인데스 통계 정보
- 데이터 없이 테이블 모양만 CTAS로 생성
create table hr.emp as select * from hr.employees where 1=2;- CTAS를 하면 처음에 통계수집을 하는데 안에 데이터가 없기 때문에 통계정보들은 0으로 조회된다.
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tables
where owner='HR'
and table_name='EMP';
- 데이터 입력
insert into hr.emp select * from hr.employees;
commit;- 통계수집
execute dbms_stats.gather_table_stats('hr','emp');- 수집한 테이블 통계정보 조회
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tables
where owner='HR'
and table_name='EMP';
- 인덱스 생성
create unique index hr.emp_idx on hr.emp(employee_id);- 인덱스 통계정보 확인
BLEVEL: leaf block까지 오기전의 root,brach block의 수. 값이 낮을수록 검색 성능이 좋음.LEAF_BLOCKS: 인덱스의 리프 블록 개수. 인덱스 크기를 나타냄.DISTINCT_KEYS: 인덱스 내 고유 키 값의 개수.CLUSTERING_FACTOR: 인덱스와 테이블 데이터 정렬 정도. 값이 낮을수록 성능이 좋음.
select
index_name,
blevel,
leaf_blocks,
distinct_keys,
clustering_factor,
num_rows,
to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_indexes
where owner='HR'
and table_name='EMP';
- 테이블에 대한 통계정보 삭제 후 인덱스 통계정보 조회
- 인덱스의 통계정보도 같이 삭제가 되었다.
execute dbms_stats.delete_table_stats('hr','emp');
select
index_name,
blevel,
leaf_blocks,
distinct_keys,
clustering_factor,
num_rows,
to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_indexes
where owner='HR'
and table_name='EMP';
- 다시 통계수집
casecade => false: 테이블 통계수집 하면서 관련 있는 인덱스 통계 수집 안하겠다.casecade => true: 테이블 통계수집 하면서 관련 있는 인덱스 통계 수집 하겠다(기본값)
execute dbms_stats.gather_table_stats('hr','emp',cascade=>false)- 테이블 & 인덱스 통계정보 확인
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tables
where owner='HR'
and table_name='EMP';
select
index_name,
blevel,
leaf_blocks,
distinct_keys,
clustering_factor,
num_rows,
to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_indexes
where owner='HR'
and table_name='EMP';

- 인덱스 통계정보만 수집
execute dbms_stats.gather_index_stats('hr','emp_idx')- 인덱스의 통계정보만 삭제
execute dbms_stats.delete_index_stats('hr','emp_idx')통계수집 무효화 파라미터
- 통계수집은 하되 실행계획에 대한 무효화는 안함
no_invalidate: 라이브러리 캐시에 캐싱된 커서(LCO)를 무효화 할지 결정no_invalidate => true: 연관된 커서(LCO)를 무효화 하지 않겠다.(10g)no_invalidate => false: 연관된 커서(LCO)를 무효화 한다.(9i 기본값)no_invalidate => dbms_stats.auto_invalidate: 정해진 시간동안 조금씩 무효화 한다.(10g new feature 기본값)
execute dbms_stats.gather_table_stats('hr','emp',no_invalidate=>true)- dbms_stats.auto_invalidate(천천히 무효화)에 대한 히든파라미터 확인
- 정해진 시간 단위는 (초)단위
select a.ksppinm as parameter,b.ksppstvl as session_value, c.ksppstvl as instance_value
from x$ksppi a, x$ksppcv b, x$ksppsv c
where a.indx = b.indx
and a.indx = c.indx
and a.ksppinm = '_optimizer_invalidation_period';
자동 통계수집(10g new feature)
Auto Optimizer Stats Collection: 쿼리 최적화를 위해 자동으로 통계 정보를 수집.Auto Space Advisor: 저장 공간 비효율성을 감지하고 최적화 조언을 제공.SQL Tuning Advisor: SQL 성능을 분석하고 개선 방안을 제시.
select client_name, status from dba_autotask_client; 
CONSUMER_GROUP: 세션별 자원(CPU, 메모리 등) 사용을 관리하는 그룹.WINDOW_GROUP: 특정 시간대에 실행되는 작업들을 관리하는 스케줄러 그룹.
select client_name, status, consumer_group, window_group from dba_autotask_client;
- ORA$AT_WGRP_OS라는 윈도우 그룹에 월요일부터 일요일까지 매일 실행되는 7개의 윈도우가 포함되어 있으며, 각 윈도우는 특정 시간대에 유지 관리 작업을 실행합니다.
select * from dba_scheduler_wingroup_members where window_group_name = 'ORA$AT_WGRP_OS';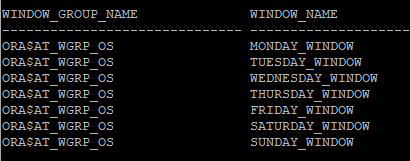
- 이 내용은 Oracle 스케줄러 윈도우 설정으로, 특정 요일과 시간대에 유지 관리 작업을 실행하는 시간과 지속 시간을 나타냅니다. 예를 들어, 월요일부터 금요일까지는 저녁 10시에 4시간 동안 유지 관리 작업이 실행되며, 주말에는 더 긴 시간 동안 작업이 수행됩니다.
