
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2022년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
-
Anomaly detection pipeline은 2개의 main stages로 구성됨.
(1) feature extraction (2) normality score assignment -
최근 연구들은 feature extraction위해 pre-trained network를 사용하여 SOTA 달성.
-
하지만 그동안의 pre-trained network는 train 시 normal samples에 대해 '완전하게 사용'하지 못함.
-
본 논문은 teacher-student 학습을 통해 이를 해결함.
-
Pre-trained된 teacher network는 student network를 오직 normal samples 들로만 학습시킴.
-
Student network가 오직 정상 데이터로만 학습되었기에, teacher network의 abnormal case로부터 멀어질 수 있음.
-
둘의 차이는 Pre-trained feature vector에 보완적으로 사용될 수 있으며, teacher-student feature vector로 표현됨.
-
따라서 Transformaly는 사전 학습된 ViT를 통해 (1) pre-trained (agnostic) features와 (2) teacher-student (fine-tuned) features를 추출함.
-
실험을 통해, Unimodal(클래스 하나만 정상 나머지 비정상), Multimodal(클래스 하나만 비정상 나머지 정상) 두 경우에서 SOTA AUROC 결과를 얻음.
1. Introduction
Anomaly detection은 오래 연구되었고 다루는 분야가 다양하여 많은 각각의 문제들이 존재합니다.
그 중에서 multi-class classifcation task에서는 종종 out-of-distribution (OOD) detection과 novelty detection 용어가 사용됩니다.
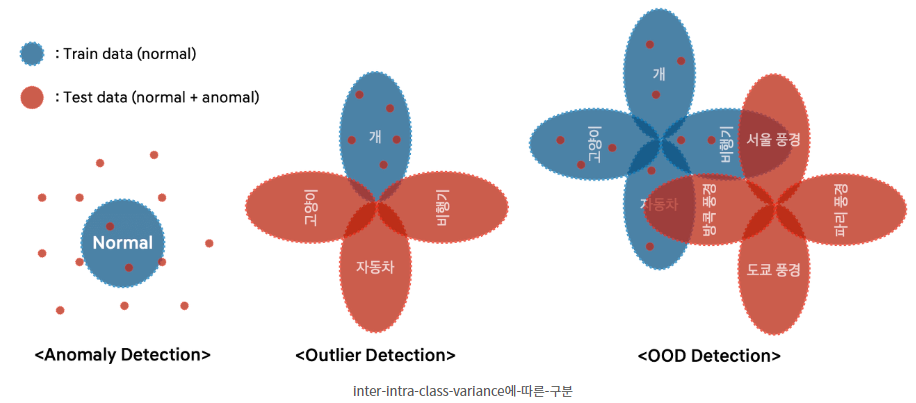
그림에서 Anomaly Detection은 하나의 인스턴스에 대해 학습시키고 anomaly를 찾는 task 입니다. 예를 들어, Defect Detection(불량 탐지)가 여기에 속합니다.
다음으로, Outlier Detection은 하나의 클래스만을 정상으로 두고 나머지는 비정상으로 두어 분류하는 task입니다. 그 중에서도 semantic meaning 즉 클래스들이 의미적으로 다른 경우 이를 분류하는 task는 semantic anomaly detection이라고 합니다.
OOD detection는 클래스를 구분하는 느낌보다는 데이터셋을 통째로 구분하는 느낌이 더 큽니다.
본 논문은 그 중에서도 semantic anomaly detection task에 대해 실험을 진행합니다.
Anomaly detection은 representation과 modelling의 조합으로 표현되곤 합니다.
해당 문제를 해결하기 위한 방법론은 크게 Unsupervised, self-supervised, pretrained-based로 나눌 수 있습니다.
먼저 Unsupervised 방법론은 라벨링 없이 오직 normal data만을 사용합니다. 대표적으로 Reconstruction 방법론이 있습니다.
