
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2023년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- 대규모 제조 상황에서 Defective parts를 찾는 것이 중요해짐
- 상황에 맞게 모델을 만들 수도 있지만, 만들어진 모델을 다양한 데이터셋에 동시에 사용할 수 있도록 하는 것이 효율적
- PatchCore는 ImageNet의 사전학습된 정보와 Anomaly detection을 합친 모델임
- 정상 이미지 표현을 모두 저장하는 것이 아니라, Patch features를 만든 뒤 가장 중요한 부분만 Memory bank에 저장하는 방식
- 성능도 SOTA 지만 inference time도 빠름
1. Introduction
산업 이미지 데이터에 대한 visual inspection에서 unusual patterns을 찾는 것은 중요하다.
정상 이미지는 얻기 쉽지만, 결함 이미지는 얻기 굉장히 힘들기 때문에 One-class classification 혹은
cold-start anomaly detection 방법론들이 많이 연구되고 있다.
Industrial visual defect classification은 굉장히 어려운데 그 이유는
error들이 얇은 스크래치부터 커다란 구조적 결함 (ex. missing components)부터 다양하기 때문이다.

Cold start anomaly detection 방법들은 Auto-encoding 방법, GAN 기반 방법, 아니면 다른 Unsupervised adaptation 방법들이 있다.
최근에는 ImageNet 분류 데이터로부터 Deep representation을 얻어서 adaptation 없이 그대로
타겟 분포에 활용하는 방법들이 연구된다.
해당 방법이 가능한건 Deep feature representation의 Multi-scale 특성을 이용하는 Feature matching
덕분이다.
여기서 한 가지 문제가 있다면, ImageNet으로부터 얻은 feature는 High-level abstract feature이고 산업 현장에서 필요한 feature는 조금 더 abstract features 라는 점이다.
PatchCore의 장점은 (1) 추론 시 정상 정보를 최대한 활용하고 (2) ImageNet class로 향하는 bias를 줄이고 (3) 높은 추론 속도를 낼 수 있다는 점이다.
Single patch만 Anomalous면 전체 이미지가 이미 anomalous라는 점을 이용해서,
PatchCore는 locally aggregated, mid-level features patches를 사용한다.
이를 통해 ImageNet class로 향하는 bias를 최소화하며 동시에 충분한 spatial context를 포착할 수 있다.
마지막으로는 greedy coreset subsampling을 통해서 nominal feature bank에서 중복을 최소화하며
필요한 정상 feature만 사용할 수 있게된다.
실험은 MVTec AD와 MTD 데이터셋을 사용했고, SOTA 성능을 달성했다.
빠른 추론 속도를 증명했으며, 이를 통해 현업에서 더 매력적인 알고리즘임을 입증했다.
3. Method
3.1 Locally aware patch features
은 학습에 쓰이는 정상 이미지
는 추론에 쓰이는 정상 + 이미지
는 pretrained on ImageNet으로
는 features를 나타냄
여러 연구에서는 pretrained network의 feature hierarchy에서 last level을 주로 사용했는데
그렇게 한다면 2가지 단점이 존재함.
(1) localized nominal 정보를 잃게됨
(2) Natural 이미지 분류에 편향된 feature를 얻게됨
따라서 본 연구는 intermediate 혹은 mid-level feature 표현으로 구성된 memory bank 을 사용해서
training context를 제대로 사용하고 ImageNet 분류에 너무 편향된 feature 학습을 피하도록 함
예를 들어, 1,2,3,4 layer로 되어있다면 2, 3 쯤을 사용하는 것.
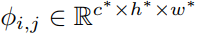
Feature map은 3차원으로 구성되어 있다.
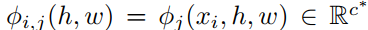
이제 이걸 slice해서 patch 하나하나씩으로 보게 된다.
이 때 local spatial variations에 강건하기 위해서 충분히 큰 receptive field size를 갖도록 쪼갠다.
