
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 머신러닝 알고리즘의 성능을 향상시키는 가장 쉬운 방법은 같은 데이터셋에 수많은 다른 모델들을 학습시키고, 예측값을 평균내는 방법
- 하지만 이 방법은 너무 계산 비용이 높음
- 본 논문은 지식을 증류(Distillation)하는 방법으로 모델의 앙상블 효과를 하나의 모델로 전이할 수 있음
- MoE와 달리, Specialist model(Student model)은 빠르고 병렬적으로 학습이 가능함
1. Introduction
지금까지 대규모 머신러닝은 학습 단계랑 배포 단계에서 다른 요구 사항일지라도 유사한 모델을 사용했다. 학습 시에 거대한 중복 데이터셋에서 구조를 추출하는 방향을 택하지만 실시간에서 활용될 필요가 없고 계산 비용도 불필요하게 커진다.
하지만 배포단계에서 사용자는 보유한 리소스가 제한적이다. 따라서 제안하는 방법은 거대한 앙상블 모델로부터 획득한 지식을 하나의 작은 모델로 전이(증류)하는 방법을 택해서 제약을 극복하고자 한다.
일반적으로 학습된 파라미터를 어떻게 다른 네트워크에 전이하여 지식을 유지할지를 생각하면 전이하는 방법을 설계하는 것이 까다롭다. 하지만 결국 네트워크를 거쳐서 나온 출력 벡터를 지식이라고 생각하면 지식을 증류하는 개념이 쉬워진다.
학습의 목적은 정답의 평균 로그 확률을 최대화하는 것인데, 그 과정에서 부정확한 답변에 확률을 할당하게되는 부작용이 존재한다. 이제 부정확한 답변에 확률을 할당하는 것 또한 지식으로서 활용하자는게 아이디어이다.
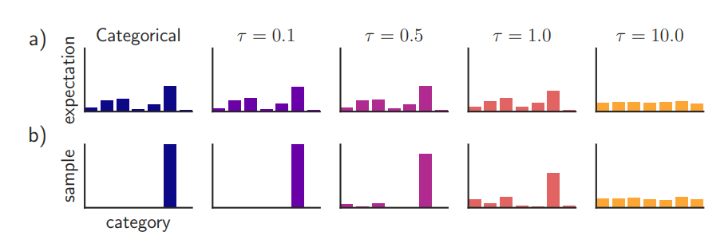
아이디어를 간단 요약하자면, Cubersome 모델에서 산출된 클래스 확률을 작은 모델을 학습시키는 "soft targets"로 활용하자는 것이다. 높은 엔트로피의 "soft targets"로 활용하면 "hard targets"를 사용할 때보다 더 많은 정보를 제공받을 수 있게 된다.
MNIST를 예시로 들면 숫자 2 이미지에 대해 분류를 진행할 때 3으로 예측한 확률이 , 7로 예측한 확률이 이라고 가정한다면, 기존 hard target으로 해당 정보를 사용하면 0에 가깝기 때문에 모델에 영향이 서로 미비하게 비슷하지만, sigmoid 함수에 (temperature)가 포함된 soft targets을 사용한다면 다른 logit의 지식도 함께 작은 모델에게 전달이 가능하다. 이것이 바로 증류(Distillation)이다.
2. Distillation
신경망은 "softmax" 함수를 통해 각 클래스별 확률값을 만들어낸다.
각 클래스별 확률값은 , logit은 로 표현하면 아래와 같다.
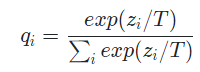
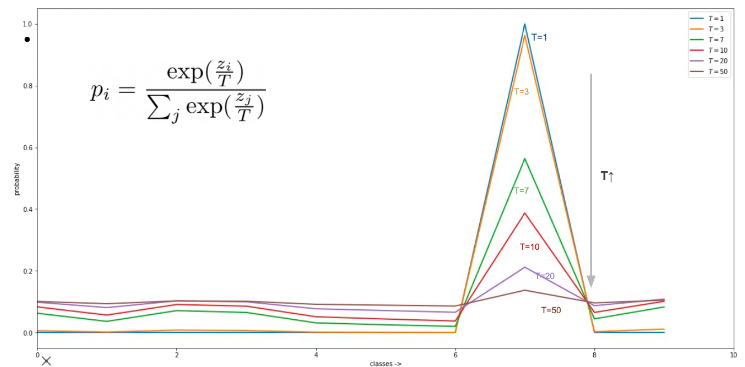
일반적인 분류문제에서는 T가 1이며, T가 더 커진다면 Soft한 확률값을 얻을 수 있다.
