
본 게시물은 고려대학교 스마트생산시스템 연구실 2023년 동계 신입생 세미나 활동입니다.
Michigan 대학의 Justin Johnson 교수님의 강의를 공부하는 형식입니다.
관련 유튜브 영상은 여기에서 확인 가능합니다.
Lecture 8: CNN Architectures 강의에서는 배울 수 있는 내용은 다음과 같습니다.
- ImageNet Classification Challenge
- AlexNet
- ZFNet
- VGG
- GoogLeNet
- Residual Networks
- Another Networks
ImageNet Classification Challenge
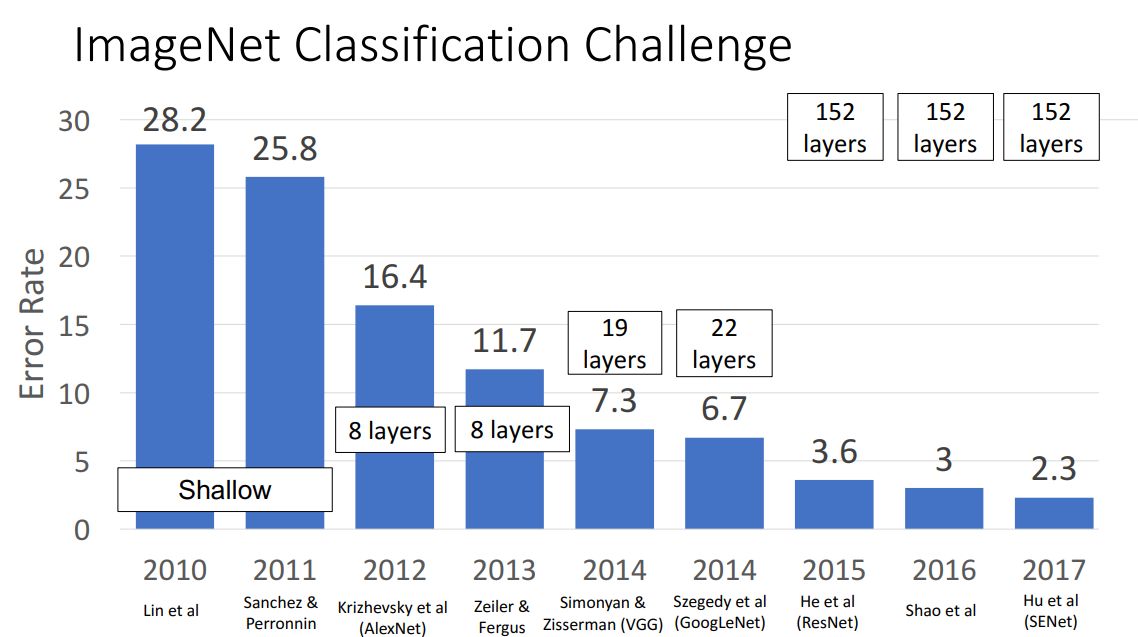
CNN 구조의 모델들이 얼마나 이미지 분류를 잘해왔는지를 살펴보기 위해 2010년부터 매년 열려왔던
ImageNet Classification Challenge를 살펴볼 필요가 있습니다.
ImageNet Dataset은 1.2 million 정도의 이미지와 1000개의 Class를 지닌 거대한 데이터셋입니다.
해당 데이터셋을 분류하는 대회에서 매년 Highest Performing model 들이 소개되었습니다.
지금부터 살펴볼 모델은 2012년도 ImageNet Classification Challenge의 우승자이자 2010, 2011년도에는 Shallow 했던 CNN 모델들로부터 벗어난 모델로 유명한 AlexNet 입니다.
AlexNet
AlexNet 모델은 현재로서는 엄청 Deep하다고 말할 수 있는 모델은 아닙니다.
해당 모델이 주목받는 데에는 여러 이유가 있지만, 간단하게 하나를 꼽자면
ReLU 비선형 함수를 처음 사용한 CNN 구조입니다.
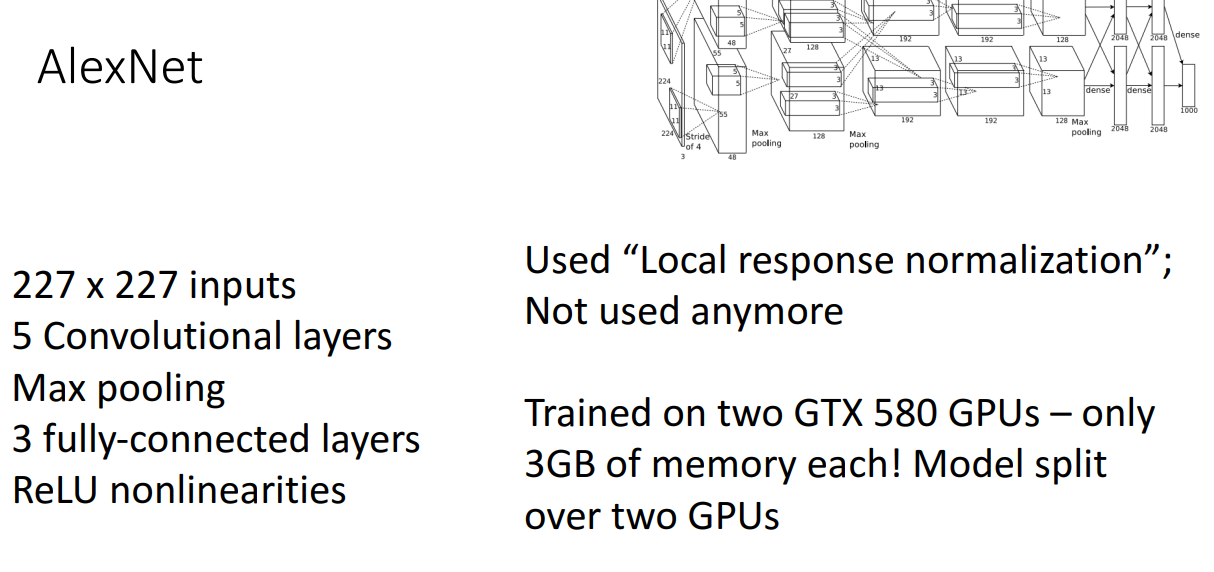
위 그림을 보면 왼쪽에는 간단하게 모델에서 사용한 구성요소들이 소개되어 있습니다.
오른쪽에는 해당 모델이 왜 요즘에는 잘 사용하지 않는지에 대한 이유입니다.
AlexNet은 Local response normlization 이라는 정규화 기법을 사용한 모델인데,
현재는 Batch Normalization이 주로 사용됩니다.
당시에는 GTX 580 GPU가 가장 좋은 GPU였는데 겨우 3GB 메모리 밖에 안돼서
AlexNet 개발자들은 모델을 두개의 GPU에 나눠서 학습에 사용했습니다.
따라서 사용 코드는 조금 더 복잡한 형태입니다.
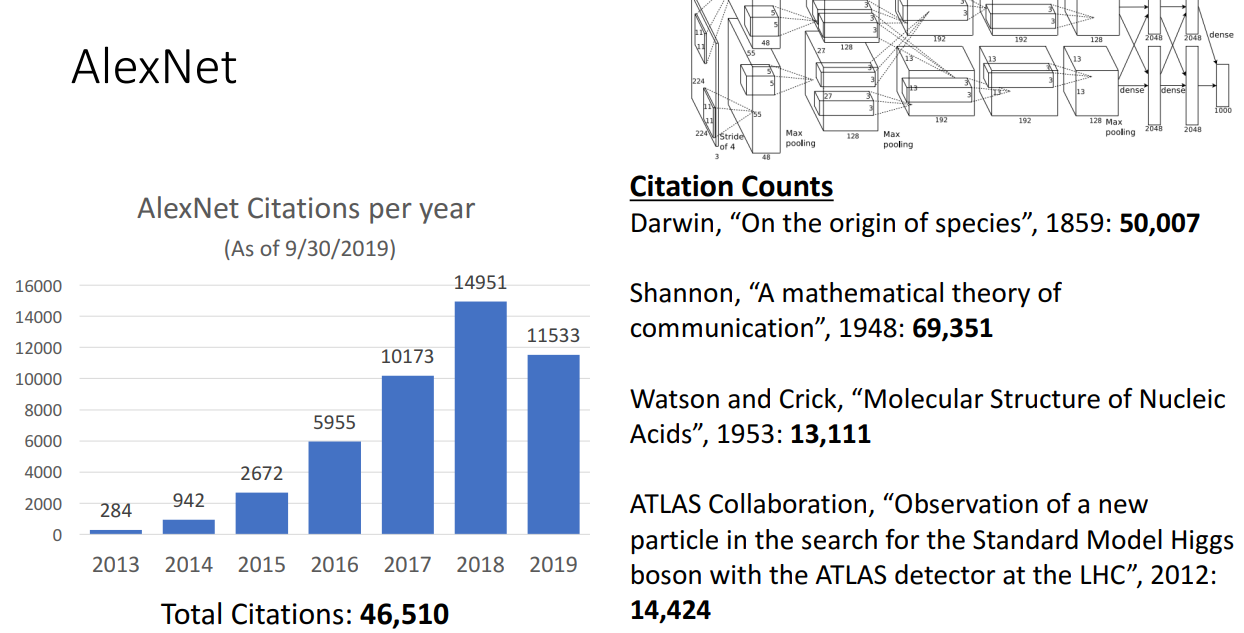
AlexNet에 대해서 설명에 들어가기 앞서서 해당 모델이 얼마나 영향력 있는 모델인지를 설명해주는 장표입니다.