Self-supervised 접근법은 auxiliary task로 학습됩니다. 즉, 모델은 정상 데이터를 잘 반영하는 의미있는 feature를 학습하게 됩니다. 대표적으로 Rotation classification, puzzle-solving, CutPaste 등이 있습니다.
이 쪽 분야 관련해서 최근에는 Contrastive learning이 각광받고 있습니다. 특히 해당 방법론은 semantic anomaly detection에서 좋은 성과를 거두고 있습니다.
마지막으로 pre-trained 모델로부터 feature extraction하고 간단한 scoring 알고리즘을 조합하는 방법론이 anomaly detection에서 효과적입니다. 대표적으로 pre-trained ResNet 모델과 kNN scoring을 조합한 모델이 모든 unsupervised와 self-supervised 방법론보다 뛰어나다는 것이 밝혀졌습니다.
Pre-trained features는 train 단계에서 사용 가능한 normal data에 구애받지 않는다는 단점이 있습니다. 이것은 가치있는 정보의 손실이며 이를 극복하고자 저자는 teacher-student training을 도입합니다. 그렇게 함으로써 pre-trained feature와 teacher-student 학습을 결합할 수 있게 됩니다. 두가지 케이스에서 저자는 둘 다 pre-trained ViT를 사용했습니다.
Teacher-student training은 이미 고화질 이미지에서의 pixel-precise anomaly segmentation에서 사용된 바 있습니다. 그들의 representation은 defect detection에 적합한 low level 통계량을 학습하게 됩니다.
반면에, 저자는 semantic representation이 중요한 semantic anomaly detection에 포커싱합니다. 그래서 teacher-student discrepancy representation에 raw pre-trained embedding까지 더해서 SOTA 성능을 달성합니다.
그리고 teacher-student setting을 전체 네트워크를 수정하는게 아니라 block을 사용해서 수정했습니다. 특히, ViT를 사용했는데 Transformer의 encoder가 block 단위로 수행된 것에서 아이디어를 차용한 것입니다. 방법은 다음과 같습니다.
Teacher block을 통해 student block을 만듭니다. 학습 시에 student block은 teacher block을 모방합니다. 각 student block은 독립적으로 학습되며, 오직 정상 sample만으로 학습됩니다. 테스트 시에 각 sample은 teacher와 student들의 output 차이에 대한 vector로 표현됩니다. 이를 teacher-student discrepancy로 명명합니다.
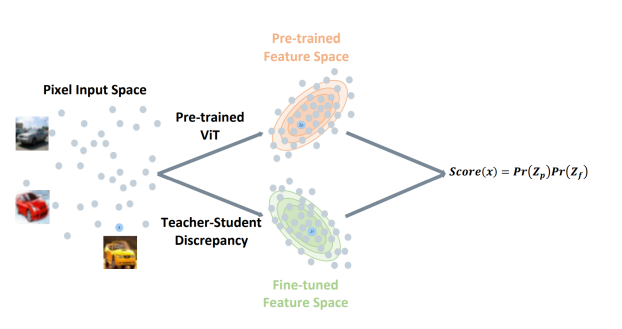
위 그림은 모델에 대한 간단한 아이디어를 보여주는 그림입니다. 각 sample은 서로 다른 두 개의 feature space에 매핑됩니다. 하나는 pre-trained ViT 네트워크에 의해 생성된 space며, 다른 하나는 teacher와 student block의 차이에 의해서 생성된 space입니다.
sample의 likelihood는 두 feature space의 likelihood의 곱으로 계산됩니다.
Likelihood를 모델링하기 위해서 kNN, single Gaussian, Gaussian Mixture Model을 고려해볼 수 있습니다.
결론적으로 본 논문의 Contribution은 다음과 같습니다.
