batch I/O 기법
- inner쪽 인덱스와 조인하면서 중간 결과집합을 만든 후에 inner쪽 테이블과 일괄(batch) 처리한다.
- batch I/O를 사용하려면
nlj_batching(inner 테이블 별칭)hint 사용, prefetch로 단계를 내려가러면no_nlj_batching(inner 테이블 별칭)hint 사용 - nested loops가 중복으로 나타남.
- 메모리에 inner쪽 데이터블록이 있으면 실행계획에서는 batch i/o로 나와도 실제 동작은 일반 nested loops 처럼 작동된다.
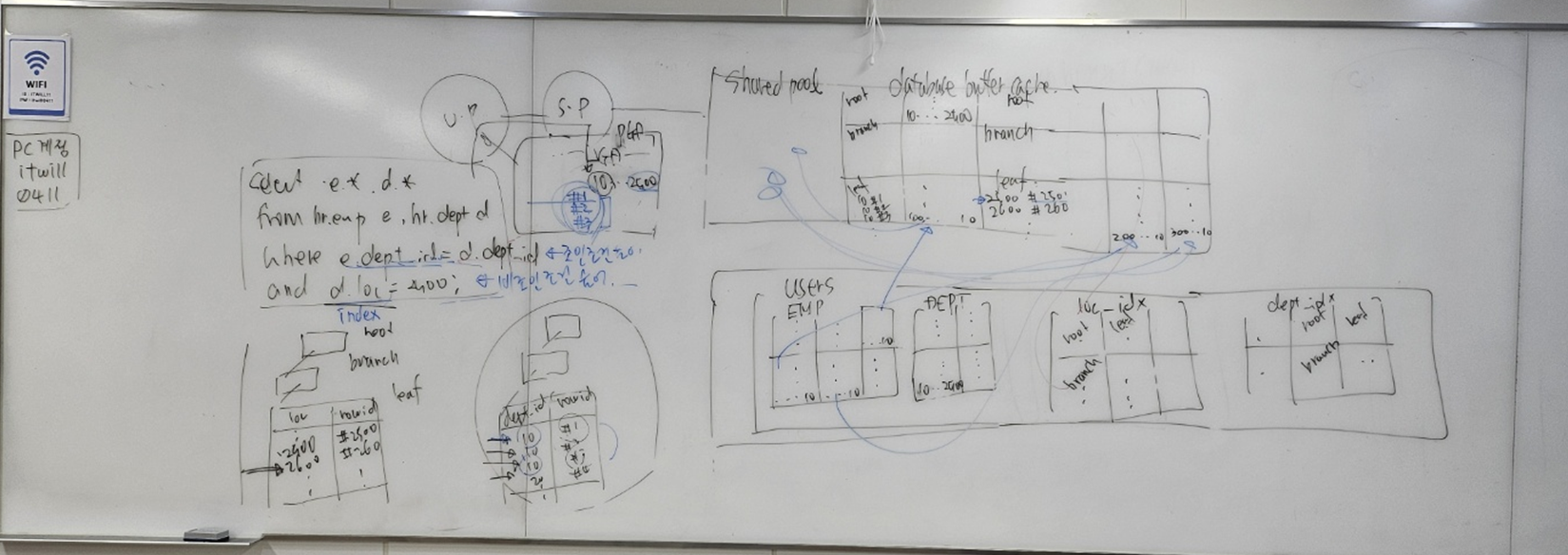
select /*+ gather_plan_statistics */ e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id
and d.location_id = 2500;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 2696597736
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 34 |00:00:00.01 | 11 | 3 |
| 1 | NESTED LOOPS | | 1 | 10 | 34 |00:00:00.01 | 11 | 3 |
| 2 | NESTED LOOPS | | 1 | 10 | 34 |00:00:00.01 | 7 | 3 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS | 1 | 1 | 1 |00:00:00.01 | 3 | 2 |
|* 4 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 1 | 1 | 1 |00:00:00.01 | 2 | 1 |
|* 5 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 1 | 10 | 34 |00:00:00.01 | 4 | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 34 | 10 | 34 |00:00:00.01 | 4 | 0 |
------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("D"."LOCATION_ID"=2500)
5 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")table prefetch 기법
- 디스크 I/O를 수행하려면 비용이 많이 들기 때문에 한번에 I/O call이 필요한 시점에 곧이어 읽을 가능성이 높은 블록들을 데이터베이스 버퍼 캐시에 미리 적재해 두는 기능(physical I/O를 줄일 수 있다)
- inner 쪽에 non unique index를 range scan 시에 발생한다.