select window_name, resource_plan, repeat_interval, duration from dba_scheduler_windows;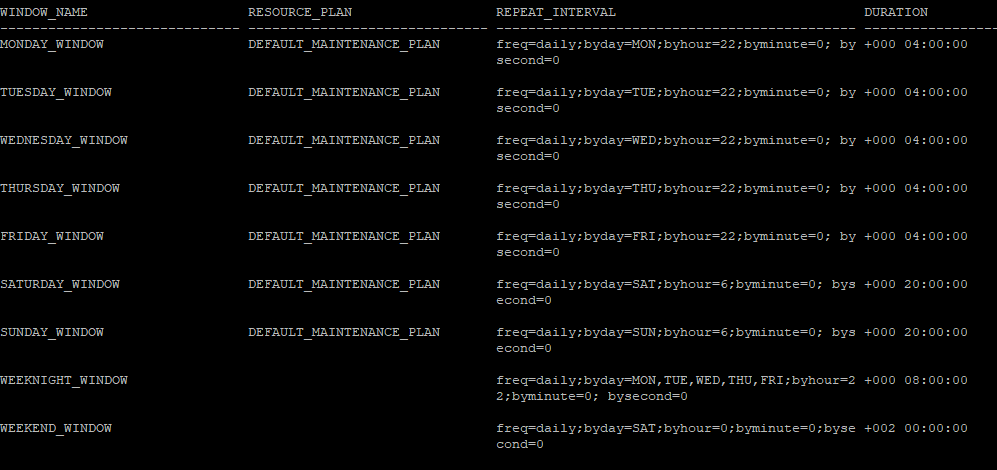
- 이 내용은 Oracle 자동 작업(Auto Task)과 관련된 설정을 보여주는 조회 결과입니다. 각 윈도우(window)에 대해 자동 작업이 언제 실행될지와 어떤 작업들이 활성화되어 있는지를 나타냅니다
select window_name, window_next_time, autotask_status, optimizer_stats,segment_advisor, sql_tune_advisor
from dba_autotask_window_clients;
- Oracle 데이터베이스에서 자동 작업(Auto Task) 실행 내역을 조회하는 명령
select
client_name,
job_status,
job_start_time,
job_duration
from dba_autotask_job_history;자동 통계수집 비활성화
- 자동 옵티마이저 통계 수집 작업을 모든 시간대에서 비활성화하는 명령입니다. 이 작업을 통해 데이터베이스가 자동으로 통계 정보를 수집하지 않도록 설정합니다.
-
operation => null:
operation 매개변수에 null을 지정하여 특정 작업(operation)에 대해 제한을 두지 않음을 의미합니다. 즉, 이 명령은 모든 자동 통계 수집 작업을 대상으로 합니다. -
window_name => null:
window_name 매개변수에 null을 지정하여 특정 윈도우(window)에 제한을 두지 않습니다. 모든 시간대에서 자동 통계 수집이 비활성화됩니다.
begin
dbms_auto_task_admin.disable(client_name=> 'auto optimizer stats collection', operation=> NULL, window_name=> NULL);
end;
/
select client_name, status, consumer_group, window_group from dba_autotask_client;
- 자동 통계수집 활성화
begin
dbms_auto_task_admin.enable(client_name=> 'auto optimizer stats collection', operation=> NULL, window_name=> NULL);
end;
/STATISTICS_LEVEL
- STATISTICS_LEVEL 파라미터는 Oracle 데이터베이스에서 성능 통계 수집 수준을 결정하는 설정으로, BASIC, TYPICAL, ALL 값을 통해 수집 범위를 조정합니다.
show parameter statistics_level

alter session set statistics_level = all;
alter system set statistics_level = all;typical: 일부 통계 수집을 하겠습니다.(기본값)basic: 통계 수집을 안하겠다.all: 가능한 모든 통계 수집을 하겠습니다.(os 통계 포함)
# mmon : 통계 수집을 하는 백그라운드 프로세스
CTAS 자동 통계수집 히든 파라미터
- 테이블 생성(대용량 데이터라는 가정하에 nologging으로 생성)
create table hr.emp nologging as select employee_id, last_name,salary from hr.employees;- 통계정보 확인
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tables
where owner='HR'
and table_name='EMP';
- 12c의 new feature인 CTAS시 자동으로 통계수집 해주는 히든 파라미터 확인
_optimizer_gather_stats_on_load: CTAS, INSERT /+ APPEND / 대량의 데이터를 로드 작업시에 통계수집을 자동으로 하겠다.
select a.ksppinm as parameter,b.ksppstvl as session_value, c.ksppstvl as instance_value
from x$ksppi a, x$ksppcv b, x$ksppsv c
where a.indx = b.indx
and a.indx = c.indx
and a.ksppinm = '_optimizer_gather_stats_on_load';
자동 통계수집의 대상 테이블
- last_analyzed 컬럼의 값이 null 상태
- stale_stats 컬럼의 값이 yes 상태(마지막 통계 수집 이후에 10% 이상의 변화율이 발생된 테이블)
- SYS 또는 SYSTEM 스키마에 속하지 않는 테이블
- 자동 통계 수집이 활성화된 테이블
- 파티셔닝된 테이블
Stale_stats(통계정보의 오래됨)
- stale_stats 컬럼은 Oracle 데이터베이스에서 통계가 최신 상태인지, 아니면 오래되어 갱신이 필요한지를 나타내는 값입니다.
- YES: 테이블에 대한 통계가 오래되었거나 최신 상태가 아님을 의미하며, 다시 수집이 필요합니다.
- NO: 테이블 통계가 최신 상태라는 의미입니다.
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss'), stale_stats
from dba_tab_statistics
where owner='HR'
and table_name='EMP';- 이 쿼리는 특정 테이블이나 스키마에 대해 STALE_PERCENT 값이 어떻게 설정되어 있는지 조회하는 것입니다.
STALE_PERCENT:
STALE_PERCENT는 테이블의 데이터가 얼마나 변경되었을 때 통계가 "stale(오래됨)" 상태로 간주될지를 정의하는 비율입니다.
select * from dba_tab_stat_prefs where preference_name = 'STALE_PERCENT';
- 특정 테이블에 대한 transaction 값 확인
select inserts,updates, deletes, truncated,drop_segments, to_char(timestamp,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_modifications
where table_name = 'EMP';
- 데이터 입력
insert into hr.emp(employee_id, last_name, salary) values(300,'oracle',1000);
insert into hr.emp(employee_id, last_name, salary) values(400,'itwill',2000);- 해당 테이블에 수행한 transaction 값 확인
- 새롭게 통계수집을 하게되면 정보는 초기화 된다.
select inserts,updates, deletes, truncated,drop_segments, to_char(timestamp,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_modifications
where table_name = 'EMP';
- 가끔 정보가 안보이는 경우 flush 해주도록 하자.
execute dbms_stats.flush_database_monitoring_info- 테이블 값을 update 후 수행한 transaction 값을 확인
update hr.emp set salary = salary * 1.1 where salary > 10000;
select inserts,updates, deletes, truncated,drop_segments, to_char(timestamp,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_modifications
where table_name = 'EMP';
- 테이블 값을 delete 후 수행한 transaction 값을 확인
delete from hr.emp where employee_id in (100,101,102);
select inserts,updates, deletes, truncated,drop_segments, to_char(timestamp,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_modifications
where table_name = 'EMP';
- 많은 dml 작업으로 테이블의 변경값이 10% 이상 증가되어 stale_stats 값이 yes로 변경되었다.
