_e = \Pr\{T > 0; \mathcal{H}_0\} = Q\left( \frac{\frac{1}{2} \| s_1 - s_0 \|^2}{\sqrt{\sigma^2 \| s_1 - s_0 \|^2}} \right) \\[0.2cm] = Q \left( \frac{\frac{1}{2} \| s_1 - s_0 \|^2}{\sigma \| s_1 - s_0 \|} \right) \\[0.2cm] = Q \left( \frac{\frac{1}{2} \| s_1 - s_0 \|^2}{\sigma^2} \right) \\[0.2cm] \text{Assuming the constraint on the average signal energy} \\[0.2cm] \bar{\mathcal{E}} = \frac{1}{2} (\mathcal{E}_0 + \mathcal{E}_1), \\[0.2cm] \| s_1 - s_0 \|^2 = 2 \bar{\mathcal{E}} - 2 s_1^T s_0 = 2 \bar{\mathcal{E}} (1 - \rho_s) \\[0.2cm] \text{where } \rho_s = \frac{s_1^T s_0}{\bar{\mathcal{E}}} : \text{correlation coefficient} \\[0.2cm] \text{(different from Pearson correlation coefficient)} \\[0.2cm] P_e = Q \left( \sqrt{\frac{\bar{\mathcal{E}} (1 - \rho_s)}{2 \sigma^2}} \right) P e = Pr { T > 0 ; H 0 } = Q ( σ 2 ∥ s 1 − s 0 ∥ 2 2 1 ∥ s 1 − s 0 ∥ 2 ) = Q ( σ ∥ s 1 − s 0 ∥ 2 1 ∥ s 1 − s 0 ∥ 2 ) = Q ( σ 2 2 1 ∥ s 1 − s 0 ∥ 2 ) Assuming the constraint on the average signal energy E ˉ = 2 1 ( E 0 + E 1 ) , ∥ s 1 − s 0 ∥ 2 = 2 E ˉ − 2 s 1 T s 0 = 2 E ˉ ( 1 − ρ s ) where ρ s = E ˉ s 1 T s 0 : correlation coefficient (different from Pearson correlation coefficient) P e = Q ( 2 σ 2 E ˉ ( 1 − ρ s ) )
Example of phase shift keying(PSK)s 0 [ n ] = A cos 2 π f 0 n s 1 [ n ] = A cos ( 2 π f 0 n + π ) = − A cos 2 π f 0 n ρ s = s 1 T s 0 E ˉ = − 1 ⟹ P e = Q ( E ˉ σ 2 ) s_0[n] = A \cos 2 \pi f_0 n \\[0.2cm] s_1[n] = A \cos (2 \pi f_0 n + \pi) = -A \cos 2 \pi f_0 n \\[0.2cm] \rho_s = \frac{s_1^T s_0}{\bar{\mathcal{E}}} = -1 \implies P_e = Q \left( \sqrt{\frac{\bar{\mathcal{E}}}{\sigma^2}} \right) s 0 [ n ] = A cos 2 π f 0 n s 1 [ n ] = A cos ( 2 π f 0 n + π ) = − A cos 2 π f 0 n ρ s = E ˉ s 1 T s 0 = − 1 ⟹ P e = Q ( σ 2 E ˉ )
Example of frequency shift keying(FSK)s 0 [ n ] = A cos 2 π f 0 n , n = 0 , ⋯ , N − 1 s 1 [ n ] = A cos 2 π f 1 n , n = 0 , ⋯ , N − 1 ∙ If ∣ f 1 − f 0 ∣ ≫ 1 2 N , the signals are approximately orthogonal. ρ s = 0 ⟹ P e = Q ( E ˉ 2 σ 2 ) s_0[n] = A \cos 2 \pi f_0 n, \quad n = 0, \cdots, N-1 \\[0.2cm] s_1[n] = A \cos 2 \pi f_1 n, \quad n = 0, \cdots, N-1 \\[0.2cm] \bullet \ \text{If } |f_1 - f_0| \gg \frac{1}{2N}, \ \text{the signals are approximately orthogonal.} \\[0.2cm] \rho_s = 0 \implies P_e = Q \left( \sqrt{\frac{\bar{\mathcal{E}}}{2 \sigma^2}} \right) s 0 [ n ] = A cos 2 π f 0 n , n = 0 , ⋯ , N − 1 s 1 [ n ] = A cos 2 π f 1 n , n = 0 , ⋯ , N − 1 ∙ If ∣ f 1 − f 0 ∣ ≫ 2 N 1 , the signals are approximately orthogonal. ρ s = 0 ⟹ P e = Q ( 2 σ 2 E ˉ )
M-ARY Case
M M M s 0 [ n ] , s 1 [ n ] , ⋯ , s M − 1 [ n ] s_0[n],s_1[n],\cdots,s_{M-1}[n] s 0 [ n ] , s 1 [ n ] , ⋯ , s M − 1 [ n ]
Choose H i \mathcal{H}_i H i p ( x ∣ H i ) p(\text{x}|\mathcal{H}_i) p ( x ∣ H i )
Choose H k \mathcal{H}_k H k T k ( x ) = ∑ n = 0 N − 1 x [ n ] s k [ n ] − 1 2 E k is the maximum statistic of { T 0 ( x ) , T 1 ( x ) , ⋯ , T M − 1 ( x ) } . T_k(\mathbf{x}) = \sum_{n=0}^{N-1} x[n] s_k[n] - \frac{1}{2} \mathcal{E}_k \\[0.2cm] \text{is the maximum statistic of } \{T_0(\mathbf{x}), T_1(\mathbf{x}), \cdots, T_{M-1}(\mathbf{x})\}. T k ( x ) = n = 0 ∑ N − 1 x [ n ] s k [ n ] − 2 1 E k is the maximum statistic of { T 0 ( x ) , T 1 ( x ) , ⋯ , T M − 1 ( x ) } .