보시다시피 2019년 기준 약 46000 정도의 인용이 되었는데, 찰스 다윈의 '종의 기원'이 50000 정도의 인용인걸 보면 짧은 시간동안 얼마나 많이 인용이 되었는지 확인할 수 있습니다.

Input 이미지가 주어졌을 때 Conv layer를 거치면 Output의 크기가 어떻게 되는지에 대한 공식은 Lecture 7 리뷰에서 언급했습니다.
Memory, Learning parameter의 수, Floating point operations(연산량) 수 계산도 앞선 리뷰에서 살펴보았지만 그 중에서 Floating point operations(연산량)에 대해서만 자세하게 살펴보겠습니다.
그 이유는 앞으로 나오는 많은 CNN 모델들이 Floating point operations(연산량)을 얼마나 효율적으로 줄였는지에 대해 Contribution으로 내세우기 때문입니다.
Floating point operations(연산량) 계산은 Number of output elements * ops per output elem로
Conv 계층의 경우 상당히 많은 시간이 소모됨을 알 수 있습니다.
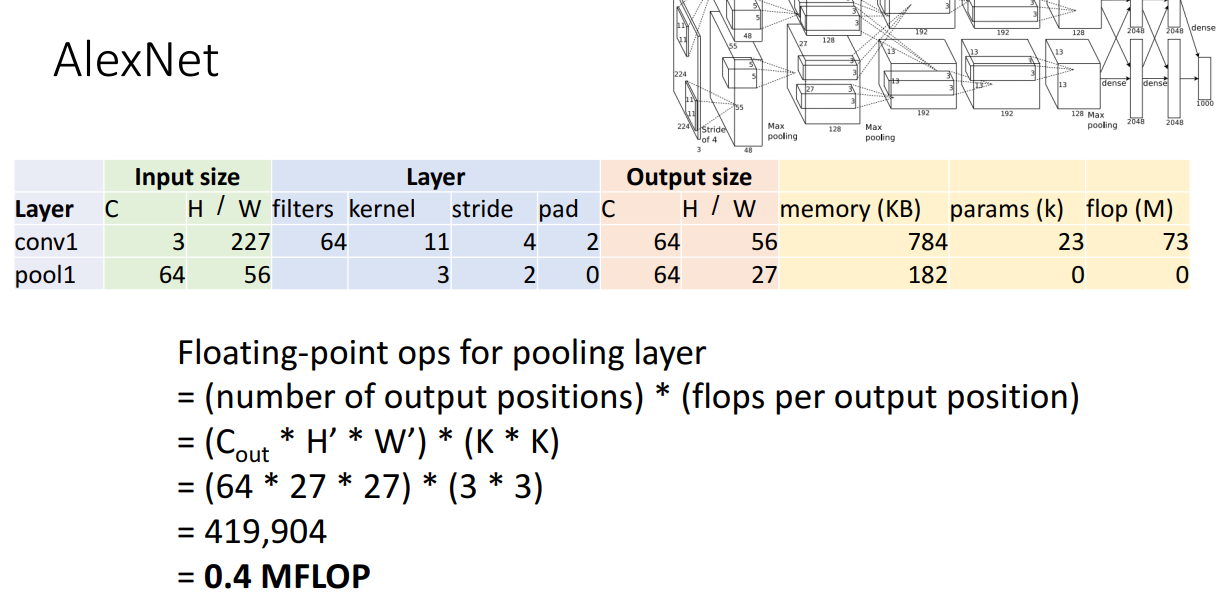
반면 Floating point operations(연산량)이 풀링 계층에서는 상당히 작습니다.
학습해야할 파라미터가 없기도 하고, 행렬곱과 같은 복잡한 연산이 없기 때문입니다.
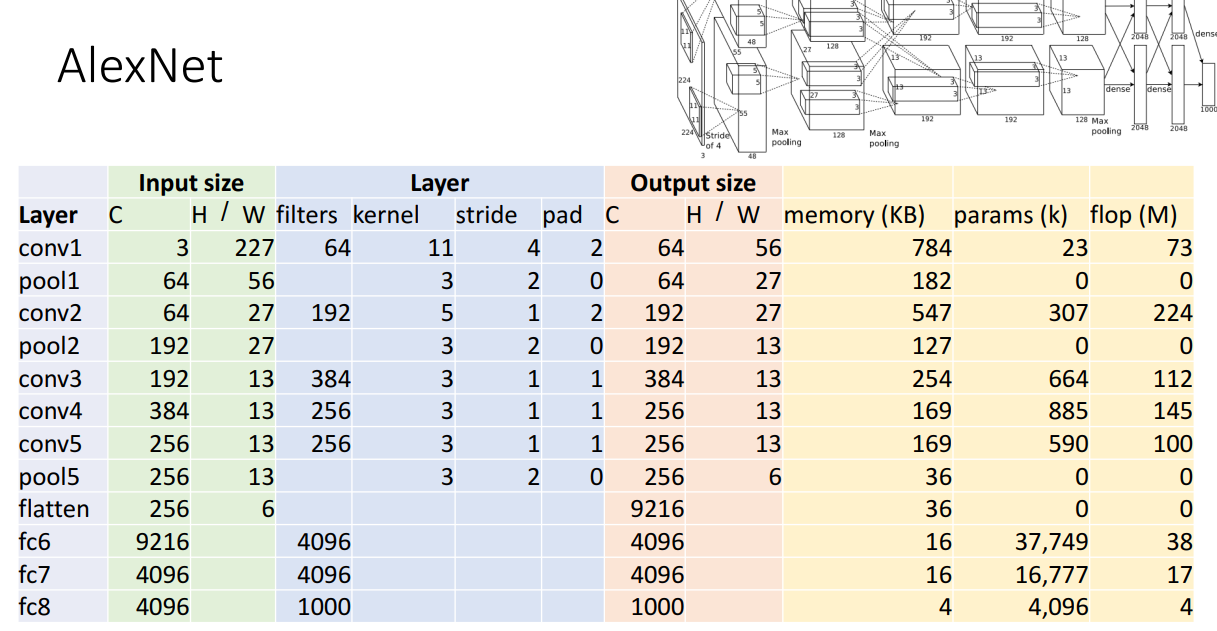
최종적인 AlexNet 구조의 모습과 Memory, Parameter, 연산량에 대한 표입니다.
Fully-connected layer의 경우도 연산량이 어느 정도 있음을 확인할 수 있으나 Conv layer 만큼은 아닙니다.
AlexNet의 위와 같은 구조는 안타깝게도 Trial-and-error 방식으로 연구자들이 찾아낸 구조입니다.