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss'), stale_stats
from dba_tab_statistics
where owner='HR'
and table_name='EMP'; 
- 다시 통계수집후 통계정보 확인
degree=>2: 병렬처리 수행
execute dbms_stats.gather_table_stats('hr','emp',degree=>2)
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss'), stale_stats
from dba_tab_statistics
where owner='HR'
and table_name='EMP'; 
- stale 상태로 빠지는 변화율 값을 수정(테이블 레벨) 후 수정값 확인
execute dbms_stats.set_table_prefs('hr','emp','stale_percent',40)
select * from dba_tab_stat_prefs where preference_name = 'STALE_PERCENT';
- truncate 후 transaction 값 확인
- truncate를 하였지만 delete 값도 올라간다.
truncate table hr.emp;
select inserts,updates, deletes, truncated,drop_segments, to_char(timestamp,'yyyy-mm-dd hh24:mi:ss')
from dba_tab_modifications
where table_name = 'EMP';
partition
- 테이블과 인덱스를 파티션 단위로 나누어 저장하는 방식입니다.
- 파티션을 적용하면 하나의 테이블이라도 파티션 키에 따라 데이터를 별도의 물리적 세그먼트에 저장합니다.
- 관리적 측면 : 보관 주기가 지난 데이터를 쉽게 백업하거나 삭제할 수 있어 데이터 관리가 용이해집니다.
- 성능적 측면
- 대용량 테이블에서 파티션 없이 인덱스를 이용한 검색은 데이터 양이 많을수록 성능이 저하될 수 있으며, 일정량을 넘으면 인덱스 기반 검색이 Full Table Scan보다 비효율적일 수 있습니다.
- 하지만 Full Table Scan이 부담스럽다면, 파티셔닝을 통해 일부 파티션 세그먼트만 읽고 필요한 부분에서 멈출 수 있어, 성능을 크게 개선할 수 있습니다.
수동 파티셔닝(manual partitioning)
- 오라클 7버전까지는 파티션 테이블이 제공되지 않았기 때문에 파티션 뷰를 통해 파티션 기능을 구현했다.
- 파티션 뷰의 핵심기능은 뷰 쿼리에 사용된 조건절에 부합하는 테이블만 읽는다.
- 이를
partition pruning이라고 한다.
수동 파티셔닝 실습
- 3개의 테이블 생성
create table hr.p10 as select * from hr.employees where 1=2;
create table hr.p20 as select * from hr.employees where 1=2;
create table hr.p30 as select * from hr.employees where 1=2;- check 제약조건 추가
alter table hr.p10 add constraint c_dept_10 check(department_id <20);
alter table hr.p20 add constraint c_dept_20 check(department_id >=20 and department_id <30);
alter table hr.p30 add constraint c_dept_30 check(department_id >=30 and department_id < 40);- 데이터 입력
insert into hr.p10 select * from hr.employees where department_id <20;
insert into hr.p20 select * from hr.employees where department_id >=20 and department_id <30;
insert into hr.p30 select * from hr.employees where department_id >=30 and department_id < 40;
commit;- 생성되어있는 제약조건 조회
select table_name, constraint_name, search_condition
from dba_constraints
where owner='HR'
and table_name in ('P10','P20','P30');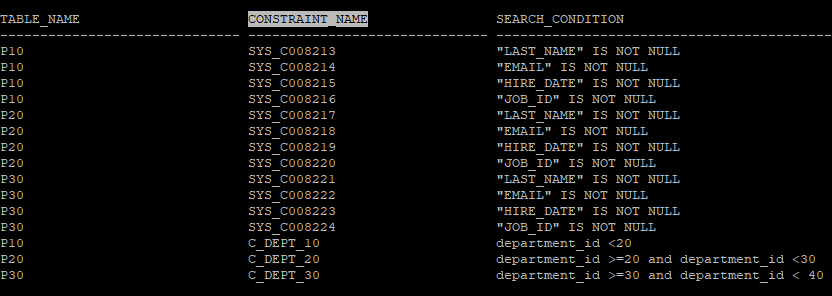
- view 생성
create or replace view hr.emp_partition
as
select * from hr.p10
union all
select * from hr.p20
union all
select * from hr.p30;- 통계정보를 수집
execute dbms_stats.gather_table_stats('hr','p10')
execute dbms_stats.gather_table_stats('hr','p20')
execute dbms_stats.gather_table_stats('hr','p30')- 수집된 통계정보 확인
select num_rows, blocks, avg_row_len, to_char(last_analyzed,'yyyy-mm-dd hh24:mi:ss')
from dba_tables
where owner='HR'
and table_name in ('P10','P20','P30');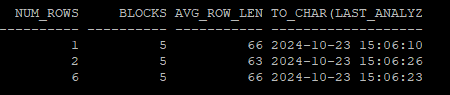
- 세션레벨에서 statistics_level을 all로 변경한다.
gather_plan_statisticshint를 사용하지 않아도 바로 실행계획을 확인할 수 있다.
alter session set statistics_level = all;- 마지막 작성 쿼리문에 대한 실행계획을 바로 볼 수 있다.
partition pruning기능을 이용해 조건절의 파티션 키 컬럼에 해당하는 테이블에 대해서만 i/o가 발생한다.