아래 그림을 참고하면 이해가 쉽다.
제안하는 지식 증류 방법은 아래와 같다.
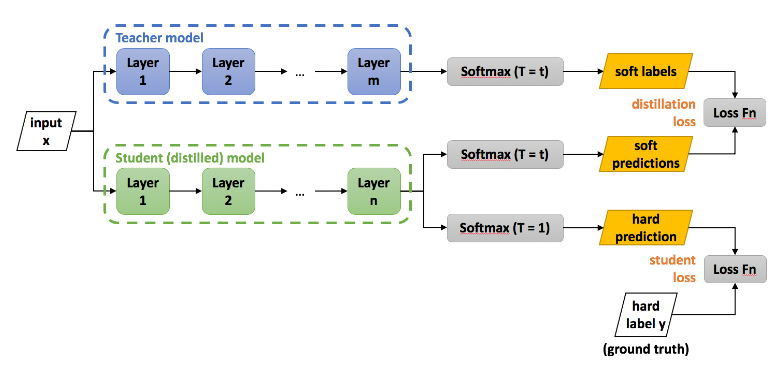
Trasfer set을 복잡한 모델에 대해 높은 T로 soft target(1)을 만들고, 같은 transfer set에 간단한 모델로 앞서 사용한 같은 T로 soft target(2)을 만든다. 다음으로 transfer set을 간단한 모델에 대해서 로 hard target(3)을 만든다.
(1)과 (3)의 cross entropy를 통해서도 간단한 지식 증류 모델을 만들 수 있긴 한데,
그보다는 (1)과 (2)의 cross entropy와 (2)와 (3)의 cross entropy를 가중합하는 방식이 훨씬 성능이 좋다고 한다. 특히 비중은 앞 손실함수에 많이 둘때 좋다고 한다.
Matching logits is a special case of distillation
Temperature을 어떻게 설정하는 것이 좋을까에 대한 고민을 특별한 케이스를 가지고 설명한다.
작은 모델의 logit 의 변화에 따른 cross enropy의 변화 즉 gradient는 아래와 같이 표현되며, 이 때 큰 모델의 logit은 로, 큰 모델에서 생성된 target 확률을 로 표현한다.
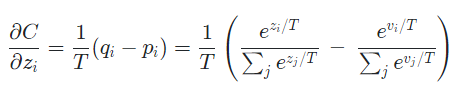
여기서 temperature가 logit의 크기에 비해 매우 크다면 다음과 같이 근사화될 수 있다.
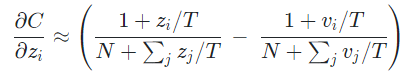
이 때 지식 증류가 잘 일어났다면 logit 와 logit 의 평균이 0이 될 것이기 때문에 최종적으로 아래와 같은 식을 얻을 수 있다.
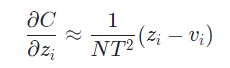
즉 T가 큰 상황에서 logit들이 zero-meaned로 주어졌다면, 지식 증류는 을 최소화하는 문제가 된다.
반대로 낮은 T에서는 negative logit matching에 대해 적게 관심을 가지는데, negative logit은 큰 모델에 noisy한 결과를 가져오기 때문에 유용하게 사용될 수 있다.
결론적으로 증류하는 모델이 복잡한 모델에서의 정보를 포착하기에 너무 작다면, 중간 정도의 temperature를 사용하는 것이 베스트다.
3. Preliminary experiments on MNIST
지식 증류가 잘 작동하는지에 대한 첫 번째 실험은 MNIST에 관한 것이었다.
복잡한 모델로 1200 ReLU를 가지는 두 개의 은닉층을 사용했으며, dropout과 weight constraints를 적절히 사용했다.
