[논문 리뷰] Neural Transformation Learning for Deep Anomaly Detection Beyond Images
2023 동계 Paper Review

본 Paper Review는 고려대학교 스마트생산시스템 연구실 2023년 동계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다.
Abstract
- Self-supervised learning에서 Data transformations 은 중요함
- 다양한 view로 이미지를 변환하여 학습하면 신경망이 downstream task에 적합한 feature representations을 학습할 수 있음 (ex. Anomaly Detection)
- 어떤 transformations을 사용할 지 결정하는게 확실하지 않기에, 본 연구에서는 end-to-end로 Anomaly Detection을 위한 learnable transformations 과정을 제시함
- 각기 다른 transformations끼리는 구별되게 하며, transformed data는 untransformed data를 닮도록 semantic space에 embed하는 아이디어
- One- vs. -rest / n- vs. -rest 모든 실험에서 좋은 성능
1. Introduction
최근 이상 탐지 분야는 Data Augmentation 패러다임에 의존해서 발전해왔습니다.
특히 이미지 데이터의 경우, 자기지도학습 상황에서 Rotation, Reflection, Cropping 등 다양한 Transformations가 데이터의 다양한 views를 학습하기 위해서 사용됩니다.
이렇게 Transformation을 적용한다면 transformation prediction과 다양한 관점으로 학습되는 representations들로 의해 강력한 Anomaly Detectors를 이끌어낼 수 있습니다.
하지만 이미지 데이터 말고, 시계열이나 Tabular 데이터에서는 어떤 Transformations을 적용해야 좋을지 알려진게 없기에 적용하기 어려운 상황입니다.
본 연구는 images 외에 다른 데이터 타입에 자기지도 이상탐지를 제안합니다.
모델 이름은 neural transformation learning for anomaly detection (NeuTraL AD)이고, learnable transformations으로 anomaly detection을 하는 end-to-end 방법론입니다.
Data transformation을 만들기 위해 auxiliary prediction task를 수행하지는 않고 그 대신, 효과적인 data transformations과 anomaly thresholding을 학습할 수 있는 목적함수를 제시합니다.
조금 더 정확히는 다른 viwe들끼리는 구별되게 하고, 같은 view라면 transformed된 샘플과 untransformed form 샘플간의 semantic information을 공유하여 닮도록하는 transformations을 학습합니다.
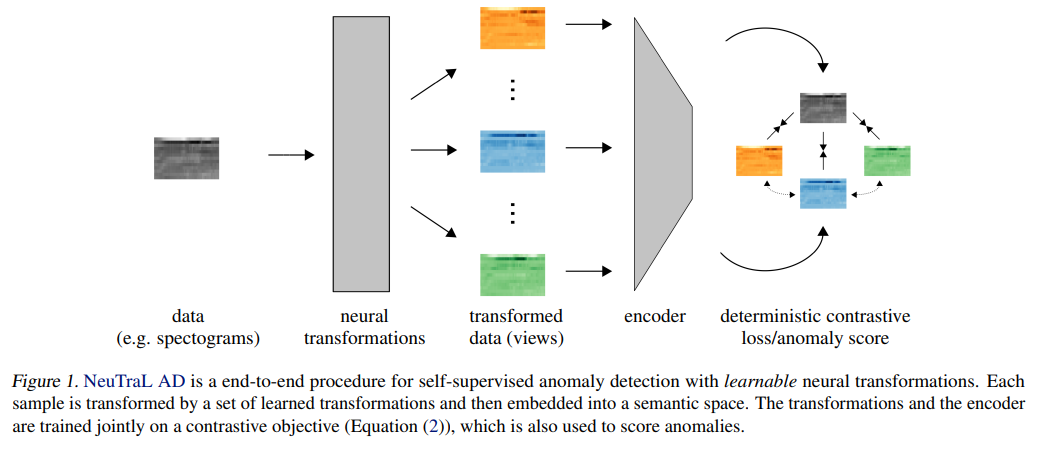
NeuTraL AD는 learnable transformations 와 encoder model 두 구성요소로 이루어져있습니다.
두 구성요소는 deterministic contrastive loss (DCL)에 의해 jointly 학습됩니다.
해당 loss는 다른 표현학습에서의 contrastive loss와 다르고 image anomaly detection에서의 loss와 다르며 negative samples을 사용하는 모든 loss들과 다릅니다.