- Anomaly Detection에 Dual feature representation (agnostic, fine-tuned)을 처음 사용한 Transformaly
- Semantic anomaly detection에 ViT를 활용한 teacher-student difference 사용
- 다양한 데이터셋에서 SOTA 성능 달성
- Unimodal setting에서는 발견되지 않았지만, Multimodal setting에서 발견된 "Pre-training Confusion"을 처음으로 보고
2. Background
챕터 2 Background에서는 Out Of Distribution Detection, Defect Detection, Semantic Anomaly Detection에 대해서 개념과 Related Works를 소개하고 있으니, 관심있으신 분들은 논문을 참고해주시면 감사하겠습니다.
3. Method
본 논문의 저자는 pre-trained ViT로 두개의 feature space를 구축하는 효과를 사용합니다.
Notation을 간단하게 정리하자면, 는 sample이며 pre-trained feature vector 와 fine-tuned feature vector 로 임베딩됩니다.
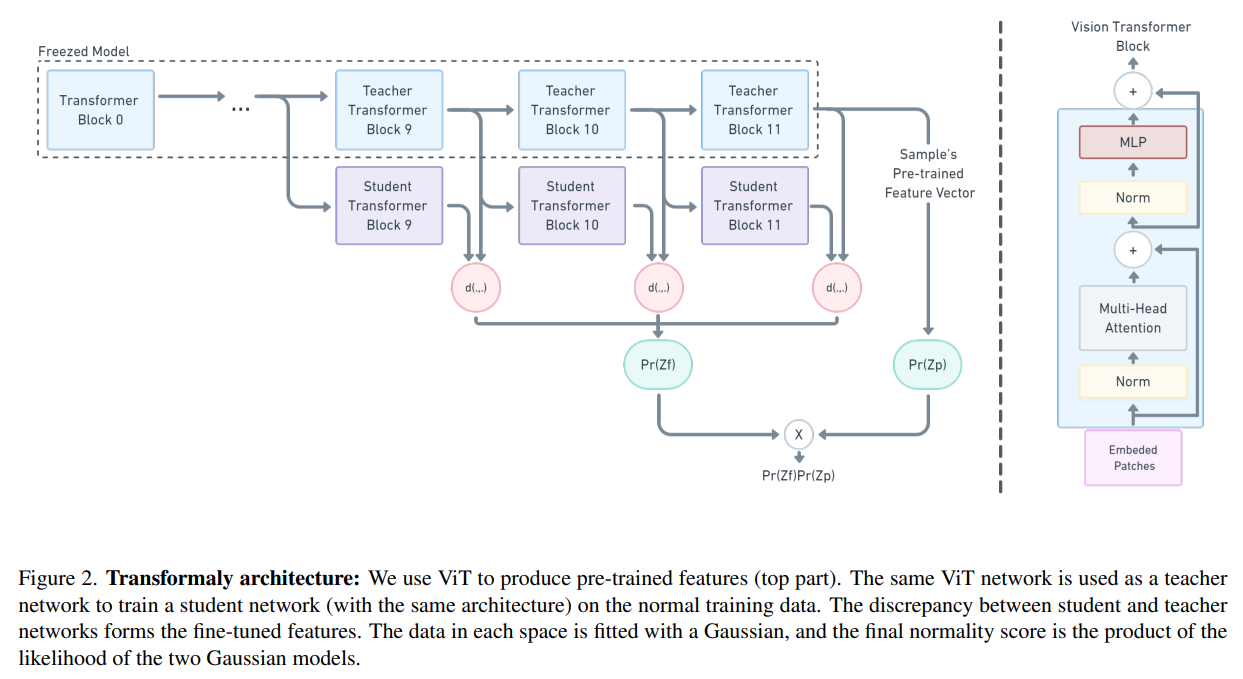
하나씩 자세하게 살펴보겠습니다.
Pre-trained Features
먼저 pre-trained vector 는 input 를 pre-trained ViT 네트워크를 거쳐서 얻어집니다.
이 때 정상, 비정상 상관없이 임베딩됩니다.
로 표현하며 그 후 Gaussian이 fit 됩니다. 추론 관정에서 각 sample은 fitted model로부터 유도된 log probability에 따라 score가 매겨집니다.
Normal sample은 abnormal sample보다 더 높은 확률을 가진다는 가정이 전제됩니다.