따라서 어떻게 저런 구조를 만들었죠? 여쭤보시면 주먹구구식으로요.. 밖에 대답 못합니다ㅠㅠ
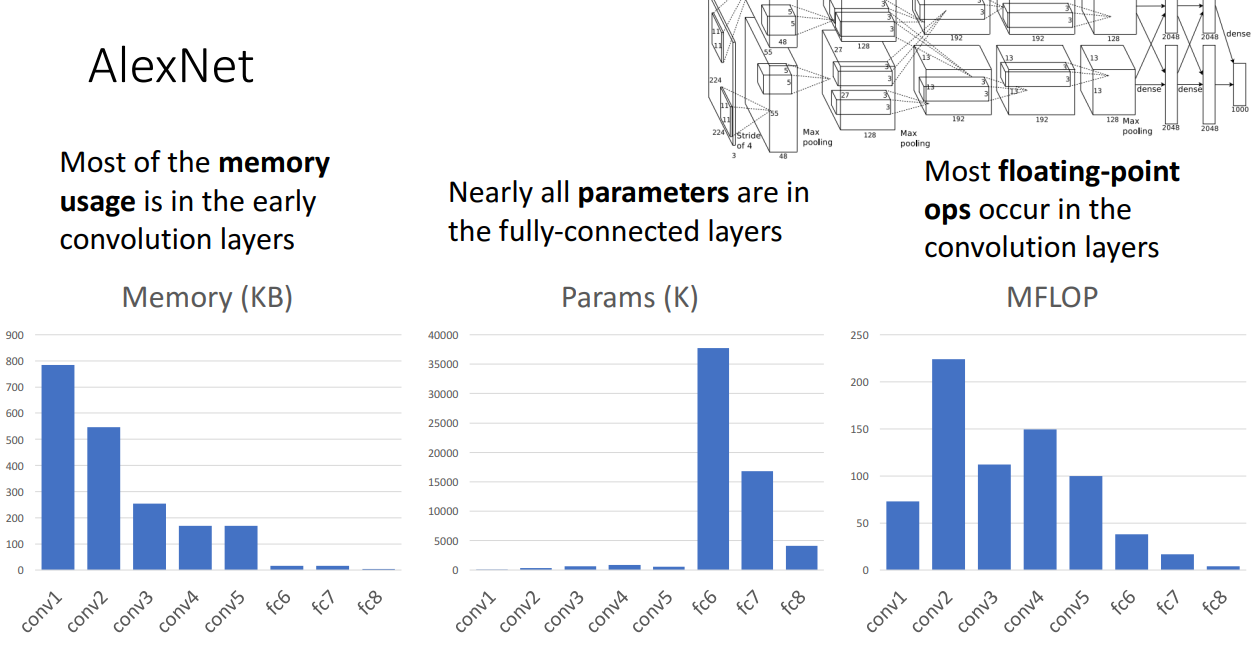
사실 주목해야할 부분은 메모리 사용량, 파라미터의 수, 연산량 입니다.
메모리 사용량의 경우 Conv layer가 가장 많고 그리고 초반 Conv layer가 가장 많습니다.
이유는 초반 Conv layer가 다루는 이미지가 고해상도이기 때문입니다.
다음으로 학습해야할 파라미터의 경우 FC layer가 가장 많습니다.
이유는 FC layer는 Weight matrix를 학습해야하는데 이미지를 Flatten 시켰기 때문에 가중치 행렬이 무지하게 큽니다. 따라서 학습 파라미터의 수가 많습니다.
마지막으로 연산량은 Conv layer가 많은데 이유는 고화질 상황에서 여러 개의 필터를 사용해야하다보니
연산량이 무척이나 커지게 됩니다.
ZFNet
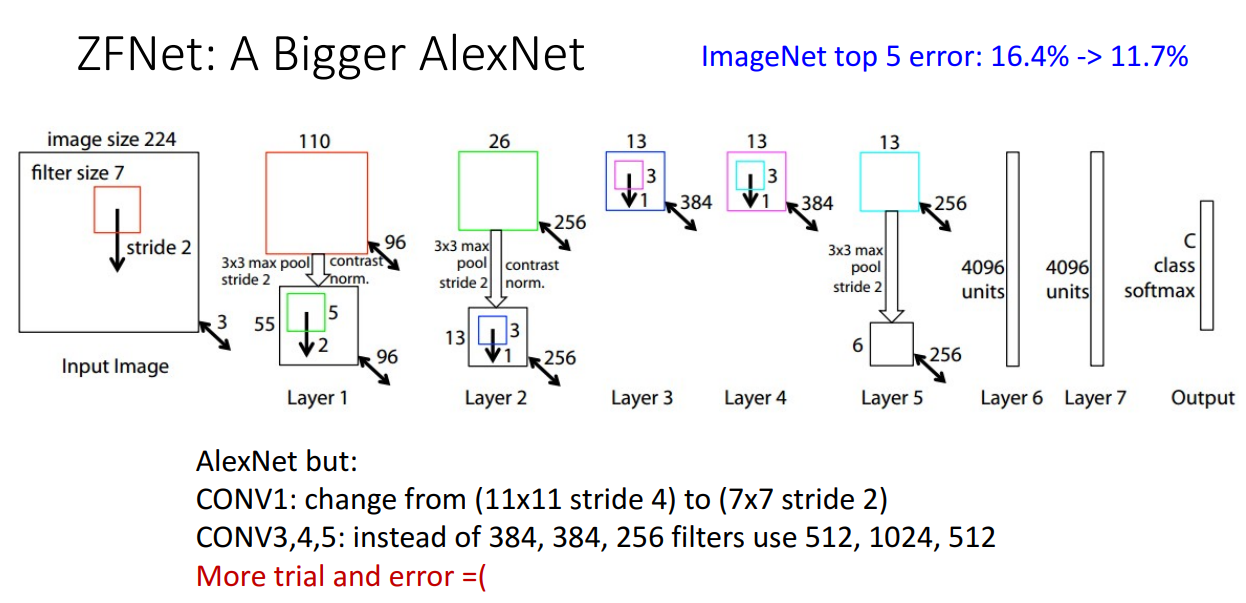
ImageNet Classification Challenge의 2013년 우승자는 ZFNet 이었습니다.
크게 주목할 점은 따로 없고 AlexNet을 더 거대하게 만든 모델입니다.
AlexNet보다 훨씬 많은 Conv 필터를 사용해서 모델을 학습했습니다.
VGG
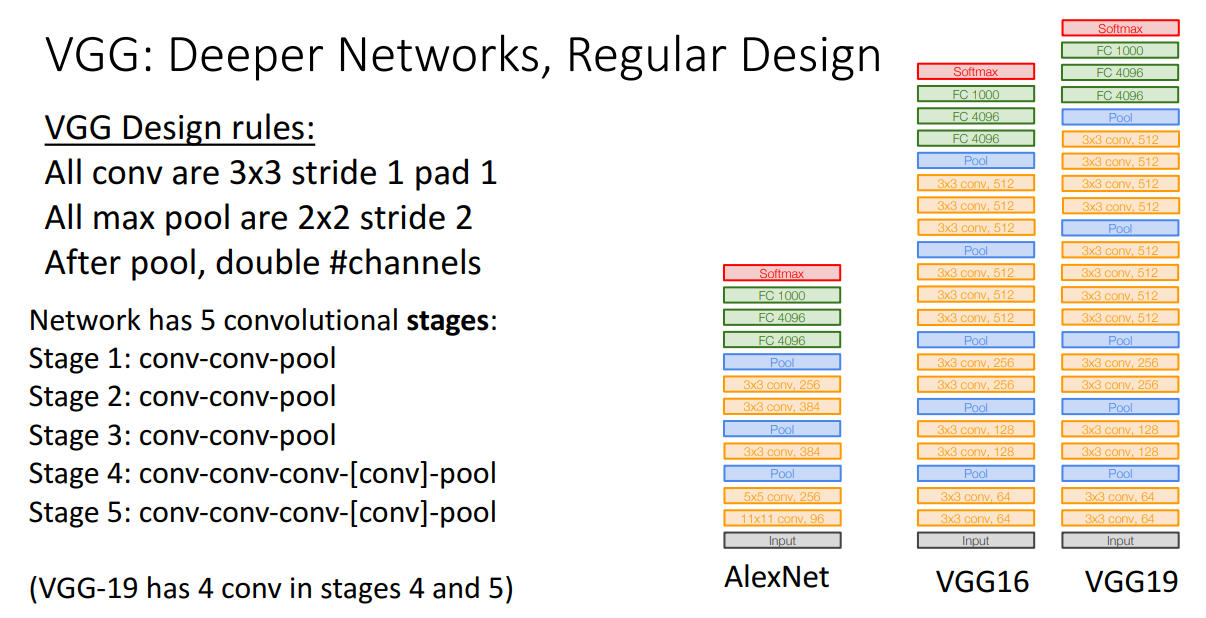
ImageNet Classification Challenge의 2014년 우승자는 아니지만 우승자보다 훨씬 많은 관심을 받은 모델은 VGG 입니다.
