[논문 리뷰] Anomaly Detection for Tabular Data with Internal Contrastive Learning
2023 동계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2023년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Tabular 데이터 구조 상 적게 분포되어 있는 out-of-class 샘플들을 찾는 Task 수행
- Single training class의 구조를 포착하기 위해서, 각 샘플과 mask된 부분간의 상호 정보량을 최대화하는 매핑 함수를 학습
- Contrastive loss 사용
- 학습이 끝나면 각 테스트 샘플에 Anomaly 점수 부여 가능
- 같은 하이퍼파라미터 실험을 했을 때 제안 모델이 SOTA
1. Introduction
One-class classification 문제는 학습 데이터로 학습을 시켜놓고 테스트 데이터가 들어왔을 때 학습 데이터의 분포와 유사한지 아닌지를 판단하는 문제로 이를 위해서 특정 기준을 세워놓습니다.
어떤 데이터를 저희가 인식한다고 할 때, input의 구조에 의존하게 됩니다.
예를 들어서 이미지를 rotation해도 class-dependent하여서 저희가 같은 class로 인식할 수 있습니다.
하지만 본 연구에서 다루는 tabular data는 이러한 데이터 구조에 대한 사전 정보가 주어지지 않습니다.
그리고 만약 데이터 구조가 존재하지 않는다고 가정한다면, 즉 모든 변수들이 독립적이라고 가정한다면 기준은 feature별 score를 결합해서 정할 수 있습니다.
하지만 당연하겠지만 모든 변수들이 독립적일 수는 없습니다.
구조가 class-dependent 라는 가정하에 저차원 공간을 만들어서 out-of-distribution class는 그 밖에 찍히도록 만들 수도 있습니다.
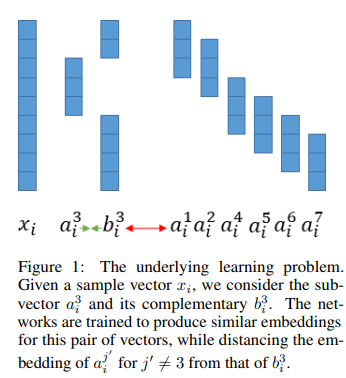
본 연구에서 feature vector에서 변수들의 하위 집합이 나머지 변수와 관련된 방식이 class-dependent하다고 가정합니다. 해당 방법은 연속적인 변수의 하위 집합을 고려합니다. 이러한 방식으로 주어진 입력 샘플에 대해 pair 쌍을 얻을 수 있습니다.
훈련 데이터셋이 주어지면, matching된 요소 사이의 잠재 공간의 상호 정보량이 극대화되도록 하는 신경망 매핑 함수를 학습합니다.
동일한 신경망인 F, G는 모든 샘플 i와 모든 시작 지수 j에 대해 학습되게 됩니다.
상호 정보량의 최대화는 대조학습을 통해 이루어집니다.
Test 시에, anomaly score 는 학습시 최소화되는 loss 입니다.
이는 이상 식별이 일부 규칙성을 학습한다고 가정하는 다른 이상 탐지 방법들과 달리 하나의 목적함수를 수행하는 데에 차이점이 있습니다.
또한 Sliding window 접근법을 사용하기 때문에 높은 anomaly score에 기여한 특정 feature를 알아내는 데에 용이합니다. 이에 따라 interpretability 의 가능성을 제공합니다.
해당 방법론은 일반적이며 데이터 구조에 대해서 거의 가정하지 않습니다.
두 가지 가정이 있는데, 첫번째 가정은 matching elements 를 식별하는 네트워크 F, G를 학습할 수 있다는 것이고, 두번째 가정은 단일 클래스 데이터에 대해 F, G가 훈련할 때 다른 클래스의 샘플에 속하는 matching elements에 대한 인식률이 상당히 낮다는 점에서 class-specific 하다는 것입니다.
F, G가 훈련된 대조학습 task는 와 의 중복을 확인하는 class-independent한 deterministic program 입니다. 하지만 본 연구 모델의 성공은 신경망을 학습하면서 class-specific 모델을 학습한다는 것을 의미합니다. 게다가 synthetic data의 시뮬레이션은 class-independent한 솔루션을 학습하는 것이 오랜 훈련 과정이 필요하며 완벽한 classifier로 수렴하지는 않다는 것을 보여줍니다.
제안 모델은 같은 하이퍼파라미터 선택, single 구조 사용 하에서 Tabular data의 one-class classification task 에서 SOTA를 달성합니다. 벤치마크들에서 일관적으로 성능 향상이 있습니다. 실험을 보면 알 수 있지만 하이퍼파라미터 선택에 민감하지 않으며, 연구의 가정이 타당하다는 것을 보여줍니다.
특정한 설계 선택(첫 번째 약한 가정)을 수행하거나 특정 방법(두 번째)으로 방법을 구현함으로써 두 가지 더 soft한 가정이 도입됩니다.
(i) 간단하게 말하자면, F, G는 j와 상관없이 와 match 하도록 학습됩니다. 대안적인 구현에서, 모든 j에 대한 네트워크 , 쌍을 학습하거나 j에 대한 위치 인코딩을 사용할 수 있습니다.
(ii) 여러 데이터 세트에서 순서가 랜덤하지 않다는 직관에 기초하여 feature들을 원래 제공되는 순서대로 사용합니다. 해당 방법은 기본적으로 연속 벡터 요소를 고려하기 때문에 근처의 feature가 함께 쌓입니다. 당연히, 이 효과의 강도는 데이터 세트에 의존합니다.
2. Related Work
해당 Chapter에서는 Anomaly Detection / Self-supervised Learning / Contrastive Learning /
NeuTraL AD 방법에 대한 내용입니다.