Fine-tuned features
Fine-tune feature embedding은 지식 증류 (knowledge distillation)로부터 영감을 받은 것입니다.
이는 teacher & student ViT block의 output 차이를 계산하는 것입니다. 특히, student block은 정상으로만 학습시키지만 teacher output과 유사한 결과를 도출하도록 합니다.
Student block의 output은 비정상 데이터에 대해서는 꽤나 다른 결과를 도출하게 됩니다.
해당 과정을 수식으로 정리하면 다음과 같습니다.
모델은 개의 teacher-student block을 거치는 프로세스를 따라가게됩니다.
student block 을 loss를 사용해서 teacher block 을 모방하도록 독립적으로 학습시킵니다.
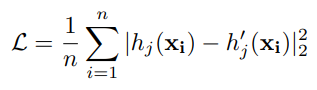
추론을 거쳐서 sample 는 다음과 같이 표현됩니다.
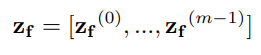
여기서 는 j번째 teacher block 와 j번째 student block 의 차이입니다.
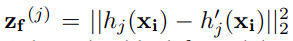
논문의 저자는 일반적으로 을 10 정도로 설정해놓습니다. 그리고 경험적으로 앞의 2 block 정도는 모델의 성능에 영향을 못 주기에 사용하지 않는다고 합니다. 앞의 2 block은 normal과 abnormal sample 둘 다에서 보이는 low-level feature를 학습하는데 이는 semantic anomalies를 detecting 하는데에 쓸모가 없다고 합니다.
Final Scoring method
다음으로 두 임베딩 벡터 와 모두에 Gaussian 함수를 fit 시킵니다.
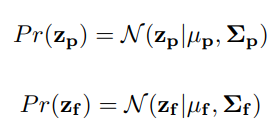
는 각각의 임베딩의 평균과 covariance를 나타냅니다.
결론적으로 sample x는 두 확률을 곱하여서 구해집니다.
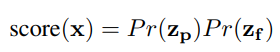
4. Experiments
4.1 Implementation Details
저자는 를 사용했고 ImageNet-21k로 pre-train, ImageNet-1k로 fine-tune합니다.
ViT는 12개의 heads, 16x16 patch size, dropout rate은 0.1, 끝에서 두번째 layer의 output은 768 차원의 벡터가 되도록하고 이는 pre-trained features로 쓰입니다.
모든 input image는 ViT의 pre-training에 따라서 normalize 됩니다.
fine-tune feautures는 ViT의 마지막 10개의 block을 teacher-student training을 적용한 결과이기에 10D 차원의 vector입니다.
Pre-trained features는 768D 차원이나 되기에 데이터의 분산을 90% 정도는 유지하도록하여 차원 축소를 거칩니다.
4.2 Datasets
평가에 사용된 데이터셋은 다음과 같습니다.

4.3 Benchmark Settings
본 논문은 Unimodal과 Multimodal 두 경우에 대해서 모두 실험을 진행했습니다.
전자는 클래스 하나만 정상 나머지는 비정상, 후자는 클래스 하나만 비정상 나머지는 정상으로 둡니다.
Unimodal setting이 일반적으로 연구에서 많이 측정되는 방법이기에 실험하지만, 사실 현실 상황에서는 정상 데이터가 비정상 데이터보다 압도적으로 많은 경우가 빈번합니다. 그래서 Multimodal setting 또한 실험한 것입니다.
4.4 Results
성능 지표로는 AUROC를 사용했습니다.