- index scan은 single block I/O가 발생한다. 이때 발생하는 이벤트는
db file sequential read(multi block I/O가 아니라 single block I/O 라는 증거) 발생할 수 있는데 table prefetch기능이 수행되면df file paralle reads이벤트가 같이 발생한다. - prefetch를 적용할때
nlj_prefetch(inner 테이블 별칭)hint 사용, 적용하지 않을때no_nlj_prefetch(inner 테이블 별칭)hint 사용 - nested loops 위에 원래 inner에 있어야할 테이블이 있음
- 메모리에 inner쪽 데이터블록이 있으면 실행계획에서는 prefetch로 나와도 실제 동작은 일반 nested loops 처럼 작동된다.
select /*+ gather_plan_statistics no_nlj_batching(e) */ e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id
and d.location_id = 2500;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 17944037
------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 0 | | 0 |00:00:00.01 | 0 | 0 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED | EMPLOYEES | 1 | 10 | 34 |00:00:00.01 | 11 | 4 |
| 2 | NESTED LOOPS | | 1 | 10 | 34 |00:00:00.01 | 7 | 3 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| DEPARTMENTS | 1 | 1 | 1 |00:00:00.01 | 3 | 2 |
|* 4 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 1 | 1 | 1 |00:00:00.01 | 2 | 1 |
|* 5 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 1 | 10 | 34 |00:00:00.01 | 4 | 1 |
------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("D"."LOCATION_ID"=2500)
5 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")일반 nested loops
select /*+ optimizer_features_enable('10.1.0') gather_plan_statistics leading(d,e) use_nl(e) no_nlj_prefetch(e) */ e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id
and d.location_id = 2500;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 968347104
------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 34 |00:00:00.01 | 11 |
| 1 | NESTED LOOPS | | 1 | 5 | 34 |00:00:00.01 | 11 |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 1 | 1 |00:00:00.01 | 3 |
|* 3 | INDEX RANGE SCAN | DEPT_LOCATION_IX | 1 | 1 | 1 |00:00:00.01 | 2 |
| 4 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 10 | 34 |00:00:00.01 | 8 |
|* 5 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 1 | 10 | 34 |00:00:00.01 | 4 |
------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("D"."LOCATION_ID"=2500)
5 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")sort merge join
- 조인되는 건수가 많을때 유리하다.
- sort에 대한 성능 문제가 발생할 수 있다.
- sort시키는건 cpu의 연산작업이다.
use_merge,leading(first, second)hint가 필요- first table : 유니크한 컬럼이 있는 테이블
- second table : 중복된 값들이 많은 테이블
- sort merge join 단계
1) 조인 키 컬럼을 기준으로 양쪽 집합을 정렬한다.
2) 정렬된 양쪽 집합을 서로 merge 한다.
select /*+ gather_plan_statistics */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 1343509718
------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 18 | 1 | | | |
| 1 | MERGE JOIN | | 1 | 106 | 106 |00:00:00.01 | 18 | 1 | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 12 | 0 | | | |
| 3 | INDEX FULL SCAN | DEPT_ID_PK | 1 | 27 | 27 |00:00:00.01 | 6 | 0 | | | |
|* 4 | SORT JOIN | | 27 | 107 | 106 |00:00:00.01 | 6 | 1 | 22528 | 22528 |20480 (0)|
| 5 | TABLE ACCESS FULL | EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 6 | 1 | | | |
------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")위의 실행계획은 두개의 집합을 만들고 키 컬럼을 가지고 merge 하는거다.