VGG는 옥스포드 대학의 연구실 이름이며, 교수 1명과 대학원생 1명이 만들어낸 모델로 유명합니다.
해당 모델은 수작업이었던 trial-and-error 방식에서 탈피하고 Principles를 정립했습니다.
conv-conv-pool 구조를 Stage를 나눠서 반복하고, 사용된 Conv layer는 3x3 필터를 사용했습니다.
필터 크기는 일정했지만 Stage가 증가할때마다 필터의 개수는 2배로 증가시킵니다.
Pool layer는 2x2 stride 2의 max pooling을 사용합니다.
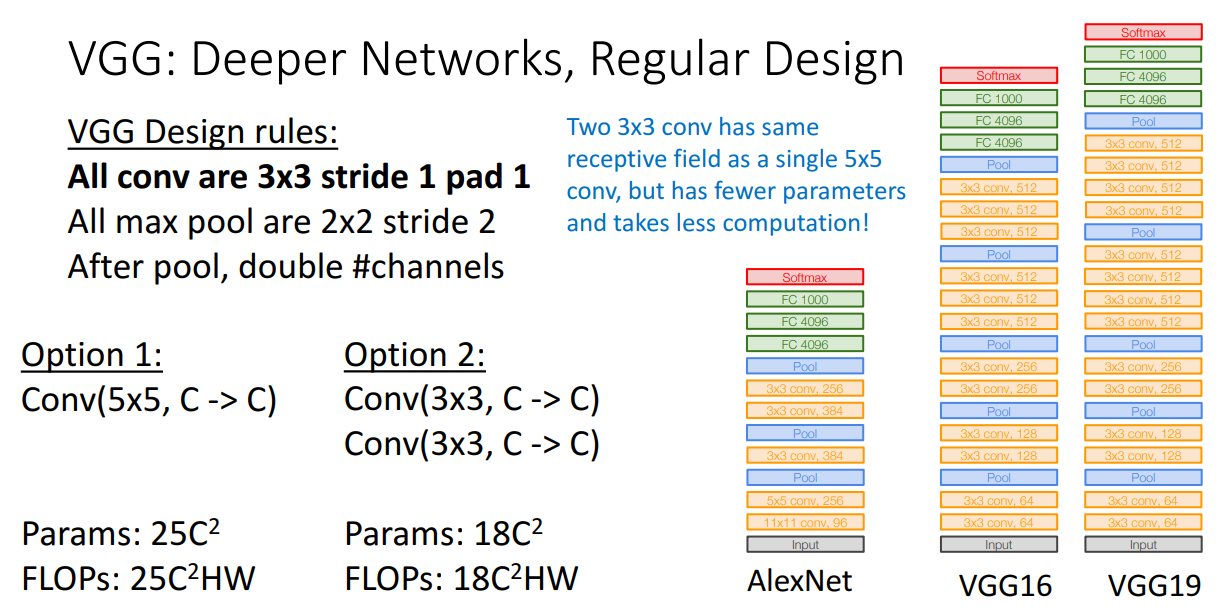
앞선 강의에서 Conv layer를 Nonlinear function 없이 겹쳐쓴다면 하나를 쓰는 거랑 큰 차이가 없다고 설명을 드렸는데, VGG는 Conv layer를 겹쳐쓰는 방식을 택했습니다.
그 이유는 같은 Receptive field 즉 같은 효과를 낼 때는 크기가 큰 필터를 사용하는 것보다 크기가 작은 필터를 여러개 겹쳐쓰는 방법이 연산량이 더 적기 때문입니다.
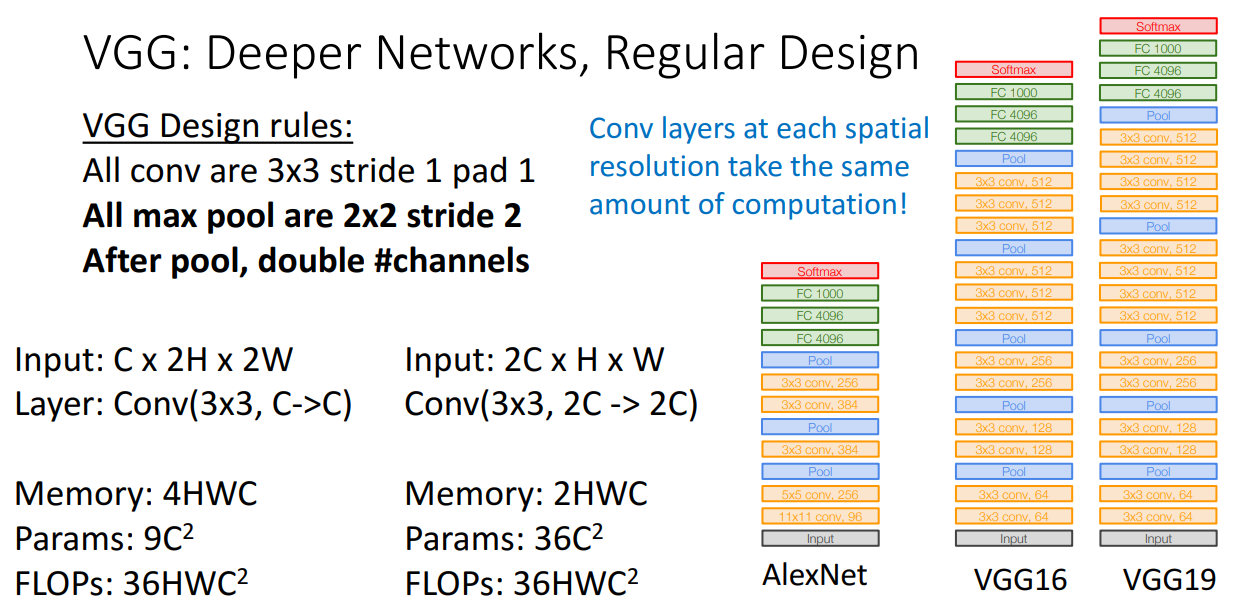
그리고 Max pooling을 2x2 stride 2로 거친 후에 채널을 2배로 만드는 이유는
해상도를 1/2 * 1/2 로 낮춘다면 채널을 2배로 해도 계산량이 동일하기 때문입니다.
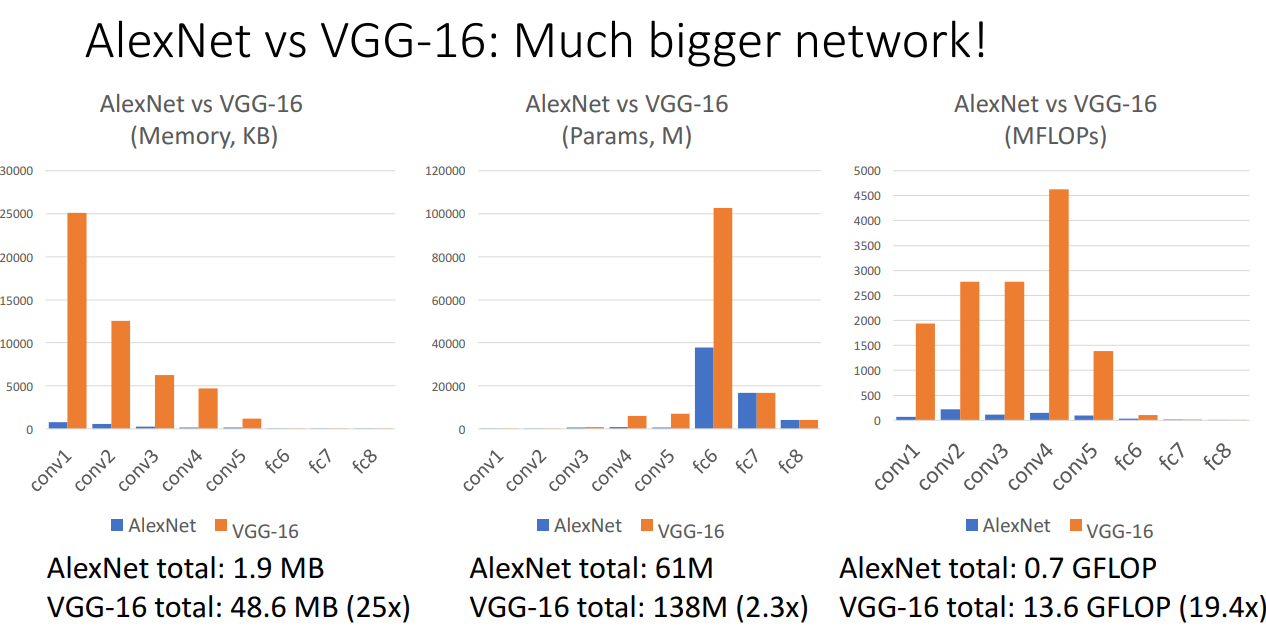
앞서 살펴본 AlexNet과 비교해본다면 VGG 모델의 연산량이 무려 19배나 더 많습니다.