추가적인 regularization이나 adversarial training이 필요없는 non-stochastic 목적함수를 제시하고, 이는 곧 anomaly score가 됩니다.
2. Related Work
Deep Anomaly Detection
Deep Learning은 기술적으로 엄청난 발전을 이뤘지만, 이상탐지 분야에 활용된 것은 최근입니다.
관련된 방법론들은 Deep autoencoder, Deep one-class classification, Deep generative models, Outlier exposure 등 다양합니다.
자기지도 Anomaly detection을 Detection Accuracy을 크게 향상시켰습니다.
사용 사례로 데이터를 augment한 후 어떤 transformations이 적용되었는지 예측하는 방법입니다.
학습이 끝난 후에 나오는 Classifier는 Anomaly detection에 사용됩니다.
자기지도 Anomaly detection의 다른 방법은 같은 image로부터 나온 두개의 view를 맞히는 contrastive loss로 classifier를 학습하는 방법입니다.
이렇게 한다면 strong representations을 얻을 수 있고 이상탐지에 활용할 수 있습니다.
자기지도 Anomaly detection 방법을 image 외에 다른 도메인에서 사용하고자 하는 노력도 있었습니다.
유사하게 transformation prediction을 기반으로 하지만 open-set setting을 사용했습니다.
Tabular data를 위해 random affine transformations을 적용합니다.
본 연구에서는 유사하지만 학습 가능한 transformations을 사용하고 더 높은 성능을 얻어냅니다.
Self-Supervised Learning
자기지도 학습은 대부분 auxiliary task를 위한 data augmentation에 의존합니다.
Auxiliary tasks (e.g. patch prediction, solving jigsaw-puzzles, cross-channel prediction, rotation prediction)으로 학습한 네트워크는 downstream task를 위한 feature extractors로 사용됩니다.
Image에서 주로 발전되어왔지만, 시계열 representations 추출을 위한 temporal order verification과 같은 auxiliary task 방법론도 제안되었습니다.
Contrastive Representation Learning
대부분의 자기지도 방법론들은 InfoMax 방식을 따르고 있습니다.
해당 방법 기반들은 데이터와 문맥 간 혹은 데이터의 각기 다른 views들간의 "상호정보량"을 극대화하도록 학습됩니다.
이러한 방법들에서 상호정보량을 계산하는 일은 힘들기 때문에, approximation 혹은 bounds 들이 사용되곤 합니다.
본 연구에서도 Contrastive loss를 사용했지만 같은 샘플에서의 두개의 views와 다른 샘플들에서의 views들을 미니배치 안에서 대조하는 방법을 선택하지 않고, 같은 샘플에서의 서로 다른 views로부터 original version을 결정하도록 학습되었습니다.
이렇게 single sample만을 사용하는 방법은 test 시에 anomalies에 score를 부여할 수 있고, data transformation을 학습시킬 수 있다는 장점이 있습니다.
Learning Data Augmentation Schemes
Data Augmentation 방법은 예전부터 있어왔습니다.
일반적으로는 Hand-crafted data augmentation 방법들이었죠.
본 연구에도 차용한 방식은 Framework 안에 representation learning을 위한 views들을 생성해내는 방법을 학습하는 방식입니다.
이렇게 하면 original sample과 semantic information을 공유하지 않는 trivial solution인 view들을 피하도록 학습할 수 있습니다.
NeuTraL AD 방법론은 시계열이나 Tabular data 에서도 사용할 수 있으며 특히 시계열에서 상당히 좋은 성능을 보입니다.
3. Neural Transformation Learning for Deep Anomaly Detection
Proposed Method: NeuTraL AD
NeuTraL AD 방법론은 Learnable transformations와 Encoder 두 개의 파이프라인으로 이루어져있습니다.
둘 모두 deterministic contrastive loss (DCL)에 의해 jointly 학습됩니다.
목적 함수는 두 가지 목적으로 작동하는데,
첫번째로 학습 시에 encoder와 transformation의 parameters를 최적화시키고,
두번째로 추론 시에 각 Sample들이 inlier인지, anomaly인지 스코어링합니다.
Learnable Data Transformations
몇 가지 notation만 살펴보면 다음과 같습니다.
- Data Sample
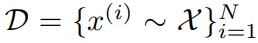
- K transformations
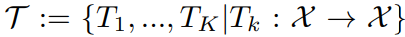
Transformations 은 학습 가능합니다.