select * from hr.emp_partition where department_id = 10;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));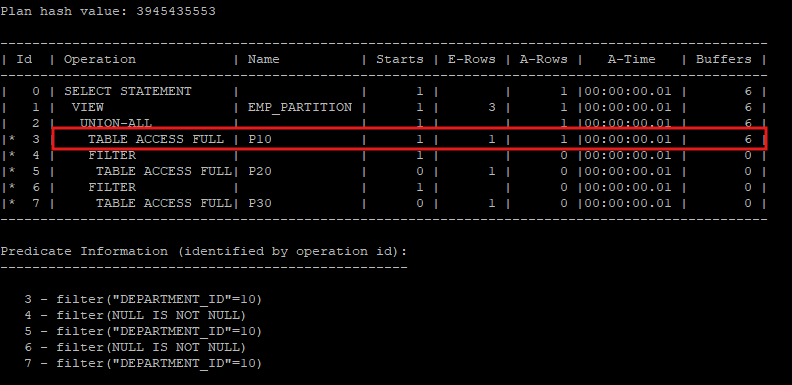
select * from hr.emp_partition where department_id = 20;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));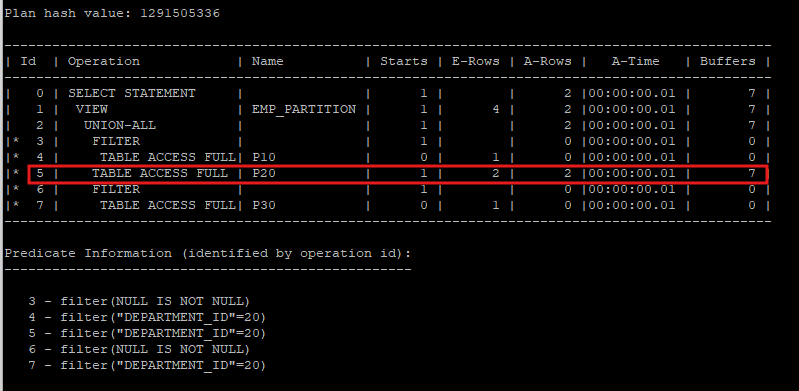
- 조건절의 파티션 키 값을 바인드 변수로 처리하면 partition pruning 기능이 작동되지 않고 테이블 전부 조회하게 된다.
var b_dept_id number
execute :b_dept_id := 30
select * from hr.emp_partition where department_id = :b_dept_id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));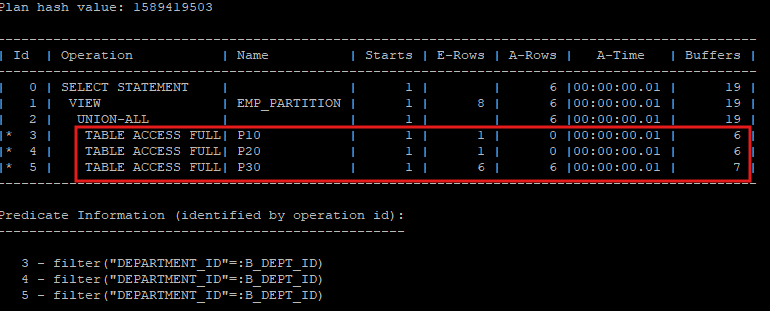
- 파티션이 되어있는 상태에서 인덱스까지 생성되어있으면 index scan을 수행하여 i/o를 더 줄일 수 있다.
create unique index hr.p30_idx on hr.p30(employee_id);
select * from hr.emp_partition where department_id = 30 and employee_id = 115;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));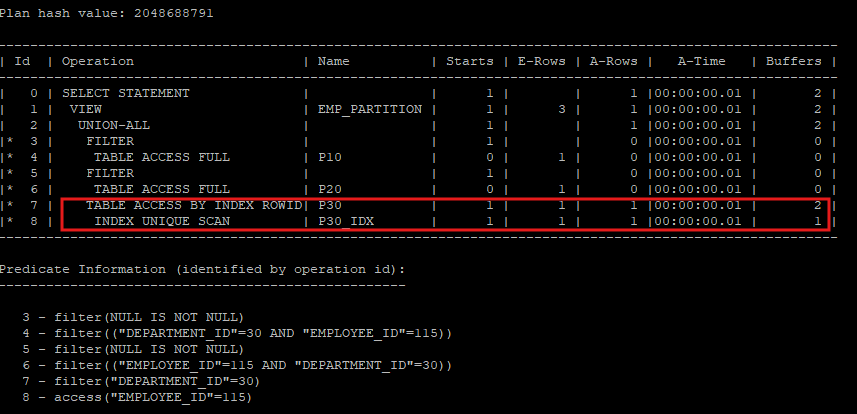
- V$OPTION 뷰는 Oracle 데이터베이스에서 사용 가능한 옵션 및 기능을 확인할 수 있는 동적 성능 뷰입니다.
- partitioning 기능은 enterprise 모드에서만 사용가능한 기능이다.
select * from v$option;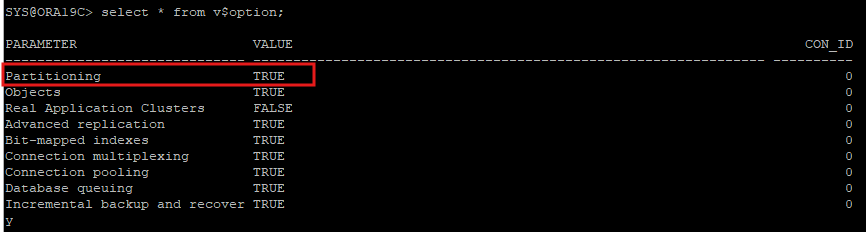
range partition
- 8버전 부터 제공
- 이력성 데이터 조회에 유리
- 여러컬럼을 파티션키로 지정 가능(최대 16)
- maxvalue 파티션을 꼭 생성하자
테스트 1
- 파티션 테이블 생성
less than(to_date('2005-01-01','yyyy-mm-dd')): < to_date('2005-01-01','yyyy-mm-dd')less than(maxvalue)): >= to_date('2007-01-01','yyyy-mm-dd')
create table hr.emp_year
partition by range(hire_date) -- hire_date 컬럼을 키컬럼으로 설정
(partition p2004 values less than(to_date('2005-01-01','yyyy-mm-dd')), -- p2004라는 파티션테이블(세그먼트)에 저장
partition p2005 values less than(to_date('2006-01-01','yyyy-mm-dd')), -- p2005라는 파티션테이블(세그먼트)에 저장
partition p2006 values less than(to_date('2007-01-01','yyyy-mm-dd')), -- p2006라는 파티션테이블(세그먼트)에 저장
partition pmax values less than(maxvalue))
as
select employee_id, last_name, salary, hire_date, department_id
from hr.employees;- 파티션 정보 조회
- 통계정보는 아직 수집하지 않아 null로 보인다.
