[논문 리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2021)
2022 하계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2022년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
-
Transformer 구조는 NLP 분야에서 높은 성능을 보이며 표준으로 자리잡는데에 반해,
Computer Vision 분야에서는 아직 제한적이었음. -
Computer Vision 분야에서 Attention은 CNN에 결합해서 쓰거나, CNN의 구성 요소를 대체하는 식으로 간접적으로만 사용됨.
-
논문을 발표한 구글팀은 이미지 분야에서 CNN에 대한 의존을 끊고 Transformer를 직접적으로 사용하기 위해 image를 patch로 잘라 Sequence로서 사용하는 방식으로 이미지 분류를 수행.
-
거대한 양의 데이터셋 (ImageNet, JFT)으로 pre-train한 후, 중간 사이즈 혹은 적은 양의 이미지 데이터셋에 대해 transfer하는 방식으로 기존의 ResNet 기반의 SOTA 모델들보다 좋은 성능 & 적은 계산량을 보임.
1. Introduction

Transformer는 Self-attention을 사용한 구조로, 자연어처리(NLP) 분야에서 높은 성능을 거두며 거의 표준으로 사용되고 있습니다.
해당 방법론은 거대한 text corpus로부터 pre-train한 후 작은 task의 데이터셋에 대해서 fine-tune하여 처리하는 방식입니다.
특히 Transformer의 적은 계산량과 높은 확장성으로 인해, 100B가 넘어가는 막대한 parameter를 가지는 모델도 학습이 가능하게 되었습니다. 현실의 데이터셋이 점점 더 커지는 가운데 이는 현실 상황에 적합한 모델로 평가할 수 있습니다.
Computer Vision 분야에서는 ViT 논문이 발표되기 전까지는 여전히 CNN 기반 모델들이 지배적이었습니다.
NLP 분야에서의 성공에 힘입어, CNN 구조의 모델들에 Self-attention을 접목시키려는 노력은 있었습니다. 게다가 CNN 구조를 통째로 Transformer로 바꾸려는 노력도 있었는데요, 이는 이론적으로는 괜찮아보이나, specialized된 attention 패턴을 보여서 계산상으로 비효율적이었습니다.
구글팀은 이러한 상황에서 거의 수정을 거치지 않은 표준 그대로의 Transformer를 이미지에 적용해보고자 했습니다.
아이디어는 다음과 같습니다.
이미지를 일정한 크기의 Patch로 나눠서, 이를 단어의 배열처럼 Sequence로 사용하자!
그렇게 한다면 이미지 패치는 NLP 분야에서 Token (Words)처럼 처리하면 될 것!
(이러한 아이디어때문인지 논문의 제목도 이미지를 16x16 단어로 표현합니다.)
구글팀은 먼저 ImageNet과 같은 mid-sized 데이터셋으로 학습시켰는데요, 이는 ResNet 기반 모델들에 비해 살짝 안 좋은 성능을 보였습니다. 이러한 결과는 어떻게 보면 당연한 것이었는데요. 그 이유는 바로 Inductive bias 때문입니다.
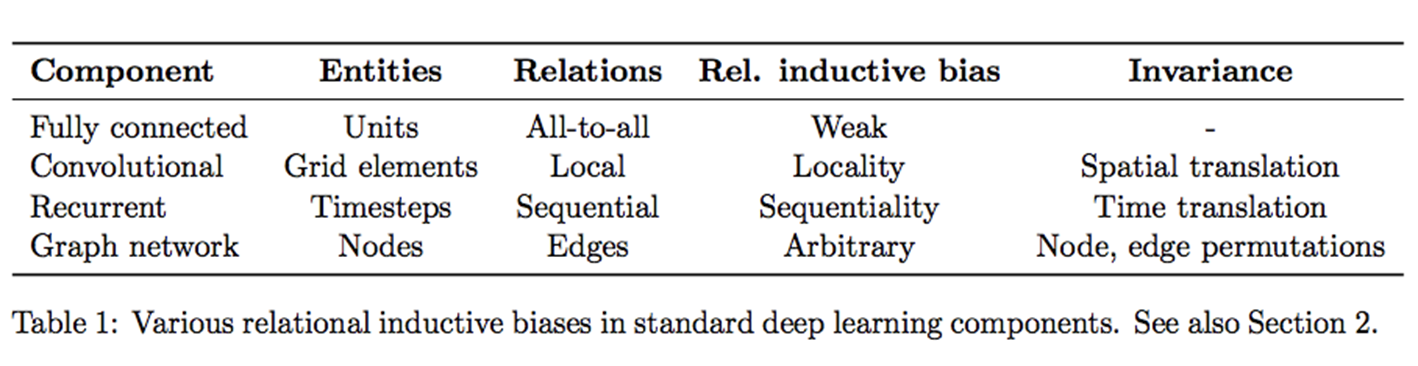
여기서 Inductive bias란 주어지지 않은 입력의 출력을 예측하는 능력입니다.
즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정(Additional Assumptions)으로 볼 수 있습니다.
위 표에서 보이는건 Fully connected layer의 경우 inductive bias가 낮고, CNN이나 RNN 계열의 경우 Relative Inductive bias가 존재합니다.
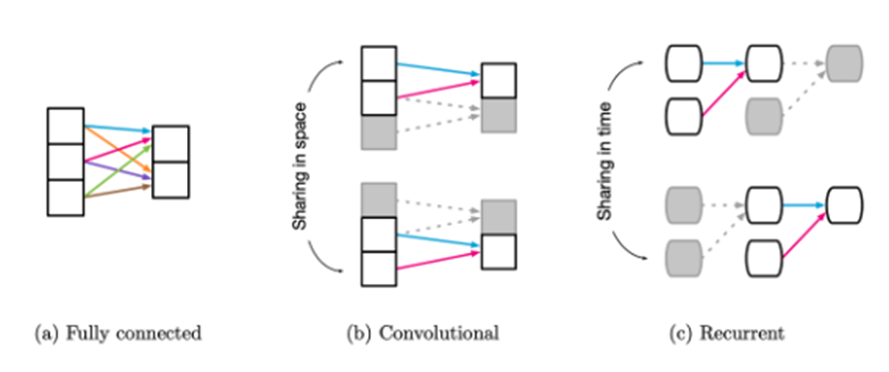
FC layer의 경우 모든 입력의 요소가 어떤 출력 요소던지 영향을 미칠 수 있습니다.
반면, CNN은 Convolution Filter가 입력의 요소를 Window Sliding 하게되면서 위치 정보 즉, locality를 다음 layer로 전달 가능합니다.
CNN과 마찬가지로 RNN도 inductive bias가 있는데요, CNN이 공간의 개념을 사용한 것 처럼, RNN은 시간의 개념을 사용합니다. 그래서 Sequential & Temporal한 Invariance가 존재합니다.
다시 Transformer로 돌아와보면 Transformer는 Attention만을 사용할 뿐, CNN과 RNN 구조에 전혀 의존하지 않습니다. Attention은 Query, Key, Value로 나누어서 Attention Score를 계산하고 이를 통해 Sequence가 다른 Sequence의 요소들과 어느 정도의 연관이 있는지를 나타냅니다. 따라서 FCN 처럼 모든 입력의 요소가 어떤 출력 요소던지 영향을 미칠 수 있다고 생각할 수 있으며 Inductive Bias가 약해집니다.
그래서 구글팀은 mid-sized 데이터셋에 대해서는 높은 Inductive Bias를 지닌 CNN 계열인 ResNet에 비해서 낮은 성능을 보일 수 있다고 지적합니다. 하지만 14M-300M의 거대한 데이터셋으로 학습을 한다면 large scale이 inductive bias를 이길 수 있다고 주장합니다. 따라서 ImageNet-21k 혹은 JFT-300M의 데이터셋으로 사전학습해서 전이학습했을 때 SOTA의 성능을 거둡니다.
2. Related Work
먼저 Transformer는 2017년 기계 번역을 위해서 제안되었고 많은 NLP task에 있어서 SOTA의 성능을 보였습니다. 앞서 말한대로, 거대한 Corpora로 학습하고 실제 task에 대해서 fine-tune하는 방식이며 이를 활용한 유명한 모델은 BERT와 GPT가 있습니다.
Self-attention을 이미지에 적용하는 것을 간단하게 생각했을 때 각 픽셀이 각각의 픽셀에게 attend하는 걸 생각해볼 수 있습니다.
하지만 그렇게 된다면 pixel의 수에 따라 엄청나게 많은 cost가 소요될 수도 있어서 현실적이지 못합니다.
이를 해결하면서 Transformer를 적용하려는 무수한 노력들이 있었고, 이는 논문에 자세하게 나와있으니 Reference로서 궁금하신 분들은 논문을 살펴보면 되겠습니다.