Gradient-based 최적화 방법들로 parameter들을 학습시킬 수 있고, 저자는 feed-forward 신경망을 사용했습니다.
Deterministic Contrastive Loss (DCL)
본 연구의 가장 핵심 부분입니다. NeuTraL AD는 새로운 목적함수를 제시합니다.
DCL 손실함수는 transformed sample과 original sample을 가깝게 하고 다른 transformed version sample과는 멀어지게 합니다.
- 이를 위한 Score Function은 다음과 같습니다.
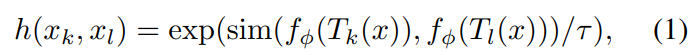
Score Function에서 f 함수가 X → Z 하는 encoder 함수이며 features extractor 입니다.
sim function은 consine similarity 입니다.
- 다음으로 DCL 손실함수는 다음과 같습니다.
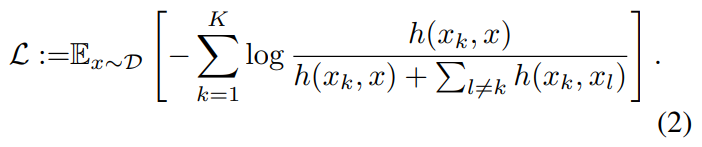
위 식의 분자는 transformed sample을 original sample과 가깝게 합니다.
그렇게 함으로써 transformation이 semantic information을 보존하도록 합니다.
위 식의 분모는 transformed sample들이 다른 transformed sample들과 멀어지도록 합니다.
위 식에서 parameter들은 입니다.
는 encoder의 parameter & 는 transformation들의 parameter 입니다.
Anomaly Score
본 연구의 장점은 training loss가 곧 anomaly score가 된다는 점입니다.
- Anomaly Score의 공식은 다음과 같습니다.
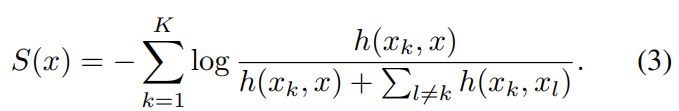
해당 Score는 deterministic하며 새로운 data point에 대해 곧바로 평가되기 때문에 negative sample이 필요가 없습니다.
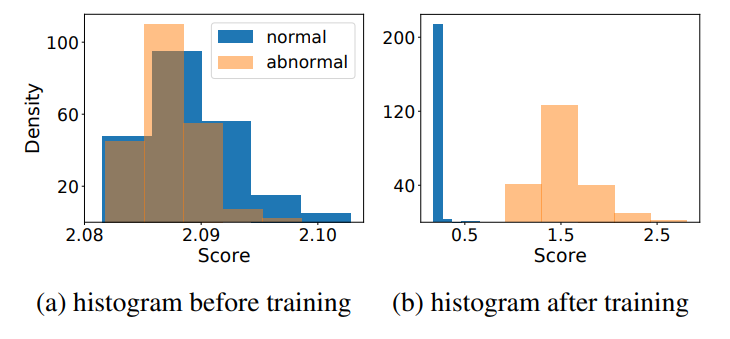
따라서 학습을 진행해서 DCL을 최소화하고 나면 위 그림처럼 정상과 이상의 Score가 뚜렷하게 구분됩니다.
해당 Score 방식은 상당히 simple하고 추가적인 regularization이나 constraints가 필요없습니다.
A Theory of Neural Transformation Learning
자기지도 이상탐지를 위한 transformation을 학습하는 과정을 수학적으로 증명이 가능합니다.
크게 두 개의 Requirement를 성립하는 transformation들을 사용하면 됩니다.
- Semantics: Transformations은 original data와 관련있는 semantic 정보를 공유하는 views 를 만들어내야함
- Diversity: Transformations은 각 샘플의 다양한 views들을 만들어낼 수 있어야함
위 두 개의 Requirement는 trade-off 관계입니다.
Transformation을 신경망 학습으로 수행하고 성공적인 자기지도 학습을 수행하기 위해서는 두 조건을 만족해야합니다.
만약 Semantics 조건을 만족하지 못한다면 input x의 정보 자체가 반영되지 않으므로 정상/비정상 여부를 판단할 수 없습니다.
그리고 Diversity 조건을 만족하지 못한다면 자기지도 학습 자체가 수행되지 않습니다.
NeuTraL AD가 두가지 관점에서 다 만족할 수 있었는데 다른 접근 방식들은 왜 별로인지 알아보겠습니다.