따라서 AlexNet 보다도 훨씬 거대한 네트워크 구조입니다.
GoogLeNet

ImageNet Classification Challenge의 2014년 우승자는 바로 Google 팀에서 만든 GoogLeNet입니다.
해당 이름이 귀여운 점은 앞 강의 리뷰에서 소개했던 1998년의 모델 LeNet의 오마주입니다.
GoogLeNet은 VGG 모델이나 앞선 모델들에 비해서 Efficiency 성능에 대해 많이 고민했습니다.
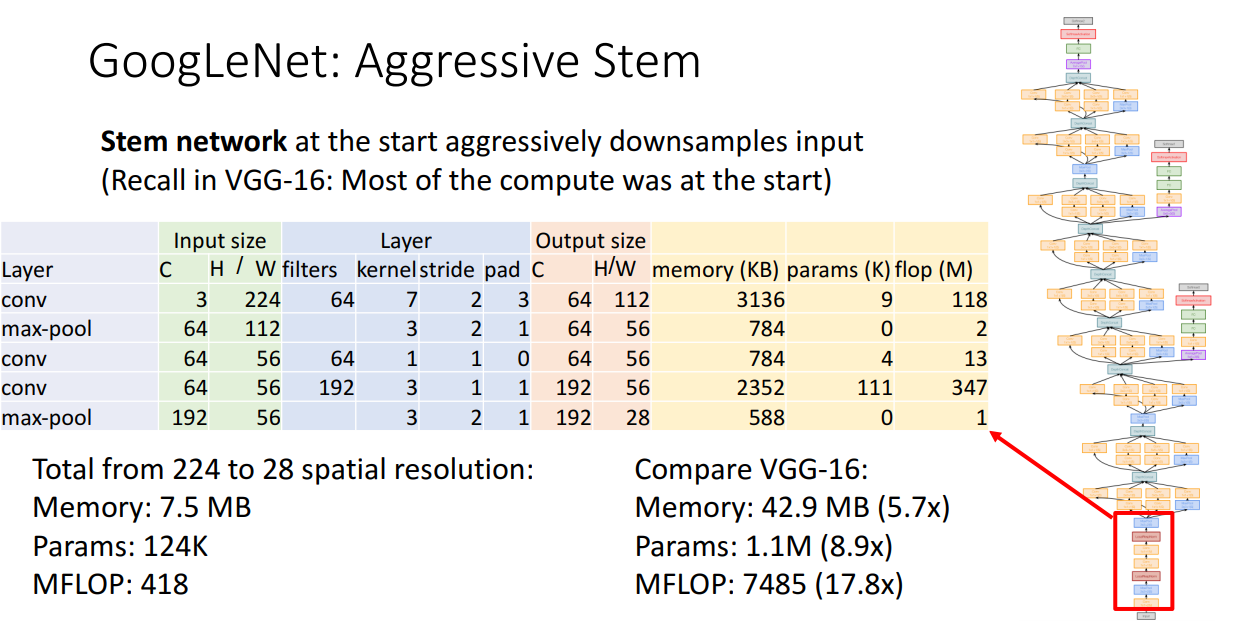
첫번째로, Aggressive Stem 입니다.
네트워크의 초반 부분에서 공격적으로 원본 이미지의 크기를 downsample 합니다.
224x224 크기의 원본 이미지를 28x28 크기의 activation map으로 줄이는 과정을 빠르게 진행합니다.
위 표에 나와있는 구조를 거치는 방식이고, Downsample 하는 과정의 연산량은 VGG와 비교했을 때 약 18배 정도 적습니다.
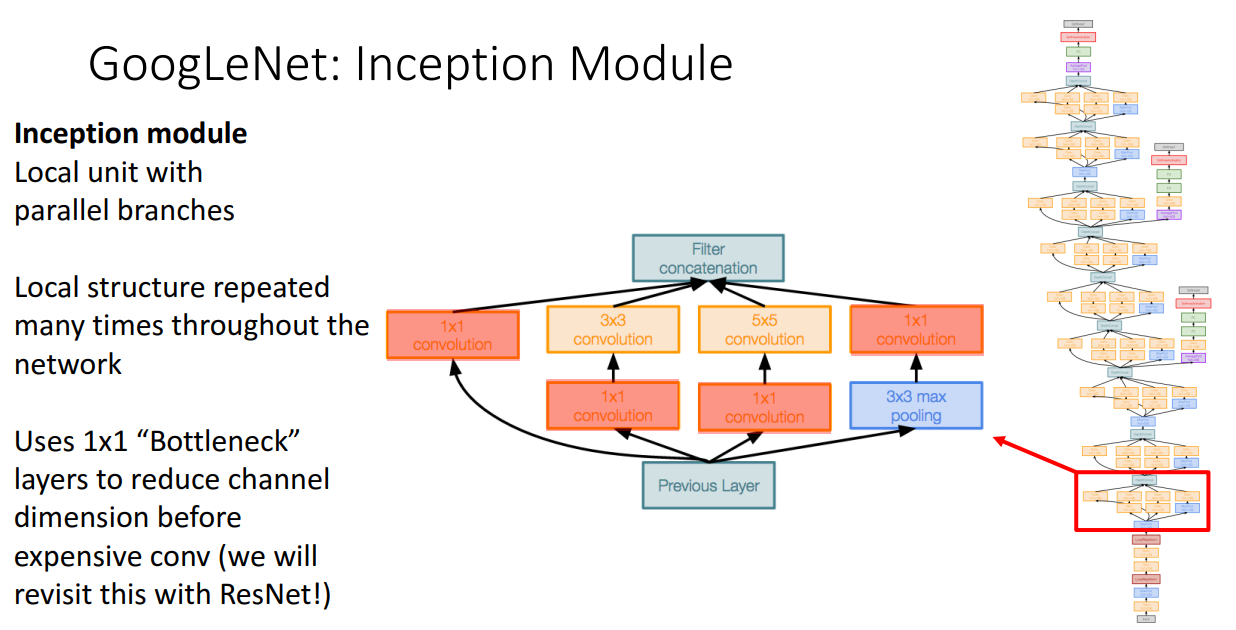
두번째는 Inception Module입니다.
병렬적으로 다른 크기의 kernel 필터를 거치는 구조입니다.
주목할 점은 1x1 Bottleneck Conv 계층을 연산량이 많은 Conv 계층 전에 삽입하는 것인데 이렇게 한다면,
채널의 수를 줄일 수 있어서 연산량이 적어집니다.
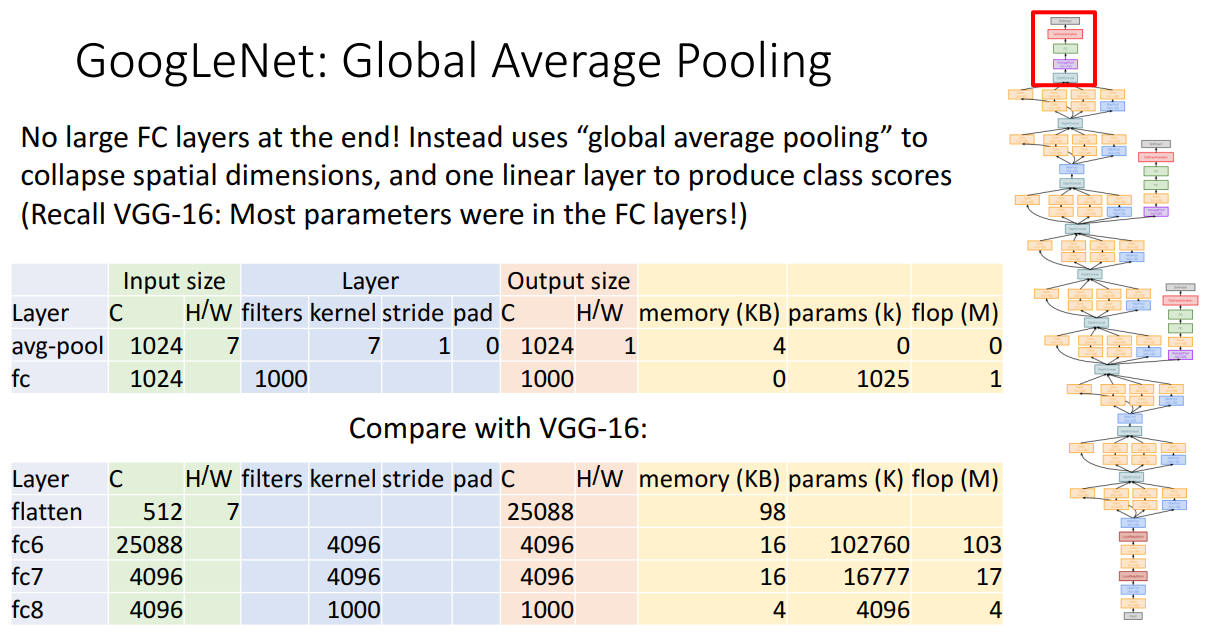
세번째는 Global Average Pooling입니다.