간단한 모델로 800 ReLU를 가지는 두 개의 은닉층을 사용했으며, 추가적인 학습 기법은 활용하지 않았다.
60000개의 훈련 이미지를 사용해서 10000개의 테스트 이미지에 대해 평가했을 때,
복잡한 모델은 67개의 오류 간단한 모델은 146개의 오류를 냈다.
그리고 복잡한 모델의 지식을 으로 간단한 모델에 지식 증류했을 때는 74개의 오류를 냈다.
증류된 모델이 300개 이상의 유닛과 두 개의 은닉층 정도를 갖는다면, temperature가 8 이상이면 비슷한 결과를 보였고, 30개 정도로 줄어든다면 temperature는 2.5~4 정도일 때 좋은 성능을 보였다.
추가로 숫자 3에 해당하는 이미지를 transfer set에서 제거해서 실험을 진행해보았는데, 증류된 모델은 총 206개의 오류를 냈고, 숫자 3에 해당하는 1010개의 이미지 중 단 133개만 오류를 냈다.
여기에 올바른 bias 값을 추가한다면 숫자 3에 대해 훨씬 높은 정확도 98.6%를 보였다.
심지어 transfer set에 숫자 7과 8만 두고 모델을 증류했을 때도 증류된 모델의 정확도는 47.3%나 됐다.
4. Experiments on speech recognition
Automatic Speech Recognition (ASR)에서 사용된 DNN acoustic model을 앙상블링 하는 방법으로 실험을 진행했다.
SOTA ASR 시스템은 짧은 waveform으로부터 추출된 시계열 피쳐 context를 Hidden Markov Model(HMM)의 discrete 상태에 대한 확률 분포로 매핑하는 DNN을 사용한다.
복잡한 모델로 저자는 2560 ReLU에 마지막 softmax 레이어는 14000개의 라벨을 갖는 8 hidden layer 구조를 사용했다.
모델의 input은 10ms 전진하는 40개의 멜 스케일 필터 뱅크 계수의 26프레임이며, 21번째 프레임의 HMM 상태를 예측한다.
학습에 사용된 데이터는 2000 시간의 영어 발화 데이터셋이다.
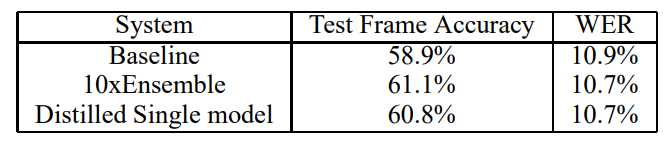
temperature는 [1, 2, 5, 10]을 사용했으며, hard target에 대한 가중치는 0.5로 두었다.
실험 결과 hard label을 사용해서 학습한 single model에 비해 지식 증류한 single model 성능이 좋았으며, 10번의 앙상블 모델과 성능 차이가 크지 않았다.
5. Training ensembles of specialists on very big datasets
앙상블 모델 학습은 병렬 계산을 쉽게 할 수 있지만 각각의 모델의 대규모 신경망이고 학습 데이터가 너무 크다면 매우 많은 계산능력과 훈련시간을 필요로 하게 된다.
따라서 저자는 혼동하기 쉬운 서로 다른 subset에 집중하는 전문가 모델을 제안해 이 문제를 해결한다.
전문가 모델의 주된 문제는 오버피팅이 쉽게 일어난다는 점인데 이는 soft target을 사용해서 방지한다.
JFT dataset
사용한 데이터셋은 JFT로 구글의 내부자료이다. 총 15000개의 레이블을 가진 10억개의 이미지이다.
두 가지의 병렬처리 방식으로 학습시켜도 6달이나 걸리는 거대한 데이터셋이다.