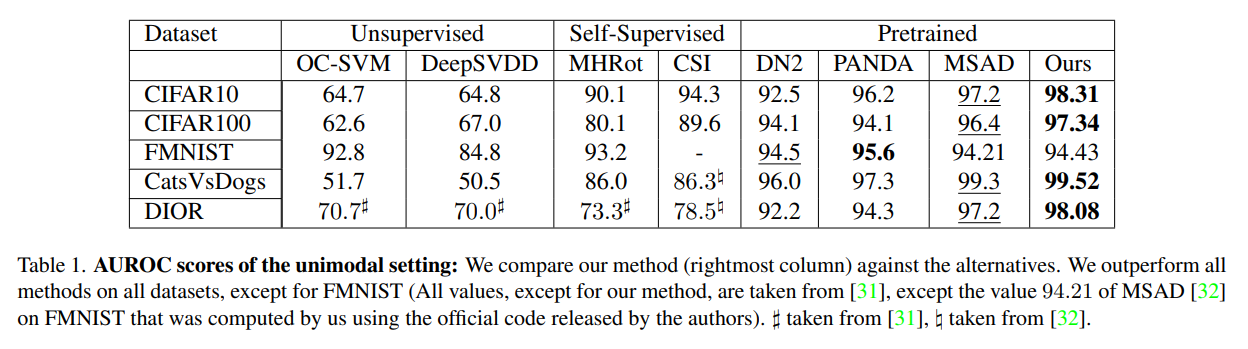
Unsupervised 방법론인 OC-SVM과 DeepSVDD, Self-Supervised 방법론인 MHRot, CSI, Pretrained 방법론인 DN2, PANDA, MSAD 들과 Transformaly를 비교한 결과는 위와 같습니다.
결과는 Fashion MNIST를 제외한 모든 데이터셋에서 가장 좋은 성능을 보였습니다.
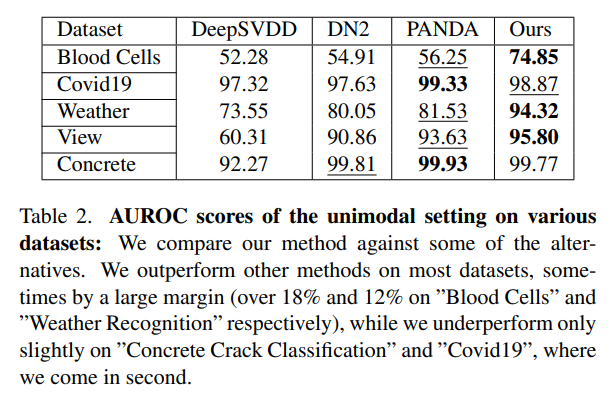
다른 데이터셋에 대해서도 추가 실험을 진행했습니다.
대부분의 데이터셋에 대해 좋은 결과를 도출해냈고, 큰 폭으로 성능이 상승한 데이터셋들도 있었습니다.
추가 실험에 쓰인 데이터셋들은 도메인이 다들 완전히 달랐지만 그럼에도 불구하고 좋은 성능을 보였다는 것을 통해 robustness와 flexibility가 있음을 증명해냈습니다.
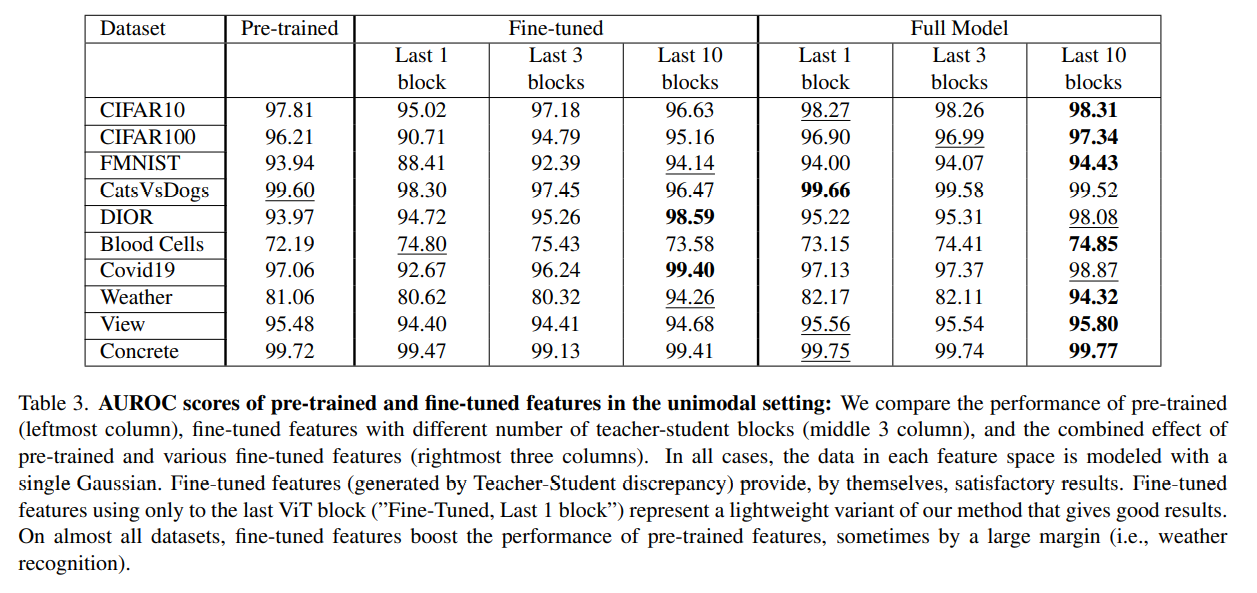
다음으로 pre-trained와 fine-tuned feature의 기여도를 측정했습니다. 결과는 위와 같습니다.
그리고 다른 수의 teacher-student block의 성능도 측정해봤습니다.