3. Method
구글팀은 최대한 original 형태의 Transformer를 이미지에 사용하고자 했고 해당 노력의 결과로 탄생한 Visual Transformer 구조의 모습은 아래와 같습니다.
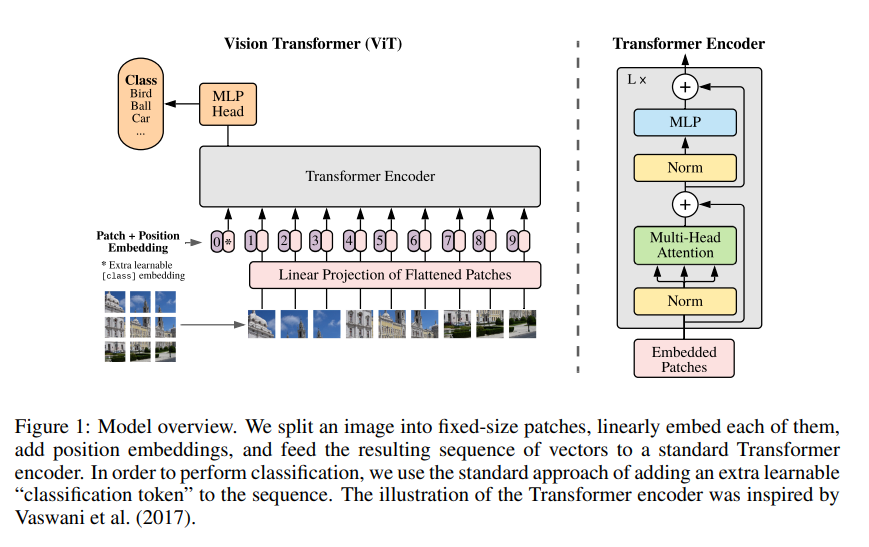
3.1 Vision Transformer (ViT)
ViT의 작동 과정은 5개의 Step으로 설명 가능합니다.
- Step 1. 이미지 가 있을 때, 이미지를 크기의 패치 개로 분할하여 sequence 를 구축함.
여기서 는 원본 이미지의 해상도, 는 채널의 수, 는 이미지 패치의 해상도 입니다.- Step 2. Trainable linear projection을 통해 의 각 패치를 flatten한 벡터 차원으로 변환한 후, 이를 패치 임베딩으로 사용함.
- Step 3. Learnable class 임베딩과 패치 임베딩에 learnable position 임베딩을 더함.
여기서 Learnable class는 BERT 모델의 토큰과 같이 classification 역할을 수행합니다.- Step 4. 임베딩을 Transformer encoder에 input으로 넣어 마지막 layer에서 class embedding에 대한 output인 image representation을 도출함
여기서 image representation이란 L번의 encoder를 거친 후의 output 중 learnable class 임베딩과 관련된 부분을 의미합니다.- Step 5. MLP에 image representation을 input으로 넣어 이미지의 class를 분류함.
이와 관련한 수식은 다음과 같습니다.

Step 1~3까지는 (1)번 수식, Step 4는 (2), (3)번 수식, Step 5는 (4)번 수식과 연결됩니다.
Inductive Bias
ViT에서 MLP는 locality와 translation equivariance가 있습니다. 왜냐하면 이미지 패치를 sequential하게 잘라서 임베딩했기 때문입니다. 하지만 MSA는 global하기 때문에 CNN보다 image-specific inductive bias가 낮습니다.
따라서 ViT에서는 모델에 두가지 방법을 사용하여 inductive bias의 주입을 시도합니다.
- Patch extraction: cutting the image into patches
- Resolution adjustment: adjusing the position embeddings for images of diffrent resolution at fine-tuning
Hybrid Architecture
ViT의 입력으로 raw image가 아닌 CNN으로 추출한 raw image의 feature map을 활용할 수 있습니다.
Feature map은 이미 raw image의 공간적 정보를 포함하고 있으므로 패치를 자를 때 1x1로 설정해도 됩니다.
그렇게 한다면 feature map의 공간 차원을 flatten하여 각 벡터에 linear projection을 적용하면 됩니다.
3.2 Fine-Tuning And Higher Resolution
이제 ViT의 구동 방법을 알았으니 어떻게 활용하면 될까?
논문의 저자는 ViT를 large dataset으로 pre-train하고 downstream task에 fine-tune하여 사용합니다.