Specialist models
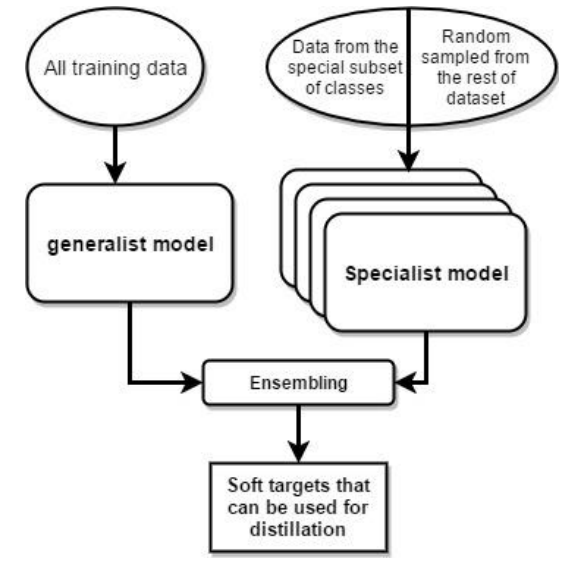
클래스의 수가 매우 많다면, 복잡한 모델을 앙상블 하기 위해 위와 같이 전체 데이터셋에 대해 훈련된 Generalist model과 혼동하기 쉬운 클래스 subset 데이터에 대해 훈련된 Specialist model을 함께 사용하는 것이 좋다.
또한 전문가 모델이 신경쓰지 않는 다른 subset들을 하나의 dustbin 클래스로 결합하여 softmax를 더욱 작게 만들 수도 있다.
오버피팅을 줄이고 더 낮은 수준의 feature detector 학습을 공유하기 위해 각 전문가 모델은 generalist model의 가중치로 초기화된다.
그리고 이 가중치들은 각 전문가의 목표 클래스에서 절반, 나머지 데이터 셋에서 랜덤으로 절반을 가져와 훈련하며 수정된다.
훈련이 끝난 후, 오버샘플된 전문가 클래스의 비율의 log값으로 dustbin 클래스의 logit을 증가시킴으로써 biased된 훈련셋을 수정한다.
Assigning classes to specialists
전문가 모델로 객체 카테고리들을 그룹화하기 위해 모든 네트워크가 혼동하는 클래스에 집중해야 한다.
이를 위해 혼동 행렬을 활용하는 방법도 있지만 true label이 필요없는 클러스터링 방식으로 그룹화를 시도했다.

전문가 모델의 클러스터를 구할 때, Generalist 모델의 예측에 대한 공분산 행렬을 K-means 알고리즘의 온라인 버전을 적용해 얻을 수 있다. 그 결과는 위와 같다.
Performing inference with ensembles of specialists
전문가 모델에 증류하기 전에 전문가 모델이 포함된 앙상블 모델의 성능이 어느 정도 되는지 확인했다.
주어진 이미지 에 대해 두 단계에 걸쳐 평가했다.
Step 1. 각 테스트 케이스에 대해 Generalist 모델에 의해 가장 가능성이 높은 개의 클래스를 찾아낸다 (해당 실험에서는 ). 해당 클래스 집합을 라고 한다.
Step 2. 클래스 집합 의 하위 클래스 과 사이의 교차점을 가져와 Active 전문가 셋 을 구성한다. 다음으로 아래 식을 최소화하는 전체 클래스에 대한 확률분포 를 구한다
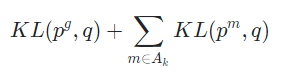
, 는 각각 전문가 모델의 확률 분포와 Generalist 모델의 확률 분포이다.
Results
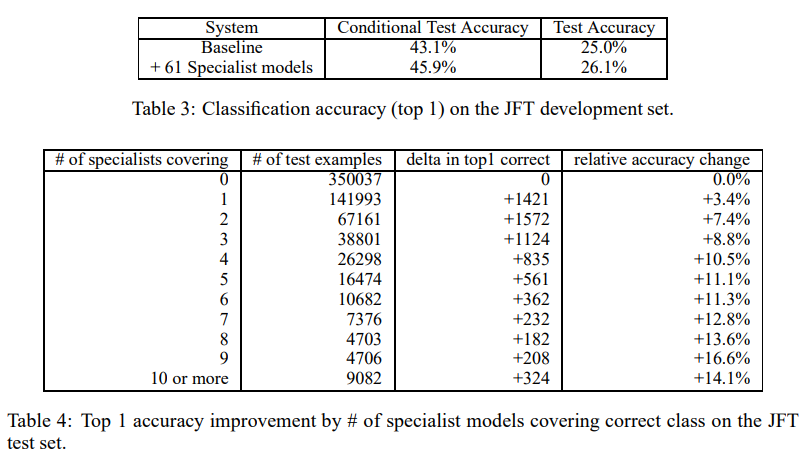
Baseline 전체 네트워크보다 전문가 모델은 매우 빠르게 훈련되었다.