모든 feature space에 대해서 single Gaussian을 사용했습니다.
결과적으로 pre-trained와 fine-tuned feature를 전부 사용한 Full model이 좋은 성능을 보임을 알 수 있었습니다. 그리고 적은 수보다는 10개의 teacher-student block을 전부 사용했을 때 가장 좋은 성능을 보였습니다.
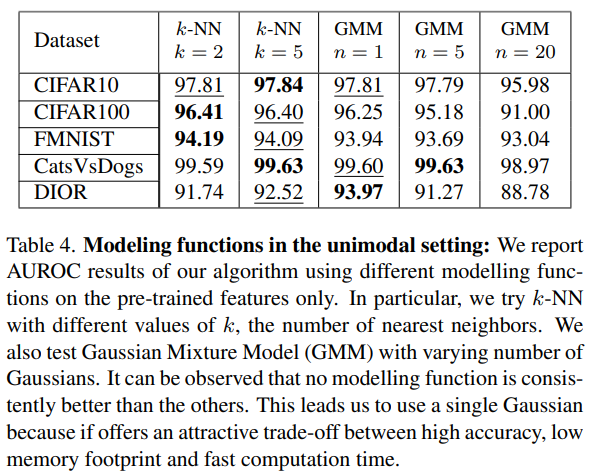
지금까지 계속해서 single Gaussian을 적용했었는데 다른 modeling functions들의 성능 또한 비교가 되어있었습니다.
Table 4에 따르면 사실 그렇게 큰 성능 차이가 있지는 않았습니다. 그렇기 때문에 가장 적은 메모리를 사용하고 계산이 가장 빠른 single Gaussian을 채택하게 되었습니다.
Multimodal Setting
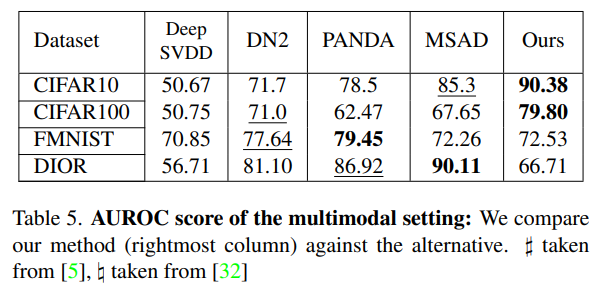
Multimodal setting 상황에서도 SOTA의 성능을 거둔 데이터셋이 있었습니다.
대표적으로 CIFAR-10, 100 데이터셋에서 상당히 큰 격차의 성능을 거두었습니다.
