Q-Learning Algorithm
Sarsa와의 차이점은 행동가치 함수 를 수정하는 식만 다르다는 것이다
Sarsa
Q-Learning
Sarsa알고리즘에서는 다음에 취할 행동 을 구해서 행동가치 함수를 수정하는 데 사용했다- 그러나,
Q러닝에서는 상태 에 대한 각행동가치 함수값중가장 값이 큰 것을 사용해 행동가치 를 수정한다 - 또한
Sarsa는 다음 단계의 행동 을 사용해 행동가치 함수 를 수정하므로 를 수정할 때 을 구하기 위해정책에 의존한다는 특징이 있다이러한 특징을
온-폴리시(on-policy)라고 한다 - 이와 달리
Q러닝은 행동가치 함수 를 수정할 때정책에 의존하지 않는다이러한 특징을
오프-폴리시(off-policy)라고 한다 - -greedy 알고리즘 특성상 나타나는 무작위 행동이 수정식에 포함되지 않는 만큼 행공가치 함수가
Sarsa보다 빨리 수렴하는 것이 특징
Q-Learning 구현
# Q러닝 알고리즘으로 행동가치 함수 Q를 수정
def Q_learning(s, a, r, s_next, Q, eta, gamma) :
if s_next == 8 : # 목표 지점에 도달한 경우
Q[s, a] = Q[s, a] + eta * (r - Q[s, a])
else :
Q[s, a] = Q[s, a] + eta * (r + gamma * np.nanmax(Q[s_next, :]) - Q[s, a])
return QQ러닝에서 수정한 함수에 맞춰 이를 실행하는 goal_maze_ret_s_a_Q 함수에서도 함수Sarsa를 호출하던 부분을Q-learning으로 수정한다
# 행동가치 함수 Q의 초기 상태
[a, b] = theta_0.shape # 열과 행의 개수를 a, b 변수에 저장
Q = np.random.rand(a, b) * theta_0 * 0.1
# * theta_0으로 요소 단위 곱셈을 수행, Q에서 벽 방향으로 이동하는 행동에는 nan을 부여- 그리고
Q러닝으로 미로를 푸는 부분에서는 에피소드별로상태가치함수의 값을 변수 에 저장해둔다
# Sarsa 알고리즘으로 미로 빠져나오기
eta = 0.1 # 학습률
gamma = 0.9 # 시간할인율
epsilon = 0.5 # epsilon-greedy 알고리즘 epsilon 초깃값
v = np.nanmax(Q, axis = 1) # 각 상태마다 가치의 최댓값을 계산
is_continue = True
episode = 1
V = [] # 에피소드별로 상태가치를 저장
V.append(np.nanmax(Q, axis = 1)) # 상태별로 행동가치의 최댓값을 계산
while is_continue : # is_continue의 값이 False가 될 때까지 반복
print('에피소드 :'+str(episode))
# epsilon 값을 조금씩 감소시킴
epsilon = epsilon / 2
# Sarsa 알고리즘으로 미로를 빠져나온 후, 결과로 나온 행동 히스토리와 Q값을 변수에 저장
[s_a_history, Q] = goal_maze_ret_s_a_Q(Q, epsilon, eta, gamma, pi_0)
# 상태가치의 변화
new_v = np.nanmax(Q, axis = 1) # 각 상태마다 행동가치의 최댓값을 계산
print(np.sum(np.abs(new_v - v))) # 상태가치 함수의 변화를 출력
v = new_v
print("목표 지점까지의 단계 수 :" + str(len(s_a_history)))
# 100 에피소드 반복
episode += 1
if episode > 100:
break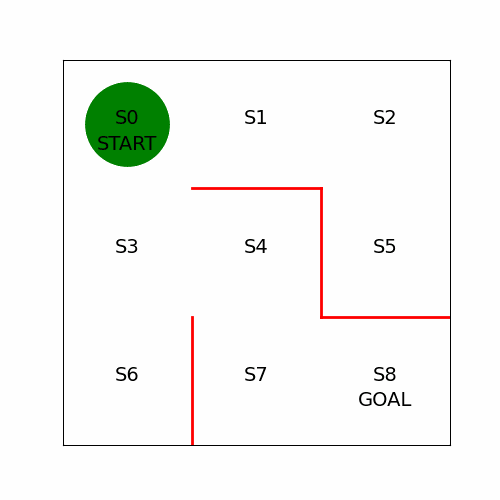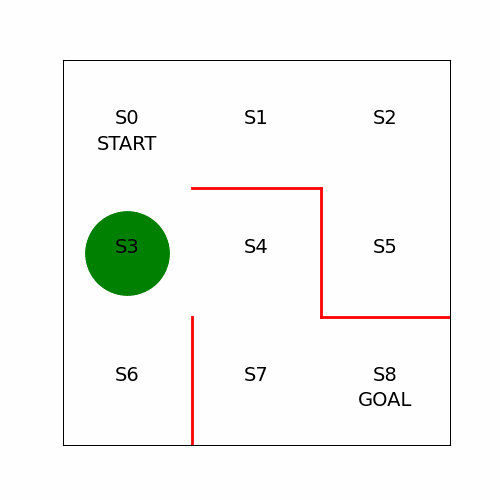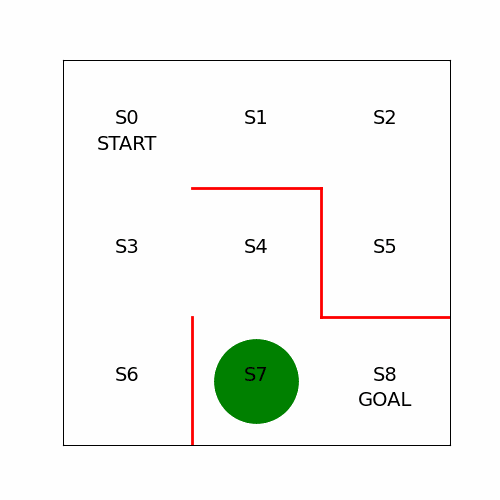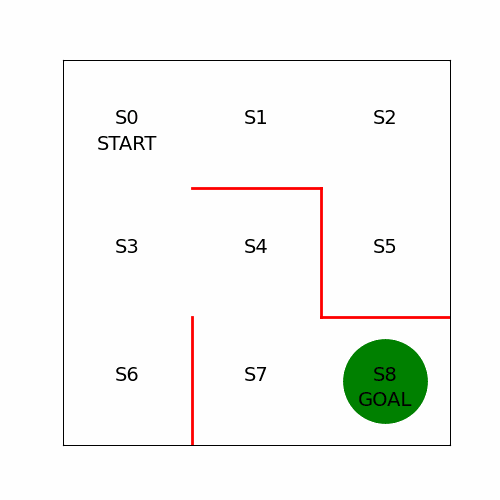

AI, Security