위와 같은 경우에는 pre-trained prediction head를 제거하고 zero-initialized feedforward layer로 대체하면 됩니다.
대체가 이루어진다면 pre-training 시보다 더 높은 해상도를 fine-tune하는 것에 도움이 됩니다.
높은 해상도의 이미지를 모델에 적용한다면, patch size는 그대로 가져갈 것이고, 그렇다면 상당히 큰 sequence length를 갖게 됩니다.
물론 ViT는 가변적 길이의 패치를 처리할 수는 있지만, pre-trained position embeddings는 의미를 잃게 됩니다. 이 경우 pre-trained position embedding을 원본 이미지의 위치에 따라 2D interpolation하면 됩니다.
4. Experiments
4.1 Setup
Datasets
| Pre-trained Dataset | # of Classes | # of Images |
|---|---|---|
| ImageNet-1k | 1k | 1.3M |
| ImageNet-21k | 21k | 14M |
| JFT | 18k | 303M |
| (High resolution) |
ViT는 위와 같이 3개의 데이터셋으로 pre-train 됩니다.
그 후 이를 몇가지 benchmark tasks에 transfer 합니다. benchmark tasks는 다음과 같습니다.
- ReaL labels, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102
- 19-task VTAB classification suite
Model Variants
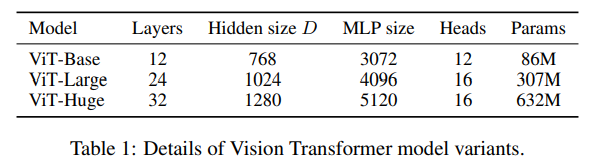
ViT는 총 3개의 volume에 대해서 실험을 진행했으며, 각 볼륨에서도 다양한 패치 크기에 대해 실험을 진행했습니다.
여기서 Base와 Large 모델은 BERT 모델에서 직접적으로 채택했으며, Huge는 저자들이 추가한 것입니다.
본 논문의 저자인 구글 팀은 이전 논문으로 transfer learning에 적합한 Big Transformer (BiT) 구조의 ResNet을 발표했습니다. 이는 batch normalization layer를 group normalization으로 변경하고 standardized convolutional leyer를 사용한 모델입니다.
해당 모델을 비교군으로 삼아 실험을 진행합니다.
Metrics
평가 지표로는 few-shot accuracy와 fine-tuning accuracy를 고려합니다.
- Few-shot accuracy: Training set에 없는 클래스를 맞추는 문제에 대한 정확도
- Fine-tuning accuracy: Fine-tuning 후의 정확도
본 논문의 저자는 fine-tuning의 성능에 집중하고 있기에 fine-tuning accuracy를 사용하지만 fine-tuning의 cost가 너무 크기 때문에 빠른 평가를 위해 때때로는 few-shot accuracies를 사용했습니다.
4.2 Comparison To State Of The Art
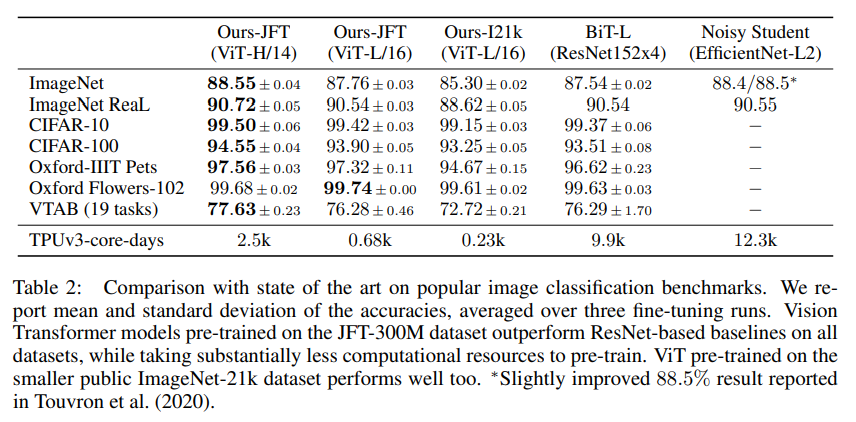
거의 모든 데이터셋에서 ViT-H/14 모델이 가장 높은 성능을 보였습니다. 이는 기존 SOTA 모델인 BiT-L 보다도 높은 성능이며 더 적은 시간이 걸렸습니다. 또한 주목할 점은 이보다 작은 모델인 ViT-L/16 또한 BiT-L보다 높은 성능을 보였으며 시간은 훨씬 적게 걸렸다는 것입니다.