# first
select department_name, department_id
from hr.departments
order by department_id;
# second
select department_id, employee_id
from hr.employees
order by department_id;
1. first table을 중복값이 많은 employees로 설정하고 second를 department로 설정하면 성능이 좋지 않다.
select /*+ gather_plan_statistics leading(e,d) use_merge(d) */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 3586199209
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 6 | | | |
| 1 | MERGE JOIN | | 1 | 106 | 106 |00:00:00.01 | 6 | | | |
| 2 | SORT JOIN | | 1 | 107 | 107 |00:00:00.01 | 4 | 15360 | 15360 |14336 (0)|
| 3 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 4 | | | |
|* 4 | SORT JOIN | | 107 | 27 | 106 |00:00:00.01 | 2 | 2048 | 2048 | 2048 (0)|
| 5 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | | | |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")2. 두 테이블을 full table scan으로 유도 후 조건 컬럼값이 유니크한 department 테이블을 first, 중복값이 많은 employees 테이블을 second로 설정해서 실행계획을 유도
select /*+ gather_plan_statistics full(e) full(d) leading(d,e) use_merge(e) */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 2202216887
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 6 | | | |
| 1 | MERGE JOIN | | 1 | 106 | 106 |00:00:00.01 | 6 | | | |
| 2 | SORT JOIN | | 1 | 27 | 27 |00:00:00.01 | 2 | 2048 | 2048 | 2048 (0)|
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | | | |
|* 4 | SORT JOIN | | 27 | 107 | 106 |00:00:00.01 | 4 | 15360 | 15360 |14336 (0)|
| 5 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 4 | | | |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
filter("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")3. nested loops join을 유도하였지만 index scan으로 single block i/o가 발생되기 때문에 sort merge join보다는 좋지 않다.
select /*+ gather_plan_statistics leading(d,e) use_nl(e) */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 1021246405
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 39 | 5 |
| 1 | NESTED LOOPS | | 1 | 106 | 106 |00:00:00.01 | 39 | 5 |
| 2 | NESTED LOOPS | | 1 | 270 | 106 |00:00:00.01 | 24 | 5 |
| 3 | TABLE ACCESS FULL | DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 11 | 5 |
|* 4 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 27 | 10 | 106 |00:00:00.01 | 13 | 0 |
| 5 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 106 | 4 | 106 |00:00:00.01 | 15 | 0 |
---------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
4. nested loops join을 하는데 m쪽 집합을 outer로 설정하고 1쪽 집합을 inner로 설정해서 최악의 i/o를 보여준다.
select /*+ gather_plan_statistics leading(e,d) use_nl(d) */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 919050303
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 129 |
| 1 | NESTED LOOPS | | 1 | 106 | 106 |00:00:00.01 | 129 |
| 2 | NESTED LOOPS | | 1 | 107 | 106 |00:00:00.01 | 23 |
| 3 | TABLE ACCESS FULL | EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 13 |
|* 4 | INDEX UNIQUE SCAN | DEPT_ID_PK | 107 | 1 | 106 |00:00:00.01 | 10 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPARTMENTS | 106 | 1 | 106 |00:00:00.01 | 106 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
hash join
- nested loop join은 대량의 데이터에 대해서 random I/O가 부담스럽고(1건씩 조회하기 때문에) sort merge join은 정렬작업에 대한 부담이 있다.
이럴때 hash join 사용하면 유리하다. - 조인으로 수행하는 집합중에 작은 집합(테이블)을 build table(hash table)로 생성하고 반대쪽 테이블(큰집합)을 probe table해서 해시 테이블을 탐색하면서 조인하는 방식
- hash table은 pga안의 sql 연산작업 공간의 hash_area에 만들어지게 된다.
- hash table을 만드는것도 cpu의 연산작업이다.
- 연산자의 제약조건이 있다. (=) 비교연산자만 사용해야한다.
use_hash(probe table 별칭),leading(build table, probe table)hint 사용swap_join_inputs: probe 테이블을 build 테이블로 변환하는 hint
select /*+ gather_plan_statistics leading(d,e) use_hash(e) */ e.*, d.*
from hr.departments d, hr.employees e
where e.department_id = d.department_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 2052257371
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 64 | 11 | | | |
|* 1 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 64 | 11 | 1376K| 1376K| 1582K (0)|
| 2 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | 0 | | | |
| 3 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 11 | 0 | | | |
--------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")# build table, hash table
select department_name, department_id
from hr.departments;
# probe table
select department_id, employee_id
from hr.employees;
1. location(build table)과 departments(probe table)를 해쉬조인해서 hash table을 만들고 employees(probe table)로 해쉬조인하는 실행계획을 생성하였다.