하지만 여기서 모든 Patch를 다 사용한다면 patch-features들이 ImageNet-specific하게 될 위험이 있고 anomaly detection task와 관련이 없어질 위험이 있다.
이러한 위험을 해결하고자 local neighbourhood aggregation을 사용해서 receptive field size와 작은 spatial deviations을 spatial resolution이나 feature map의 유용성을 잃지 않고 증가시켰다.
Patchcore에서는 adaptive average pooling을 사용했고, 이는 각 feature map에 대한
local smoothing과 유사하다.
Patchcore는 두 개의 intermediate feature hierarchies를 사용했으며 이를 평균내어 최종적으로 Coreset을 만들고 Memory bank 에 입력하게 된다.
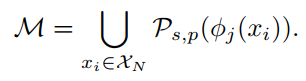
3.2 Coreset-reduced patch-feature memory bank
학습 시 사용되는 정상 이미지가 증가할수록, Memory bank 는 점점 더 커지고 추론 시간도 길어진다.
이러한 문제를 해결하고자 관련 문헌인 SPADE는 preselection 단계를 거쳐서 pixel-level anomaly detection을 위한 feature maps을 image-level anomaly detection 매커니즘에 적합하도록 하였다.
하지만 ImageNet에 편향된 표현이 detection과 localization 성능에 부정적인 영향을 미쳤다.
PatchCore는 patch 기반 비교를 하기 때문에 편향에 있어서 조금 더 자유롭고 anomaly detection과
segmentation 성능도 하락하지 않는다.
대신 문제는 기존의 Random subsampling 과정을 거친다면 Memory bank 에서 사용가능한 중요한 정보들을 잃게 된다는 단점이 있다.
이를 극복하기 위해 coreset subsampling 매커니즘을 사용해서 성능은 유지되도록 하며 추론 시간을 줄이는 방안을 택했다.
Coreset subsampling은 Greedy Search 방법이며 가장 멀게 위치한 Sample들을 반복적으로 선택하는 방식을 택한다.

알고리즘은 위와 같다.
정상 data의 모든 정보를 가지고 있을 필요가 없다는 아이디어를 Coreset subsampling을 통해 구현한 것이며, 이를 통해 중복된 비중이 적고 정상 feature가 고르게 선택되게 된다.
3.3 Anomaly Detection with PatchCore
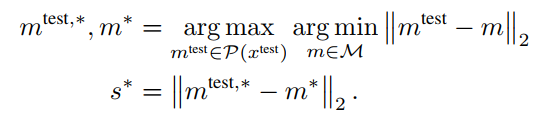
Image-level anomaly score 를 구하기 위해서는
test patch feature와 Memory bank안에 가장 가까운 patch feature와의 maximum distance score 를 사용한다.
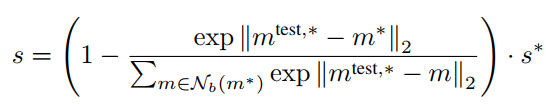
최종적인 Anomaly score는 위와 같다.
Test patch와 memory bank 안의 feature를 비교할 때는 Nearest Neighbor 방법을 사용하는데 이는
faiss를 통해 빠르게 연산 가능하다.
Faiss는 모든 관측치와 비교하지 않고 cluster을 활용하여 효율적인 similarity 계산을 가능하게 한다.
이제 Patch들 중 가장 큰 anomaly score를 Image에 대한 Anomaly score로 할당하고,
Local patch에 대한 resolution을 원본 이미지 크기로 interpolation 후 gaussian smoothing을 적용해서
Pixel-level Anomaly score 또한 산출한다.
4. Experiments
4.1 Experimental Details
Datasets
MVTec Anomaly Detection benchmark 데이터셋을 사용해 주된 실험이 이뤄졌다.
해당 데이터셋은 15개의 sub-datasets, 총 5354 장, Test set에는 1725장으로 구성되어 있다.