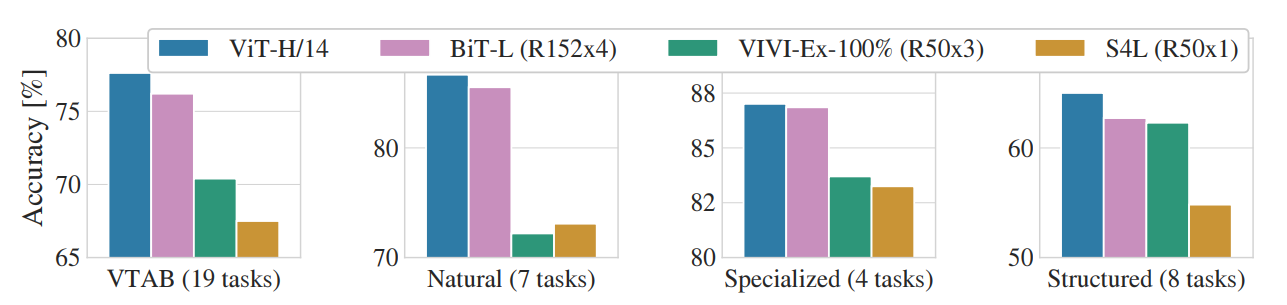
VTAB 데이터셋에서도 ViT-H/14 모델이 가장 좋은 성능을 보였습니다. 해당 실험은 데이터셋을 3개의 그룹으로 나누어 진행한 실험인데 그룹은 다음과 같습니다.
- Natural: tasks like Pets, CIFAR, etc
- Specialized: medical and satellite imagery
- Structured: tasks that require geometric understanding like localization
4.3 Pre-training Data Requirements
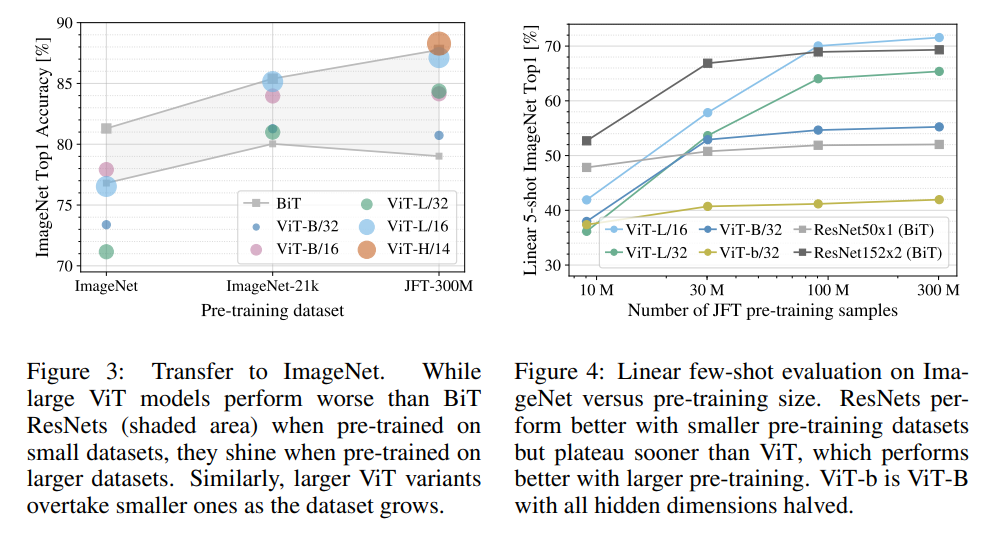
Figure 3 실험을 통해 알 수 있는 것은 크기가 큰 데이터셋으로 pre-training 하는 경우 BiT보다 ViT가 더 높은 성능을 띄고, 반대의 경우는 반대의 성능을 띈다는 것입니다.
Figure 4 실험은 JFT 데이터셋을 각각 다른 크기로 랜덤 샘플링한 데이터셋을 활용하여 진행한 것입니다. 이를 통해 작은 데이터셋에서는 확실히 inductive bias 효과가 있는 CNN 계열의 BiT가 높은 성능을 보이나, 큰 데이터셋으로 갈수록 ViT 성능이 더 좋아지는 것을 확인할 수 있습니다.