select partition_name, high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_YEAR';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_YEAR';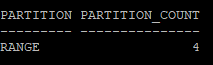
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_YEAR';
- 테이블안에서도 특정 파티션 내용만 조회
select * from 테이블명 partition(파티션테이블)
select * from hr.emp_year partition(p2004);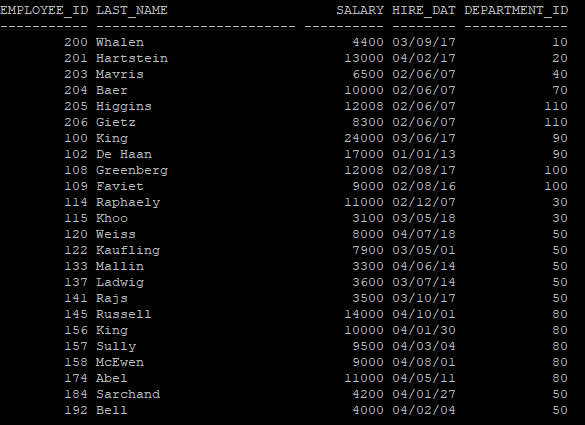
select * from hr.emp_year partition(pmax);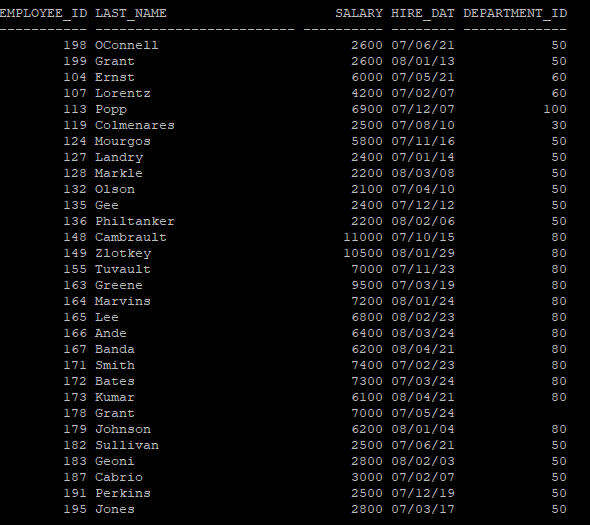
테스트 2(파티션 자동생성)
- 1년 단위로 파티션을 자동 생성하는 테이블 생성
- 자동생성을 하지 않을경우에는 반드시 maxvalue를 설정해줘야 한다.
create table hr.emp_year
partition by range(hire_date) interval(numtoyminterval(1,'year')) -- hire_date 컬럼을 키컬럼으로 설정
(partition p2004 values less than(to_date('2005-01-01','yyyy-mm-dd')), -- p2004라는 파티션테이블(세그먼트)에 저장
partition p2005 values less than(to_date('2006-01-01','yyyy-mm-dd')), -- p2005라는 파티션테이블(세그먼트)에 저장
partition p2006 values less than(to_date('2007-01-01','yyyy-mm-dd'))) -- p2006라는 파티션테이블(세그먼트)에 저장
as
select employee_id, last_name, salary, hire_date, department_id
from hr.employees;- 파티션 정보 조회
- 직접 만든 파티션이후에도 1년 interval로 자동으로 만들어져있다.
select partition_name, high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_YEAR';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
- 파티션의 건수도 무한대로 늘어났다.
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_YEAR';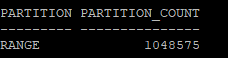
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_YEAR';
- 테이블안에서도 특정 파티션 내용만 조회
select * from 테이블명 partition(파티션테이블)
select * from hr.emp_year partition(SYS_P762);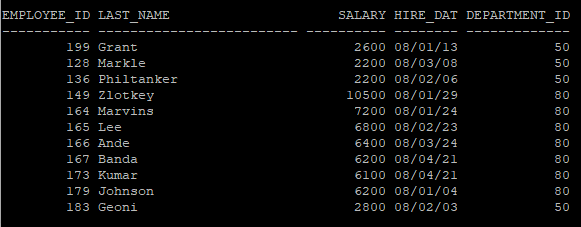
- 오늘날짜로 데이터를 입력후 파티션을 조회해보면 증가된걸 볼 수 있다.
- rollback을 하여도 생성된 파티션 세그먼트는 사라지지 않는다.
insert into hr.emp_year values(200,'oracle',1000,sysdate,10);
select partition_name, high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_YEAR';
- 파티션을 이용해 조회를 하면 실행계획에서 partition range single operation이 발생한다.
partition range single이 발생하면 partition pruning 기능이 작동된걸로 생각하면 된다.- 하나의 파티션을 이용해서 데이터를 조회한걸 의미한다.
select * from hr.emp_year partition(p2004);
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));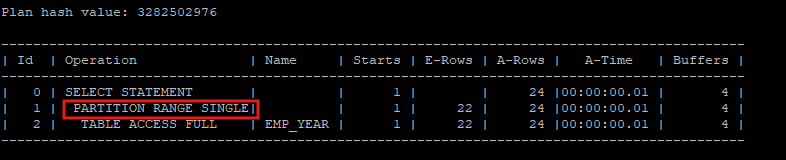
- 파티션을 명시해서 select 하지 않고 조건을 해당 partition에 맞게 주어지면 이것 또한 partition pruning 기능이 작동하였다.