-
K개의 transformation 중 어떤 transformation을 가했는지 예측하는 방법입니다. 이 경우에는 softmax classification loss를 사용합니다.
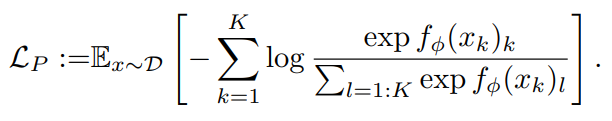
-
SimCLR로 미니배치 안에서 두 개의 데이터와 두 개의 transformation을 뽑아 positive pair 끼리는 유사도가 높도록, negative pair 끼리는 유사도가 낮아지도록 학습하는 방법입니다.
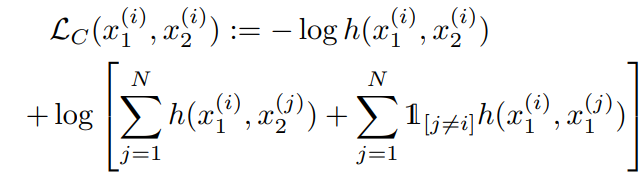
위 두 방법들은 이미지를 위한 anomaly detectors로서 고정되어 있어서 다른 데이터 형태에는 적용하기가 어렵습니다.
왜 해당 방법들이 적합하지 않은지는 Proposition으로 설명되어있습니다.


첫번째 Proposition을 보시면 constant transformation은 입력에 상관 없이 고정된 transformation을 도출하기 때문에 적용된 transformation 종류를 예측하는 문제가 굉장히 시워집니다. 따라서 목적함수의 최저값이 되어버려 semantics 조건을 만족하지 않는 transformation이 학습될 수 있습니다.
두번째 Proposition을 보시면 Identity transformation은 transformation이 모두 동일해져 버리는 현상인데 로 transformation을 학습할 경우 positive pair가 쉽게 파악될 수 있는 identity transformation이 학습될 가능성이 있습니다.
이러한 Proposition들에 따라 와 는 정상과 이상 모두 같은 loss를 만들어내게 될 위험이 있습니다.
이를 방지하기 위한 몇 가지 방법으로 careful parametrization, regularization, adversarial training 세 가지 정도있습니다.
이를 모두 사용한 방법도 있지만 NeuTraL AD 방법은 DCL 손실함수를 통해 이를 해결합니다.
분자 부분을 통해 transformed data가 원래 데이터와 유사도가 높아지도록 동작하므로 semantics 조건을 만족시키고, 분모 부분을 통해 각 transformed data끼리의 유사도가 낮아지도록 동작해 diversity 조건을 만족시킵니다.
또 하나의 DCL의 장점은 SimCLR와 다르게 대조 학습을 위한 negative sample이 필요 없기 때문에 훈련 및 추론 시 시간적 이득이 있습니다.
4. Empirical Study: Deep Anomaly Detection of Time Series and Tabular Data
본 논문의 방법론의 장점은 다양한 데이터 타입에서 사용 가능하다는 점이고, 이미지에서는 이미 대조학습을 hand-crafted transformation으로 잘 사용하고 있기 때문에 Tabular 데이터와 시계열 데이터에 대해 이상탐지 실험을 수행합니다.
Evaluation Protocol
일반적으로 쓰이는 one-vs-rest(하나의 클래스만 정상, 나머지 클래스를 비정상)와
더 어려운 n-vs-rest(n개의 클래스를 정상, 나머지 클래스를 비정상) 상황에서 실험을 진행했습니다.
Shallow and Deep Anomaly Deteciton Baselines
비교 모델들은 다음과 같습니다.
- Traditional Anomaly Detection Baselines
OC-SVM / IF / LOF - Deep Anomaly Detection Baselines
Deep SVDD / DROCC / DAGMM - Self-Supervised Anomaly Detection Baselines
GOAD / 이미지에서 좋은 성능을 보이는 대조학습을 시계열에 맞게 변형한 모델 Ts - Anomaly Detection Baselines for Time Series
RNN / LSTM-ED
Anomaly Detection of Time Series
이상탐지 실험은 전체 Sequence 레벨에서의 이상을 탐지하게 됩니다.
사용된 데이터셋들은 다음과 같습니다.
- SAD / NATOPS / CT / EPSY / RS

결과를 보시면 알 수 있듯 모든 RS를 제외한 모든 데이터셋에서 NeuTraL AD 방법론이 가장 좋은 AUC 성능 지표를 얻어냈습니다.