물론 성능이 상당히 별로인 데이터셋도 있었는데 DIOR 데이터셋이 그랬습니다.
이는 4.5 Limitation 파트에서 자세하게 다루겠습니다.
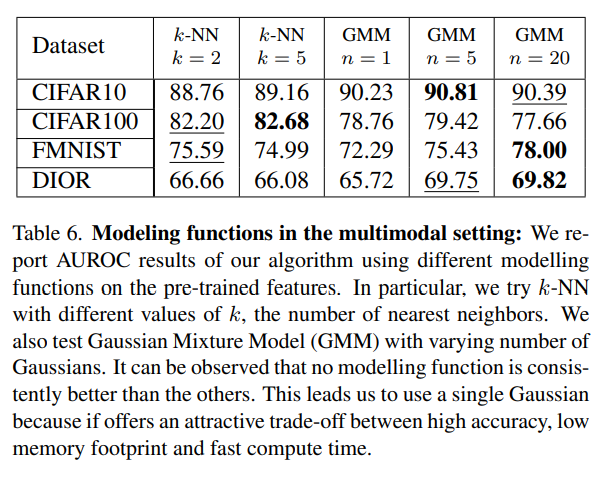
Multimodal 상황에서도 modeling functions끼리 큰 성능 차이가 없었기에 single Gaussian을 채택합니다.
Whitening
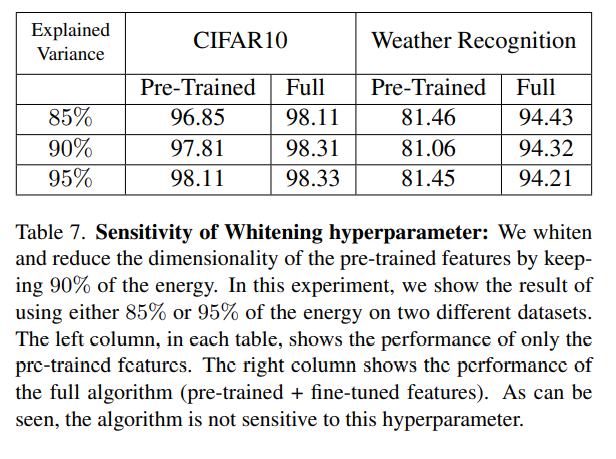
차원 축소된 parameter를 사용하는 알고리즘의 robustness를 측정하기 위한 실험도 진행했습니다.
앞서 실험했을 때는 90% 정도를 유지하도록 차원 축소를 하고 실험을 진행했었습니다.
85%, 95%로 차원 축소 했을 때도 크게 성능 차이가 있지는 않았습니다.
이를 통해 hyperparameter 선택에 따라 크게 민감하지 않다는 결과가 도출되었습니다.