In general, difficult to evaluate the probability of error
Assume that the signals are orthogonal and have equal energies E i = E \mathcal{E}_i=\mathcal{E} E i = E cov ( T i , T j ; H i ) = E ( ∑ n = 0 N − 1 w [ n ] s i [ n ] ∑ n = 0 N − 1 w [ n ] s j [ n ] ) = ∑ m = 0 N − 1 ∑ n = 0 N − 1 E ( w [ m ] w [ n ] ) s i [ m ] s j [ n ] = σ 2 ∑ n = 0 N − 1 s i [ n ] s j [ n ] = 0 for i ≠ j P e = ∑ i = 0 M − 1 Pr { T i < max ( T 0 , ⋯ , T i − 1 , T i + 1 , ⋯ , T M − 1 ) ∣ H i } P ( H i ) = Pr { T 0 < max ( T 1 , T 2 , ⋯ , T M − 1 ) ∣ H 0 } . \text{cov}(T_i, T_j; \mathcal{H}_i) = E \left( \sum_{n=0}^{N-1} w[n] s_i[n] \sum_{n=0}^{N-1} w[n] s_j[n] \right) \\[0.2cm] = \sum_{m=0}^{N-1} \sum_{n=0}^{N-1} E(w[m] w[n]) s_i[m] s_j[n] \\[0.2cm] = \sigma^2 \sum_{n=0}^{N-1} s_i[n] s_j[n] = 0 \quad \text{for } i \neq j \\[0.2cm] P_e = \sum_{i=0}^{M-1} \text{Pr} \{T_i < \max(T_0, \cdots, T_{i-1}, T_{i+1}, \cdots, T_{M-1}) \; | \; \mathcal{H}_i\} P(\mathcal{H}_i) \\[0.2cm] = \text{Pr} \{T_0 < \max(T_1, T_2, \cdots, T_{M-1}) \; | \; \mathcal{H}_0\}. cov ( T i , T j ; H i ) = E ( n = 0 ∑ N − 1 w [ n ] s i [ n ] n = 0 ∑ N − 1 w [ n ] s j [ n ] ) = m = 0 ∑ N − 1 n = 0 ∑ N − 1 E ( w [ m ] w [ n ] ) s i [ m ] s j [ n ] = σ 2 n = 0 ∑ N − 1 s i [ n ] s j [ n ] = 0 for i = j P e = i = 0 ∑ M − 1 Pr { T i < max ( T 0 , ⋯ , T i − 1 , T i + 1 , ⋯ , T M − 1 ) ∣ H i } P ( H i ) = Pr { T 0 < max ( T 1 , T 2 , ⋯ , T M − 1 ) ∣ H 0 } .