select *
from hr.emp_year
where hire_date >= to_date('20040101','yyyymmdd')
and hire_date < to_date('20050101','yyyymmdd');
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));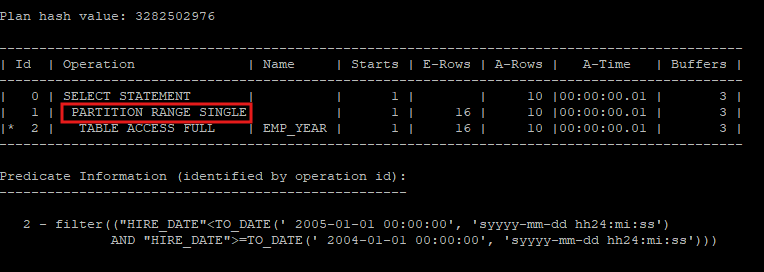
- 데이터 전체를 조회할 경우 partition range all operation으로 되는데 이럴경우에는 partition pruning 이 작동되지 않는다.
select *
from hr.emp_year
where salary >= 1000;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));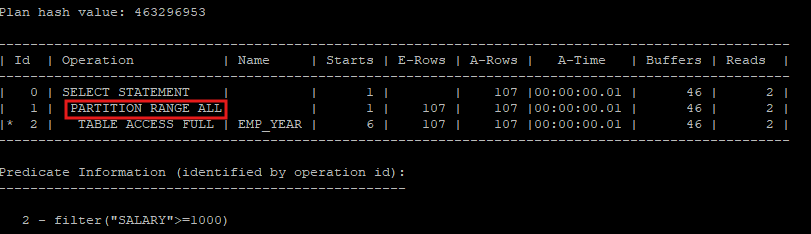
hash partition
- 8i 버전부터 제공
- partition key 값에 해시함수를 적용하여 데이터를 분할하는 방식
- 데이터 분포가 고른 컬럼을 파티션 컬럼으로 선정하는게 좋다.
- 중복성보다는 유일키값으로 키값을 정하자.
- 파티션 개수는 2의 제곱(2,4,8,16,32...)으로 하는 이유는 특정 파티션에 몰리지 않도록 하기 위해서
- 조건절 (=),(in) 조건을 검색할때만 partition pruning 기능이 수행된다.
- 병렬 쿼리 성능 향상뿐 아니라 동시에 입력이 많은 대용량 테이블이나 인덱스에 발생하는 경합을 줄일 목적으로 해시 파티셔닝을 사용한다.
테스트 1
- hash partition을 이용한 테이블 생성
create table hr.emp_hash
partition by hash(employee_id) partitions 4
as
select employee_id, last_name, salary, department_id
from hr.employees;- 파티션 정보 조회
select partition_name, high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_HASH';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_HASH';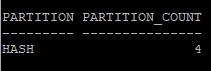
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_HASH';
list partition
- 9i 버전부터 제공
- 미리 정해진 그룹을 기준으로 데이터를 분할, 값 목록
- 단일 컬럼만 키 컬럼 가능
- default 구성을 반드시 해야한다.
- 설정해놓은 값 이외의 값이 입력되었을때 처리방법
- list partition을 이용한 테이블 생성
create table hr.emp_list
partition by list(department_id)
(partition p_dept_1 values(10,20,30,40),
partition p_dept_2 values(50),
partition p_dept_3 values(60,70,80,90,100,110),
partition p_dept_4 values(default)
)
as
select employee_id, last_name, salary, department_id
from hr.employees;- 파티션 정보 조회
select partition_name, high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_LIST';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_LIST';
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_LIST';
- 특정 파티션으로 조회
select * from hr.emp_list partition(p_dept_1);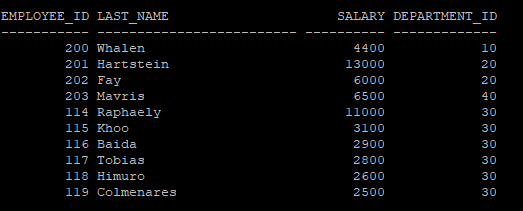
조합 partition
-
서브 파티션 마다 세그먼트를 하나씩 할당하고 서브 파티션 단위로 데이터를 저장
-
주 파티션에 따라 1차적으로 데이터를 분배하고 서브 파티션 키에 따라 최종적으로 저장할(세그먼트) 위치를 결정한다.
-
설정 조합
- range - hash partition(8i)
- range - list partition(9i)
- range - range partition(11g)
- list - hash partition(11g)
- list - range partition(11g)
- list - list partition(11g)
테스트 1 (range - hash)
- main partition은 range, sub partition은 hash인 테이블 생성
create table hr.emp_comp
partition by range(salary)
subpartition by hash(employee_id) subpartitions 4
(partition p4999 values less than(5000),
partition p9999 values less than(10000),
partition p19999 values less than(20000),
partition pmax values less than(maxvalue)
)
as
select employee_id, last_name, salary, department_id
from hr.employees;- 파티션 정보 조회
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_COMP';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_COMP';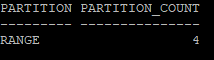
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_COMP';
- 메인 partition 안에 서브 partition 조회
select partition_name, subpartition_name, high_value, subpartition_position
from dba_tab_subpartitions
where table_name='EMP_COMP'
and table_owner='HR';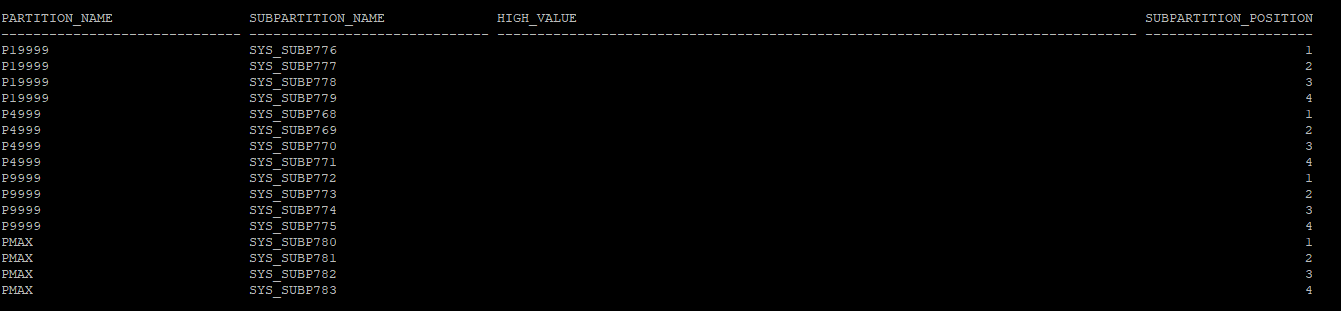
- 메인 partition의 갯수와 그 안에 들어있는 서브 partition의 갯수 확인
select partitioning_type, partition_count, subpartitioning_type, def_subpartition_count
from dba_part_tables
where table_name = 'EMP_COMP'
and owner='HR';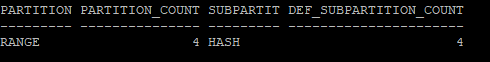
- 실행계획 확인
-
이 쿼리는 salary < 5000 조건에 맞는 데이터를 모든 서브파티션에서 검색합니다.