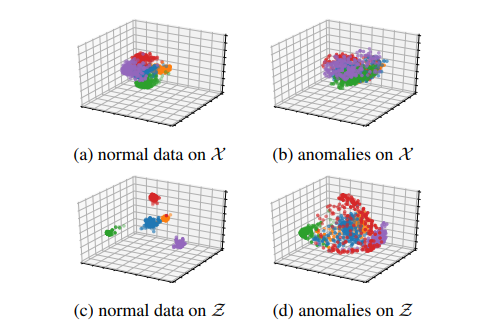
위 그림을 보시면 정상/비정상 데이터가 DCL에 의해 어떻게 훈련되었는지 확인할 수 있습니다.
정상 데이터에 K = 4 transformation (a)에 대해 encoder로 추출한 feature space (c)를 보면 서로 다른 transformation에 대해 매우 퍼져있고 같은 transformation들끼리 군집된 것을 확인할 수 있습니다. 반면 비정상 데이터는 transformation과 상관없이 매우 덜 구조화된 것을 알 수 있습니다.

정상 클래스 하나에 K = 4 transformation을 적용한 결과입니다.
보시면 각자 다른 부분에 초점을 두고 있는 것을 확인할 수 있습니다.

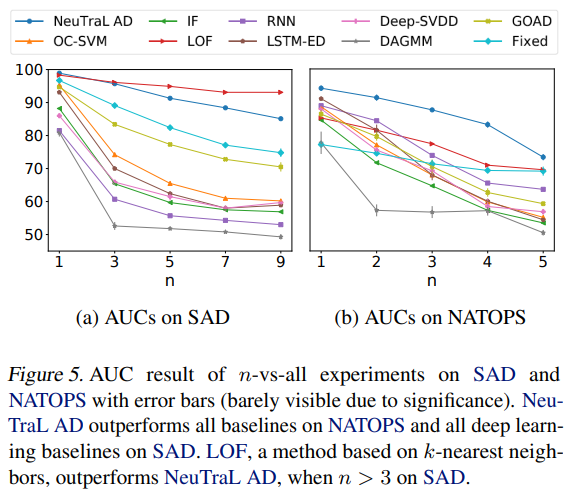
n-vs-rest 상황에서도 제안한 모델이 좋은 결과를 주로 보여주곤 하는데, 비교적 간단한 SAD 와 같은 데이터셋에서는 k-nn 기반의 LOF가 제일 높은 성능을 보였습니다.
Anomaly Detection of Tabular Data
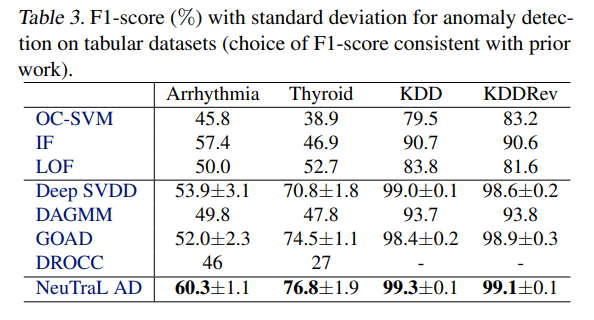
Tabular Data 또한 이상탐지가 중요한데, 4가지 데이터셋으로 실험을 진행했고 그 결과 제안한 모델의
F1-Score가 가장 좋다는 것을 알 수 있습니다.
Design choices for transformations
실험에서는 로 구성했지만 (feed forward)나
(residual) 식으로도 transformation을 구성할 수 있습니다.

위 그림을 보시면 인 순간부터 성능이 안정적으로 높게 나오고, 그 전까지는 transformation 수가 적어서 효과적인 이상탐지가 힘듭니다. 그리고 transformation 방법들간의 성능 차이가 그리 크지는 않습니다.
5. Conclusion
본 논문에서는 learnable transformations을 할 수 있는 자기지도 이상탐지 방법론을 제시합니다.
해당 목적함수의 핵심은 DCL 손실함수이며 이는 original sample과 semantic 정보를 공유하는 다양한 views을 만들어내는 transformation을 가능하게 합니다.
본 논문의 방법론은 시계열이나 tabular data에도 적용 가능하고, 실험 또한 여러가지 데이터 타입의 데이터셋으로 진행해서 SOTA 성능을 거뒀습니다.