또한 모든 전문가 네트워크는 독립적으로 훈련되었다.
위 표를 살펴보면 Table 3는 Baseline과 Baseline + 61개 전문가 모델인데 확실히 성능 향상이 있었다.
Table 4는 전문가 모델이 추가될수록 나타나는 상대적 개선률이다.
6. Soft Targets as Regularizers

Soft target을 쓰면 Hard target을 쓸 때보다 더 많은 유용한 정보를 전달할 수 있다.
위 표에서 볼 수 있듯 학습 데이터셋의 3%만 사용하는 실험을 진행했다.
Soft target을 사용하면 과적합을 예방할 수 있었고 추가로 정확도가 수렴하기 때문에 Early stopping을 고려하지 않아도 된다는 장점이 있었다.
또한 모든 클래스에 대해 full softmax을 전문가 모델이 하도록 했을때, early stopping보다 훨씬 overfitting을 잘 방지할 수 있었다. 저자는 3% 정도의 데이터셋을 활용할 때가 제일 좋았다고 제안했다.
7. Relationship to Mixtures of Experts
전문가 모델을 사용하는 것은 MoE를 사용하는 것과 유사하다.
MoE는 각 전문가에 각각의 example을 할당하는 확률을 계산할 수 있는 gating 네트워크를 활용한다.
Gating 네트워크는 어떤 전문가에 어떤 example을 할당할지를 상대적 discriminative 성능을 기반으로 결정하도록 학습된다.
이렇게 한다면 단순히 입력 벡터를 클러스터링하여 전문가에 할당하는 것보다 훨씬 좋지만, 훈련을 병렬로 진행하기 어렵다는 단점이 존재한다.
왜냐하면 첫번째로 각 전문가에 대한 가중치 훈련 세트는 다른 모든 전문가에 따라 계속 변경되며, 두번째로 Gating 네트워크는 할당 확률을 수정하는 방법을 알기 위해 동일한 예제에 대한 여러 전문가의 성능을 비교해야하기 때문이다.
이러한 이유로 뚜렷하게 다른 subset을 포함하는 대규모 데이터 세트에서는 오히려 비효율적이다.
MoE 보다는 전문가 모델의 훈련을 병렬화하는 것이 훨씬 쉽다.
Generalist 모델을 훈련하고 혼동 행렬을 사용하여 전문가 모델이 훈련받을 subset을 정의한다.
Subset이 정의된다면 전문가 모델을 완전히 독립적으로 훈련할 수 있다.
추론 시에 Generalist 모델의 예측을 사용하여 어떤 전문가가 관련성이 있는지 결정하고, 해당 전문가 모델만 실행하면 끝이다.
8. Discussion
본 논문을 통해 지식 증류가 앙상블 또는 고도로 정규화된 대규모 모델에서 더 작은 증류 모델로 지식을 옮기는데 효과적임을 증명했다.
게다가 transfer 데이터셋에 하나 이상의 클래스에 대한 예시가 없더라도 MNIST에서 지식 증류는 잘 작동했다.
해당 학습 방식을 잘 활용한다면 심층 신경망의 앙상블을 훈련하여 얻을 수 있는 개선 사항을 단일 신경망으로 증류할 수 있기 때문에 훨씬 더 쉽게 모바일 기기에도 배포할 수 있을 것이다.
매우 큰 신경망은 전체 앙상블을 훈련하는 것조차 불가능할 수 있으나, 저자는 매우 오랫동한 훈련된 하나의 매우 큰 신경망 성능을 혼동하기 쉬운 클러스터의 클래스를 구별하는 법을 학습할 수 있는 다수의 전문가 네트워크를 학습함으로써 대체할 수 있다고 주장합니다.