-
PARTITION HASH ALL: 이는 모든 서브파티션을 검색하는 것을 의미합니다. 이 경우 salary에 대한 조건만 있으므로 파티션 키가 아닌 다른 조건으로 데이터를 조회하므로, 모든 서브파티션을 순차적으로 스캔하게 됩니다.
-
PARTITION RANGE SINGLE: 이 작업은 메인 파티션에서 하나의 파티션만 스캔한다는 것을 의미합니다. 즉, 조건에 맞는 하나의 범위에 해당하는 파티션을 선택하여 스캔합니다.
select * from hr.emp_comp where salary < 5000;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));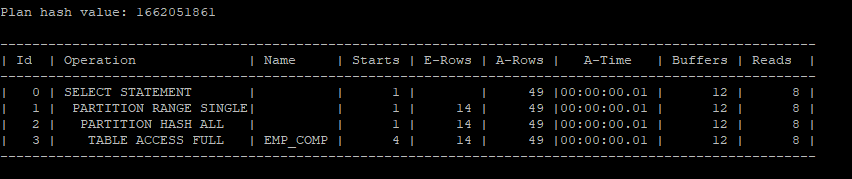
-
이 쿼리는 employee_id = 200 조건에 맞는 하나의 서브파티션을 검색하고, 그 안에서 salary < 5000 조건에 맞는 데이터를 찾습니다.
-
PARTITION RANGE SINGLE: 이는 단일 파티션을 스캔한다는 것을 의미합니다. 여기서는 employee_id를 기준으로 특정 서브파티션을 정확히 찾고, 그 서브파티션 내에서만 검색을 수행합니다.
-
효율성: 이 실행 계획에서는 employee_id와 salary 조건을 모두 사용하여 하나의 파티션과 하나의 서브파티션만을 검색하므로, 훨씬 더 효율적인 검색이 이루어집니다.
select * from hr.emp_comp where salary < 5000 and employee_id = 200;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));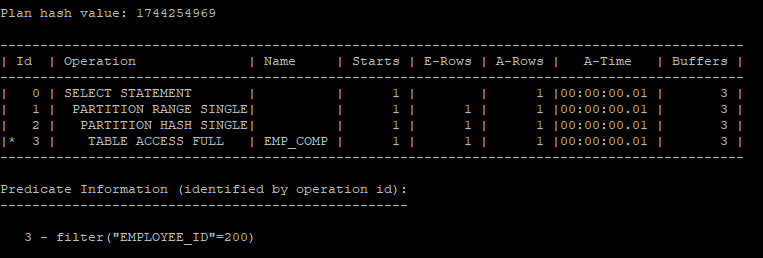
테스트 2 (range - list)
- main partition은 range, sub partition은 list인 테이블 생성
create table hr.emp_year
partition by range(hire_date)
subpartition by list(department_id)
subpartition template
(subpartition p_dept_1 values(10,20,30,40),
subpartition p_dept_2 values(50),
subpartition p_dept_3 values(60,70,80,90,100,110),
subpartition p_dept_4 values(default))
(partition p2004 values less than(to_date('2005-01-01','yyyy-mm-dd')),
partition p2005 values less than(to_date('2006-01-01','yyyy-mm-dd')),
partition p2006 values less than(to_date('2007-01-01','yyyy-mm-dd')),
partition pmax values less than(maxvalue))
nologging
as
select employee_id, last_name, salary,hire_date, department_id
from hr.employees;- 파티션 정보 조회
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='EMP_YEAR';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='EMP_YEAR';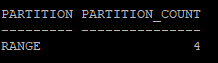
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='EMP_YEAR';
- 메인 partition 안에 서브 partition 조회
select partition_name, subpartition_name, high_value, subpartition_position
from dba_tab_subpartitions
where table_name='EMP_YEAR'
and table_owner='HR';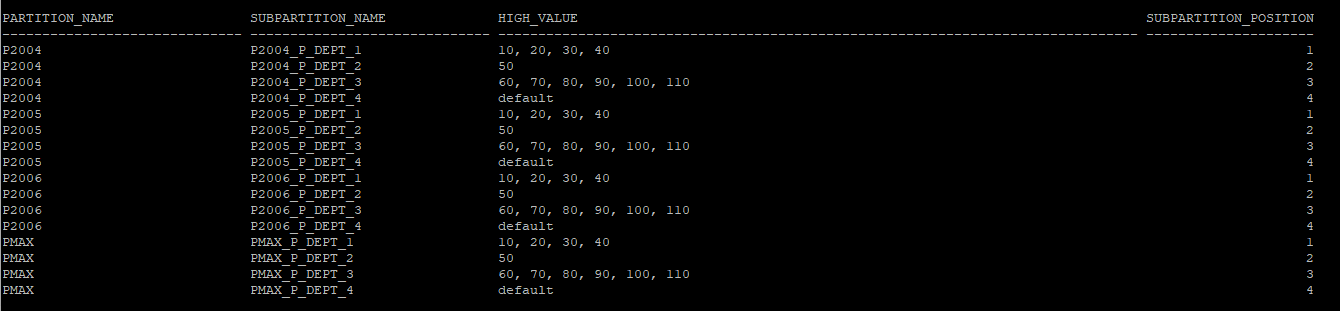
- 메인 partition의 갯수와 그 안에 들어있는 서브 partition의 갯수 확인
select partitioning_type, partition_count, subpartitioning_type, def_subpartition_count
from dba_part_tables
where table_name = 'EMP_YEAR'
and owner='HR';
- 실행계획 확인
- 조건절에 hire_date컬럼에 대한 조건만 있어 메인 파티션은 range single로 찾고 서브 파티션은 list all로 찾은걸 알 수 있다.