각 데이터셋은 nominal-only 학습 데이터와 nominal과 anomalous 샘플이 섞여있는 test set으로 구성되어있다.
이미지들은 사진 가운데 위치하며 256x256 혹은 224x224 크기고 Resize되어 있다.
Data augmentation은 따로 추가되지 않았따.
위 데이터셋 외에도 Magnetic Tile Defects (MTD)를 사용했으며,
Defect-free 이미지 925장, Anomolous magnetic tile 이미지 392장으로 구성되어있다.
산업 이미지 외에도 Mini Shanghai Tech Campus (mSTC)라는 데이터셋도 사용했다.
해당 데이터셋은 12개의 서로 다른 scene으로 구성되어 있는 보행자 비디오이다.
Evaluation Metrics
Image-level anomaly detection performance는 AUROC를 사용했다.
Segmentation 성능 또한 측정하기 위해 pixel-wise AUROC와 PRO metric을 사용했다.
4.2 Anomaly Detection on MVTec AD

Image-level AUROC 성능 비교 결과이다. PatchCore가 SOTA 성능을 달성했으며, Coreset sampling 비율에 크게 영향 받지 않는 모습을 알 수 있다. 이를 통해 정상 데이터 Coreset의 1%만 활용하여도 높은 성능을
거둠을 알 수 있다.

Pixel-wise AUROC 또한 같은 상황이다.

PRO도 이하동문이다.
4.3 Inference Time
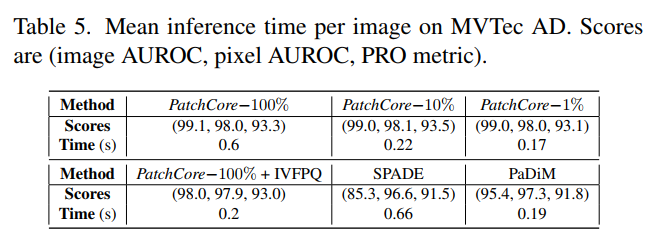
논문에서 계속 주장하듯 PatchCore가 다른 모델들에 비해 빠른 Inference 속도를 보임을 알 수 있다.
Time (s)의 경우 한 장을 처리할 때 소요되는 시간으로 이해하면 되겠다.
4.4 Ablations Study
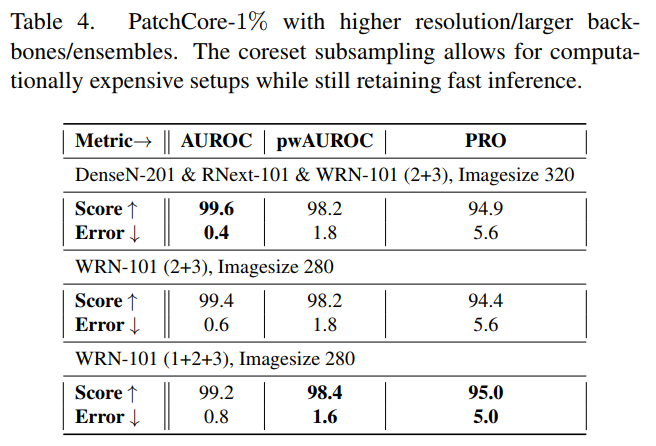
Backbone과 Layer 조합에 따라 성능이 조금씩 달라지는 것을 알 수 있다.
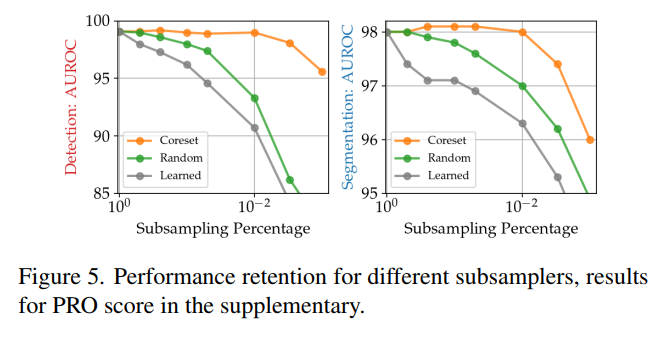
Coreset sampling 비율이 낮아질 수록 성능이 떨어지는 것을 알 수 있으나, 다른 Sampling 기법에 비해서는 Robust하다는 것을 알 수 있다.