select /*+ gather_plan_statistics
leading(l,d,e)
use_hash(d)
use_hash(e)*/ e.*, d.*, l.*
from hr.departments d, hr.employees e, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 2684174912
---------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | Used-Mem |
---------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 17 | 2 | | | |
|* 1 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 17 | 2 | 932K| 932K| 1295K (0)|
|* 2 | HASH JOIN | | 1 | 27 | 27 |00:00:00.01 | 5 | 1 | 1031K| 1031K| 1290K (0)|
| 3 | TABLE ACCESS FULL| LOCATIONS | 1 | 23 | 23 |00:00:00.01 | 2 | 1 | | | |
| 4 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | 0 | | | |
| 5 | TABLE ACCESS FULL | EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 11 | 0 | | | |
---------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("D"."LOCATION_ID"="L"."LOCATION_ID")2. 의도적으로 d(build table),e(probe table)의 해쉬조인값을 build table로 하고 locations를 probe table로 설정해서 실행계획을 생성해보았다.
- 옵티마이저가 나의 의도와는 다르게 locations 테이블을 build table(hash table)로 잡고 d,e의 해쉬조인값을 probe table로 hash join으로 실행계획을 생성하였다.
select /*+ gather_plan_statistics
leading(d,e,l)
use_hash(e)
use_hash(l)
*/ e.*, d.*, l.*
from hr.departments d, hr.employees e, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 1575956938
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 17 | | | |
|* 1 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 17 | 1025K| 1025K| 1296K (0)|
| 2 | TABLE ACCESS FULL | LOCATIONS | 1 | 23 | 23 |00:00:00.01 | 2 | | | |
|* 3 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 14 | 1376K| 1376K| 1538K (0)|
| 4 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | | | |
| 5 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 11 | | | |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("D"."LOCATION_ID"="L"."LOCATION_ID")
3 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")3. swap_join_inputs hint를 사용하여 probe 테이블을 build 테이블로 변환하여 실행계획 생성
select /*+ gather_plan_statistics
leading(d,e,l)
use_hash(e)
use_hash(l)
swap_join_inputs(l)*/ e.*, d.*, l.*
from hr.departments d, hr.employees e, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 1575956938
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 17 | | | |
|* 1 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 17 | 1025K| 1025K| 1284K (0)|
| 2 | TABLE ACCESS FULL | LOCATIONS | 1 | 23 | 23 |00:00:00.01 | 2 | | | |
|* 3 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 14 | 1376K| 1376K| 1501K (0)|
| 4 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | | | |
| 5 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 11 | | | |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("D"."LOCATION_ID"="L"."LOCATION_ID")
3 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")4. 의도적으로 no_swap_join_inputs를 사용하여 작은 테이블인 locations테이블을 probe 테이블로 그대로 냅둬서 실행계획이 좋지 않다.
- 큰 테이블이 build table이 될 경우 cpu 사용량과 메모리 사용량이 좋지 않다.
select /*+ gather_plan_statistics
leading(d,e,l)
use_hash(e)
use_hash(l)
no_swap_join_inputs(l)*/ e.*, d.*, l.*
from hr.departments d, hr.employees e, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));Plan hash value: 3997756786
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 106 |00:00:00.01 | 13 | | | |
|* 1 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 13 | 878K| 878K| 849K (0)|
|* 2 | HASH JOIN | | 1 | 106 | 106 |00:00:00.01 | 7 | 1376K| 1376K| 1500K (0)|
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 1 | 27 | 27 |00:00:00.01 | 2 | | | |
| 4 | TABLE ACCESS FULL| EMPLOYEES | 1 | 107 | 107 |00:00:00.01 | 4 | | | |
| 5 | TABLE ACCESS FULL | LOCATIONS | 1 | 23 | 23 |00:00:00.01 | 5 | | | |
------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("D"."LOCATION_ID"="L"."LOCATION_ID")
2 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")