Conditioned on H 0 \mathcal{H}_0 H 0 T i ( x ) = ∑ n = 0 N − 1 x [ n ] s i [ n ] − 1 2 E i ∼ { N ( 1 2 E i , σ 2 E ) , for i = 0 N ( − 1 2 E i , σ 2 E ) , for i ≠ 0 P e = 1 − Pr { T 0 > max ( T 1 , T 2 , ⋯ , T M − 1 ) ∣ H 0 } = 1 − Pr { T 1 < T 0 , T 2 < T 0 , ⋯ , T M − 1 < T 0 ∣ H 0 } = 1 − ∫ − ∞ ∞ Pr { T 1 < t , T 2 < t , ⋯ , T M − 1 < t ∣ T 0 = t , H 0 } p T 0 ( t ) d t = 1 − ∫ − ∞ ∞ ∏ i = 1 M − 1 Pr { T i < t ∣ H 0 } p T 0 ( t ) d t . T_i(\mathbf{x}) = \sum_{n=0}^{N-1} x[n] s_i[n] - \frac{1}{2} \mathcal{E}_i \sim \begin{cases} \mathcal{N} \left( \frac{1}{2} \mathcal{E}_i, \sigma^2 \mathcal{E} \right), & \text{for } i = 0 \\[0.2cm] \mathcal{N} \left( -\frac{1}{2} \mathcal{E}_i, \sigma^2 \mathcal{E} \right), & \text{for } i \neq 0 \end{cases} \\[0.4cm] P_e = 1 - \text{Pr} \{ T_0 > \max(T_1, T_2, \cdots, T_{M-1}) \; | \; \mathcal{H}_0 \} \\[0.2cm] = 1 - \text{Pr} \{ T_1 < T_0, T_2 < T_0, \cdots, T_{M-1} < T_0 \; | \; \mathcal{H}_0 \} \\[0.2cm] = 1 - \int_{-\infty}^\infty \text{Pr} \{ T_1 < t, T_2 < t, \cdots, T_{M-1} < t \; | \; T_0 = t, \mathcal{H}_0 \} p_{T_0}(t) \, dt \\[0.2cm] = 1 - \int_{-\infty}^\infty \prod_{i=1}^{M-1} \text{Pr} \{ T_i < t \; | \; \mathcal{H}_0 \} p_{T_0}(t) \, dt. T i ( x ) = n = 0 ∑ N − 1 x [ n ] s i [ n ] − 2 1 E i ∼ ⎩ ⎪ ⎨ ⎪ ⎧ N ( 2 1 E i , σ 2 E ) , N ( − 2 1 E i , σ 2 E ) , for i = 0 for i = 0 P e = 1 − Pr { T 0 > max ( T 1 , T 2 , ⋯ , T M − 1 ) ∣ H 0 } = 1 − Pr { T 1 < T 0 , T 2 < T 0 , ⋯ , T M − 1 < T 0 ∣ H 0 } = 1 − ∫ − ∞ ∞ Pr { T 1 < t , T 2 < t , ⋯ , T M − 1 < t ∣ T 0 = t , H 0 } p T 0 ( t ) d t = 1 − ∫ − ∞ ∞ i = 1 ∏ M − 1 Pr { T i < t ∣ H 0 } p T 0 ( t ) d t . = 1 − ∫ − ∞ ∞ Φ M − 1 ( t + 1 2 E σ 2 E ) 1 2 π σ 2 E exp [ − 1 2 σ 2 E ( t − 1 2 E ) 2 ] d t = 1 − ∫ − ∞ ∞ Φ M − 1 ( u ) 1 2 π exp [ − 1 2 ( u − E σ 2 ) 2 ] d u where Φ ( ⋅ ) is the CDF of N ( 0 , 1 ) random variable. = 1 - \int_{-\infty}^\infty \Phi^{M-1} \left( \frac{t + \frac{1}{2} \mathcal{E}}{\sqrt{\sigma^2 \mathcal{E}}} \right) \frac{1}{\sqrt{2\pi \sigma^2 \mathcal{E}}} \exp \left[ -\frac{1}{2\sigma^2 \mathcal{E}} \left( t - \frac{1}{2} \mathcal{E} \right)^2 \right] dt \\[0.4cm] = 1 - \int_{-\infty}^\infty \Phi^{M-1}(u) \frac{1}{\sqrt{2\pi}} \exp \left[ -\frac{1}{2} \left( u - \sqrt{\frac{\mathcal{E}}{\sigma^2}} \right)^2 \right] du \\[0.4cm] \text{where } \Phi(\cdot) \text{ is the CDF of } \mathcal{N}(0,1) \text{ random variable.} = 1 − ∫ − ∞ ∞ Φ M − 1 ( σ 2 E t + 2 1 E ) 2 π σ 2 E 1 exp [ − 2 σ 2 E 1 ( t − 2 1 E ) 2 ] d t = 1 − ∫ − ∞ ∞ Φ M − 1 ( u ) 2 π 1 exp ⎣ ⎢ ⎡ − 2 1 ( u − σ 2 E ) 2 ⎦ ⎥ ⎤ d u where Φ ( ⋅ ) is the CDF of N ( 0 , 1 ) random variable.
All Content has been written based on lecture of Prof. eui-seok.Hwang in GIST(Detection and Estimation)