이미지의 Class를 분류하기 위해서 기존 방법들은 네트워크 구조의 마지막 즈음에 이미지를 Flatten 시키고 FC layer를 거치도록 합니다.
AlexNet이 그런 과정을 거쳤고 그 때도 알 수 있듯 학습해야할 파라미터의 수가 너무 많고 연산량도 많았습니다.
따라서 해당 과정을 Global Average Pooling을 통해서 대체합니다.
위 표에서처럼 각 채널별로 7x7 크기의 activation map이 존재했는데 이를 평균 숫자 하나로 요약해서 마치 Flatten 시킨 듯한 효과를 내는 것입니다.
그렇게 했을 때 엄청난 연산량 차이가 생깁니다.

네번째는 Auxiliary Classifiers입니다.
GoogLeNet은 그림에서도 알 수 있듯 상당히 넓고 깊은 모델입니다.
따라서 파라미터들을 학습하기 위해 Gradient를 순전파, 역전파하는 과정이 어렵습니다.
GoogLeNet에서는 해당 문제점을 극복하기 위해서 네트워크 구조 중간중간에서 먼저 분류 작업을 수행해보고 학습할 파라미터들을 학습하게 됩니다.
GoogLeNet을 사용할 분들이 조심해야할 점은 BatchNorm을 사용하면 네트워크 구조 중간중간에서 전혀 다른 값으로 정규화되기 때문에 분류 작업이 불가능하다는 점입니다.
Auxiliary Classifiers를 사용하려면 BatchNorm은 피하셔야합니다.
Residual Networks
마지막 모델은 대망의 Residual Networks 다른 이름으로 ResNet입니다.

ImageNet Classification Challenge의 2015년 우승자이자 ILSVRC, COCO와 같은 다른 이미지 분류 대회에서도 우승을 한 대단한 모델입니다.
그 전까지는 각 대회에서 1등을 거둔 모델들이 다른 경우가 일반적이었는데 ResNet은 모든 대회 성적을 갈아치우는 기염을 토합니다.

2014년에서 2015년으로 넘어갈 때 Batch Normalization이 발견됩니다.
그래서 해당 개념을 활용해서 사람들은 그동안의 네트워크 구조보다 훨씬훨씬 깊은 네트워크를 쌓으려고 노력합니다.
그런데 여기서 문제가 생깁니다.
Deep한 모델이 오히려 Shallow한 모델보다 성능이 별로라는 점입니다.
이러한 원인에 대해서 처음에는 Deep model이 너무 학습을 잘해서 Overfitting 되었구나 생각합니다.

하지만 반전으로 Training 시에도 Shallow 모델이 더욱 좋은 성능을 보여주면서,
Deep 모델은 Overfitting이 아니라 애초에 학습이 잘 안되는 Underfitting 상황임을 깨닫습니다.

위와 같은 사실들을 깨닫고 ResNet은 그렇다면 Deep한 모델이 Shallow한 모델을 모방해보는 것은 어떨까라는 아이디어에서 시작합니다.
그런데 Deep한 모델은 Shallow한 모델을 모방하려는 identitiy function을 잘 최적화하지 못했습니다. 이에 따라 ResNet은 Identitiy Function을 잘 학습할 수 있는 구조를 제시합니다.
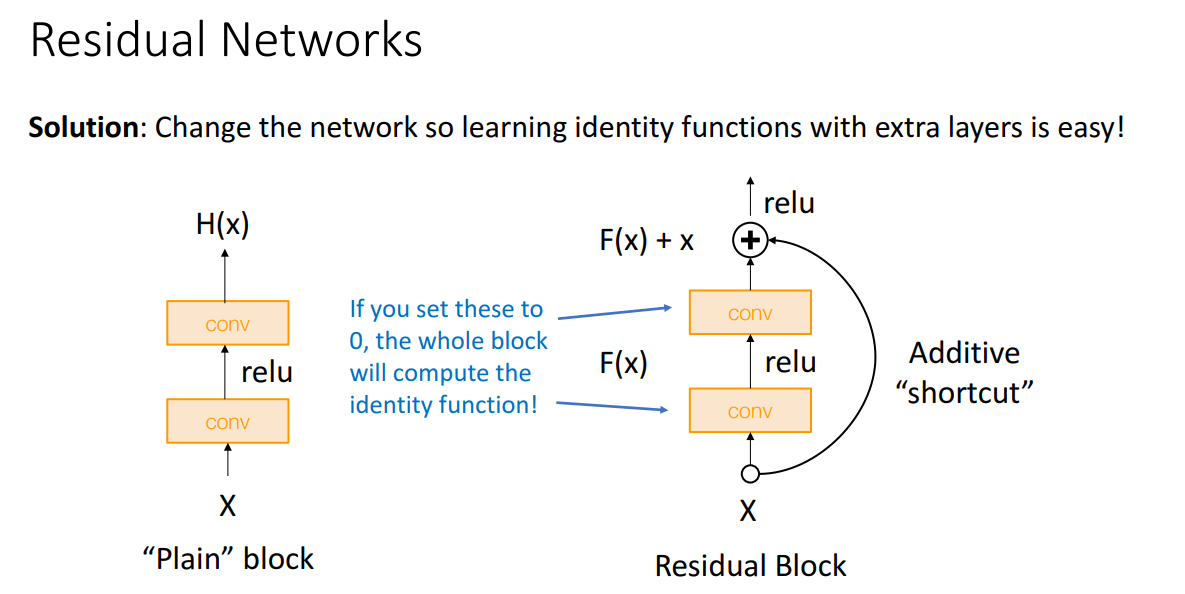
기존 Conv Block에서 Additive "shortcut"을 추가하는 방법입니다.
Residual Block에서 Conv 계층만 무시하면 그냥 Identitiy Function을 계산하는 것이기 때문에, Identity Function 학습이 간단합니다.
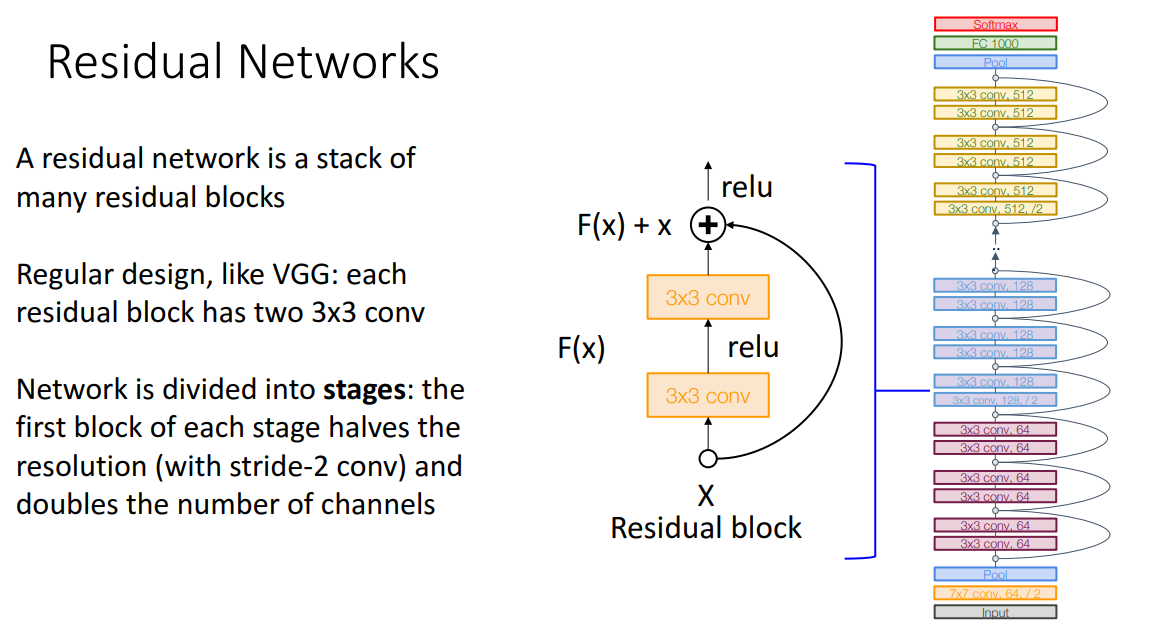
ResNet은 VGG 처럼 일정한 Stage로 구조를 반복하게 되는데 대신에 Residual block을 반복하는 것입니다.