select *
from hr.emp_year
where hire_date >= to_date('20020101','yyyymmdd')
and hire_date < to_date('20030101','yyyymmdd');
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));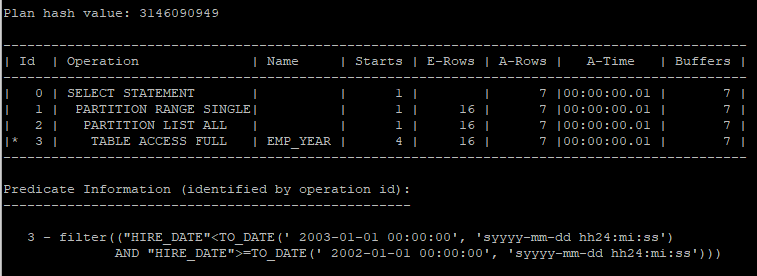
- 메인 파티션, 서브 파티션에 대한 키 컬럼들을 조건 걸기 때문에 single로 찾는다.
select *
from hr.emp_year
where hire_date >= to_date('20020101','yyyymmdd')
and hire_date < to_date('20030101','yyyymmdd')
and department_id = 100;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));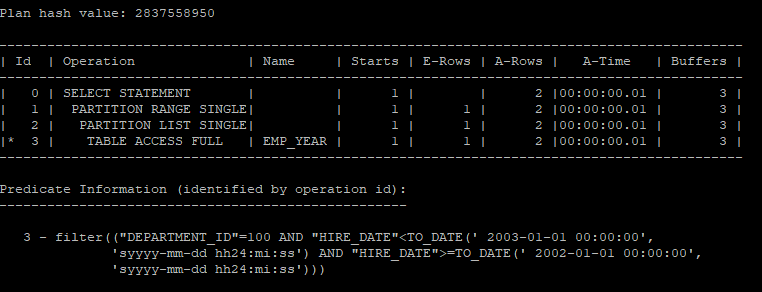
partition 분할
- range partion이 메인 파티션인 테이블 생성
create table hr.sal_emp
partition by range(salary)
(partition p1 values less than(5000),
partition p2 values less than(15000),
partition p3 values less than(25000)
)
as
select employee_id, last_name, salary, department_id
from hr.employees;- 파티션 정보 조회
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='SAL_EMP';
- 만들어진 파티션 갯수 및 파티션의 종류 확인
select partitioning_type, partition_count
from dba_part_tables
where owner='HR'
and table_name='SAL_EMP';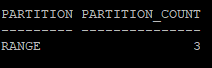
- 파티션 키 컬럼 조회
select *
from dba_part_key_columns
where owner='HR'
and name='SAL_EMP';
- p3 파티션 테이블 조회
select * from hr.sal_emp partition(p3);
- p3 파티션에서 20000을 기준으로 20000 이하는 p3 파티션, 이상은 p4 파티션으로 분할
alter table hr.sal_emp split partition p3 at(20000) into (partition p3, partition p4);
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='SAL_EMP';
- p3 파티션의 데이터가 분할 된걸 조회할 수 있다.
select * from hr.sal_emp partition(p3);
partition 추가
- maxvalue를 설정해놓지 않고 추후 파티션을 추가해야할 때
alter table 테이블명 add partition 파티션이름 values less than(조건값);
alter table hr.sal_emp add partition p5_1 values less than(30000);
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='SAL_EMP';
partition 이름 변경
alter table 테이블명 rename partition 원래이름 to 바꿀이름;
alter table hr.sal_emp rename partition p5_1 to p5;
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='SAL_EMP';
partition 삭제
alter table 테이블명 drop partition 지워야할 파티션이름;
alter table hr.sal_emp drop partition p5;
select partition_name, subpartition_count,high_value, tablespace_name, num_rows,blocks,avg_row_len
from dba_tab_partitions
where table_owner='HR'
and table_name='SAL_EMP';
특정 partition 데이터 truncate
select * from hr.sal_emp partition(p3);
alter table 테이블명 truncate partition 파티션명;
alter table hr.sal_emp truncate partition p3;
select * from hr.sal_emp partition(p3);
update를 통한 partition 이동
- 데이터를 입력
insert into hr.sal_emp
select employee_id, last_name, salary, department_id
from hr.employees
where employee_id in (101,102);
commit;
select * from hr.sal_emp partition(p3);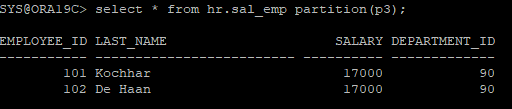
- p3 파티션은 20000까지는 키컬럼 변경 허용범위이기 때문에 문제가 없다.
update hr.sal_emp set salary = 18000 where employee_id = 101;
rollback;- 하지만 p3 범주를 벗어나게 키컬럼을 변경하려는 순간 오류가 발생한다.
update hr.sal_emp set salary = 21000 where employee_id = 101;
- 파티션의 범주를 벗어나게 변경한다는것은 다른 세그먼트(파티션)으로 변경한다는 의미이기 때문에 rowid가 변경된다. 따라서 변경하기 전 row movement를 enable 상태로 변경해야 한다.
alter table hr.sal_emp enable row movement;
- update를 통해 101번 사원은 p4 파티션(세그먼트)로 이동되었다.
update hr.sal_emp set salary = 21000 where employee_id = 101;
- row movement를 비활성화한다.
alter table hr.sal_emp disable row movement;
- 101사원은 update를 통해 더이상 p3 파티션에는 없다.
select * from hr.sal_emp partition(p3);
- 101번 사원이 p4 파티션으로 이동되었다.
select * from hr.sal_emp partition(p4);