4.4 Scaling Study
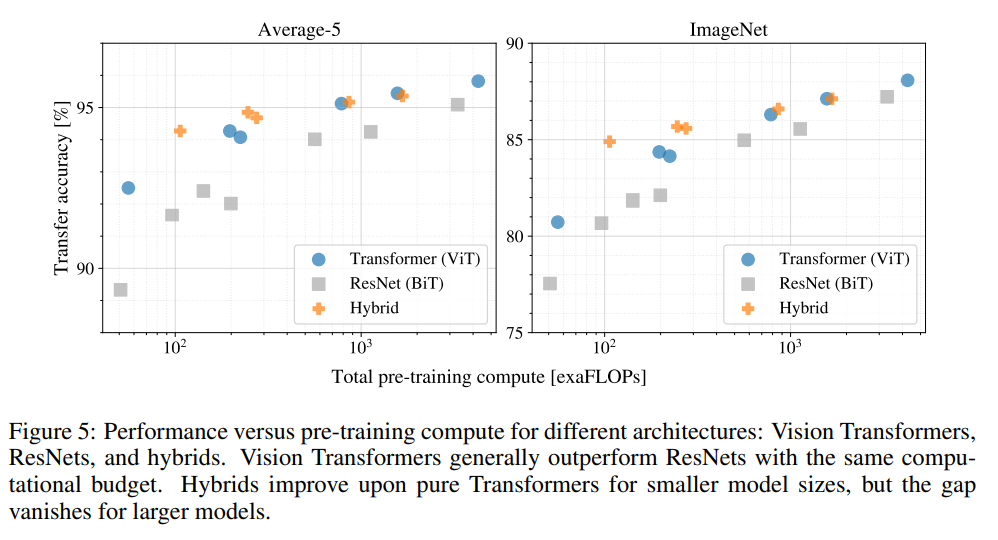
Figure 5를 통해 같은 시간이 소모되었을 때 ViT가 더 높은 성능을 거두는 것을 확인할 수 있었습니다. 따라서 성능과 cost의 trade-off에서 ViT가 BiT보다 우세한 것을 검증해냈습니다.
또한 Cost가 낮을 때는 Hybrid가 ViT보다 유리한 듯 하지만 Cost가 높아지면서 trade-off 차이가 감소합니다.
4.5 Inspecting Vision Transformer
결국은 ViT는 이미지를 처리하는 모델이기에 저자들은 시각적으로 어떻게 이미지를 처리하는지를 이해하기 위한 실험을 진행했습니다.

왼쪽부터 살펴보면, flatten된 패치를 패치 임베딩으로 변환하는 linear projection의 principal components를 분석한 모습입니다. 이를 통해 저차원의 CNN Filter 기능과 유사하다는 것을 알 수 있습니다.
가운데를 살펴보면, 패치 간 position embedding의 유사도를 통해 가까운 위치에 있는 패치들의 position embedding이 유사한지를 확인하는 모습입니다. 실제로 2D 이미지 모양대로 가까이 있는 패치들끼리 유사도가 높음을 확인할 수 있습니다.
오른쪽을 살펴보면, ViT의 layer별 평균 attention distance를 확인한 결과, 초반 layer에서도 attention을 통해 이미지 전체의 정보를 통합하여 사용함을 알 수 있었습니다.

또한 attention을 사용한 만큼 task를 수행할 때 이미지의 어느 부분에 집중하는지를 파악할 수 있었습니다.
5. Conclusion
-
image-specific inductive biases를 특별하게 사용하지 않고, 이미지를 패치로 자른 sequence를 NLP에서 사용하는 Transformer encoder에 넣어서 self-attention을 사용함.
-
특히 large datasets으로 pre-train 시킴으로써 기존의 SOTA 모델들을 능가하는 성능과 더 적은 computational cost가 소요.
-
여전히 Challenge는 존재. 1. Detection과 Segmentation 2. Self-Supervised Learning
Reference
유튜브
https://www.youtube.com/watch?v=0kgDve_vC1o
블로그
https://velog.io/@changdaeoh/Vision-Transformer-Review
함께 읽으면 좋을 논문
Transformaly - Two (Feature Spaces) Are Better Than One
(리뷰)Transformaly - Two (Feature Spaces) Are Better Than One

이 리뷰에 따르면 Vision Transformers는 더 뛰어난 성능과 더 저렴한 컴퓨팅 비용으로 사진 인식에 혁명을 일으킬 수 있습니다. NLP와 컴퓨터 비전의 결합은 매력적이며 시각적 문제에 대한 새로운 방법을 가능하게 합니다. strands game