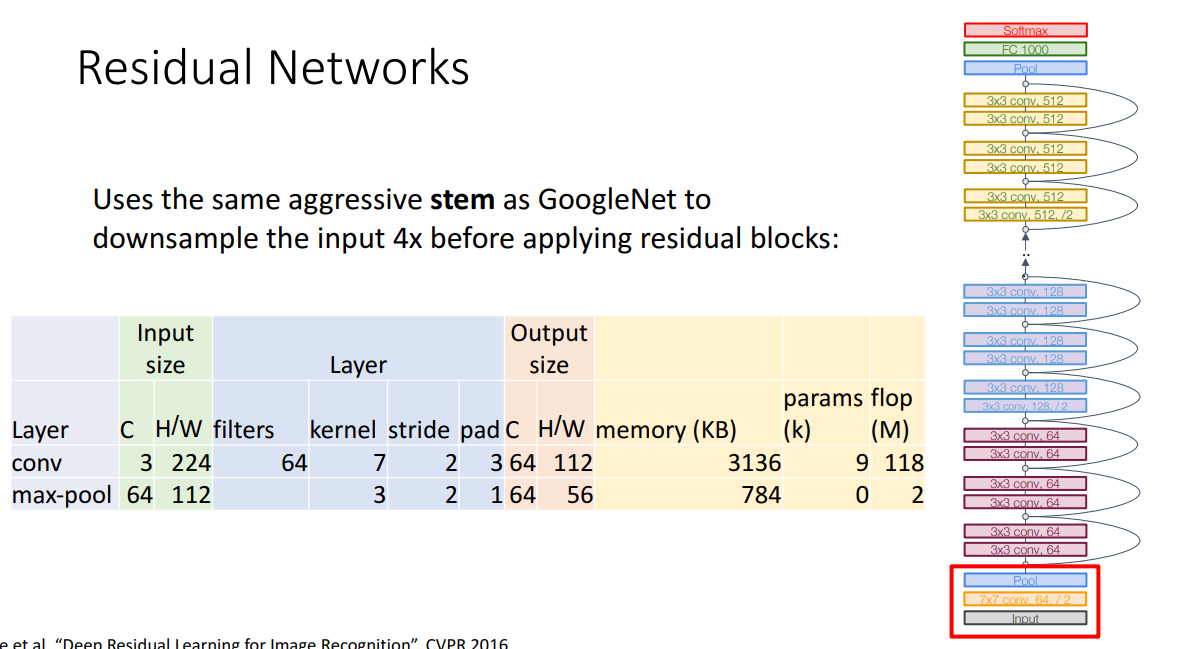
ResNet도 GoogLeNet처럼 초반에 공격적으로 이미지 크기를 줄입니다.

GoogLeNet처럼 Global average pooling도 사용하죠.

ResNet이 좋은 점은 구조를 여러개 제안한다는 점입니다. 물론 깊게 쌓을 수록 성능은 좋지만
연산량이 증가하는 Trade-off가 존재합니다.
하지만 VGG와 비교했을 때는 더 효율적이고 더 성능도 좋습니다.

또한 추가적으로 "Bottleneck" Residual block도 제안하는데 채널을 줄이는 1x1 Conv와 채널은 늘리는 1x1 Conv를 연산량이 많은 Conv 앞뒤로 추가하는 방식입니다.
이렇게 한다면 연산량이 많은 Conv 계층에서 처리해야할 채널이 줄어들어서 실질적으로는 더 효율적이고
동시에 더 많은 비선형성을 얻을 수 있다는 장점이 있습니다.
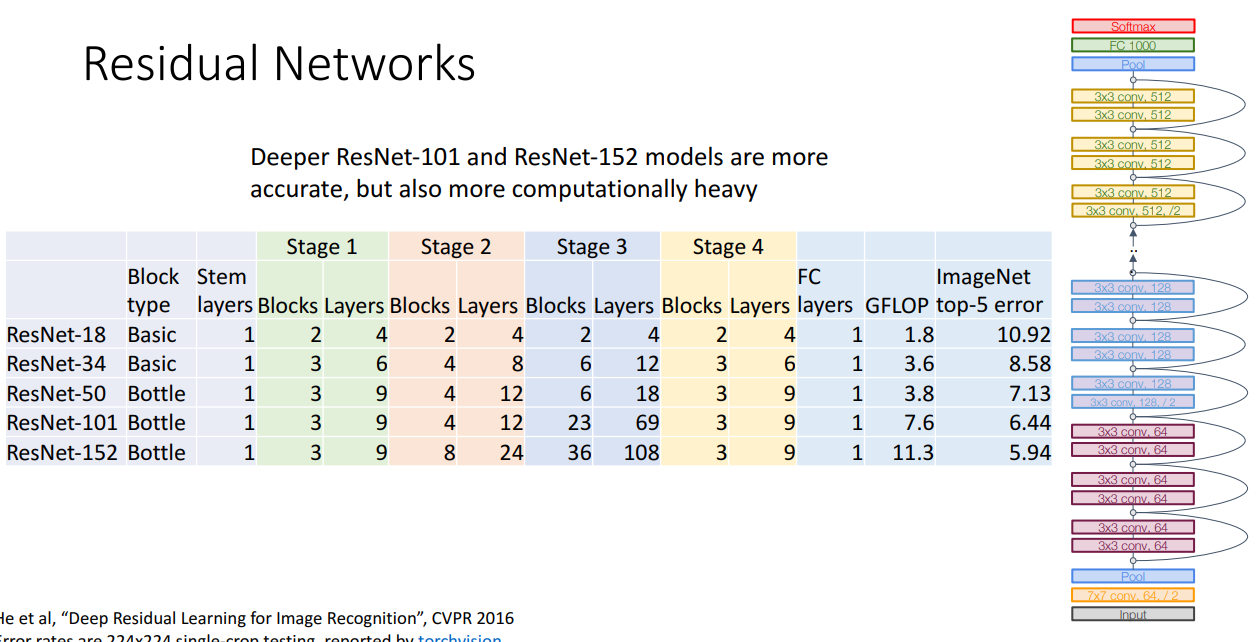
ResNet 50 부터는 Bottleneck Residual block을 사용해서 높은 성능을 보여줍니다.
101이랑 152가 성능은 더 좋긴하지만 연산량이 많습니다.

추후 연구에서는 ResNet Block 내 구조들을 조금 Shuffling해서 더 좋은 성능을 내려는 시도도 있었습니다.