4.5 Limitation
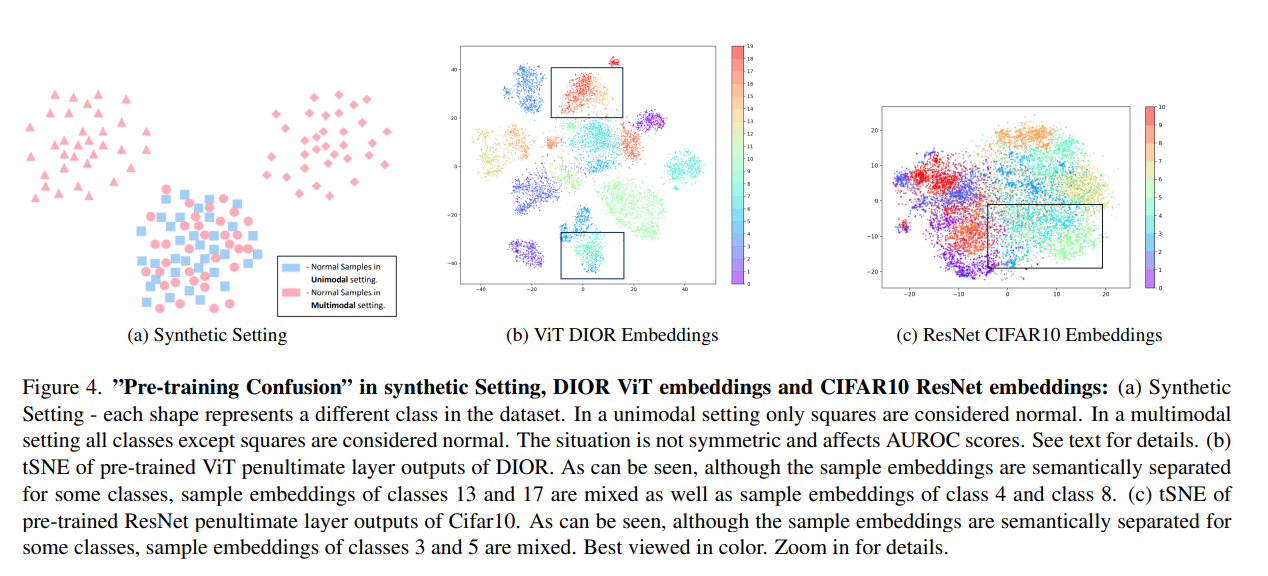
앞서 multimodal setting에서 "DIOR" 데이터셋에 대해서 상당히 낮은 성능을 거둔 것을 볼 수 있었습니다.
저자는 이러한 상황을 "pre-training confusion"에 의해서 발생했다고 설명합니다.
이는 Figure 4 (a)를 보면 설명이 가능합니다.
현재 데이터셋이 (a)와 같이 분포해있다고 가정해봅시다.
Unimodal setting에서 정상 클래스를 파란색 네모로 두고 나머지를 비정상으로 둡니다.
이 경우에는 추론 시에 오직 빨간 동그라미만 헷갈립니다.
그래서 비정상인 빨간 동그라미 정도는 제대로 분류 못할 수 있죠.
하지만 Multimodal setting이라면 빨간색 클래스들이 정상 파란색이 비정상입니다.
그렇다면 비정상은 파란색 네모밖에 없는데 이들이 비정상이지만 전혀 캐치해내지 못하고 맙니다.
따라서 저렇게 클래스들의 분포가 닮아있어서 섞여 있는 경우 Unimodal setting에서는 어느 정도만 성능이 떨어지겠지만, Multimodal setting의 경우 성능이 상당히 하락하게 됩니다.
그러한 상황이 DIOR 데이터셋에서 나타난 것입니다.
실제로 Figure 4(b)를 보면 DIOR의 feature들의 임베딩을 tSNE를 통해 시각화해본 그림입니다.
이 경우 클래스 13, 17 그리고 클래스 4, 8이 상당히 닮아있습니다.
이러한 현상은 Transformer 기반에서만 일어나는 것은 아닙니다.
ResNet 구조에서도 발생하는데요. Figure 4(c)를 보면 알 수 있습니다.
Cifar10의 pre-trained ResNet feature의 tSNE embedding을 살펴보면 클래스 3, 5과 혼재되어 있습니다.
따라서 multimodal setting은 unimodal setting보다 성능이 낮고 앞서 말한 Pre-training confusion 문제를 해결해야할 것입니다.
5. Conclusions
-
Transformaly는 ViT를 활용한 anomaly detection algorithm.
-
데이터는 pre-trained feature space와 fine-tuned feature space 각각에 매핑.
-
각 query point의 normality score는 각 space의 likelihood 곱으로 계산.
-
Pre-trained feature는 pre-trained ViT로부터,
Fine-tuned feature는 오직 normal data로만 student-network를 학습시킬 때 구해짐. -
다양한 데이터셋에서 좋은 성능을 거뒀고, 특히 SOTA 성능을 달성한 데이터셋도 있음(CIFAR).
함께 읽으면 좋을 논문
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
(리뷰) AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