앞선 3개가 관심있으신 분들은 논문을 참고하시고 NeuTraL AD 방법은 다음의 링크를 참고하세요.
https://velog.io/@kbm970709/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Neural-Transformation-Learning-for-Deep-Anomaly-Detection-Beyond-Images
3. Method
d차원의 벡터인 in-class 샘플 의 training set.
Underlying 분포에서 샘플링되었다면 낮은 값, 다른 곳에서 샘플링되었다면 높은 값을 부여하는 점수를 설계하는 것이 목표입니다.
해당 방법론은 차원을 결정하는 두 개의 하이퍼파라미터가 있습니다.
d차원보다 작은 k는 고려하는 feature의 하위집합의 크기를 결정하고 u는 embedding 크기를 결정합니다.
차근차근 방법을 설명하자면 다음과 같습니다.
먼저 각 training 샘플 에서 m=d+1-k 쌍의 집합을 구성합니다.
해당 집합의 각 쌍은 에서 k개의 연속된 feature들을 추출해서 얻습니다.
를 로 하고 여기서 위 첨자는 의 원소를 나타냅니다.
를 로 하고 의 다른 d-k 원소의 벡터로 정의합니다.
그런 다음 와 사이의 상호정보량을 최대로 하는 F, G를 학습합니다.
여기서 j에 상관없이 동일한 매핑 F, G를 학습하게 됩니다.
상호정보량은 noise contrastive estimation framework를 통해 최대화됩니다.
해당 Framework에서 query q, positive sample , negative sample , 에서의 모든 벡터가 존재합니다.
대조학습은 positive sample과 query의 유사성을 극대화하는 동시에 negative sample과 query의 유사성을 최소화합니다.
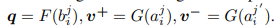
현재의 거의 모든 대조 학습 방법은 unit norm이 1이 되도록 벡터 q와 v+, v-의 Normalization을 사용합니다. Normalization는 입력 벡터 의 모든 하위 벡터를 고려하여 의 각 벡터 차원에 별도로 적용되는 첫 번째 정규화 단계 후에 수행됩니다. 첫 번째 정규화 단계의 동기는 규모 자체가 특정 feature의 식별으로 이어질 수 있기 때문입니다. feature의 이러한 스케일링은 클래스에 종속적인 반면 분류 작업은 클래스에 종속되어야 하기 때문에 클래스에 독립적인 경우가 많다.
Loss Function은 다음과 같습니다.
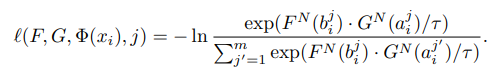
4. Experiments
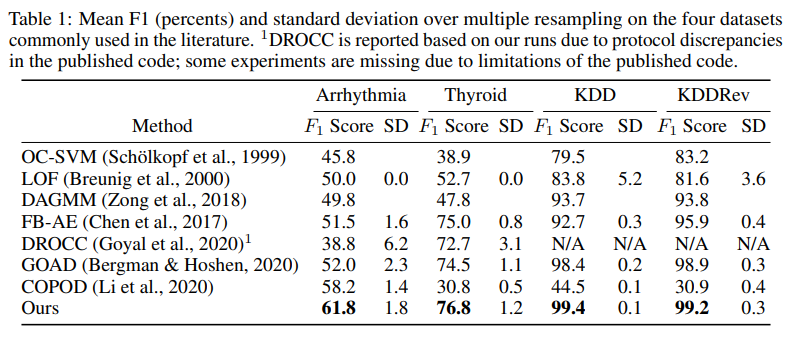
실험 결과 입니다.
4가지 데이터셋으로 실험을 진행하였습니다. Baseline model은 위에 보시는 바와 같습니다.
4가지 데이터셋에서 모두 제안 모델의 F1-score 성능이 높은 것을 확인할 수 있습니다.
훨씬 엄청나게 많은 데이터셋들로도 실험을 진행한 것들이 있으니 궁금하신 분들은 논문을 참고하시면 되겠습니다.
5. Discussion
?
6. Conclusions
본 연구는 Tabular 데이터에 대한 일반적인 one-class classification 방법을 제시했습니다.
해당 방법론은 나머지를 기반으로 missing feature를 식별할 수 있다고 가정하고 다른 auxiliary loss 없이 contrastive loss를 사용했습니다.
광범위한 실험에서 기존의 이상 탐지 방법보다 훨씬 좋은 성능을 나타냈습니다.
게다가 서로 다른 데이터셋에 대해 튜닝할 필요가 없으며 하이퍼파라미터에 Robust 합니다.

안녕하십니까? 리뷰 잘 보았습니다. 리뷰를 보고 흥미가 생겨 논문 페이지에 들어가 논문을 직접 읽어보고 데모도 실행해 보았습니다. 논문에 따르면 정상 셋으로 훈련시킨 모델에 대해 이상 데이터의 contrastive loss가 크게 나타날 것이라고 하는데, 정확히 어느 지점에서 정상 범주의 loss, 즉 threshold를 설정해야할지는 도메인 knowledge를 이용하여 사용자가 직접 판단해야 하는 것인가요? 데모에서는 test셋의 이상 셋 데이터 개수를 cheating하여, 이를테면 이상 데이터가 10개로 구해졌다면 loss값이 상위 10개인 데이터를 이상 데이터로 판별하였는데 실제 application에서는 이상 셋 개수를 알 수 없으니 loss를 구해도 threshold를 어느 지점으로 설정해야할지 잘 모르겠습니다.. 데모와 논문에 포함된 다양한 데이터셋들을 확인해보았으나 threshold loss가 제각각이라.. AI 초보자라 관련 인사이트를 공유받고자 글 남깁니다. 감사합니다!