4.5 Low-shot Anomaly Detection
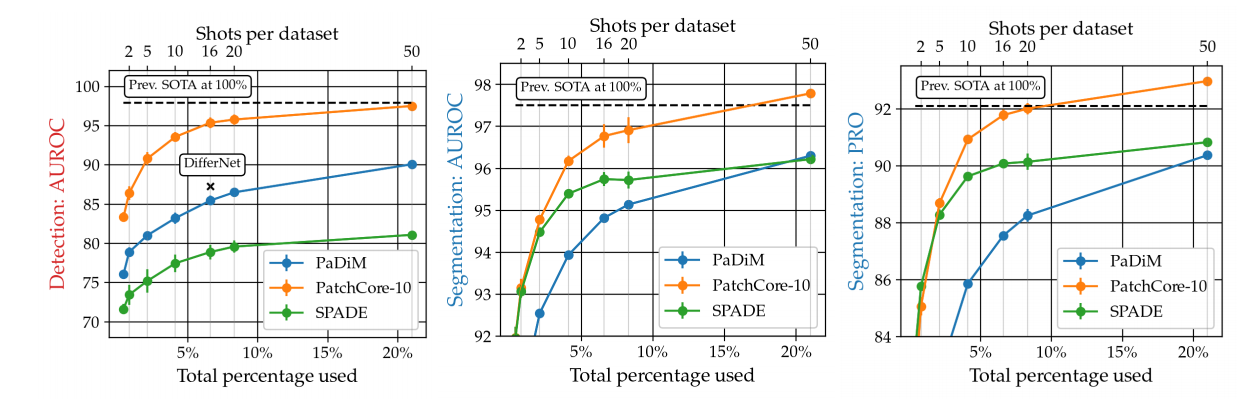
PatchCore의 Ref 논문 격인 PaDiM과 SPADE와 Shot 별로 성능을 비교한 그림이다.
PatchCore가 Low-shot 상황에서 다른 모델보다 준수한 성능을 보임을 알 수 있다.
4.6 Evalutation on other benchmarks
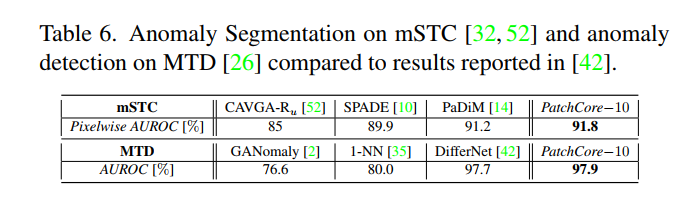
MVTec AD 외의 다른 데이터셋에서도 PatchCore가 SOTA 성능을 보임을 알 수 있다.
5. Conclusion
PatchCore는 정상 데이터 맥락을 최대한 활용하면서 추론 시간은 낮추는 균형 있는 이상 탐지 방법론을
제시하였다. 그 성능은 MVTec AD 벤치마크 데이터셋을 통해 검증되었다.
PatchCore는 산업 이상탐지에 특화된 모델로 사회적으로 부정적인 영향을 끼칠 위험은 낮다고 평가했다.
동시에 산업에서 종사하는 현업자에게 자동화된 이상 탐지 모델로서 높은 효율성을 보일 것이라 기대한다.
하나 한계점은 PatchCore가 산업 분야 특화 이상 탐지 모델이기 때문에 다른 분야에서 사용하려면 Adaptation이 필요하다고 한다.