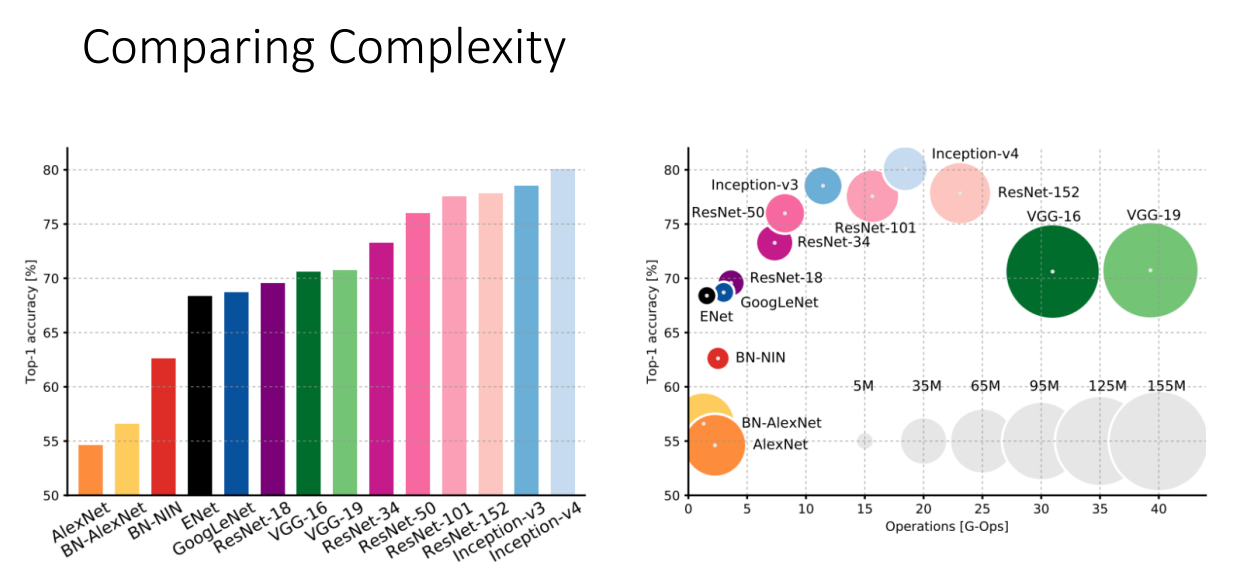
지금까지 살펴본 모델들의 성능과 복잡성입니다.
오른쪽 그림에서 원의 크기가 학습해야할 파라미터의 수, 즉 연산량으로 생각하시면 편합니다.
VGG의 경우 연산량이 상당합니다.
GoogLeNet의 경우 상당히 효율적입니다.
AlexNet의 경우 성능은 떨어지고 효율성도 그닥입니다.
ResNet이 확실히 상대적으료 효율적이면서 가장 좋은 성능을 보여줍니다.
Another Networks
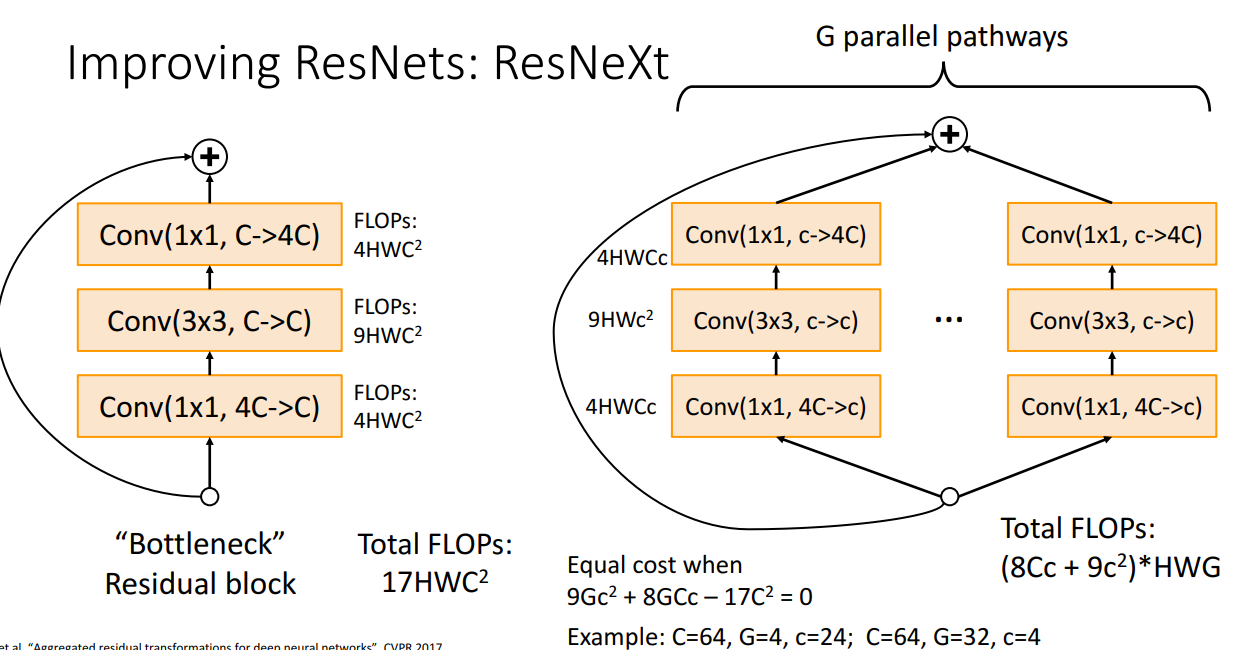
ResNet의 성공에 감명받아 연구된 ResNeXt입니다.
해당 모델은 특이하게 G개의 병렬적인 Residual Block을 거치는데, G와 c를 잘 설정하면 연산량이 기존 Residual Block과 동일합니다.
Grouped Convolution을 사용하는 이 방식이 연산량은 유지한채 더 좋은 성능을 얻어냄을 증명해냅니다.
이밖에도 여러 모델들이 간단하게만 소개되는데 그 중에서 인상깊은 모델을 가져오자면

Depthwise Separable Convolution을 사용한 MobileNets입니다.
해당 모델이 제시된 2017년부터는 이제 성능은 어느 정도 감안하더라도 훨씬 가볍고 효율적인 모델에 대한 연구가 진행됩니다.
MobileNet 외에도 ShuffleNet이 있습니다.
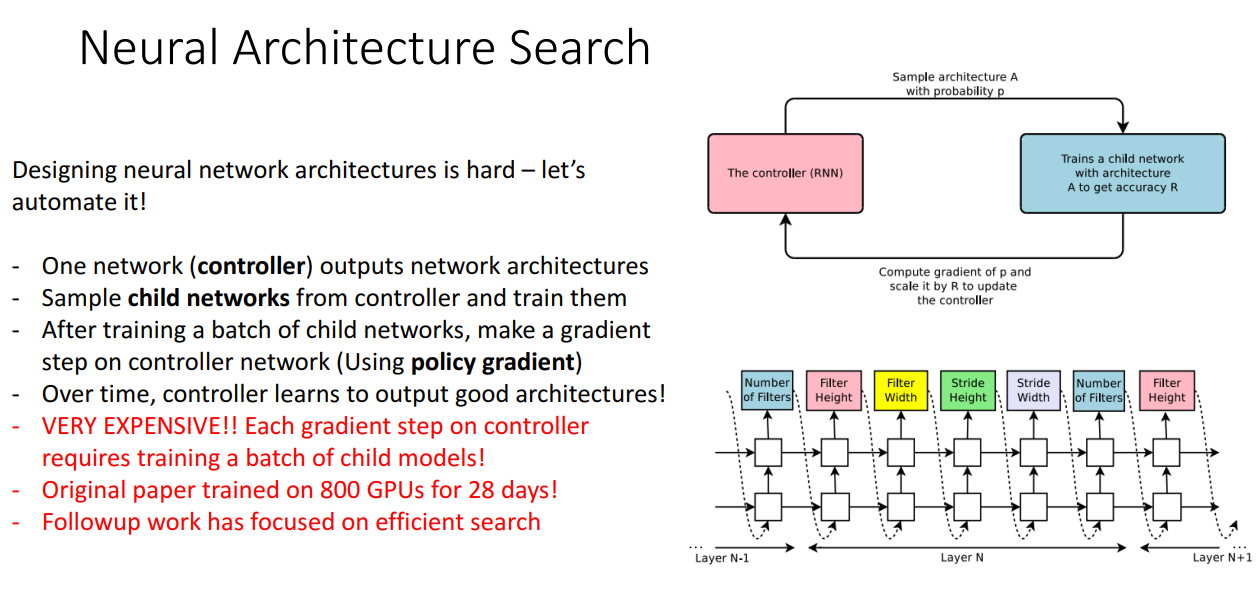
마지막으로 Neural Architecture Search (NAS) 구조입니다.
정확하게 이해는 못했지만 구조를 Design하는 과정을 자동화시켜주는 모델입니다.
엄청엄청엄청 오래 걸리는 모델이니 저는 사용 못할 것 같습니다...

교수님의 조언입니다.
저희는 영웅이 될 필요는 없습니다. 기존 모델을 잘 활용합시다.
성능이 필요하다면 ResNet, 속도가 필요하다면 MobileNet, ShuffleNet 쓰세요~
